Java函数式编程详解
Java从1.8以后引入了函数式编程,这是很大的一个改进。函数式编程的优点在提高编码的效率,增强代码的可读性。本文历时两个多月一点点写出来,即作为心得,亦作为交流。
1.Java函数式编程的语法:
使用Consumer作为示例,它是一个函数式接口,包含一个抽象方法accept,这个方法只有输入而无输出也就是说这个方法无返回值。
现在我们要定义一个Consumer接口的实例化对象,传统的方式是这样定义的:
public static void main(String[] args) {
//JDK1.8版本之前的做法
Consumer
@Override
public void accept(Integer t) {
System.out.println(t);
}
};
//调用方法
con.accept(3);
}
这里可以打印出3.
上面是JDK1.8以前的做法,在1.8以后引入函数式的编程可以这样写:
public static void main(String[] args) {
//第一种写法:
Consumer
//第二种写法:
Consumer
//第三种写法:
Consumer
con2.accept(3);
}
上面的con、con1、con2这个Consumer对象的引用照样可以打印出3.
在上面的第二种写法是第一种写法的精简,但是只有在函数题中只有一条语句时才可以这么使用,做进一步的简化。
在上面的第三种写法是对第一、二种写法的进一步精简,由于第三种写法只是进行打印,调用了System.out中的println静态方法对输入参数直接进行打印。它表示的意思就是针对输入的参数将其调用System.out中的静态方法println进行打印。
上面已说明,函数式编程接口都只有一个抽象方法,因此在采用这种写法时,编译器会将这段函数编译后当作该抽象方法的实现。
如果接口有多个抽象方法,编译器就不知道这段函数应该是实现哪个方法的了。
因此,= 后面的函数体我们就可以看成是accept函数的实现。
输入:-> 前面的部分,即被()包围的部分。此处只有一个输入参数,实际上输入是可以有多个的,如两个参数时写法:(a, b);当然也可以没有输入,此时直接就可以是()。
函数体:->后面的部分,即被{}包围的部分;可以是一段代码。
输出:函数式编程可以没有返回值,也可以有返回值。如果有返回值时,需要代码段的最后一句通过return的方式返回对应的值。但是Consumer这个函数式接口不能有具体的返回值。
Java 8 中我们可以通过 `::` 关键字来访问类的构造方法,对象方法,静态方法。
好了,到这一步就可以感受到函数式编程的强大能力。
通过最后一段代码,我们可以简单的理解函数式编程,Consumer接口直接就可以当成一个函数了,这个函数接收一个输入参数,然后针对这个输入进行处理;当然其本质上仍旧是一个对象,但我们已经省去了诸如老方式中的对象定义过程,直接使用一段代码来给函数式接口对象赋值。
而且最为关键的是,这个函数式对象因为本质上仍旧是一个对象,因此可以做为其它方法的参数或者返回值,可以与原有的代码实现无缝集成!
2.Java函数式接口
java.util.function.Consumer;
java.util.function.Function;
java.util.function.Predicate;
2.1 Consumer是一个函数式编程接口; 顾名思义,Consumer的意思就是消费,即针对某个东西我们来使用它,因此它包含有一个有输入而无输出(无返回值)的accept接口方法;
除accept方法,它还包含有andThen这个方法;
JDK源码定义如下:
default Consumer
Objects.requireNonNull(after);
return (T t) -> { accept(t); after.accept(t); };
}
andThen这个方法是作用是:指定在调用当前Consumer后是否还要调用其它的Consumer;
public static void main(String[] args) {
//定义第一个Consumer
Consumer
//定义第二个Consumer
Consumer
//consumer1可以连续的调用自己
//consumer1.andThen(consumer1).andThen(consumer1).accept(3);
//打印出 3 3 3
//consumer1可以调用自己后调用consumer2
consumer1.andThen(consumer1).andThen(consumer2).accept(3);
//打印出3 3 9
}
注意:当一个Consumer接口调用另外一个Consumer对象时两个Counsumer对象的泛型必须一致。
2.2 Function也是一个函数式编程接口;它代表的含义是“函数”,它是个接受一个参数并生成结果的函数,而函数经常是有输入输出的,因此它含有一个apply方法,包含一个输入与一个输出;
除apply方法外,它还有compose与andThen及indentity三个方法,其使用见下述示例;
apply的用法:
public static void main(String[] args) {
Function
Integer i = fun.apply(2);
System.out.println(i);
}
上面打印出2。
Function编程接口有两个泛型Function
compose的用法:
JDK源码定义:
default
Objects.requireNonNull(before);
return (V v) -> apply(before.apply(v));
}
public static void main(String[] args) {
Function
Function
Integer i = (Integer) fun.compose(fun1).apply(2);
System.out.println(i);
}
上面打印出21;
上面表示了fun2接收到2以后先计算,然后将fun2计算的结果再交给fun再计算。
andThen方法的用法:
JDK源码定义:
default
Objects.requireNonNull(after);
return (T t) -> after.apply(apply(t));
}
public static void main(String[] args) {
Function
Function
Integer i = (Integer) fun.andThen(fun1).apply(3);
System.out.println(i);
}
上面打印出40
上面表示了fun先计算得到4,然后将计算结果4再给fun1计算得到40;
indentity方法的用法:
JDK源码定义:
static
return t -> t;
}
public static void main(String[] args) {
System.out.println(Function.identity().apply("总分"));
}
上面打印出“总分“;就是说传入什么参数输出什么参数。
2.3 Predicate为函数式接口,predicate的中文意思是“断定”,即判断的意思,判断某个东西是否满足某种条件; 因此它包含test方法,根据输入值来做逻辑判断,其结果为True或者False。
test方法的用法:
JDK源码定义: boolean test(T t);
public static void main(String[] args) {
Predicate
boolean rest = pre.test("1234");
System.out.println(rest);
}
上面打印出true。
and方法的用法:
JDK源码定义:
default Predicate
Objects.requireNonNull(other);
return (t) -> test(t) && other.test(t);
}
public static void main(String[] args) {
Predicate
Predicate
Predicate
boolean rest = pre.and(pre1).test("1234");
boolean rest1 = pre.and(pre1).test("12341");
System.out.println(rest);
System.out.println(rest1);
}
上面先打印出true,后打印出false
根据源码,"1234"先和pre比较,如果为true,再和pre1比较。不为true直接返回false,不再和pre1比较。当“1234”和pre比较后为true,再和pre1比较结果为true,所以最终返回true。
negate()的用法:
JDK源码定义:
default Predicate
return (t) -> !test(t);
}
public static void main(String[] args) {
Predicate
boolean rest = pre.negate().test("1234");
System.out.println(rest);
}
上面打印出false,上面的意思是如果比较的结果是true,那么返回false,如果为false,就返回true。
or的方法的用法:
JDK源码定义:
default Predicate
Objects.requireNonNull(other);
return (t) -> test(t) || other.test(t);
}
public static void main(String[] args) {
Predicate
Predicate
boolean rest = pre.or(pre1).test("12341");
System.out.println(rest);
}
上面打印出true;
or方法的意思是:只要一个为true就返回true。
isEqual方法用法:
JDK源码定义:
static
return (null == targetRef)
? Objects::isNull
: object -> targetRef.equals(object);
}
public static void main(String[] args) {
System.out.println(Predicate.isEqual("12345").test("12345"));
}
上面打印出true;isEqual里的参数是要比较的目标对象。
3.函数式编程接口的使用
通过Stream以及Optional两个类,可以进一步利用函数式接口来简化代码。
3.1 Stream
Stream可以对多个元素进行一系列的操作,也可以支持对某些操作进行并发处理。
3.1.1 Stream对象的创建
Stream对象的创建途径有以下几种:
a. 创建空的Stream对象
Stream str = Stream.empty();
b. 通过集合类中的stream或者parallelStream方法创建;
List
Stream listStream = list.stream(); //获取串行的Stream对象
Stream parallelListStream = list.parallelStream(); //获取并行的Stream对象
c. 通过Stream中的of方法创建:
Stream s = Stream.of("test");
Stream s1 = Stream.of("a", "b", "c", "d");
d. 通过Stream中的iterate方法创建:
iterate方法有两个不同参数的方法:
public static
public static
其中第一个方法将会返回一个无限有序值的Stream对象:它的第一个元素是seed,第二个元素是f.apply(seed); 第N个元素是f.apply(n-1个元素的值);生成无限值的方法实际上与Stream的中间方法类似,在遇到中止方法前一般是不真正的执行的。因此无限值的这个方法一般与limit等方法一起使用,来获取前多少个元素。
当然获取前多少个元素也可以使用第二个方法。
第二个方法与第一个方法生成元素的方式类似,不同的是它返回的是一个有限值的Stream;中止条件是由hasNext来断定的。
第二种方法的使用示例如下:
/**
* 本示例表示从1开始组装一个序列,第一个是1,第二个是1+1即2,第三个是2+1即3..,直接10时中止;
* 也可简化成以下形式:
* Stream.iterate(1,
* n -> n <= 10,
* n -> n+1).forEach(System.out::println);
* 写成以下方式是为简化理解
*/
Stream.iterate(1,
new Predicate
@Override
public boolean test(Integer integer) {
return integer <= 10;
}
},
new UnaryOperator
@Override
public Integer apply(Integer integer) {
return integer+1;
}
}).forEach(System.out::println);
e. 通过Stream中的generate方法创建
与iterate中创建无限元素的Stream类似,不过它的每个元素与前一元素无关,且生成的是一个无序的队列。也就是说每一个元素都可以随机生成。因此一般用来创建常量的Stream以及随机的Stream等。
示例如下:
/**
* 随机生成10个Double元素的Stream并将其打印
*/
Stream.generate(new Supplier
@Override
public Double get() {
return Math.random();
}
}).limit(10).forEach(System.out::println);
//上述写法可以简化成以下写法:
Stream.generate(() -> Math.random()).limit(10).forEach(System.out::println);
f. 通过Stream中的concat方法连接两个Stream对象生成新的Stream对象
这个比较好理解不再赘述。
3.1.2 Stream对象的使用
Stream对象提供多个非常有用的方法,这些方法可以分成两类:
中间操作:将原始的Stream转换成另外一个Stream;如filter返回的是过滤后的Stream。
终端操作:产生的是一个结果或者其它的复合操作;如count或者forEach操作。
其清单如下所示,方法的具体说明及使用示例见后文。
所有中间操作:

所有的终端操作:
下面就几个比较常用的方法举例说明其用法:
3.1.2.1 filter
用于对Stream中的元素进行过滤,返回一个过滤后的Stream
其方法定义如下:
Stream
使用示例:
Stream
//查找所有包含t的元素并进行打印
s.filter(n -> n.contains("t")).forEach(System.out::println);
3.1.2.2 map
元素一对一转换。
它接收一个Funcation参数,用其对Stream中的所有元素进行处理,返回的Stream对象中的元素为Function对原元素处理后的结果
其方法定义如下:
示例,假设我们要将一个String类型的Stream对象中的每个元素添加相同的后缀.txt,如a变成a.txt,其写法如下:
Stream
s.map(n -> n.concat(".txt")).forEach(System.out::println);
3.1.2.3 flatMap
元素一对多转换:对原Stream中的所有元素使用传入的Function进行处理,每个元素经过处理后生成一个多个元素的Stream对象,然后将返回的所有Stream对象中的所有元素组合成一个统一的Stream并返回;
方法定义如下:
示例,假设要对一个String类型的Stream进行处理,将每一个元素的拆分成单个字母,并打印:
Stream
s.flatMap(n -> Stream.of(n.split(""))).forEach(System.out::println);
3.1.2.4 takeWhile
方法定义如下:
default Stream
如果Stream是有序的(Ordered),那么返回最长命中序列(符合传入的Predicate的最长命中序列)组成的Stream;如果是无序的,那么返回的是所有符合传入的Predicate的元素序列组成的Stream。
与Filter有点类似,不同的地方就在当Stream是有序时,返回的只是最长命中序列。
如以下示例,通过takeWhile查找”test”, “t1”, “t2”, “teeeee”, “aaaa”, “taaa”这几个元素中包含t的最长命中序列:
Stream
//以下结果将打印: "test", "t1", "t2", "teeeee",最后的那个taaa不会进行打印
s.takeWhile(n -> n.contains("t")).forEach(System.out::println);
3.1.2.5 dropWhile
与takeWhile相反,如果是有序的,返回除最长命中序列外的所有元素组成的Stream;如果是无序的,返回所有未命中的元素组成的Stream;其定义如下:
default Stream
如以下示例,通过dropWhile删除”test”, “t1”, “t2”, “teeeee”, “aaaa”, “taaa”这几个元素中包含t的最长命中序列:
Stream
//以下结果将打印:"aaaa", "taaa"
s.dropWhile(n -> n.contains("t")).forEach(System.out::println);
3.1.2.6 reduce与collect
关于reduce与collect由于功能较为复杂,在后续将进行单独分析与学习,此处暂不涉及。
3.2 Optional用于简化Java中对空值的判断处理,以防止出现各种空指针异常。
Optional实际上是对一个变量进行封装,它包含有一个属性value,实际上就是这个变量的值。
3.2.1 Optional对象创建
它的构造函数都是private类型的,因此要初始化一个Optional的对象无法通过其构造函数进行创建。它提供了一系列的静态方法用于构建Optional对象:
3.2.1.1 empty
用于创建一个空的Optional对象;其value属性为Null。
如:
Optional o = Optional.empty();
3.2.1.2 of
根据传入的值构建一个Optional对象;
传入的值必须是非空值,否则如果传入的值为空值,则会抛出空指针异常。
使用:
o = Optional.of("test");
1
3.2.1.3 ofNullable
根据传入值构建一个Optional对象
传入的值可以是空值,如果传入的值是空值,则与empty返回的结果是一样的。
3.2.2 方法
Optional包含以下方法: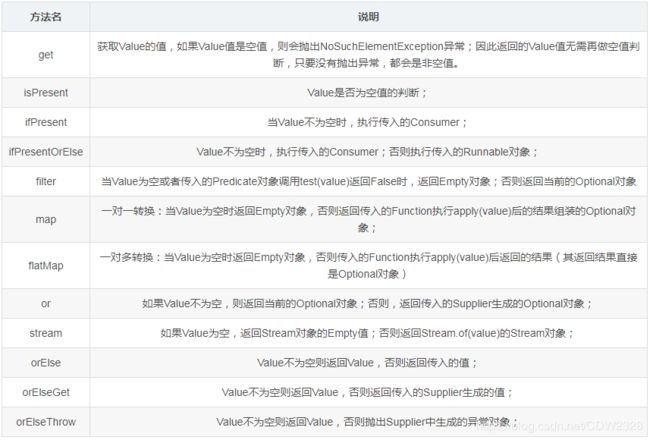
3.2.3 使用场景
常用的使用场景如下:
3.2.3.1 判断结果不为空后使用
如某个函数可能会返回空值,以往的做法:
String s = test();
if (null != s) {
System.out.println(s);
}
现在的写法就可以是:
Optional
s.ifPresent(System.out::println);
乍一看代码复杂度上差不多甚至是略有提升;那为什么要这么做呢?
一般情况下,我们在使用某一个函数返回值时,要做的第一步就是去分析这个函数是否会返回空值;如果没有进行分析或者分析的结果出现偏差,导致函数会抛出空值而没有做检测,那么就会相应的抛出空指针异常!
而有了Optional后,在我们不确定时就可以不用去做这个检测了,所有的检测Optional对象都帮忙我们完成,我们要做的就是按上述方式去处理。
3.2.3.2 变量为空时提供默认值
如要判断某个变量为空时使用提供的值,然后再针对这个变量做某种运算;
以往做法:
if (null == s) {
s = "test";
}
System.out.println(s);
现在的做法:
Optional
System.out.println(o.orElse("test"));
3.2.3.3 变量为空时抛出异常,否则使用
以往写法:
if (null == s) {
throw new Exception("test");
}
System.out.println(s);
现在写法:
Optional
System.out.println(o.orElseThrow(()->new Exception("test")));