RetinaNet系列1:ResNet和FPN部分总结
在FPN 原文Feature Pyramid Networks for Object Detection中,使用了ResNet原文 Deep Residual Learning for Image Recognition中的resnet34层模型的 conv2_到conv5_,ResNet34的conv2_到conv5_的depth分别是64,128,256,512。输入图片的size是224x224 。
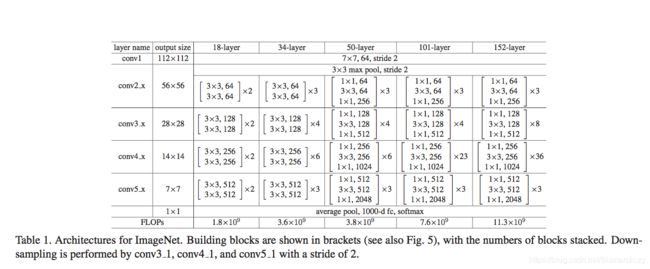
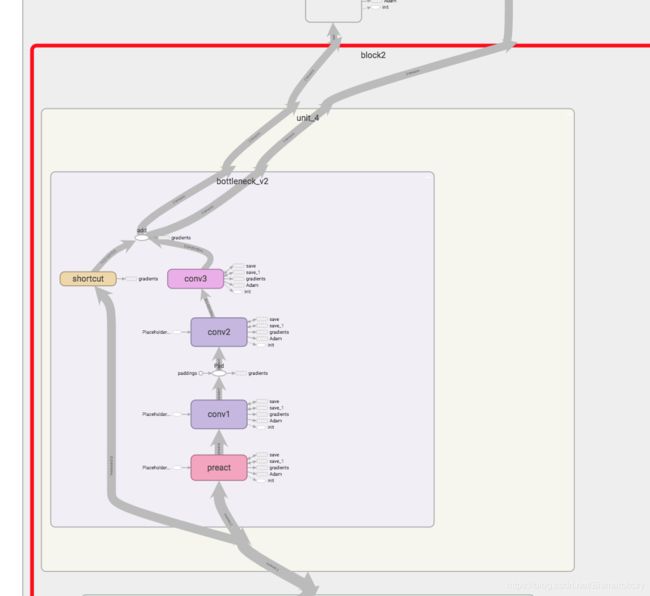


上面两张图分别是
blovk2/unit4/bottleneck_v2
block3/unit6/bottleneck_v2
block4/unit3/bottleneck_v2
在kaiming He的两篇paper的描述中,不同类型的ResNet都是四个block组成,比如ResNet50_v2,四个block的unit数目分别是3,4,6,3,而resnet101_v2的四个block的unit数目是3,4,23,3。对于每一个unit,它包含一个bottleneck_v2结构,bottleneck_v2的结构可以从上述三个图看出来,也可以从下图看出来。它包含三个卷积层,它是一个先用11降维,再33的普通卷积,再11升维的过程,11的卷积计算量很小,同时降维之后在3*3的卷积部分也会由于维度下降导致训练时间减少,参数数目也会减少,从而使得整体的训练时间减少,这也是resnet_v2区别于v1的一个地方。另一个区别就是卷积层之前的BN和ReLU。
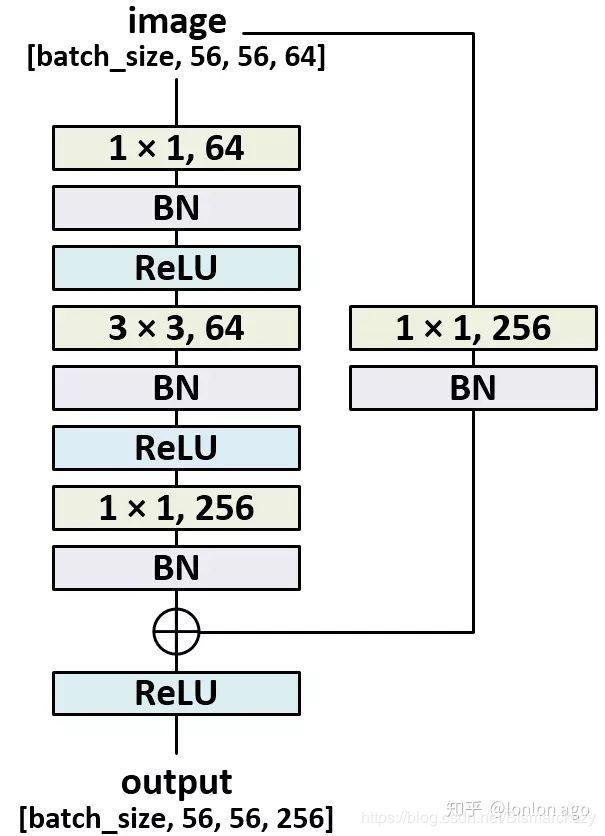
解析完了unit内部情况,再谈block层次。
有一个我认为比较重要的细节是,在一般的resnet实现中,downsamping都是在每一个block的第一个unit中实现的。也就是说上一个block的最后一个unit的最后一个conv layer可能是wh,那么在这一层的第一个unit的第一个conv layer进行的卷积的stride是2,这个conv layer的大小是w/2h/2 当然,可能伴随着depth翻倍,这种实现是比较常见的。
但是在tf官方(当然也是一堆热心程序员开源的),实现的resnet50_v2的结构跟上面描述的结构是有一点不一样的。
我们知道block1对应的是conv2,而conv1中进行了一次stride=2的卷积,然后做了一次stride=2的max_pooling,所以block1的输入是I/4,I是原图大小。
为了方便起见,我们假设输入图片大小是[512 512 3]
那么到了block1,输入的feature map是[128,128,64],记为block1/unit1/conv1,64是depth,先别在意。
根据上图中的bottleneck的操作(也就是unit),操作示意如下:
block1/unit1/conv1 : [128,128,64] conv_with 1x1x64x64----->
block1/unit1/conv2 : [128,128,64] conv_with 3x3x64x64----->
block1/unit1/conv3 : [128,128,64] conv_with 1x1x64x256---->
这就得到了block1/unit1/conv3的输出[128,128,256]
block1/unit2/conv1: [128,128,256] conv_with 1x1x256x64—>
block1/unit2/conv2: [128,128,64] conv_with 3x3x64x64—>
block1/unit2/conv3: [128,128,64] conv_with 1x1x64x256—>
所以block1/unit2/conv3的输出是[128,128,256]。
那么downsampling在哪里呢?
答案是 block1 2 3的downsampling发生在的最后一个unit中的第一个和第二个conv之间。block没有进行downsampling。
怎么说?
还是回到刚刚说的block1/unit2/conv3 [128,128,256]。你可能以为他要在block1/unit3中继续进行卷积三连。然后在下一个block的第一个unit进行downsampling。
事实上,一部分resnet似乎是这么实现的。比如何凯明个人github给的可视化网站。

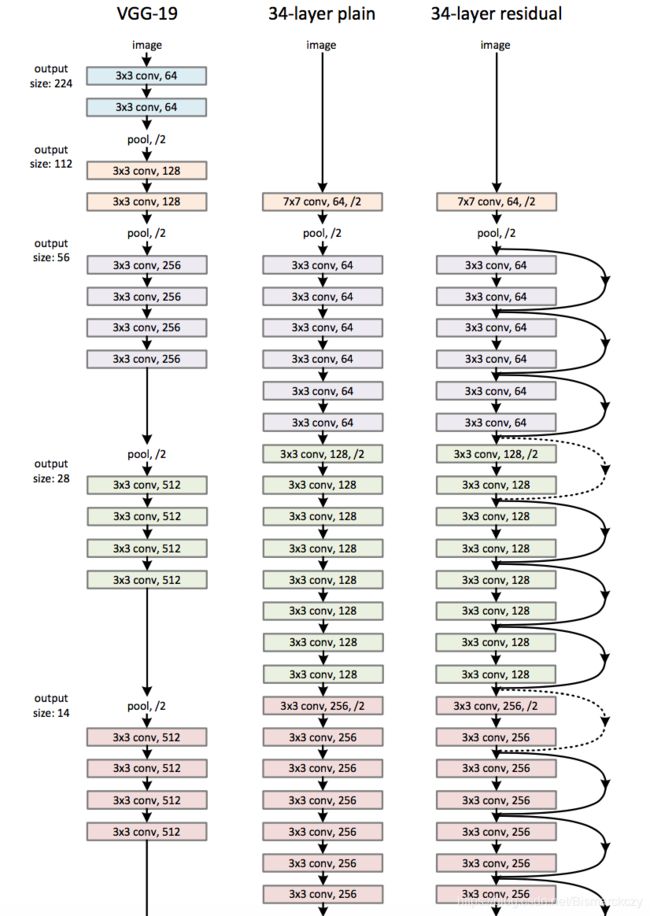
我们知道resent34的unit是(3,4,6,3)*2=34。这里的2意味着resnet是属于v1
所以paper中的上图也表示downsampling发生在下一个block中,这一点在最开始给的表格中也是一样。
然而,如果你用过tf官方的resnet50_v2,或者在tensorboard看过它。会发现,downsampling,发生在每一个block的最后一个unit(最后一个block4没有downsampling)。举个栗子:
还是回到刚刚说的block1/unit2/conv3 [128,128,256]。你可能以为他要在block1/unit3中继续进行卷积三连,他确实要进行卷积三连,但是和unit1,unit2中的卷积三连是不一样的,这里为了易懂(让我自己),我省掉了unit3中的padding。
block1/unit3/conv1: [128,128,256] conv_with 1x1x256x64—>
block1/unit3/conv2: [128,128,64] conv_with 3x3x64x64 stride=2 !
block1/unit3/conv3: [64,64,64] conv_with 1x1x64x256—>
所以block1/unit3/conv3的输出是[64,64,256] 。
聪明的人可能会说,诶你下采样但是不增加depth,这不符合基和本谐法啊!
好像有道理。
那我得找个地方增加一下depth,不然这很不深度学习。
接下来说block2了。直接放操作。
block2/unit1/conv1: [64,64,256] conv_with 1x1x256x128—>
block2/unit1/conv2: [64,64,128] conv_with 3x3x128x128—>
block2/unit1/conv3: [64,64,128] conv_with 1x1x128x512—>
没错,增加depth的操作放在了下一个block的unit1的conv2之后
block2/unit2/conv1: [64,64,512] conv_with 1x1x512x128—>
block2/unit2/conv2: [64,64,128] conv_with 3x3x128x128—>
block2/unit2/conv3: [64,64,128] conv_with 1x1x128x512—>
block2/unit3/conv1: [64,64,512] conv_with 1x1x512x128—>
block2/unit3/conv2: [64,64,128] conv_with 3x3x128x128—>
block2/unit3/conv3: [64,64,128] conv_with 1x1x128x512—>
block2/unit4/conv1: [64,64,512] conv_with 1x1x512x128—>
block2/unit4/conv2: [64,64,128] conv_with 3x3x128x128 stride=2
block2/unit4/conv3: [32,32,128] conv_with 1x1x128x512—>
block3/unit1/conv1: [32,32,512] conv_with 1x1x512x256
block3/unit1/conv2: [32,32,256] conv_with 3x3x256x256
block3/unit1/conv3: [32,32,256] conv_with 1x1x256x1024
block3/unit2/conv1: [32 32 1024]…
…
block3/unit6/conv1: [32 32 1024] conv_with 1x1x1024x256
block3/unit6/conv2: [32 32 256] conv_with 3x3x256x256 stride=2
block3/unit6/conv3: [16 16 256] conv_with 1x1x256x1024
block4/unit1/conv1: [16 16 1024]
block4/unit1/conv2: [16 16 512]
block4/unit1/conv3: [16 16 512] conv_with 1x1x512x2048
…
block4/unit3/conv1: [16 16 2048]
block4/unit3/conv2: [16 16 512]
block4/unit3/conv3: [16 16 2048]
…
end
总结一下重点
每一个block的最后一层的大小
block1/unit3/conv3 64 64 256
block2/unit4/conv3 32 32 512
block3/unit6/conv3 16 16 1024
block4/unit3/conv3 16 16 2048
在RetinaNet中,我选择
block1/unit3/conv3
block2/unit4/conv3
block4/unit3/conv3
来构造FPN,为什么不要block3,因为丑吗?
不是,因为block3的feature map和block4一样大,但是block4的depth是block3的两倍。
ResNet 哔哔结束,开始bb FPN。
这里的FPN是FPN论文里面的FPN,不是RetinaNet论文里面的FPN,两者虽然原理一样,但是结构和实现略微不同,FPN论文使用的是ResNet34,懂的人知道,ResNet34只属于v1。而RetinaNet用的ResNet50,属于v2,稍后说它。
我们先说FPN论文的目的。
熟悉faster rcnn的人知道,faster rcnn利用的是vgg的最后的conv5卷积特征,大小是7x7x512,而这造成了一个问题,经过多次卷积之后的特征通常拥有很大的感受野,它们比较适合用来检测大物体,或者说,它们在检测小物体任务上效果很差,所以像SSD和FPN这样的网络思想就是将浅层和深层的的卷积层都拿出来,组成一个multisacle结果,既能检测大物体,又能检测小物体。
基于这个思想,FPN从ResNet34构造了一组新的特征,p2,p3,p4,p5,每一个 p i p_i pi都是ResNet中不同卷积层融合的结果,这保证了他们都拥有多尺度信息。他们拥有相同的depth,都是256。
构造的方式如下:

bottom-up就是简单的使用了ResNet34,主要是top-down中的思想值得看看。
在上文中我们提到ResNet50的c2-c5的大小和维度分别是56x56x64,28x28x128,14x14x256,7x7x512,所以在top-down中,先用了一个1x1x512x256的卷积将c5:7x7x512 变成了m5:7x7x256, 每一个m之后都接了一个3x3x256x256卷积用来消除不同层之间的混叠效果,其实也就是缓冲作用。
关于p4的构造,我们先将m5的feature map加倍,用简单的nearest neighbour upsamping方法就行,这样m5就变成了m5’:14x14x256,同时c4:14x14x256经过1x1x256x256得到c4’:14x14x256, 将m5’+c4’, element-wisely,就可以得到m4:14x14x256,m4经过3x3x256x256卷积得到p4。
…
所以最后的p2-p5大小分别是
56x56x256。,28x28x256,14x14x256,7x7x256。
在理解了FPN的基本操作之后,我们来看看RetineNet里面,多层次特征是怎么得到的。
首先,RetinaNet中使用的是ResNet50,上面的图片已经给出了ResNet50的结构了。50怎么来的?
(3+4+6+3)*3+2=50,这里的2表示conv1里面的7x7conv和conv2开始的maxpooling layer。
所以我们发现,其实ResNet50跟ResNet34大同小异,可以分成conv2到conv5四个部分。
怎么用c2-c5构造 p i p_i pi是RetinaNet的一个特点。
" RetinaNet uses feature pyramid levels P3 to P7, where P3 to P5 are computed from the output of the corresponding ResNet residual stage (C3 through C5) using top-down and lateral connections just as in [20], P6 is obtained via a 3⇥3 stride-2 conv on C5, and P7 is computed by apply- ing ReLU followed by a 3⇥3 stride-2 conv on P6. This differs slightly from [20]: (1) we don’t use the high-resolution pyramid level P2 for com- putational reasons, (2) P6 is computed by strided convolution instead of downsampling, and (3) we include P7 to improve large object detection. These minor modifications improve speed while maintaining accuracy. " -----------《Focal Loss for Dense Object Detection》
我在上面已经详细的介绍了resnet的c2到c5了,也就是block1到block4的最后一层。对于一个512的输入,c2到c5的大小分别是
64x64x256
32x32x512
16x16x1024
16x16x2048
论文中取得是c3到c5,而实际上,代码中,我取的是c2,c3,c5,也就是block1 block2 block4,所以接下来的文章里面,记得c3=c2,c4=c3,c5=c5
首先跟fpn中类似,假设输入图片是 I × I I \times I I×I,那么c3到c5的大小是
I 2 3 × I 2 3 × 256 = 64 × 64 × 256 \frac{I}{2^3}\times\frac{I}{2^3}\times256=64\times64\times256 23I×23I×256=64×64×256;
I 2 4 × I 2 4 × 512 = 32 × 32 × 512 \frac{I}{2^4}\times\frac{I}{2^4}\times512=32\times32\times512 24I×24I×512=32×32×512;
I 2 5 × I 2 5 × 2048 = 16 × 16 × 2048 \frac{I}{2^5}\times\frac{I}{2^5}\times2048=16\times16\times2048 25I×25I×2048=16×16×2048;
类似于fpn的操作,我们将c5通过1x1x256卷积变成m5: I 2 5 × I 2 5 × 256 \frac{I}{2^5}\times\frac{I}{2^5}\times256 25I×25I×256,再通过3x3x256卷积得到
p5: 16 × 16 × 256 16\times16\times256 16×16×256。
同理可以得到
p4: 32 × 32 × 256 32\times32\times256 32×32×256;
p3: 64 × 64 × 256 64\times64\times256 64×64×256;
在RetinaNet中新增了p6和p7,p6是通过对p5 进行3x3,stride=2的卷积得到,所以p6大小是p6: 8 × 8 × 256 8\times8\times256 8×8×256
对p6进行ReLU,然后再通过3x3,stride=2的卷积,就可以得到p7,大小是p7: 4 × 4 × 256 4\times4\times256 4×4×256。
原文中也说了, p i p_i pi的意思就是 p i p_i pi has resolution 2 i 2^i 2ilower than the input.
原文中解释,加入p6和p7就是为了让模型更好地检测大物体,因为感受野大。而不用p2的原因是p2的feature map太大导致计算量太大。
所以如果想检测小物体,理论上有两种方法,一种是加入p2然后去掉p6和p7,但是这个代价是引入了128x128的feature map,这样在p2这一层生成的anchor数目是128x128x9=16384x9=147456. 有点过多了,算起来很慢的。
另一种方法就是在设置anchor的base size和ratios还有scales上让anchor尽量小一点。
近期补充anchor生成部分总结。
假设输入图片大小是512x512
选择的feature map的大小和anchors的大小的关系,以及anchors和ground truth之间的计算关系。
anchors数目是N=(64x64+32x32+16x16+8x8+4x4)*9=49104
其中
在64x64的feature map上,我用的anchor size是8x8
同理32x32 map对应anchor size是16x16
…
在4x4的map上 anchor size是128x128
参考文章
ResNet源码解析