CDH5(CDH 5.16.1)安装
CDH 6系列(CDH 6.0.0、CDH 6.1.0、CDH 6.2.0等)安装和使用
CDH5(CDH 5.16.1)安装
linux配置
1.第一种方式:rsa算法加密,非对称加密的方式基于私钥登陆的方式:(ssh连接时无需输入用户密码)
1.ssh-keygen -t rsa 然后四下回车
2./root/.ssh目录下:
私钥:id_rsa
公钥:id_rsa.pub
3.ssh-copy-id linux的IP
每个节点都需要拷贝秘钥然后分发给别的linux,执行命令后然后输入yes,然后最终输入密码
ssh-copy-id node1
ssh-copy-id node2
ssh-copy-id node3
4.ssh linux的用户名@别的linux的IP
现在无需输入别的linux的用户密码即能登录到别的linux中
5.ssh root@node1
exit
ssh root@node2
exit
ssh root@node3
exit
2.第二种方式:dsa算法加密,非对称加密的方式基于私钥登陆的方式:(ssh连接时无需输入用户密码)
1.先做好各种登录自己免密
ssh-keygen -t dsa -P '' -f ~/.ssh/id_dsa
cat ~/.ssh/id_dsa.pub >> ~/.ssh/authorized_keys
chmod 600 ~/.ssh/authorized_keys
2.再做节点间免密
ssh-copy-id -i ~/.ssh/id_dsa.pub root@node1
ssh-copy-id -i ~/.ssh/id_dsa.pub root@node2
ssh-copy-id -i ~/.ssh/id_dsa.pub root@node3
3.报错解决:如果执行 ssh-copy-id 时报错如下:
ERROR: WARNING: REMOTE HOST IDENTIFICATION HAS CHANGED!
ERROR: IT IS POSSIBLE THAT SOMEONE IS DOING SOMETHING NASTY!
ERROR: Someone could be eavesdropping on you right now (man-in-the-middle attack)!
ERROR: It is also possible that a host key has just been changed.
ERROR: The fingerprint for the ECDSA key sent by the remote host is
ERROR: 66:d4:d5:27:79:15:65:e0:91:be:b3:1b:0e:75:09:34.
ERROR: Please contact your system administrator.
ERROR: Add correct host key in /root/.ssh/known_hosts to get rid of this message.
ERROR: Offending ECDSA key in /root/.ssh/known_hosts:1
ERROR: ECDSA host key for cdh01 has changed and you have requested strict checking.
ERROR: Host key verification failed.
解决方式:比如在node2执行ssh-copy-id发送id_rsa.pub(公钥)给node1出现上述报错的话,可以在node1上执行vim /root/.ssh/known_hosts 删除文件中node2的公钥信息,
然后node2重新执行ssh-copy-id重新发送id_rsa.pub(公钥)给node1即可。
1.查看IP地址:ip addr
2.配置网卡信息
1.vi /etc/sysconfig/network-scripts/ifcfg-ens33
TYPE=Ethernet
PROXY_METHOD=none
BROWSER_ONLY=no
BOOTPROTO=none
DEFROUTE=yes
IPV4_FAILURE_FATAL=yes
IPV6INIT=yes
IPV6_AUTOCONF=yes
IPV6_DEFROUTE=yes
IPV6_FAILURE_FATAL=no
IPV6_ADDR_GEN_MODE=stable-privacy
NAME=ens33
UUID=1945a1d8-e6a6-4d0d-828e-60dc0320edb4
DEVICE=ens33
ONBOOT=yes 修改完这个然后重启网络后就可以ping通外界网络了
IPADDR=192.168.88.100
PREFIX=24
GATEWAY=192.168.88.2
DNS1=192.168.88.2
IPV6_PRIVACY=no
3.重启网络:service network restart
4.ping baidu.com
5.yum install vim
6.vim添加行号
vim /etc/vimrc
最后一行添加内容 :set number
3.设置 hostname,reboot重启之后即能显示(注意:不使用大写字符作为主机名,否则在CDH中无法正常通过Kerberos进行身份验证)
hostnamectl set-hostname 主机名
vim /etc/hostname 设置主机名,直接保存主机名即可
vim /etc/sysconfig/network 文件内容如下
NETWORKING=yes
HOSTNAME=主机名
4.设置 hosts 文件
vim /etc/hosts 配置格式为:IP 主机名
192.168.88.100 node1
192.168.88.101 node2
192.168.88.102 node3
scp -r /etc/hosts root@node2:/etc
scp -r /etc/hosts root@node3:/etc
5.禁用 防火墙(重启生效)
关闭 systemctl stop firewalld
开机禁用 systemctl disable firewalld
查看状态 systemctl status firewalld 
6.禁用 SELINUX
1.临时关闭SELINUX
setenforce 0
2.永久关闭SELINUX
修改配置文件 vim /etc/selinux/config(重启生效)
将 SELINUX=enforcing 改为 SELINUX=disabled
3.查看SELINUX状态 sestatus
reboot 重启机器后 执行 sestatus 显示 SELinux status: disabled
7.配置时间同步
如果多个节点之间的NTP服务没有成功同步时间的话,多个组件都无法使用,并且CM页面上会显示“时钟偏差不良”,并报错信息:
The health test result for HOST_CLOCK_OFFSET has become bad: The host's NTP service is not synchronized to any remote server
注意:ntpd服务启动后,主节点一般需要1~5分钟才能同步上外部的授时中心,其他子节点同样可能需要1~5分钟才同步上主节点时钟
1.方案一(推荐使用方案二或方案三,不建议使用方案一)
安装 yum install ntpdate
根据aliyun提供的服务进行 时间同步:ntpdate ntp6.aliyun.com
查看当前时间:date 或 timedatectl
2.方案二(推荐使用方案二或方案三,不建议使用方案一)
该方案目的:同步node1的时间为外部授时时间,然后node、node3的时间为同步node1的时间
先安装 ntp 再使用命令同步外部授时中心:ntpdate -u cn.pool.ntp.org 或 ntpdate -u ntp6.aliyun.com
1.ntp
安装 yum install ntp
启动服务 systemctl start ntpd
查看是否启动 ps -ef | grep ntpd
开机启动 systemctl enable ntpd.service
查看当前时间 date
查看当前时间和NTP服务的同步状态 timedatectl
2.node1作为NTP Server,node2和node3作为NTP Client,node2和node3要跟node1同步时间,node1要去外部授时中心同步时间
1.配置 node1:
1.配置前先使用命令同步外部授时中心:ntpdate -u cn.pool.ntp.org 或 ntpdate -u ntp6.aliyun.com
2.vim /etc/ntp.conf
注释以下配置
#server 0.centos.pool.ntp.org iburst
#server 1.centos.pool.ntp.org iburst
#server 2.centos.pool.ntp.org iburst
#server 3.centos.pool.ntp.org iburst
增加如下配置:
# 允许内网其他机器同步时间,如果不添加该约束默认允许所有IP访问本机同步服务。192.168.88.0为本局域网内的子网IP
restrict 192.168.88.0 mask 255.255.255.0 nomodify notrap
# 配置和上游标准时间同步
server 210.72.145.44 # 中国国家授时中心
server 133.100.11.8 #日本[福冈大学]
server 0.cn.pool.ntp.org
server 1.cn.pool.ntp.org
server 2.cn.pool.ntp.org
server 3.cn.pool.ntp.org
# 配置允许上游时间服务器主动修改本机(内网ntp Server)的时间
restrict 210.72.145.44 nomodify notrap noquery
restrict 133.100.11.8 nomodify notrap noquery
restrict 0.cn.pool.ntp.org nomodify notrap noquery
restrict 1.cn.pool.ntp.org nomodify notrap noquery
restrict 2.cn.pool.ntp.org nomodify notrap noquery
restrict 3.cn.pool.ntp.org nomodify notrap noquery
# 确保localhost有足够权限,使用没有任何限制关键词的语法。
# 外部时间服务器不可用时,以本地时间作为时间服务。
# 注意:这里不能改,必须使用127.127.1.0,否则会导致无法
#在ntp客户端运行ntpdate serverIP,出现no server suitable for synchronization found的错误。
#在ntp客户端用ntpdate –d serverIP查看,发现有“Server dropped: strata too high”的错误,并且显示“stratum 16”。而正常情况下stratum这个值得范围是“0~15”。
#这是因为NTP server还没有和其自身或者它的server同步上。
#以下的定义是让NTP Server和其自身保持同步,如果在ntp.conf中定义的server都不可用时,将使用local时间作为ntp服务提供给ntp客户端。
#下面这个配置,建议NTP Client关闭,建议NTP Server打开。因为Client如果打开,可能导致NTP自动选择合适的最近的NTP Server、也就有可能选择了LOCAL作为Server进行同步,而不与远程Server进行同步。
server 127.127.1.0 # local clock
fudge 127.127.1.0 stratum 10
2.配置 node2、node3:
1.vim /etc/ntp.conf
注释以下配置
#server 0.centos.pool.ntp.org iburst
#server 1.centos.pool.ntp.org iburst
#server 2.centos.pool.ntp.org iburst
#server 3.centos.pool.ntp.org iburst
增加如下配置:
#配置上游时间服务器为本地的ntpd Server服务器
server 192.168.88.100
# 配置允许上游时间服务器主动修改本机的时间
restrict 192.168.88.100 nomodify notrap noquery
3.方案三(推荐使用方案二或方案三,不建议使用方案一)
该方案目的:node、node3的时间为同步node1的时间,node1的时间可以使用同步命令ntpdate同步外部授时时间即可。
先安装 ntp 再使用命令同步外部授时中心:ntpdate -u cn.pool.ntp.org 或 ntpdate -u ntp6.aliyun.com
1.ntp
安装 yum install ntp
启动服务 systemctl start ntpd
查看是否启动 ps -ef | grep ntpd
开机启动 systemctl enable ntpd.service
查看当前时间 date
查看当前时间和NTP服务的同步状态 timedatectl
2.node1作为NTP Server,node2和node3作为NTP Client,node2和node3要跟node1同步时间,node1要去外部授时中心同步时间
1.配置 node1:
1.配置前先使用命令同步外部授时中心:ntpdate -u cn.pool.ntp.org 或 ntpdate -u ntp6.aliyun.com
2.vim /etc/ntp.conf
注释以下配置
#server 0.centos.pool.ntp.org iburst
#server 1.centos.pool.ntp.org iburst
#server 2.centos.pool.ntp.org iburst
#server 3.centos.pool.ntp.org iburst
增加如下配置:
server 127.127.1.0
fudge 127.127.1.0 stratum 10
disable monitor
server node1
restrict node1 nomodify notrap noquery
2.配置 node2、node3:
1.vim /etc/ntp.conf
注释以下配置
#server 0.centos.pool.ntp.org iburst
#server 1.centos.pool.ntp.org iburst
#server 2.centos.pool.ntp.org iburst
#server 3.centos.pool.ntp.org iburst
增加如下配置:
# 同步node1的时间到node、node3
server node1
Fudge node1 stratum 10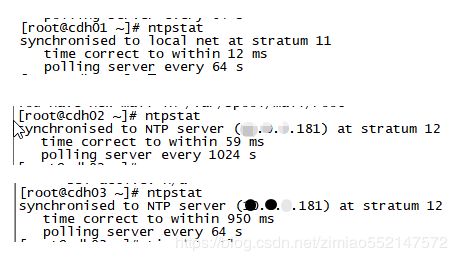

4.检查各台机器之间是否同步时间成功(下面是使用方案二后进行检查的情况)
1.检查node1
1.systemctl restart ntpd 重启服务端ntpd服务
2.ntpq -p 查看网络中的NTP服务器,同时显示客户端和每个服务器的关系 
3.ntpstat 查看时间同步状态
1.正在尝试同步的话,执行ntpstat会显示 synchronised to local net at stratum 11
主节点一般需要1~5分钟才能同步上外部的授时中心。所以,服务器启动后需要稍等下。
2.没有同步成功的话,执行ntpstat会显示unsynchronised
3.同步成功以后,node1会显示 synchronised to NTP server (119.28.183.184) at stratum 3
4.也可以使用 ntpdate -u ntp6.aliyun.com 同步阿里云时间
timedatectl 查看当前时间和NTP服务的同步状态:必须保证所有节点下的时间都是一致,并且NTP服务同步成功,那么才能作为CDH启动成功的保证

2.检查node2、node3
1.systemctl restart ntpd 重启服务端ntpd服务
2.ntpq -p 查看网络中的NTP服务器,同时显示客户端和每个服务器的关系 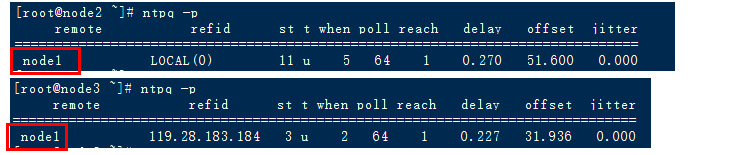
3.ntpstat 查看时间同步状态
其他子节点同样可能需要1~5分钟才同步上主节点时钟
同步还没有成功时,node2、node3会显示 synchronised to unspecified at stratum 3
同步成功以后,node2、node3会显示 synchronised to NTP server (主节点IP)at stratum 3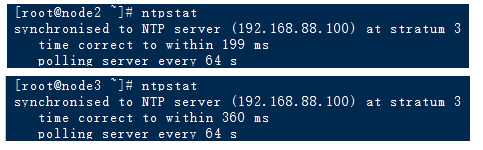
4.node2、node3 都可以手动执行 ntpdate -u node1 同步主节点的时间
timedatectl 查看当前时间和NTP服务的同步状态 timedatectl:必须保证所有节点下的时间都是一致,并且NTP服务同步成功,那么才能作为CDH启动成功的保证

8.安装httpd服务
1.yum install httpd
2.systemctl start httpd 启动httpd服务
systemctl restart ntpd
systemctl stop ntpd
3.ps -ef | grep httpd 查看httpd服务是否启动
4.vim /etc/yum.repos.d/os.repo 以下为文件内容
9.安装 JDK
1.查看CentOS是否已安装的自带openjdk,如果安装了自带openjdk,那么卸载CentOS自带的该openjdk:
(1)查看CentOS已安装的所有软件库:rpm -qa
(2)查看CentOS已安装的自带openjdk:rpm -qa | grep java
比如说查看出CentOS已安装的自带的两个openjdk:
java-1.6.0-openjdk-1.6.0.35-1.13.7.1.el6_6.x86_64
java-1.7.0-openjdk-1.7.0.79-2.5.5.4.el6.x86_64
(3)卸载上述两个CentOS已安装的自带的两个openjdk:
rpm -e java-1.6.0-openjdk-1.6.0.35-1.13.7.1.el6_6.x86_64
rpm -e java-1.7.0-openjdk-1.7.0.79-2.5.5.4.el6.x86_64
或者执行下面卸载命令:
rpm -e --nodeps java-1.6.0-openjdk-1.6.0.35-1.13.7.1.el6_6.x86_64
rpm -e --nodeps java-1.7.0-openjdk-1.7.0.79-2.5.5.4.el6.x86_64
(4)检查是否卸载成功:rpm -qa | grep java
2.方案一:安装Java官方提供的 JDK 1.8
mkdir /usr/local/java
tar zxvf jdk-8u45-linux-x64.tar.gz -C /usr/local/java
scp -r /xx/yy.txt root@IP或域名:/xx/
scp -r /usr/local/java root@node2:/usr/local
scp -r /usr/local/java root@node3:/usr/local
3.方案二:安装CDH官方提供的JDK:oracle-j2sdk1.7-1.7.0+update67-1.x86_64.rpm
1.下载连接:http://archive.cloudera.com/cm5/redhat/7/x86_64/cm/5.16.1/RPMS/x86_64/
2.直接使用 rpm -ivh 命令安装 rpm 文件的方式,默认安装在 /usr/java下
rpm -ivh oracle-j2sdk1.7-1.7.0+update67-1.x86_64.rpm
4.vim /etc/profile 文件中内容如下
JAVA_HOME=/usr/java/jdk1.8.0_141-cloudera
CLASSPATH=.:$JAVA_HOME/lib/tools.jar
PATH=$JAVA_HOME/bin:$PATH
export JAVA_HOME CLASSPATH PATH
5.重新加载profile配置文件,让配置文件生效:source /etc/profile
6.检查是否已配置好新的JDK:java -version
10.CDH之优化Linux底层:
https://www.cloudera.com/documentation/enterprise/latest/topics/cdh_admin_performance.html#cdh_performance__section_nt5_sdf_jq
1.关闭透明大页
禁用透明重复页面(THP)
CDH支持的大多数Linux平台都包含一个名为transparent hugepages的功能,该功能与Hadoop工作负载交互不良,并且可能严重降低性能。
1.执行 cat /sys/kernel/mm/transparent_hugepage/enabled
显示为 [always] madvise never 表示启用
默认情况下,状态为always,需要调整为never
2.vim /etc/default/grub
把 第六行的 GRUB_CMDLINE_LINUX="crashkernel=auto rd.lvm.lv=centos/root rd.lvm.lv=centos/swap rhgb quiet"
修改为 GRUB_CMDLINE_LINUX="rd.lvm.lv=centos/root rd.lvm.lv=centos/swap rhgb quiet transparent_hugepage=never"
3.grub2-mkconfig -o /boot/grub2/grub.cfg
4.reboot
5.重启后 重新执行 cat /sys/kernel/mm/transparent_hugepage/enabled 显示 always madvise [never] 表示禁用
6.在安装CDH如果还提示没有禁用成功的话,请进行如下设置进行禁用:
已启用透明大页面压缩,可能会导致重大性能问题,需要禁用此设置。
请运行“echo never > /sys/kernel/mm/transparent_hugepage/defrag”和“echo never > /sys/kernel/mm/transparent_hugepage/enabled”可以暂时生效
永久生效:将上述两个命令然 添加到/etc/rc.local等初始化脚本中,以便在系统重启时予以设置。
vim /etc/rc.local
echo never > /sys/kernel/mm/transparent_hugepage/defrag
echo never > /sys/kernel/mm/transparent_hugepage/enabled
scp -r /etc/rc.local root@node2:/etc/
scp -r /etc/rc.local root@node3:/etc/
2.设置vm.swappiness Linux内核参数
Linux内核参数, vm.swappiness,是一个0-100的值,用于控制应用程序数据(作为匿名页面)从物理内存到磁盘上的虚拟内存的交换。
值越高,从物理内存中交换出更积极的非活动进程。值越小,交换的次数越少,强制清空文件系统缓冲区。
在大多数系统上, vm.swappiness默认设置为60。这不适用于Hadoop集群,因为即使有足够的可用内存,有时也会交换进程。
这可能会导致重要系统守护程序的冗长垃圾收集暂停,从而影响稳定性和性能。
Cloudera建议您设置 vm.swappiness对于最小交换,值为1到10,优选为1。
1.vim /etc/sysctl.conf 添加 vm.swappiness=1
2.执行激活 sysctl -p 显示 vm.swappiness = 1
查看 cat /proc/sys/vm/swappiness 显示值为 1
3.reboot 重启后 重新查看
3.禁用已调优的服务
1.(无需执行)确保已启动调优服务:systemctl start tuned
2.关闭调优服务:tuned-adm off
3.确保没有活动的配置文件:tuned-adm list 最后一行显示为 No current active profile(无当前活动配置文件)
4.关闭并禁用调优服务:
systemctl stop tuned
systemctl disable tunedMySQL安装,只需要一台主机比如node1安装即可
注意:初始化数据库之前必须先配置 MySQl配置文件my.cnf:vim /etc/my.cnf
11.MySQL
1.第一种方法 安装、配置 MySQL (推荐第三种安装方法)
1.查看系统已安装MySQL:rpm -qa | grep mysql
如果需要卸载已安装的MySQL的话,执行 rpm -e 加上
2.在线安装MySQL:yum install mysql mysql-server mysql-devel
3.启动MySQL服务:/etc/init.d/mysqld start
启动MySQL服务:service mysqld start
4.查看MySQL的运行状态:service mysqld status
查询结果显示MySQL正在运行的结果信息:mysqld (pid 22484) is running...
5.设置MySQL开机启动:chkconfig mysqld on
6.查看“设置MySQL开机启动”是否成功:chkconfig mysqld --list
查询结果显示MySQL为开机启动的结果信息:mysqld 0:off 1:off 2:on 3:on 4:on 5:on 6:off
7.进入MySQL配置密码、远程访问权限:
1.如果没有配置密码,那么只需要执行命令:mysql
2.配置密码:
USE mysql;
UPDATE user SET Password=PASSWORD('admin') WHERE user='root';
FLUSH PRIVILEGES;
3.允许远程登录:
mysql -u root -padmin
GRANT ALL PRIVILEGES ON *.* TO 'root'@'%' IDENTIFIED BY 'admin' WITH GRANT OPTION;
FLUSH PRIVILEGES;
4.重启MySQL:service mysqld restart;
2.第二种方法 安装、配置 MySQL:(推荐第三种安装方法)
1.在/root目录下创建MySQL文件夹:mkdir /root/mysql
2.把64位的MySQL(centOS 6 版本MySQL:MySQL-5.6.25-1.el6.x86_64.rpm-bundle.tar)解压到 /root/mysql目录文件夹下
指定解压到/root/mysql目录下的命令:tar zxvf MySQL-5.6.25-1.el6.x86_64.rpm-bundle.tar -C /root/mysql
3.安装带share的软件、卸载mysql-libs依赖包、安装server和client、并开启服务:
(1)安装带share的软件:rpm -ivh MySQL-shared-*
(2)卸载mysql-libs依赖包:rpm -e mysql-libs
(3)安装server:rpm -ivh MySQL-server-5.6.25-1.el6.x86_64.rpm
(4)安装client:rpm -ivh MySQL-client-5.6.25-1.el6.x86_64.rpm
(5)开启服务:service mysql start
4.查看.mysql_secret配置文件中默认提供的随机用户密码:cat /root/.mysql_secret
5.复制.mysql_secret配置文件中提供的随机用户密码:比如此处随机用户密码为FvL6PYBVUInBK16_
6.登录数据库设置root用户密码并修改权限:
mysql -uroot -pFvL6PYBVUInBK16_
set password = password('admin');
grant all privileges on *.* to 'root' @'%' identified by 'admin';
flush privileges;
exit
7.把3306端口添加到防火墙,注释是不在数据中直接执行下面两句:
/sbin/iptables -I INPUT -p tcp --dport 3306 -j ACCEPT
/etc/rc.d/init.d/iptables save
8.window下连接到CentOS中的数据库,把开发中的数据库表和数据拷贝到CentOS中的数据库中:
把开发中的数据库表和数据导出为SQL文件,然后在window下的“连接到CentOS中的”数据库中创建同名的数据库,
然后执行执行该SQL文件导入数据库表和数据;
3.(推荐)第三种方法 安装、配置 MySQL:(推荐该种安装方法)
1.查看是否安装了自带mysql:rpm -qa | grep mysql
2.把64位的MySQL(centOS 7 版本MySQL:mysql-5.7.24-linux-glibc2.12-x86_64.tar.gz)解压到 /usr/local 目录文件夹下
cd /usr/local
tar zxvf mysql-5.7.24-linux-glibc2.12-x86_64.tar.gz -C /usr/local
mv mysql-5.7.24-linux-glibc2.12-x86_64 /usr/local/mysql
rm -f mysql-5.7.24-linux-glibc2.12-x86_64.tar.gz
3.mkdir -p /usr/local/mysql/data
mkdir -p /usr/local/mysql/database
mkdir -p /usr/local/mysql/data/relay
mkdir -p /usr/local/mysql/data/binlog
mkdir -p /usr/local/mysql/data/tmp
chmod -R 777 /usr/local/mysql/data
touch /usr/local/mysql/data/error.log
touch /usr/local/mysql/data/mysql.sock
touch /usr/local/mysql/data/mysql.pid
4.(可以忽略)创建 mysql 用户组和 mysql 用户 , 把 mysql 目录所有者赋给 mysql 用户
groupadd mysql
useradd -r -g mysql mysql
chown -R mysql:mysql mysql
cd mysql
主目录权限处理(查看是否有就得用户,有删除并新建用户)
查看组和用户情况:cat /etc/group | grep mysql
查看组和用户情况:cat /etc/passwd |grep mysql
若存在,则删除原mysql用户:userdel -r mysql,会删除其对应的组和用户并在次查看。
创建mysql组:groupadd mysql
创建mysql用户:useradd -r -g mysql mysql
修改目录拥有者:chown -R mysql:mysql /usr/local/mysql
5.配置 vim /etc/my.cnf:my.cnf配置看另外一页,先删除原有的所有配置信息,然后添加新的进去
6.初始化数据库 使用 mysqld 安装
cd /usr/local/mysql/bin
root 用户(目前这个用户):./mysqld --initialize --user=root --basedir=/usr/local/mysql --datadir=/usr/local/mysql/database
mysql 用户:./mysqld --initialize --user=mysql --basedir=/usr/local/mysql --datadir=/usr/local/mysql/database
注意:
1.执行上述语句进行初始化时,有可能打印出的显示信息中包括默认的登录密码:root@localhost:(该随机数字字母为自动生成的登录密码)
如果执行上述语句进行初始化时,没有任何打印信息的话,那么cat /usr/local/mysql/data/error.log文件中即能找到:root@localhost:(该随机数字字母为自动生成的登录密码)
2.如果使用随机密码也无法登录mysql的话,那么需要重新执行如下步骤:
1.删除 /usr/local/mysql 目录下的 database文件夹,然后执行 mkdir /usr/local/mysql/database
2.cd /usr/local/mysql/bin
重新初始化 ./mysqld --initialize --user=root --basedir=/usr/local/mysql --datadir=/usr/local/mysql/database
3.service mysql restart重启mysql后,再使用新的随机密码登录mysql
3.如果执行上述语句时报错:./mysqld: error while loading shared libraries: libaio.so.1: cannot open shared object file: No such file or directory
需要安装命令: yum install -y libaio
再执行 ./mysqld --initialize --user=root --basedir=/usr/local/mysql --datadir=/usr/local/mysql/database
7./etc/profile环境变量配置
vim /etc/profile
export PATH="$PATH":/usr/local/sbin:/usr/local/bin:/sbin:/bin:/usr/sbin:/usr/bin
export MYSQL_HOME=/usr/local/mysql
export PATH="$PATH":"$MYSQL_HOME"/bin
source /etc/profile
8.开机服务启动设置:
1.(第一种方法:目前使用这种即可)cp -a /usr/local/mysql/support-files/mysql.server /etc/init.d/mysql
(第二种方法)cp /usr/local/mysql/support-files/mysql.server /etc/init.d/mysqld
2.(第一种方法:目前使用这种即可)chmod 777 /etc/init.d/mysql
(第二种方法)chmod 777 /etc/init.d/mysqld
cd /etc/init.d
ll 查看到有mysql文件
3.chkconfig --list mysql 查看mysql服务是否在服务配置中
最后一行 显示 service mysql supports chkconfig, but is not referenced in any runlevel (run 'chkconfig --add mysql')
翻译为 服务mysql支持chkconfig,但没有在任何运行级别中引用(运行'chkconfig --add mysql')
因此需要把mysql注册为开机启动的服务
(第一种方法:目前使用这种即可)chkconfig --add mysql
(第二种方法)chkconfig --add mysqld
然后再进行查看 chkconfig --list
显示 mysql 0:off 1:off 2:on 3:on 4:on 5:on 6:off
mysqld 0:off 1:off 2:on 3:on 4:on 5:on 6:off
如果看到mysql的服务,并且3,4,5都是on的话则成功,如果是off,则键入
chkconfig --level 2345 mysql on
chkconfig --level 2345 mysqld on
9.mysql服务注册成功后,便可以使用以下命令进行启动 或 停止mysql
service mysql start 显示 Starting MySQL. SUCCESS!
service mysql stop
service mysql status
service mysql restart
或者也可以使用 安全启动 方式
cd /usr/local/mysql/bin
./mysqld_safe --user=root &
查看mysql进程是否启动成功:ps -ef | grep mysql
10.创建快捷方式
(已把mysql的bin目录路径配置到环境变量/etc/profile中后则不需要再创建快捷方式)ln -s /usr/local/mysql/bin/mysql /usr/bin
服务启动后,直接运行 mysql -u root -padmin 即可登录,不需要进入到/usr/local/mysql/bin目录
8.默认登录密码可以在两处地方找到
1.可以在执行初始化数据库语句(./mysqld --initialize)显示的信息中查看到:root@localhost:(该随机数字字母为自动生成的登录密码)
2.可以在 error.log日志(cat /usr/local/mysql/data/error.log)里查看
cat /usr/local/mysql/data/error.log
root@localhost: 后面的随机数字字母就是默认登录密码
如果找不到可能默认是空,登录时无需密码直接回车
3.如果使用随机密码也无法登录mysql的话,那么需要重新执行如下步骤:
1.删除 /usr/local/mysql 目录下的 database文件夹
2.重新初始化 ./mysqld --initialize --user=root --basedir=/usr/local/mysql --datadir=/usr/local/mysql/database
3.service mysql restart重启mysql后,再使用新的随机密码登录mysql
9.登录mysql
cd /usr/local/mysql/bin
./mysql -u root -p(该随机数字字母为自动生成的登录密码)
set password = password('admin');
grant all privileges on *.* to 'root' @'%' identified by 'admin';
flush privileges;
exit
4.建立CM、Hive等需要的表(可以一次性粘贴执行完所有句子)
create database metastore default character set utf8;
CREATE USER 'hive'@'%' IDENTIFIED BY 'password';
GRANT ALL PRIVILEGES ON metastore. * TO 'hive'@'%';
FLUSH PRIVILEGES;
create database cm default character set utf8;
CREATE USER 'cm'@'%' IDENTIFIED BY 'password';
GRANT ALL PRIVILEGES ON cm. * TO 'cm'@'%';
FLUSH PRIVILEGES;
create database am default character set utf8;
CREATE USER 'am'@'%' IDENTIFIED BY 'password';
GRANT ALL PRIVILEGES ON am. * TO 'am'@'%';
FLUSH PRIVILEGES;
create database rm default character set utf8;
CREATE USER 'rm'@'%' IDENTIFIED BY 'password';
GRANT ALL PRIVILEGES ON rm. * TO 'rm'@'%';
FLUSH PRIVILEGES;
create database hue default character set utf8;
CREATE USER 'hue'@'%' IDENTIFIED BY 'password';
GRANT ALL PRIVILEGES ON hue. * TO 'hue'@'%';
FLUSH PRIVILEGES;
create database oozie default character set utf8;
CREATE USER 'oozie'@'%' IDENTIFIED BY 'password';
GRANT ALL PRIVILEGES ON oozie. * TO 'oozie'@'%';
FLUSH PRIVILEGES;
create database sentry default character set utf8;
CREATE USER 'sentry'@'%' IDENTIFIED BY 'password';
GRANT ALL PRIVILEGES ON sentry. * TO 'sentry'@'%';
FLUSH PRIVILEGES;
create database nav_ms default character set utf8;
CREATE USER 'nav_ms'@'%' IDENTIFIED BY 'password';
GRANT ALL PRIVILEGES ON nav_ms. * TO 'nav_ms'@'%';
FLUSH PRIVILEGES;
create database nav_as default character set utf8;
CREATE USER 'nav_as'@'%' IDENTIFIED BY 'password';
GRANT ALL PRIVILEGES ON nav_as. * TO 'nav_as'@'%';
FLUSH PRIVILEGES;
5.jdbc驱动
mkdir -p /usr/share/java
cd /usr/share/java 把 mysql-connector-java-5.1.46.jar 拷贝到该目录下
chmod 777 mysql-connector-java-5.1.46.jar
ln -s mysql-connector-java-5.1.46.jar mysql-connector-java.jar
/etc/my.cnf 不带注释的配置信息
[client]
port = 3306
socket = /usr/local/mysql/data/mysql.sock
default-character-set = utf8mb4
[mysqld]
port = 3306
socket = /usr/local/mysql/data/mysql.sock
pid-file = /usr/local/mysql/data/mysql.pid
basedir = /usr/local/mysql
datadir = /usr/local/mysql/database
tmpdir = /usr/local/mysql/data/tmp
character_set_server = utf8mb4
collation_server = utf8mb4_bin
user = root
log-error=/usr/local/mysql/data/error.log
secure-file-priv = null
log_bin_trust_function_creators = 1
performance_schema = 0
explicit_defaults_for_timestamp
event_scheduler
skip-external-locking
skip-name-resolve
skip-slave-start
slave_net_timeout = 30
local-infile = 0
back_log = 1024
sql_mode = NO_ENGINE_SUBSTITUTION,NO_AUTO_CREATE_USER
key_buffer_size = 32M
max_allowed_packet = 512M
thread_stack = 256K
sort_buffer_size = 16M
read_buffer_size = 16M
join_buffer_size = 16M
read_rnd_buffer_size = 32M
net_buffer_length = 16K
myisam_sort_buffer_size = 128M
bulk_insert_buffer_size = 32M
thread_cache_size = 384
query_cache_size = 0
query_cache_type = 0
tmp_table_size = 1024M
max_heap_table_size = 512M
open_files_limit = 10240
max_connections = 2000
max-user-connections = 0
max_connect_errors = 100000
table_open_cache = 5120
interactive_timeout = 86400
wait_timeout = 86400
binlog_cache_size = 16M
slow_query_log = true
slow_query_log_file = /usr/local/mysql/data/slow_query_log.log
long_query_time = 1
log-slow-admin-statements
log-queries-not-using-indexes
innodb_buffer_pool_size = 128M
innodb_data_file_path = ibdata1:10M:autoextend
innodb_flush_log_at_trx_commit = 2
innodb_read_io_threads = 8
innodb_write_io_threads = 8
innodb_open_files = 1000
innodb_purge_threads = 1
innodb_log_buffer_size = 8M
innodb_log_file_size = 128M
innodb_log_files_in_group = 3
innodb_max_dirty_pages_pct = 75
innodb_buffer_pool_instances = 4
innodb_io_capacity = 500
innodb_file_per_table = 1
innodb_change_buffering = inserts
innodb_adaptive_flushing = 1
transaction-isolation = READ-COMMITTED
innodb_flush_method = fsync
[mysqldump]
quick
max_allowed_packet = 512M
net_buffer_length = 16384
[mysql]
auto-rehash
[isamchk]
key_buffer = 256M
sort_buffer_size = 256M
read_buffer = 2M
write_buffer = 2M
[myisamchk]
key_buffer = 256M
sort_buffer_size = 256M
read_buffer = 2M
write_buffer = 2M
[mysqlhotcopy]
interactive-timeout
/etc/my.cnf 带注释的配置信息
[client]
#客户端设置,即客户端默认的连接参数
port = 3306
#默认连接端口
socket = /usr/local/mysql/data/mysql.sock
#用于本地连接的socket套接字
default-character-set = utf8mb4
#编码
[mysqld]
#服务端基本设置
port = 3306
#MySQL监听端口
socket = /usr/local/mysql/data/mysql.sock
#为MySQL客户端程序和服务器之间的本地通讯指定一个套接字文件
pid-file = /usr/local/mysql/data/mysql.pid
#pid文件所在目录
basedir = /usr/local/mysql
#使用该目录作为根目录(安装目录)
datadir = /usr/local/mysql/database
#数据文件存放的目录
tmpdir = /usr/local/mysql/data/tmp
#MySQL存放临时文件的目录
character_set_server = utf8mb4
#服务端默认编码(数据库级别)
collation_server = utf8mb4_bin
#服务端默认的比对规则,排序规则
user = root
#MySQL启动用户。如果是root用户就配置root,mysql用户就配置mysql
log-error=/usr/local/mysql/data/error.log
#错误日志配置文件(configure file)
secure-file-priv = null
log_bin_trust_function_creators = 1
#开启了binlog后,必须设置这个值为1.主要是考虑binlog安全
#此变量适用于启用二进制日志记录的情况。它控制是否可以信任存储函数创建者,而不是创建将导致
#要写入二进制日志的不安全事件。如果设置为0(默认值),则不允许用户创建或更改存储函数,除非用户具有
#除创建例程或更改例程特权之外的特权
performance_schema = 0
#性能优化的引擎,默认关闭
#ft_min_word_len = 1
#开启全文索引
#myisam_recover
#自动修复MySQL的myisam表
explicit_defaults_for_timestamp
#明确时间戳默认null方式
event_scheduler
#计划任务(事件调度器)
skip-external-locking
#跳过外部锁定;External-locking用于多进程条件下为MyISAM数据表进行锁定
skip-name-resolve
#跳过客户端域名解析;当新的客户连接mysqld时,mysqld创建一个新的线程来处理请求。该线程先检查是否主机名在主机名缓存中。如果不在,线程试图解析主机名。
#使用这一选项以消除MySQL进行DNS解析的时间。但需要注意,如果开启该选项,则所有远程主机连接授权都要使用IP地址方式,否则MySQL将无法正常处理连接请求!
1.这个bind-address强烈推荐不配置
2.如果要配置bind-address的话,这个localhost不能修改,否则在初始化数据库(执行/opt/cloudera/cm/schema/scm_prepare_database.sh mysql cm cm password)时便会报错
如果配置了localhost的话,那么在CDH的安装页面中,配置连接数据库的主机名称必须为localhost
3.强烈不推荐写bind-address=xxx,那么后面的CDH安装对应的组件时要填写的“数据库主机名称”默认使用主机名。
4.如果/etc/my.cnf中配置了bind-address=localhost 的话,那么在CDH的安装页面中,配置连接数据库的主机名称必须为localhost。
缺点:但是在安装hue时,“数据库主机名称”并无法使用localhost或任何主机名,所以造成无法安装hue
5.不配置 bind-address=localhost 的话,则使用主机名(NDOE1)作为此处的数据库主机名称
#bind-address=localhost
#MySQL绑定IP
skip-slave-start
#为了安全起见,复制环境的数据库还是设置--skip-slave-start参数,防止复制随着mysql启动而自动启动
slave_net_timeout = 30
#在中止读取之前等待来自主/从连接的更多数据的秒数。 MySQL主从复制的时候,
#当Master和Slave之间的网络中断,但是Master和Slave无法察觉的情况下(比如防火墙或者路由问题)。
#Slave会等待slave_net_timeout设置的秒数后,才能认为网络出现故障,然后才会重连并且追赶这段时间主库的数据。
#1.用这三个参数来判断主从是否延迟是不准确的Slave_IO_Running,Slave_SQL_Running,Seconds_Behind_Master.还是用pt-heartbeat吧。
#2.slave_net_timeout不要用默认值,设置一个你能接受的延时时间。
local-infile = 0
#设定是否支持命令load data local infile。如果指定local关键词,则表明支持从客户主机读文件
back_log = 1024
#指定MySQL可能的连接数量。当MySQL主线程在很短的时间内得到非常多的连接请求,该参数就起作用,之后主线程花些时间(尽管很短)检查连接并且启动一个新线程。
#back_log参数的值指出在MySQL暂时停止响应新请求之前的短时间内多少个请求可以被存在堆栈中。
#sql_mode = 'PIPES_AS_CONCAT,ANSI_QUOTES,IGNORE_SPACE,NO_KEY_OPTIONS,NO_TABLE_OPTIONS,NO_FIELD_OPTIONS,NO_AUTO_CREATE_USER,NO_ENGINE_SUBSTITUTION'
sql_mode = NO_ENGINE_SUBSTITUTION,NO_AUTO_CREATE_USER
#sql_mode,定义了mysql应该支持的sql语法,数据校验等! NO_AUTO_CREATE_USER:禁止GRANT创建密码为空的用户。
#NO_ENGINE_SUBSTITUTION 如果需要的存储引擎被禁用或未编译,可以防止自动替换存储引擎
key_buffer_size = 32M
#索引块的缓冲区大小,对MyISAM表性能影响最大的一个参数.决定索引处理的速度,尤其是索引读的速度。默认值是16M,通过检查状态值Key_read_requests
#和Key_reads,可以知道key_buffer_size设置是否合理
max_allowed_packet = 512M
#一个查询语句包的最大尺寸。消息缓冲区被初始化为net_buffer_length字节,但是可在需要时增加到max_allowed_packet个字节。
#该值太小则会在处理大包时产生错误。如果使用大的BLOB列,必须增加该值。
#这个值来限制server接受的数据包大小。有时候大的插入和更新会受max_allowed_packet 参数限制,导致写入或者更新失败。
thread_stack = 256K
#线程缓存;主要用来存放每一个线程自身的标识信息,如线程id,线程运行时基本信息等等,我们可以通过 thread_stack 参数来设置为每一个线程栈分配多大的内存。
sort_buffer_size = 16M
#是MySQL执行排序使用的缓冲大小。如果想要增加ORDER BY的速度,首先看是否可以让MySQL使用索引而不是额外的排序阶段。
#如果不能,可以尝试增加sort_buffer_size变量的大小。
read_buffer_size = 16M
#是MySQL读入缓冲区大小。对表进行顺序扫描的请求将分配一个读入缓冲区,MySQL会为它分配一段内存缓冲区。read_buffer_size变量控制这一缓冲区的大小。
#如果对表的顺序扫描请求非常频繁,并且你认为频繁扫描进行得太慢,可以通过增加该变量值以及内存缓冲区大小提高其性能。
join_buffer_size = 16M
#应用程序经常会出现一些两表(或多表)Join的操作需求,MySQL在完成某些 Join 需求的时候(all/index join),为了减少参与Join的“被驱动表”的
#读取次数以提高性能,需要使用到 Join Buffer 来协助完成 Join操作。当 Join Buffer 太小,MySQL 不会将该 Buffer 存入磁盘文件,
#而是先将Join Buffer中的结果集与需要 Join 的表进行 Join 操作,
#然后清空 Join Buffer 中的数据,继续将剩余的结果集写入此 Buffer 中,如此往复。这势必会造成被驱动表需要被多次读取,成倍增加 IO 访问,降低效率。
read_rnd_buffer_size = 32M
#是MySQL的随机读缓冲区大小。当按任意顺序读取行时(例如,按照排序顺序),将分配一个随机读缓存区。进行排序查询时,MySQL会首先扫描一遍该缓冲,以避免磁盘搜索,
#提高查询速度,如果需要排序大量数据,可适当调高该值。但MySQL会为每个客户连接发放该缓冲空间,所以应尽量适当设置该值,以避免内存开销过大。
net_buffer_length = 16K
#通信缓冲区在查询期间被重置到该大小。通常不要改变该参数值,但是如果内存不足,可以将它设置为查询期望的大小。
#(即,客户发出的SQL语句期望的长度。如果语句超过这个长度,缓冲区自动地被扩大,直到max_allowed_packet个字节。)
myisam_sort_buffer_size = 128M
#当对MyISAM表执行repair table或创建索引时,用以缓存排序索引;设置太小时可能会遇到” myisam_sort_buffer_size is too small”
bulk_insert_buffer_size = 32M
#默认8M,当对MyISAM非空表执行insert … select/ insert … values(…),(…)或者load data infile时,使用树状cache缓存数据,每个thread分配一个;
#注:当对MyISAM表load 大文件时,调大bulk_insert_buffer_size/myisam_sort_buffer_size/key_buffer_size会极大提升速度
thread_cache_size = 384
#thread_cahe_size线程池,线程缓存。用来缓存空闲的线程,以至于不被销毁,如果线程缓存在的空闲线程,需要重新建立新连接,
#则会优先调用线程池中的缓存,很快就能响应连接请求。每建立一个连接,都需要一个线程与之匹配。
query_cache_size = 0
#工作原理: 一个SELECT查询在DB中工作后,DB会把该语句缓存下来,当同样的一个SQL再次来到DB里调用时,DB在该表没发生变化的情况下把结果从缓存中返回给Client。
#在数据库写入量或是更新量也比较大的系统,该参数不适合分配过大。而且在高并发,写入量大的系统,建系把该功能禁掉。
query_cache_type = 0
#决定是否缓存查询结果。这个变量有三个取值:0,1,2,分别代表了off、on、demand。
tmp_table_size = 1024M
#它规定了内部内存临时表的最大值,每个线程都要分配。(实际起限制作用的是tmp_table_size和max_heap_table_size的最小值。)
#如果内存临时表超出了限制,MySQL就会自动地把它转化为基于磁盘的MyISAM表,存储在指定的tmpdir目录下
max_heap_table_size = 512M
#独立的内存表所允许的最大容量.# 此选项为了防止意外创建一个超大的内存表导致永尽所有的内存资源.
open_files_limit = 10240
#mysql打开最大文件数
max_connections = 2000
#MySQL无论如何都会保留一个用于管理员(SUPER)登陆的连接,用于管理员连接数据库进行维护操作,即使当前连接数已经达到了max_connections。
#因此MySQL的实际最大可连接数为max_connections+1;
#这个参数实际起作用的最大值(实际最大可连接数)为16384,即该参数最大值不能超过16384,即使超过也以16384为准;
#增加max_connections参数的值,不会占用太多系统资源。系统资源(CPU、内存)的占用主要取决于查询的密度、效率等;
#该参数设置过小的最明显特征是出现”Too many connections”错误;
max-user-connections = 0
#用来限制用户资源的,0不限制;对整个服务器的用户限制
max_connect_errors = 100000
#max_connect_errors是一个MySQL中与安全有关的计数器值,它负责阻止过多尝试失败的客户端以防止暴力破解密码的情况。max_connect_errors的值与性能并无太大关系。
#当此值设置为10时,意味着如果某一客户端尝试连接此MySQL服务器,但是失败(如密码错误等等)10次,则MySQL会无条件强制阻止此客户端连接。
table_open_cache = 5120
#表描述符缓存大小,可减少文件打开/关闭次数;
interactive_timeout = 86400
#interactive_time -- 指的是mysql在关闭一个交互的连接之前所要等待的秒数(交互连接如mysql gui tool中的连接
wait_timeout = 86400
#wait_timeout -- 指的是MySQL在关闭一个非交互的连接之前所要等待的秒数
binlog_cache_size = 16M
#二进制日志缓冲大小
#我们知道InnoDB存储引擎是支持事务的,实现事务需要依赖于日志技术,为了性能,日志编码采用二进制格式。那么,我们如何记日志呢?有日志的时候,就直接写磁盘?
#可是磁盘的效率是很低的,如果你用过Nginx,,一般Nginx输出access log都是要缓冲输出的。因此,记录二进制日志的时候,我们是否也需要考虑Cache呢?
#答案是肯定的,但是Cache不是直接持久化,于是面临安全性的问题——因为系统宕机时,Cache中可能有残余的数据没来得及写入磁盘。因此,Cache要权衡,要恰到好处:
#既减少磁盘I/O,满足性能要求;又保证Cache无残留,及时持久化,满足安全要求。
slow_query_log = true
#开启慢查询
slow_query_log_file = /usr/local/mysql/data/slow_query_log.log
#慢查询地址
long_query_time = 1
#超过的时间为1s;MySQL能够记录执行时间超过参数 long_query_time 设置值的SQL语句,默认是不记录的。
log-slow-admin-statements
log-queries-not-using-indexes
#记录管理语句和没有使用index的查询记录
# 主从复制配置 *****************************************************
# *** Replication related settings ***
binlog_format = ROW
#在复制方面的改进就是引进了新的复制技术:基于行的复制。简言之,这种新技术就是关注表中发生变化的记录,而非以前的照抄 binlog 模式。
#从 MySQL 5.1.12 开始,可以用以下三种模式来实现:基于SQL语句的复制(statement-based replication, SBR),基于行的复制(row-based replication, RBR),混合模式复制(mixed-based replication, MBR)。相应地,binlog的格式也有三种:STATEMENT,ROW,MIXED。MBR 模式中,SBR 模式是默认的。
#max_binlog_cache_size = 102400
# 为每个session 最大可分配的内存,在事务过程中用来存储二进制日志的缓存。
log-bin = /usr/local/mysql/data/binlog/mysql-bin
#开启二进制日志功能,binlog数据位置
log-bin-index = /usr/local/mysql/data/binlog/mysql-bin.index
relay-log = /usr/local/mysql/data/relay/mysql-relay-bin
#relay-log日志记录的是从服务器I/O线程将主服务器的二进制日志读取过来记录到从服务器本地文件,
#然后SQL线程会读取relay-log日志的内容并应用到从服务器
relay-log-index = /usr/local/mysql/data/relay/mysql-relay-bin.index
#binlog传到备机被写道relaylog里,备机的slave sql线程从relaylog里读取然后应用到本地。
# *******************主要配置*********************
# 主服务器配置
server-id = 1
#服务端ID,用来高可用时做区分
#binlog-ignore-db = mysql
#binlog-ignore-db = sys
#binlog-ignore-db = binlog
#binlog-ignore-db = relay
#binlog-ignore-db = tmp
#binlog-ignore-db = test
#binlog-ignore-db = information_schema
#binlog-ignore-db = performance_schema
# 不同步哪些数据库
#binlog-do-db = game
# 只同步哪些数据库,除此之外,其他不同步
# 从服务器配置
#server-id = 2
#服务端ID,用来高可用时做区分
#replicate-ignore-db = mysql
#replicate-ignore-db = sys
#replicate-ignore-db = relay
#replicate-ignore-db = tmp
#replicate-ignore-db = test
#replicate-ignore-db = information_schema
#replicate-ignore-db = performance_schema
# 不同步哪些数据库
#replicate-do-db = game
# 只同步哪些数据库,除此之外,其他不同步
# *******************主要配置*********************
log_slave_updates = 1
#log_slave_updates是将从服务器从主服务器收到的更新记入到从服务器自己的二进制日志文件中。
expire-logs-days = 15
#二进制日志自动删除的天数。默认值为0,表示“没有自动删除”。启动时和二进制日志循环时可能删除。
max_binlog_size = 128M
#如果二进制日志写入的内容超出给定值,日志就会发生滚动。你不能将该变量设置为大于1GB或小于4096字节。 默认值是1GB。
#replicate-wild-ignore-table = mysql.%
#replicate-wild-ignore-table参数能同步所有跨数据库的更新,比如replicate-do-db或者replicate-ignore-db不会同步类似
#replicate-wild-do-table = db_name.%
#设定需要复制的Table
#slave-skip-errors = 1062,1053,1146
#复制时跳过一些错误;不要胡乱使用这些跳过错误的参数,除非你非常确定你在做什么。当你使用这些参数时候,MYSQL会忽略那些错误,
#这样会导致你的主从服务器数据不一致。
auto_increment_offset = 1
auto_increment_increment = 2
#这两个参数一般用在主主同步中,用来错开自增值, 防止键值冲突
relay_log_info_repository = TABLE
#将中继日志的信息写入表:mysql.slave_realy_log_info
master_info_repository = TABLE
#将master的连接信息写入表:mysql.salve_master_info
relay_log_recovery = on
#中继日志自我修复;当slave从库宕机后,假如relay-log损坏了,导致一部分中继日志没有处理,则自动放弃所有未执行的relay-log,
#并且重新从master上获取日志,这样就保证了relay-log的完整性
# 主从复制配置结束 *****************************************************
# *** innodb setting ***
innodb_buffer_pool_size = 128M
#InnoDB 用来高速缓冲数据和索引内存缓冲大小。 更大的设置可以使访问数据时减少磁盘 I/O。
innodb_data_file_path = ibdata1:10M:autoextend
#单独指定数据文件的路径与大小
innodb_flush_log_at_trx_commit = 2
#每次commit 日志缓存中的数据刷到磁盘中。通常设置为 1,意味着在事务提交前日志已被写入磁盘, 事务可以运行更长以及服务崩溃后的修复能力。
#如果你愿意减弱这个安全,或你运行的是比较小的事务处理,可以将它设置为 0 ,以减少写日志文件的磁盘 I/O。这个选项默认设置为 0。
#sync_binlog = 1000
#sync_binlog=n,当每进行n次事务提交之后,MySQL将进行一次fsync之类的磁盘同步指令来将binlog_cache中的数据强制写入磁盘。
innodb_read_io_threads = 8
innodb_write_io_threads = 8
#对于多核的CPU机器,可以修改innodb_read_io_threads和innodb_write_io_threads来增加IO线程,来充分利用多核的性能
innodb_open_files = 1000
#限制Innodb能打开的表的数量
innodb_purge_threads = 1
#开始碎片回收线程。这个应该能让碎片回收得更及时而且不影响其他线程的操作
innodb_log_buffer_size = 8M
#InnoDB 将日志写入日志磁盘文件前的缓冲大小。理想值为 1M 至 8M。大的日志缓冲允许事务运行时不需要将日志保存入磁盘而只到事务被提交(commit)。
#因此,如果有大的事务处理,设置大的日志缓冲可以减少磁盘I/O。
innodb_log_file_size = 128M
#日志组中的每个日志文件的大小(单位 MB)。如果 n 是日志组中日志文件的数目,那么理想的数值为 1M 至下面设置的缓冲池(buffer pool)大小的 1/n。较大的值,
#可以减少刷新缓冲池的次数,从而减少磁盘 I/O。但是大的日志文件意味着在崩溃时需要更长的时间来恢复数据。
innodb_log_files_in_group = 3
#指定有三个日志组
#innodb_lock_wait_timeout = 120
#在回滚(rooled back)之前,InnoDB 事务将等待超时的时间(单位 秒)
innodb_max_dirty_pages_pct = 75
#innodb_max_dirty_pages_pct作用:控制Innodb的脏页在缓冲中在那个百分比之下,值在范围1-100,默认为90.这个参数的另一个用处:
#当Innodb的内存分配过大,致使swap占用严重时,可以适当的减小调整这个值,使达到swap空间释放出来。建义:这个值最大在90%,最小在15%。
#太大,缓存中每次更新需要致换数据页太多,太小,放的数据页太小,更新操作太慢。
innodb_buffer_pool_instances = 4
#innodb_buffer_pool_size 一致 可以开启多个内存缓冲池,把需要缓冲的数据hash到不同的缓冲池中,这样可以并行的内存读写。
innodb_io_capacity = 500
#这个参数据控制Innodb checkpoint时的IO能力
innodb_file_per_table = 1
#作用:使每个Innodb的表,有自已独立的表空间。如删除文件后可以回收那部分空间。
#分配原则:只有使用不使用。但DB还需要有一个公共的表空间。
innodb_change_buffering = inserts
#当更新/插入的非聚集索引的数据所对应的页不在内存中时(对非聚集索引的更新操作通常会带来随机IO),会将其放到一个insert buffer中, #当随后页面被读到内存中时,会将这些变化的记录merge到页中。当服务器比较空闲时,后台线程也会做merge操作
innodb_adaptive_flushing = 1
#该值影响每秒刷新脏页的操作,开启此配置后,刷新脏页会通过判断产生重做日志的速度来判断最合适的刷新脏页的数量;
transaction-isolation = READ-COMMITTED
#数据库事务隔离级别 ,读取提交内容
innodb_flush_method = fsync
#innodb_flush_method这个参数控制着innodb数据文件及redo log的打开、刷写模式
#InnoDB使用O_DIRECT模式打开数据文件,用fsync()函数去更新日志和数据文件。
#innodb_use_sys_malloc = 1
#默认设置值为1.设置为0:表示Innodb使用自带的内存分配程序;设置为1:表示InnoDB使用操作系统的内存分配程序。
[mysqldump]
quick
#它强制 mysqldump 从服务器查询取得记录直接输出而不是取得所有记录后将它们缓存到内存中
max_allowed_packet = 512M
#限制server接受的数据包大小;指代mysql服务器端和客户端在一次传送数据包的过程当中数据包的大小
net_buffer_length = 16384
#TCP/IP和套接字通信缓冲区大小,创建长度达net_buffer_length的行
[mysql]
auto-rehash
#auto-rehash是自动补全的意思
[isamchk]
#isamchk数据检测恢复工具
key_buffer = 256M
sort_buffer_size = 256M
read_buffer = 2M
write_buffer = 2M
[myisamchk]
#使用myisamchk实用程序来获得有关你的数据库桌表的信息、检查和修复他们或优化他们
key_buffer = 256M
sort_buffer_size = 256M
read_buffer = 2M
write_buffer = 2M
[mysqlhotcopy]
interactive-timeout
#mysqlhotcopy使用lock tables、flush tables和cp或scp来快速备份数据库.它是备份数据库或单个表最快的途径,完全属于物理备份,但只能用于备份MyISAM存储引擎和运行在数据库目录所在的机器上.
#与mysqldump备份不同,mysqldump属于逻辑备份,备份时是执行的sql语句.使用mysqlhotcopy命令前需要要安装相应的软件依赖包.
下载方案一(对应安装方案一)。下载方案二(对应安装方案二)。
下载方案一(对应安装方案一):
http://archive.cloudera.com/cdh5/parcels/5.16.1/
CDH-5.16.1-1.cdh5.16.1.p0.3-el7.parcel
CDH-5.16.1-1.cdh5.16.1.p0.3-el7.parcel.sha1(要重命名为CDH-5.16.1-1.cdh5.16.1.p0.3-el7.parcel.sha)
manifest.json
http://archive.cloudera.com/cm5/cm/5/
cloudera-manager-centos7-cm5.16.1_x86_64.tar.gz (该tar.gz文件实际包含了下载方案二中的“cloudera-manager...rpm”的各种rpm文件)
下载方案二(对应安装方案二):
http://archive.cloudera.com/cm5/redhat/7/x86_64/cm/5.16.1/RPMS/x86_64/
(下面的“cloudera-manager...rpm”的各种rpm文件实际被包含在下载方案一中的cloudera-manager-centos7-cm5.16.1_x86_64.tar.gz文件)
cloudera-manager-agent-5.16.1-1.cm5161.p0.1.el7.x86_64.rpm
cloudera-manager-daemons-5.16.1-1.cm5161.p0.1.el7.x86_64.rpm
cloudera-manager-server-5.16.1-1.cm5161.p0.1.el7.x86_64.rpm
cloudera-manager-server-db-2-5.16.1-1.cm5161.p0.1.el7.x86_64.rpm
enterprise-debuginfo-5.16.1-1.cm5161.p0.1.el7.x86_64.rpm
oracle-j2sdk1.7-1.7.0+update67-1.x86_64.rpm
http://archive.cloudera.com/cdh5/parcels/5.16.1/
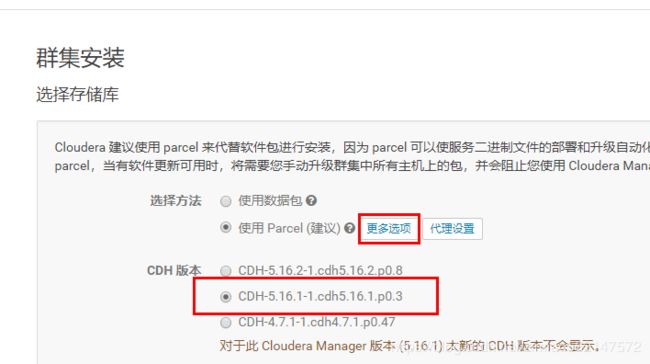
CDH-5.16.1-1.cdh5.16.1.p0.3-el7.parcel
CDH-5.16.1-1.cdh5.16.1.p0.3-el7.parcel.sha1(要重命名为CDH-5.16.1-1.cdh5.16.1.p0.3-el7.parcel.sha)
manifest.json
http://archive.cloudera.com/cm5/installer/5.16.1/
cloudera-manager-installer.bin
每台节点安装CM Server 和 CM Agent的分配方案
主机 CM Server CM Agent
node1主节点 装 装
node2从节点 不装 装
node3从节点 不装 装
安装方案一(对应下载方案一)
安装方案一(对应下载方案一):
主节点和从节点都要解压安装cloudera-manager-centos7-cm5.16.1_x86_64.tar.gz
主节点的parcel仓库目录需要放置 CDH-5.16.1-1.cdh5.16.1.p0.3-el7.parcel、CDH-5.16.1-1.cdh5.16.1.p0.3-el7.parcel.sha、manifest.json
1.主节点
1.mkdir -p /opt/cloudera-manager
tar -zxvf cloudera-manager-centos7-cm5.16.1_x86_64.tar.gz -C /opt/cloudera-manager
mkdir -p /var/cloudera-scm-server
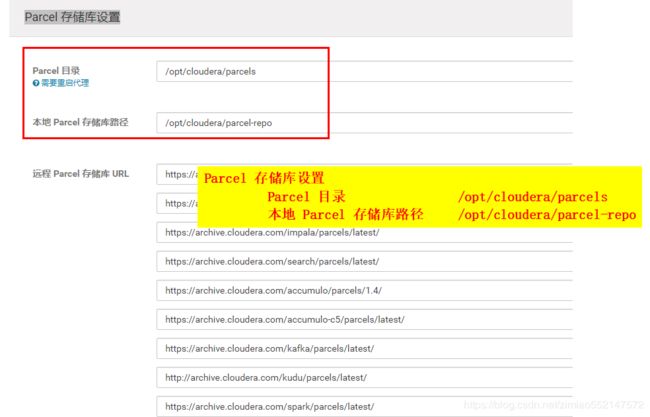
#安装时自动会将主节点的/opt/cloudera/parcel-repo目录中的文件抽取出来,分发解压激活到全部各个节点的/opt/cloudera/parcels目录中
mkdir -p /opt/cloudera/parcel-repo
mkdir -p /opt/cloudera/parcels
2.cd /opt/cloudera/parcel-repo 目录下的安装文件如下
CDH-5.16.1-1.cdh5.16.1.p0.3-el7.parcel
CDH-5.16.1-1.cdh5.16.1.p0.3-el7.parcel.sha
manifest.json
3.#scm_prepare_database.sh mysql -h"mysql数据库所在机器映射域名" -u用户 -p密码 --scm-host "mysql数据库所在机器映射域名" 数据库名 用户 密码
#注意:mysql事先不能存在命令中所指定的数据库名,否则报错已存在,这是CM会自动创建该表的
#执行完 显示All done, your SCM database is configured correctly!
sh /opt/cloudera-manager/cm-5.16.1/share/cmf/schema/scm_prepare_database.sh mysql -hcdh01 -uroot -p123456 --scm-host cdh01 cdh root 123456
4.mkdir -p /opt/cloudera-manager/cm-5.16.1/run/cloudera-scm-agent
cp /opt/cloudera-manager/cm-5.16.1/etc/init.d/cloudera-scm-server /etc/init.d/cloudera-scm-server
cp /opt/cloudera-manager/cm-5.16.1/etc/init.d/cloudera-scm-agent /etc/init.d/cloudera-scm-agent
5.vim /etc/init.d/cloudera-scm-server 修改72行为CMF_DEFAULTS=/opt/cloudera-manager/cm-5.16.1/etc/default
vim /etc/init.d/cloudera-scm-agent 修改74行为CMF_DEFAULTS=/opt/cloudera-manager/cm-5.16.1/etc/default
vim /opt/cloudera-manager/cm-5.16.1/etc/cloudera-scm-agent/config.ini 修改第3行 server_host=cdh01
6.#同时为了保证在每次服务器重启的时候都能启动cloudera-scm-server,应该在开机启动脚本/etc/rc.local中加入如下命令:
vim /etc/rc.local 添加 service cloudera-scm-server restart
service cloudera-scm-agent restart
7.chkconfig cloudera-scm-server on
chkconfig cloudera-scm-agent on
2.从节点
1.mkdir -p /opt/cloudera-manager
tar -zxvf cloudera-manager-centos7-cm5.16.1_x86_64.tar.gz -C /opt/cloudera-manager
#安装时自动会将主节点的/opt/cloudera/parcel-repo目录中的文件抽取出来,分发解压激活到全部各个节点的/opt/cloudera/parcels目录中
mkdir -p /opt/cloudera/parcels
2.mkdir -p /opt/cloudera-manager/cm-5.16.1/run/cloudera-scm-agent
cp /opt/cloudera-manager/cm-5.16.1/etc/init.d/cloudera-scm-agent /etc/init.d/cloudera-scm-agent
3.vim /etc/init.d/cloudera-scm-agent 修改74行为CMF_DEFAULTS=/opt/cloudera-manager/cm-5.16.1/etc/default
vim /opt/cloudera-manager/cm-5.16.1/etc/cloudera-scm-agent/config.ini 修改第3行 server_host=cdh01
4.#同时为了保证在每次服务器重启的时候都能启动cloudera-scm-agent,应该在开机启动脚本/etc/rc.local中加入命令:service cloudera-scm-agent restart
vim /etc/rc.local 添加 service cloudera-scm-agent restart
5.chkconfig cloudera-scm-agent on
3.在CM安装之前必须保证NODE1主节点中的以下程序均已启动
1.每台机器:
根据aliyun提供的服务进行 时间同步:ntpdate -u ntp6.aliyun.com
启动服务 systemctl start ntpd、systemctl restart ntpd
查看是否启动 ps -ef | grep ntpd
开机启动 systemctl enable ntpd.service
查看时间同步状态 ntpstat
查看时间:date 或 timedatectl
2.必须保证MySQL启动了,才能正常启动cm:service mysql start 命令启动mysql
4.主节点执行启动cloudera-scm-server 命令
service cloudera-scm-server start
service cloudera-scm-server restart
service cloudera-scm-server stop
systemctl start cloudera-scm-server
systemctl stop cloudera-scm-server
systemctl restart cloudera-scm-server
5.主节点和从节点分别执行启动cloudera-scm-agent 命令
service cloudera-scm-agent start
service cloudera-scm-agent restart
service cloudera-scm-agent stop
systemctl start cloudera-scm-agent
systemctl stop cloudera-scm-agent
systemctl restart cloudera-scm-agent
6.主节点查看 cloudera-scm-server 状态
systemctl status cloudera-scm-server #正常显示Active: active (running)
ps -ef | grep cloudera-scm-server
netstat -antlp |grep cloudera-scm-server
7.主节点和从节点分别查看 cloudera-scm-agent 状态
systemctl status cloudera-scm-agent #正常显示Active: active (running)
ps -ef | grep cloudera-scm-agent
netstat -antlp |grep cloudera-scm-agent
8.查看cm server 和 server agent 的启动日志 来排除启动失败的报错
cd /var/log/cloudera-scm-server/
cd /var/log/cloudera-scm-agent/
cd /opt/cloudera-manager/cm-5.16.1/log/cloudera-scm-agent
cd /opt/cloudera-manager/cm-5.16.1/log/cloudera-scm-server
9.cm server 和 server agent 的启动日志如果出现以下报错信息
1.报错信息中只要是包含 at com.mysql.jdbc.xxx包 或 com.mysql.jdbc.exceptions 等信息,就表示mysql没启动
2.报错:Failed to connect to previous supervisor
ps ax | fgrep supervisord 把可能以前的 supervisord 进程kill掉,然后重启cloudera-scm-server、cloudera-scm-agent
10.cloudera-scm-server 默认使用的端口 7180,那么就可以通过 192.168.88.100:7180/cmf/login 访问 CM
1.netstat -lnpt | grep 7180 显示 tcp 0 0 0.0.0.0:7180 0.0.0.0:* LISTEN 68289/java
启动之后需要一段时间才能完全整个启动(一般一分钟之内),才可以访问得到 192.168.88.100:7180/cmf/login
2.cloudera-scm-server 默认使用的端口 7180,那么就可以通过 IP:7180/cmf/login 访问 CM
netstat -lnpt | grep 7180
netstat -lnpt | grep 7182
netstat -an | grep 7180
netstat -an | grep 7182
安装方案二(对应下载方案二):
1.主节点和从节点都要安装以下CM Agent的安装包+JDK
rpm -ivh cloudera-manager-agent-5.16.1-1.cm5161.p0.1.el7.x86_64.rpm
rpm -ivh cloudera-manager-daemons-5.16.1-1.cm5161.p0.1.el7.x86_64.rpm
rpm -ivh enterprise-debuginfo-5.16.1-1.cm5161.p0.1.el7.x86_64.rpm
rpm -ivh oracle-j2sdk1.7-1.7.0+update67-1.x86_64.rpm
2.主节点要安装CM Server的安装包
rpm -ivh cloudera-manager-server-5.16.1-1.cm5161.p0.1.el7.x86_64.rpm
rpm -ivh cloudera-manager-server-db-2-5.16.1-1.cm5161.p0.1.el7.x86_64.rpm
3.修改数据库配置文件/etc/cloudera-scm-server/db.properties 先备份后修改,然后创建一个utf8的数据库名cmf
com.cloudera.cmf.db.type=mysql
com.cloudera.cmf.db.host=mysql所安装的机器的主机名node1
com.cloudera.cmf.db.name=数据库名cmf
com.cloudera.cmf.db.user=用户名root
com.cloudera.cmf.db.password=密码123456
com.cloudera.cmf.db.setupType=EXTERNAL
4.在CM安装之前必须保证NODE1主节点中的以下程序均已启动
1.每台机器:
根据aliyun提供的服务进行 时间同步:ntpdate -u ntp6.aliyun.com
启动服务 systemctl start ntpd、systemctl restart ntpd
查看是否启动 ps -ef | grep ntpd
开机启动 systemctl enable ntpd.service
查看时间同步状态 ntpstat
查看时间:date 或 timedatectl
2.必须保证MySQL启动了,才能正常启动cm:service mysql start 命令启动mysql
5.主节点执行启动cloudera-scm-server 命令
service cloudera-scm-server start
service cloudera-scm-server restart
service cloudera-scm-server stop
systemctl start cloudera-scm-server
systemctl stop cloudera-scm-server
systemctl restart cloudera-scm-server
6..主节点和从节点分别执行启动cloudera-scm-agent 命令
service cloudera-scm-agent start
service cloudera-scm-agent restart
service cloudera-scm-agent stop
systemctl start cloudera-scm-agent
systemctl stop cloudera-scm-agent
systemctl restart cloudera-scm-agent
7.主节点查看 cloudera-scm-server 状态
systemctl status cloudera-scm-server #正常显示Active: active (running)
ps -ef | grep cloudera-scm-server
netstat -antlp |grep cloudera-scm-server
8.主节点和从节点分别查看 cloudera-scm-agent 状态
systemctl status cloudera-scm-agent #正常显示Active: active (running)
ps -ef | grep cloudera-scm-agent
netstat -antlp |grep cloudera-scm-agent
9.查看cm server 和 server agent 的启动日志 来排除启动失败的报错
cd /var/log/cloudera-scm-server/
cd /var/log/cloudera-scm-agent/
cd /opt/cloudera-manager/cm-5.16.1/log/cloudera-scm-agent
cd /opt/cloudera-manager/cm-5.16.1/log/cloudera-scm-server
10.cm server 和 server agent 的启动日志如果出现以下报错信息
1.报错信息中只要是包含 at com.mysql.jdbc.xxx包 或 com.mysql.jdbc.exceptions 等信息,就表示mysql没启动
2.报错:Failed to connect to previous supervisor
ps ax | fgrep supervisord 把可能以前的 supervisord 进程kill掉,然后重启cloudera-scm-server、cloudera-scm-agent
11.cloudera-scm-server 默认使用的端口 7180,那么就可以通过 192.168.88.100:7180/cmf/login 访问 CM
1.netstat -lnpt | grep 7180 显示 tcp 0 0 0.0.0.0:7180 0.0.0.0:* LISTEN 68289/java
启动之后需要一段时间才能完全整个启动(一般一分钟之内),才可以访问得到 192.168.88.100:7180/cmf/login
2.cloudera-scm-server 默认使用的端口 7180,那么就可以通过 IP:7180/cmf/login 访问 CM
netstat -lnpt | grep 7180
netstat -lnpt | grep 7182
netstat -an | grep 7180
netstat -an | grep 7182











mkdir -p /opt/kudu/master/wal
mkdir -p /opt/kudu/master/data
mkdir -p /opt/kudu/master/logs
mkdir -p /opt/kudu/tserver/wal
mkdir -p /opt/kudu/tserver/data
mkdir -p /opt/kudu/tserver/logs
chown -R kudu:kudu /opt/kuduHDFS
1.namenode格式化:主节点node1 执行 hadoop namenode -format 或 hdfs namenode -format 即可。
当启动HDFS时报错:java.io.IOException: NameNode is not formatted.时候就必须进行namenode格式化。
2.当启动HDFS时报错:
Only one image storage directory (dfs.namenode.name.dir) configured. Beware of data loss due to lack of redundant storage directories!
Only one namespace edits storage directory (dfs.namenode.edits.dir) configured. Beware of data loss due to lack of redundant storage directories!
解决:CM页面搜索 dfs.namenode.name.dir 增加路径 /dfs/namenode/name/dir
CM页面搜索 dfs.namenode.edits.dir 增加路径 /dfs/namenode/edits/dir
然后全部节点都创建上述目录 mkdir -p /dfs/namenode/name/dir、mkdir -p /dfs/namenode/edits/dir
3.当启动HDFS时报错:/dfs/nn/current/VERSION (权限不够)
解决:全部节点执行 chmod 777 -R /dfs
4.当启动HDFS时报错:
Failed to add storage directory [DISK]file:/dfs/dn/
java.io.IOException: Incompatible clusterIDs in /dfs/dn: namenode clusterID = CID-fde0f405-b07d-4d35-97fe-b1fb1d4c0f14; datanode clusterID = cluster4
原因:该问题因为多次对namenode进行format,每一次format主节点NameNode产生新的clusterID、namespaceID,
于是导致主节点的clusterID、namespaceID与各个子节点DataNode不一致。当format过后再启动hadoop,hadoop尝试创建新的current目录,
但是由于已存在current目录,导致创建失败,最终引起DataNode节点的DataNode进程启动失败,从而引起hadoop集群完全启动失败。
因此可以通过直接删除数据节点DataNode的current文件夹,进行解决该问题。
解决:删除每个节点下/dfs/dn/目录中的current文件夹,然后重新启动HDFS,自动会重新创建current文件夹
5.当启动HDFS时报错:Canary 测试无法为 /tmp/.cloudera_health_monitoring_canary_files 创建父目录。
原因:经过查看日志,发现 Name node is in safe mode.
解决:第一步:CM页面搜索 dfs.permissions 检查 HDFS 权限
操作:关闭权限检查,选择不勾选。
如果不取消HDFS权限的话,那么当执行下面的hdfs dfsadmin -safemode leave命令时便会报错:safemode: Access denied for user root. Superuser privilege is required

第二步:hdfs dfsadmin -safemode leave,然后重启HDFS,注意可能还要等一段时间CDH才会重新显示hive为正常(绿色)
找不到hdfs命令可以到cd /opt/cloudera/parcels/CDH-5.16.1-1.cdh5.16.1.p0.3/bin目录下便有对应的命令文件。
hdfs dfsadmin -safemode enter 进入安全模式
hdfs dfsadmin -safemode get 获取模式状态。Safe mode is OFF表示安全模式关闭。
hdfs dfsadmin -safemode leave 强制离开安全模式
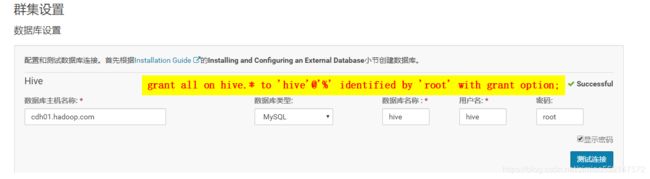
Hive
1.cd /opt/cloudera/parcels/CDH-5.16.1-1.cdh5.16.1.p0.3/lib/hive/conf 或 cd /etc/hive/conf
2.修改每台机器节点下的 hive-site.xml
如果每台机器节点下的 hive-site.xml 中配置了以下的derby连接信息请删除掉
javax.jdo.option.ConnectionURL
jdbc:derby:;databaseName=metastore_db;create=true
javax.jdo.option.ConnectionDriverName
org.apache.derby.jdbc.EmbeddedDriver
3.每台机器节点下的 hive-site.xml 增加如下mysql的连接信息
javax.jdo.option.ConnectionURL
jdbc:mysql://IP:3306/hive?createDatabaseIfNotExist=true
JDBC connect string for a JDBC metastore
javax.jdo.option.ConnectionDriverName
com.mysql.jdbc.Driver
Driver class name for a JDBC metastore
javax.jdo.option.ConnectionUserName
MySQL用户名
username to use against metastore database
javax.jdo.option.ConnectionPassword
MySQL用户对应的密码
password to use against metastore database
4. vim /etc/profile 添加 HADOOP_HOME 路径信息
export HADOOP_HOME=/opt/cloudera/parcels/CDH-5.16.1-1.cdh5.16.1.p0.3/lib/hadoop
export PATH=$JAVA_HOME/bin:$HADOOP_HOME/bin
重新加载:source /etc/profile
5.执行命令 schematool -initSchema -dbType mysql 初始化hive的元数据库。
如果执行上述schematool命令报错 -bash: schematool: command not found 表示找不到schematool 命令的话,
可以到 cd /opt/cloudera/parcels/CDH-5.16.1-1.cdh5.16.1.p0.3/lib/hive/bin 目录下便有对应的schematool 命令文件。
执行命令后打印出如下信息:
Metastore connection URL:jdbc:mysql://IP:3306/hive?createDatabaseIfNotExist=true
Metastore Connection Driver:com.mysql.jdbc.Driver
Metastore connection User:root
6.最终mysql中的hive数据库自动生成出一系列对应的hive相关表

Kafka安装
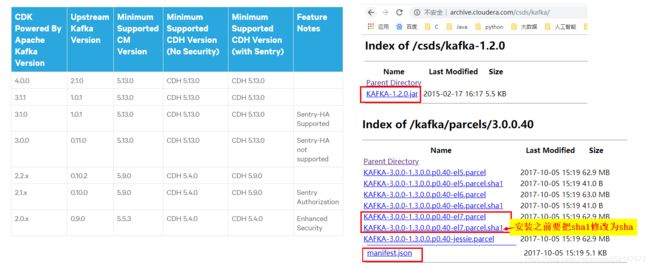
1.kafka下载连接
1.http://archive.cloudera.com/csds/kafka/
下载 KAFKA-1.2.0.jar
2.我的CDH版本是5.16.1+CentOS7,因此此处根据下面版本对应表选择一个比较相近的kafka3.0.0的el7版本
http://archive.cloudera.com/kafka/parcels/3.0.0/
下载 KAFKA-3.0.0-1.3.0.0.p0.40-el7.parcel
KAFKA-3.0.0-1.3.0.0.p0.40-el7.parcel.sha1(安装之前要把sha1修改为sha)
manifest.json
2.查看kafka和CDH对应版本:https://www.cloudera.com/documentation/enterprise/release-notes/topics/rn_consolidated_pcm.html#pcm_kafka

以下安装步骤操作只需要node1主节点进行:
1.将 KAFKA-1.2.0.jar 放到 /opt/cloudera/csd 下
#创建csd的存放路径
mkdir -p /opt/cloudera/csd
#修改用户用户组权限
chown cloudera-scm:cloudera-scm /opt/cloudera/csd
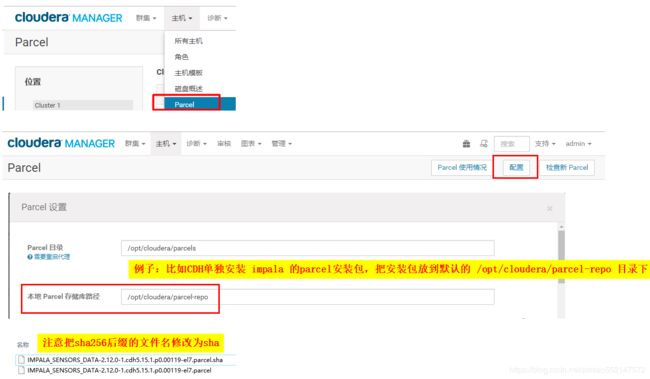
2.把 KAFKA-3.0.0-1.3.0.0.p0.40-el7.parcel.sha1 修改为 KAFKA-3.0.0-1.3.0.0.p0.40-el7.parcel.sha
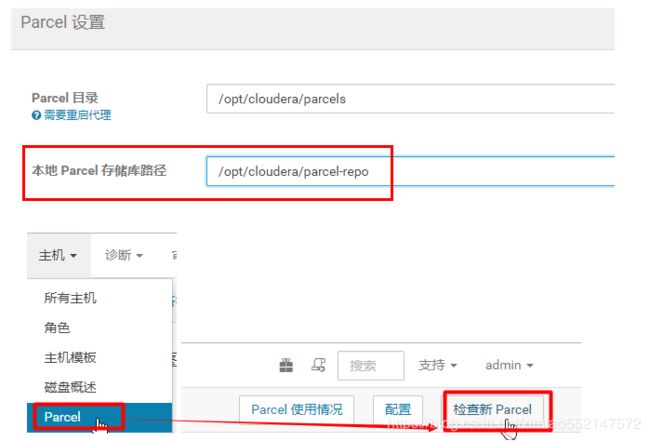
3.将 KAFKA-3.0.0-1.3.0.0.p0.40-el7.parcel 和 KAFKA-3.0.0-1.3.0.0.p0.40-el7.parcel.sha 放到 /opt/cloudera/parcel-repo
根据你的Parcel设置中的“本地Parcel存储库路径”配置的路径来放置parcel安装包。
4.在CM管理页面重启cm服务接口,然后再开始分配
5.如果出现报错信息:分配时出错 Src file /opt/cloudera/parcels/.flood
解决:首先删除每台机器下的.flood文件夹,然后主节点重启 systemctl restart cloudera-scm-server,然后主机点和从节点都重启 systemctl restart cloudera-scm-agent
6.激活
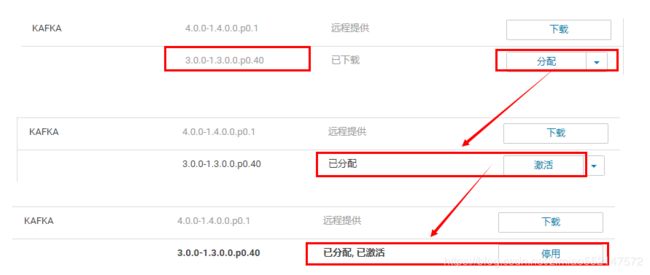

展示所有topic主题名:kafka-topics --list --zookeeper cdh01:2181
创建topic:kafka-topics --create --zookeeper cdh01:2181 --replication-factor 3 --partitions 3 --topic test
查看指定topic:kafka-topics --describe --zookeeper cdh01:2181 --topic bigdata-topic
查看所有topic:kafka-topics --describe --zookeeper cdh01:2181
生产者:kafka-console-producer --broker-list cdh01:9092 --topic test
修改topic的分区数:kafka-topics --zookeeper cdh01:2181 --alter --partitions 3 --topic test
消费者:
旧版:kafka-console-consumer --zookeeper cdh01:2181 --topic test --from-beginning
新版:kafka-console-consumer --bootstrap-server cdh01:9092 --topic test --from-beginning
kafka-console-consumer --bootstrap-server cdh01:9092,cdh02:9092,cdh03:9092 --topic bigdata-topic
指定消费者组:kafka-console-consumer --bootstrap-server cdh01:9092 --group testGroup --topic test --from-beginning
删除topic:kafka-topics --delete --zookeeper cdh01:2181 --topic test
查看消费位置,指定消费者组:
kafka-consumer-groups --bootstrap-server cdh01:9092 --describe --group testGroup
kafka-consumer-groups --bootstrap-server cdh01:9092 --describe --group testGroup --all-topics
1.如果执行删除topice的命令后,然后执行展示所有topic主题名的命令后,仍然显示没有被删除掉的topic的话,此时的删除并不是真正的删除,只是把topic标记为:marked for deletion
如下图所示:topic主题名 - marked for deletion
events_test - marked for deletion
t1119 - marked for deletion
2.解决1:修改kafaka配置文件server.properties,添加delete.topic.enable=true,重启kafka
3.解决2:CM页面中的kafka组件中的配置搜索delete.topic.enable,然后勾选,重启kafka和重新部署配置
4.解决3:进入zk shell:zookeeper-client。然后 ls /brokers/topics,打印出[events_test, t1119],然后执行 rmr /brokers/topics/topic主题名。
rmr /brokers/topics/events_test
rmr /brokers/topics/t1119
5.解决3:删除kafka存储目录,可通过server.properties文件log.dirs属性配置的路径值得知kafka存储目录:log.dirs:/var/local/kafka/data
Oozie安装
打开Oozie的web ui页面如下提示报错
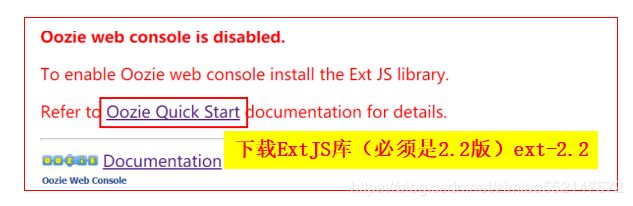

1.只需要在 oozie service 所在的 node1节点 配置即可
2.下载ExtJS库(必须是2.2版)ext-2.2 下载地址 http://archive.cloudera.com/gplextras/misc/ext-2.2.zip
3.yum install unzip
4.把 mysql-connector-java.jar 和 ext-2.2.zip 也放到 /var/lib/oozie 或 /opt/cloudera/parcels/CDH-5.16.1-1.cdh5.16.1.p0.3/lib/oozie/libext 的目录中
5.unzip /var/lib/oozie/ext-2.2.zip -d /var/lib/oozie
6.chown -R oozie:oozie /var/lib/oozie/ext-2.2 或 chown -R oozie:oozie /opt/cloudera/parcels/CDH-5.16.1-1.cdh5.16.1.p0.3/lib/oozie/libext/ext-2.2
7.chown -R oozie:oozie /var/lib/oozie/ext-2.2.zip 或 chown -R oozie:oozie /opt/cloudera/parcels/CDH-5.16.1-1.cdh5.16.1.p0.3/lib/oozie/libext/ext-2.2.zip
8.因为 /opt/cloudera/parcels/CDH-5.16.1-1.cdh5.16.1.p0.3/lib/oozie/libext 软连接到 /var/lib/oozie目录中,所以当在 libext 目录中解压 ext-2.2.zip时,
会自动在 /var/lib/oozie目录中 也同步一份 ext-2.2。如果是手动安装oozie的话,那么是不存在libext文件夹的,所以也需要 mkdir libext
Hue安装
Impala安装
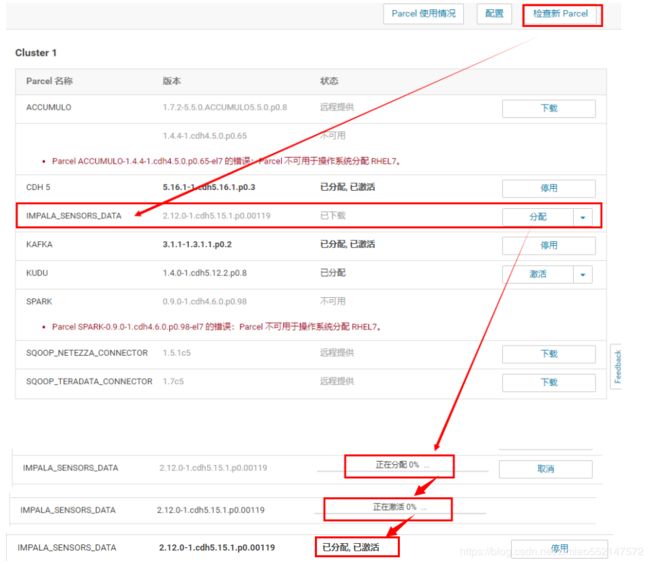
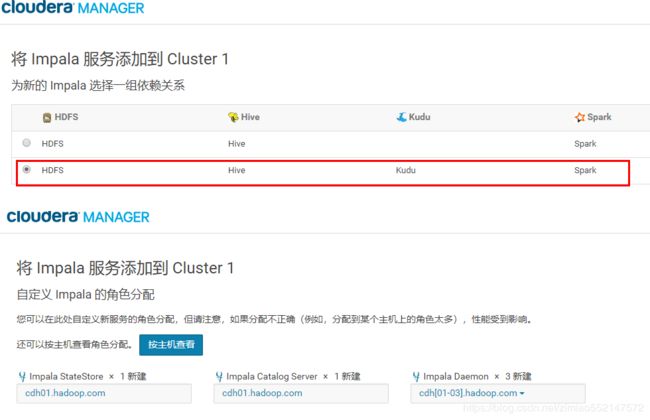
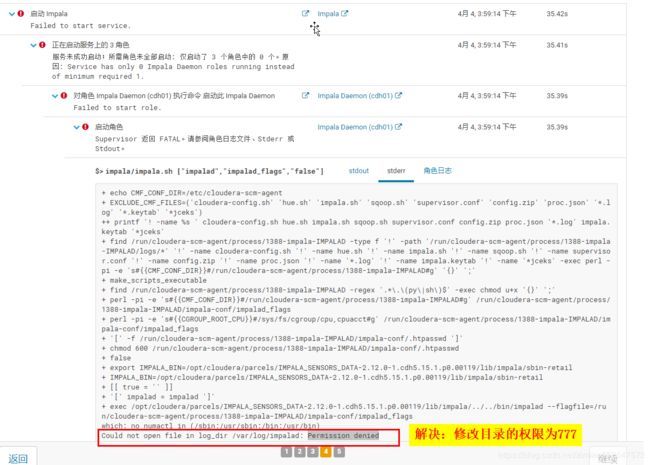
注意可以直接CM页面安装,此处举例使用另外的方式通过parcel安装包的方式安装Impala

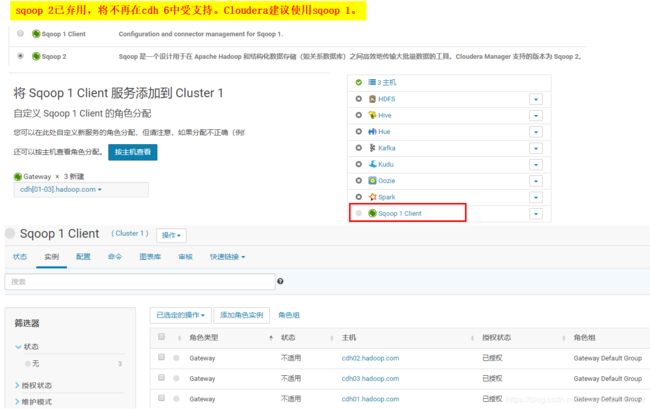
Sqoop 1 Client、Sqoop 2
1.sqoop help
2.sqoop import \
--connect jdbc:mysql://192.168.20.41:3306/adm \
--username root \
--password admin \
--table userPortraitComplete \
--hive-table adm.userPortraitComplete \
--hive-import \
--m 1
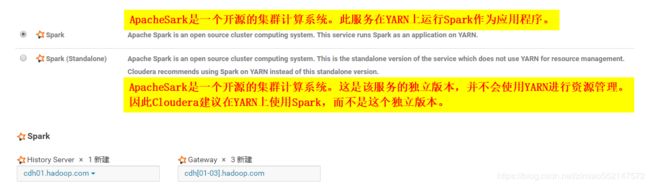
Spark

1.scala所有版本:https://www.scala-lang.org/download/all.html
可在maven 仓库中搜索spark便可以看到在某个spark相关包下的spark和scala的对应版本:https://mvnrepository.com/artifact/org.apache.spark/spark-core
2.11.0版本:https://www.scala-lang.org/download/2.11.0.html
2.每台机器都安装 scala-2.11.0
cd /usr/local
tar -zxvf scala-2.11.0.tgz
mv scala-2.11.0 scala
3.配置环境变量,将scala加入到PATH中:
vim /etc/profile 主要添加蓝色字体处配置信息
export SCALA_HOME=/usr/local/scala
export PATH=$PATH:$JAVA_HOME/bin:$SCALA_HOME/bin
或者
export PATH=$PATH:$JAVA_HOME/bin:/usr/local/scala/bin
或者
PATH=$JAVA_HOME/bin:$PATH:/usr/local/scala/bin
export JAVA_HOME CLASSPATH PATH
重新加载 source /etc/profile
4.scala的命令行模式:
输入 scala ,执行1+1,输出结果2
5.查看版本号:
scala -version
Scala code runner version 2.11.0 -- Copyright 2002-2013, LAMP/EPFL
当启动spark报错如下:
Caused by: java.lang.IllegalArgumentException: Log directory specified does not exist: hdfs://cdh01.hadoop.com:8020/user/spark/applicationHistory
原因:根据报错信息可知hdfs路径下缺少/user/spark/applicationHistory这个路径的文件夹
解决:sudo -u hdfs hadoop fs -mkdir /user/spark
sudo -u hdfs hadoop fs -mkdir /user/spark/applicationHistory
sudo -u hdfs hadoop fs -chown -R spark:spark /user/spark
sudo -u hdfs hadoop fs -chmod 777 /user/spark/applicationHistory
报错解决
1.当找不到CDH中这些每个组件的命令时,全部机器节点下的profile文件进行如下配置
vim /etc/profile
export CDH_HOME=/opt/cloudera/parcels/CDH-5.16.1-1.cdh5.16.1.p0.3
export PATH=$JAVA_HOME/bin:$CDH_HOME/bin
source /etc/profile
2.当启动kudu时报错:Call to mkstemp() failed on name template /home/data/kudutable/fs_data_dirs/instance.kudutmp.XXXXXX: Permission denied (error 13)
解决:1.全部机器节点下的/home/data-c和/home/data下的kudumaster和kudutable目录及其目录下的所有文件 都赋予777权限
cd /home/data-c
chmod 777 -R kudumaster
chown 777 -R kudutable
cd /home/data
chown 777 -R kudumaster
chown 777 -R kudutable
2.全部机器节点下的/home/data-c和/home/data下的kudumaster和kudutable目录的所属用户和用户组修改为kudu:kudu
cd /home/data-c
chown -R kudu:kudu kudumaster
chown -R kudu:kudu kudutable
cd /home/data
chown -R kudu:kudu kudumaster
chown -R kudu:kudu kudutable
3.当启动kudu时报错:
Unable to init master catalog manager: Not found
Unable to initialize catalog manager: Failed to initialize sys tables async
Unable to load consensus metadata for tablet 00000000000000000000000000000000
Unable to load consensus metadata for tablet 00000000000000000000000000000000
/home/data/kudumaster/fs_wal_dir/consensus-meta/00000000000000000000000000000000: No such file or directory (error 2)
Check failed: _s.ok() Bad status: Not found
Unable to initialize catalog manager: Failed to initialize sys tables async
Unable to load consensus metadata for tablet 00000000000000000000000000000000
Unable to load consensus metadata for tablet 00000000000000000000000000000000: /home/data/kudumaster/fs_wal_dir/consensus-meta/00000000000000000000000000000000: No such file or directory (error 2)
解决:1.可以在CM管理页面中的Kudu组件的配置中搜索 Kudu Master WAL Directory 和 Kudu Master Data Directories 和 Kudu Tablet Server WAL Directory 和
Kudu Tablet Server Data Directories 属性值所对应路径下,把该些路径下的文件全部删除,记住是所有节点下的该些路径下都存在文件。
2.重新启动Kudu服务
3.如果上述方法都不行的话,删除Kudu组件,重新添加Kudu服务到集群中,然后全部节点下执行以下命令
mkdir -p /opt/kudu/master/wal
mkdir -p /opt/kudu/master/data
mkdir -p /opt/kudu/master/logs
mkdir -p /opt/kudu/tserver/wal
mkdir -p /opt/kudu/tserver/data
mkdir -p /opt/kudu/tserver/logs
chown -R kudu:kudu /opt/kudu
3.在添加Kudu时的配置页面中根据对应属性进行以下配置
Kudu Master WAL Directory:/opt/kudu/master/wal
Kudu Master Data Directories:/opt/kudu/master/data
Kudu Tablet Server WAL Directory:/opt/kudu/tserver/wal
Kudu Tablet Server Data Directories:/opt/kudu/tserver/data
4.当启动HDFS时报错:java.io.IOException: NameNode is not formatted.
解决:主节点node1 执行 hadoop namenode -format 或 hdfs namenode -format 即可
5.当启动HDFS时报错:
Only one image storage directory (dfs.namenode.name.dir) configured. Beware of data loss due to lack of redundant storage directories!
Only one namespace edits storage directory (dfs.namenode.edits.dir) configured. Beware of data loss due to lack of redundant storage directories!
解决:CM页面搜索 dfs.namenode.name.dir 增加路径 /dfs/namenode/name/dir
CM页面搜索 dfs.namenode.edits.dir 增加路径 /dfs/namenode/edits/dir
然后全部节点都创建上述目录 mkdir -p /dfs/namenode/name/dir、mkdir -p /dfs/namenode/edits/dir
6.当启动HDFS时报错:/dfs/nn/current/VERSION (权限不够)
解决:全部节点执行 chmod 777 -R /dfs
7.当启动HDFS时报错:
Failed to add storage directory [DISK]file:/dfs/dn/
java.io.IOException: Incompatible clusterIDs in /dfs/dn: namenode clusterID = CID-fde0f405-b07d-4d35-97fe-b1fb1d4c0f14; datanode clusterID = cluster4
原因:该问题因为多次对namenode进行format,每一次format主节点NameNode产生新的clusterID、namespaceID,
于是导致主节点的clusterID、namespaceID与各个子节点DataNode不一致。当format过后再启动hadoop,hadoop尝试创建新的current目录,
但是由于已存在current目录,导致创建失败,最终引起DataNode节点的DataNode进程启动失败,从而引起hadoop集群完全启动失败。
因此可以通过直接删除数据节点DataNode的current文件夹,进行解决该问题。
解决:删除每个节点下/dfs/dn/目录中的current文件夹,然后重新启动HDFS,自动会重新创建current文件夹
8.当启动HDFS时报错:Canary 测试无法为 /tmp/.cloudera_health_monitoring_canary_files 创建父目录。
原因:经过查看日志,发现 Name node is in safe mode.
解决:第一步:CM页面搜索 dfs.permissions 检查 HDFS 权限
操作:关闭权限检查,选择不勾选。
如果不取消HDFS权限的话,那么当执行下面的hdfs dfsadmin -safemode leave命令时便会报错:safemode: Access denied for user root. Superuser privilege is required
第二步:hdfs dfsadmin -safemode leave,然后重启HDFS,注意可能还要等一段时间CDH才会重新显示hive为正常(绿色)
找不到hdfs命令可以到cd /opt/cloudera/parcels/CDH-5.16.1-1.cdh5.16.1.p0.3/bin目录下便有对应的命令文件。
hdfs dfsadmin -safemode enter 进入安全模式
hdfs dfsadmin -safemode get 获取模式状态。Safe mode is OFF表示安全模式关闭。
hdfs dfsadmin -safemode leave 强制离开安全模式
9.当启动Hive时报错:
Self-test query [select "DB_ID" from "DBS"] failed; direct SQL is disabled
javax.jdo.JDODataStoreException: Error executing SQL query "select "DB_ID" from "DBS"".
com.mysql.jdbc.exceptions.jdbc4.MySQLSyntaxErrorException: Table 'hive.DBS' doesn't exist
解决:执行 schematool -initSchema -dbType mysql 初始化hive的元数据库。
如果执行上述schematool命令报错 -bash: schematool: command not found 表示找不到schematool 命令的话,
可以到 cd /opt/cloudera/parcels/CDH-5.16.1-1.cdh5.16.1.p0.3/lib/hive/bin 目录下便有对应的schematool 命令文件。
问题:如果执行 schematool -initSchema -dbType mysql 命令时报错如下:Cannot find hadoop installation: $HADOOP_HOME or $HADOOP_PREFIX must be set or hadoop must be in the path
解决:vim /etc/profile
export HADOOP_HOME=/opt/cloudera/parcels/CDH-5.16.1-1.cdh5.16.1.p0.3/lib/hadoop
export PATH=$JAVA_HOME/bin:$HADOOP_HOME/bin
source /etc/profile
问题:如果执行 schematool -initSchema -dbType mysql 命令时报错如下:org.apache.hadoop.hive.metastore.HiveMetaException: Schema initialization FAILED! Metastore state would be inconsistent !!
原因:看到执行schematool -initSchema -dbType mysql命令所显示出来的信息包含了以下:
Metastore connection URL:jdbc:derby:;databaseName=metastore_db;create=true
Metastore Connection Driver:org.apache.derby.jdbc.EmbeddedDriver
解决:1.cd /opt/cloudera/parcels/CDH-5.16.1-1.cdh5.16.1.p0.3/lib/hive/conf 或 cd /etc/hive/conf
2.修改每台机器节点下的 hive-site.xml
3.如果每台机器节点下的 hive-site.xml 中配置了以下的derby连接信息请删除掉
javax.jdo.option.ConnectionURL
jdbc:derby:;databaseName=metastore_db;create=true
javax.jdo.option.ConnectionDriverName
org.apache.derby.jdbc.EmbeddedDriver
4.每台机器节点下的 hive-site.xml 增加如下mysql的连接信息
javax.jdo.option.ConnectionURL
jdbc:mysql://IP:3306/hive?createDatabaseIfNotExist=true
JDBC connect string for a JDBC metastore
javax.jdo.option.ConnectionDriverName
com.mysql.jdbc.Driver
Driver class name for a JDBC metastore
javax.jdo.option.ConnectionUserName
MySQL用户名
username to use against metastore database
javax.jdo.option.ConnectionPassword
MySQL用户对应的密码
password to use against metastore database
5.再次重新执行schematool -initSchema -dbType mysql 命令时,就会出现以下信息
Metastore connection URL:jdbc:mysql://IP:3306/hive?createDatabaseIfNotExist=true
Metastore Connection Driver:com.mysql.jdbc.Driver
Metastore connection User:root
6.最终mysql中的hive数据库自动生成出一系列对应的hive相关表
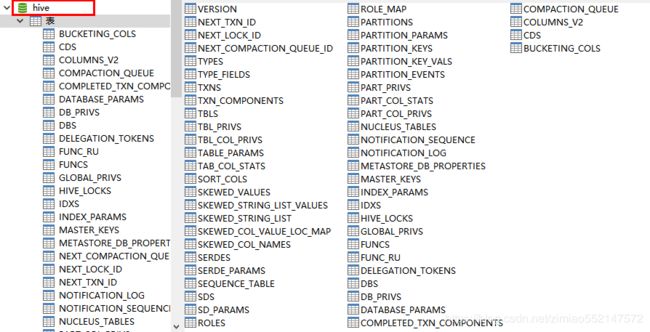
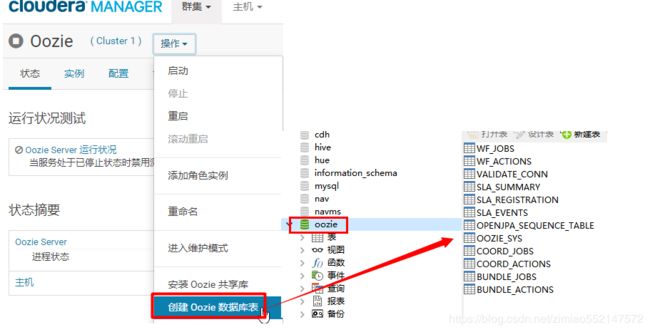
10.当启动oozie报错如下:Table 'oozie.VALIDATE_CONN' doesn't exist
解决:CM页面中的Oozie页面中的操作:创建Oozie数据库表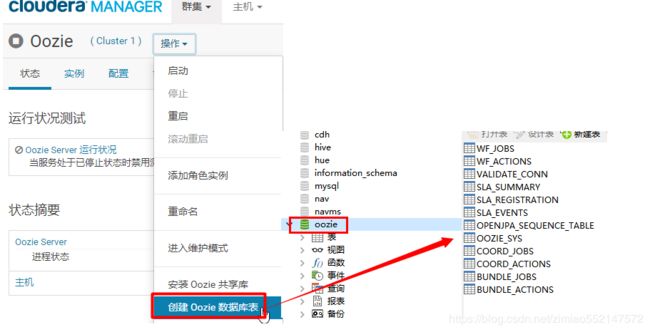
11.当启动spark报错如下:
Caused by: java.lang.IllegalArgumentException: Log directory specified does not exist: hdfs://cdh01.hadoop.com:8020/user/spark/applicationHistory
原因:根据报错信息可知hdfs路径下缺少/user/spark/applicationHistory这个路径的文件夹
解决:sudo -u hdfs hadoop fs -mkdir /user/spark
sudo -u hdfs hadoop fs -mkdir /user/spark/applicationHistory
sudo -u hdfs hadoop fs -chown -R spark:spark /user/spark
sudo -u hdfs hadoop fs -chmod 777 /user/spark/applicationHistory