你不知道XML编程的那些事儿(一)
以前接触了XML的一些简单语法,感觉XML并没有特别大的作用,今天,在继续深入WEB的学习时,发现XML中隐藏着很多让人不知道的事(这篇文章是对于那些有XML基础上写的),今天这是第一篇,主要是讲解XML解析方式和其中解析工具JAXP解析工具来讲解的,如果有什么地方不足,请指教!
XML解析方式:DOM(文档对象模型)和SAX(XML的简单解析接口)
DOM解析的原理:
以下通过一个实例来展示:
xml version="1.0"?>
<root>
<head>
<title>exampletitle>
head>
<body>
<p>content1p>
<p>content2p>
body>
<foot>
<author name="lists"/>
foot>
root>对于以上的XML文档,DOM实质是将XML文件以DOM树的形式展示出来,在解析的过程中,首先是将整个XML文件加载到内存中,再逐个进行解析。
如下图所示:
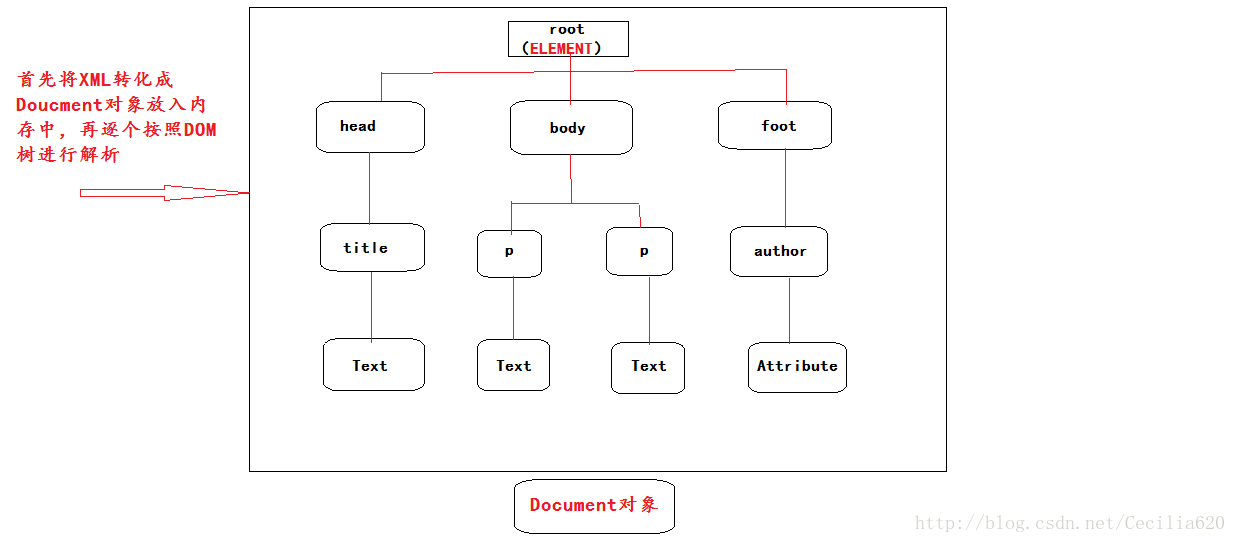
SAX解析原理:而对于SAX解析的原理说起来就比较简单啦(PS:说起来简单,可是实际操作起来可不一定哟!),实质就是对XML文档逐行逐行地进行解析,不必先将整个XML先加载入内存中,只需对一行处理,就对一行进行操作。
在这里大家应该就很容易看出来,DOM和SAX各有千秋,他们之间又有着区别呢?
DOM和SAX的区别:
1.DOM解析对于文档crud特别方便,但是由于每次解析都是先将整个XML文件加载入内存中,如果在XML文件特别大时,很容易造成内存溢出;
2.SAX解析过程是对每一行进行逐步解析,解析速度比较快,而且无论XML文件有多大,都不会担心内存溢出的问题出现,占用内存比较少,但是由于解析只是每次对每一行进行逐步解析,只适合文档的读取操作,不适合做文档的crud操作。
谈完这些解析方式,那么接下来该想到解析工具有哪些?
XML解析开发包:
JAXP:由javax.xml、org.w3c.dom、org.xml.sax包以及子包组成
该如何使用Jaxp采用DOM解析方式进行解析呢?
步骤:
1.创建DOM模式的解析器工厂
/*创建工厂*/
DocumentBuilderFactory factory=DocumentBuilderFactory.newInstance();2.得到解析器
/*得到解析器*/
DocumentBuilder builder=factory.newDocumentBuilder();3.得到所要进行操作的document对象
/*得到所要进行操作的document对象*/
Document document=builder.parse("msg/book.xml");万种原理都顶不住实例说话好,那么接下来,用实例说话:
/*XML文档案例book.xml*/
<书架>
<书>
<书名 name="Thinking in Java">Java程序编程思想书名>
<作者>张孝祥作者>
<出厂价>69.0元出厂价>
<售价>109.0元售价>
书>
<书>
<书名 name="CSS禅意花园">CSS禅意花园书名>
<作者>某某作者>
<出厂价>39.0元出厂价>
<售价>45.0元售价>
书>
书架>主函数:
/**
* 如何实现JAxp来对DOM进行解析?
* @author 芷若初荨
* @Date 2017.4.23
*/
public class JaxpAnalysisXML {
public static void main(String[] args) throws Exception {
// 1.创建工厂
DocumentBuilderFactory factory=DocumentBuilderFactory.newInstance();
// 2.得到dom解析器
DocumentBuilder builder=factory.newDocumentBuilder();
// 3.解析xml文档,得到代表文档的document
builder.parse("msg/book.xml");
}
}对文档进行读取操作:
@Test
//---------------------------文档进行读操作---------------------------
// 首先对文档进行读操作
public void read() throws Exception{
// 创建工厂
DocumentBuilderFactory factory=DocumentBuilderFactory.newInstance();
// 得到解析器
DocumentBuilder builder=factory.newDocumentBuilder();
//
Document document=builder.parse("msg/book.xml");
// 获取数据
NodeList list=document.getElementsByTagName("书名");
Node node=list.item(1);
String content=node.getTextContent();
System.out.println(content);
}
//------------------对所有节点进行读取,并且得到所有节点内容----------
@Test
public void read1() throws Exception{
// 创建工厂
DocumentBuilderFactory factory=DocumentBuilderFactory.newInstance();
// 得到解析器
DocumentBuilder builder=factory.newDocumentBuilder();
Document document=builder.parse("msg/book.xml");
// 得到根节点
Node root=document.getElementsByTagName("书架").item(0);
list(root);
}
private void list(Node node){
if(node instanceof Element){
System.out.println(node.getNodeName());
}
NodeList list=node.getChildNodes();
for(int i=0;i//--得到XML文档中标签属性的值:<书名 name="Thinking Java">Java编程思想
@Test
public void read2() throws Exception{
// 创建工厂
DocumentBuilderFactory factory=DocumentBuilderFactory.newInstance();
// 得到解析器
DocumentBuilder builder=factory.newDocumentBuilder();
Document document=builder.parse("msg/book.xml");
Element bookname=(Element) document.getElementsByTagName("书名").item(0);
String value=bookname.getAttribute("name");
System.out.println(value);
} 对文档进行添加节点操作:
@Test
// 添加节点
public void createNode() throws Exception{
// 创建工厂
DocumentBuilderFactory factory=DocumentBuilderFactory.newInstance();
// 得到解析器
DocumentBuilder builder=factory.newDocumentBuilder();
// 得到document对象
Document document=builder.parse("msg/book.xml");
// 创建节点
Element price=document.createElement("售价");
// 添加节点值
price.setTextContent("45.0元");
// 得到参考节点
Element refNode=(Element) document.getElementsByTagName("售价").item(1);
// 把创建的节点挂到第2本书上
Element book=(Element) document.getElementsByTagName("书").item(1);
// 往book节点的指定位置插入节点
book.insertBefore(price, refNode);
// 直接在后面追加节点
// book.appendChild(price);
// 更新内存中的数据写回XML文档中
TransformerFactory tffactory=TransformerFactory.newInstance();
Transformer tf=tffactory.newTransformer();
tf.transform(new DOMSource(document), new StreamResult(new FileOutputStream("msg/book.xml")));
}在这里要注意的是:在添加节点时,需要首先对内容进行更新,然后写回book.xml文件中!!!!(TransformFactory的用法)
对文档进行删除操作:
@Test
//---------------------------删除操作------------------------------
public void removeNode() throws Exception{
// 创建工厂
DocumentBuilderFactory factory=DocumentBuilderFactory.newInstance();
// 得到解析器
DocumentBuilder builder=factory.newDocumentBuilder();
// 得到document对象
Document document=builder.parse("msg/book.xml");
// 得到要删除的节点
Element e=(Element) document.getElementsByTagName("售价").item(1);
// 得到要删除节点的父节点
Element book=(Element) document.getElementsByTagName("书").item(1);
// 删除指定节点
book.removeChild(e);
// 另外一种删除方式
// e.getParentNode().removeChild(e);
// 或者删除节点的父节点
// e.getParentNode().getParentNode().getParentNode().removeChild(e.getParentNode().getParentNode());
// 更新内存中的数据写回XML文档中
TransformerFactory tffactory=TransformerFactory.newInstance();
Transformer tf=tffactory.newTransformer();
tf.transform(new DOMSource(document), new StreamResult(new FileOutputStream("msg/book.xml")));
}对文档进行更新操作:
@Test
//---------------------------更新操作------------------------------
public void updateNode() throws Exception{
// 创建工厂
DocumentBuilderFactory factory=DocumentBuilderFactory.newInstance();
// 得到解析器
DocumentBuilder builder=factory.newDocumentBuilder();
// 得到document对象
Document document=builder.parse("msg/book.xml");
// 得到要更新的节点
Element e=(Element) document.getElementsByTagName("售价").item(1);
// 更新节点内容
e.setTextContent("109.0元");
// 更新内存中的数据写回XML文档中
TransformerFactory tffactory=TransformerFactory.newInstance();
Transformer tf=tffactory.newTransformer();
tf.transform(new DOMSource(document), new StreamResult(new FileOutputStream("msg/book.xml")));
}