手把手教你如何玩转Solr(包含项目实战)
备注:学习Solr最好先了解一下Lucene的基本内容,不需要很熟,但是知道个基础即可。
大家可以关注我的微信公众号:Java菜鸟进阶之路
一:Solr简介
Solr是一个独立的企业级搜索应用服务器,它对外提供类似于Web-service的API接口。用户可以通过http请求,向搜索引擎服务器提交一定格式的XML文件,生成索引;也可以通过Http Get操作提出查找请求,并得到XML格式的返回结果。
Solr是一个高性能,采用Java5开发,
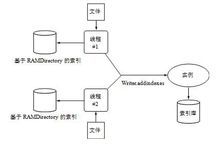 Solr
Solr
基于Lucene的全文搜索服务器。同时对其进行了扩展,提供了比Lucene更为丰富的查询语言,同时实现了可配置、可扩展并对查询性能进行了优化,并且提供了一个完善的功能管理界面,是一款非常优秀的全文搜索引擎
二:Solr服务器的搭建
步骤:
(1)在磁盘中创建一个文件目录,即认为该文件为Solr服务器的相关属性。
(2)在上述的文件目录中,复制一个Tomcat服务器(最好是纯净的,即webapps目录下不包含多余的项目)
(3)从lucene.apache.org官网或者其他资源网下载Solr资源(由于Solr目前更新都很频繁,差不多是两个月就有新版本,而且对于Solr4和Solr5之间存在着不同,所以这个根据需要下载版本吧。我用的是Solr4版本中的4.10.3版本)
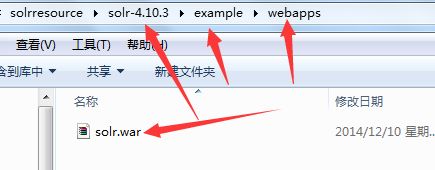
(4)将下载的solr中,进入下图的目录,然后将war包拷贝到Tomcat中的webapps下面
(5)解压拷贝过去的war包,并将解压完成之后,将之前的war包进行删除,原因就是我们需要修改解压的内容,否则不删除,在部署之后又会覆盖,所以要进行删除处理。
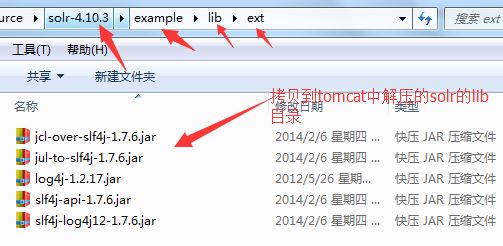
(6)从下载好的solr中的下面的目录,将jar包拷贝到Tomcat下的solr中的lib目录
(7)创建一个Solr服务器的核心家文件夹,并将其与tomcat保持同级。

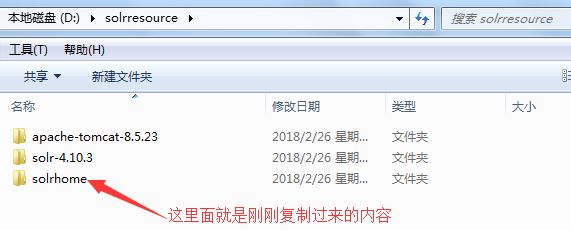
(8)修改tomcat目录webapps下的solr的web.xml文件内容,修改solr核心家的内容
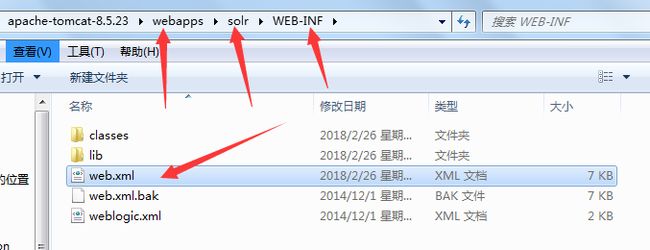

(9)运行tomcat

(10)运行成功后,访问链接http://localhost:8080/solr 即可进入到solr服务器的首页。
三:Solr服务器配置中文分词器
步骤:
(1)拷贝中文分词器IK分词包到Solr服务中的lib目录中

(2)在Solr中的WEB-INF下面创建classes文件目录,用于存放中文分词器的分词配置

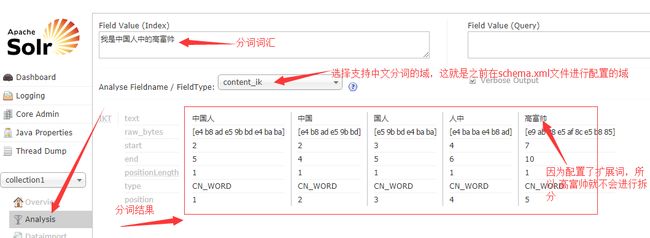
ext.dic的内容,比如如下:
高富帅
黑马程序员
二维表这样的话,碰到这样的词就不会进行拆分了,所以,一些网络新词就可以在这里进行配置。
IKAnalyer.cfg.xml文件
IK Analyzer 扩展配置
ext.dic;
stopword.dic;
stopwords.dic内容:
我
是
的
a
an
and
are
as
这样的话,对于上面的字就不会进行显示处理了,因为这些都是没有意义的词汇。
(3)在核心solr家中,找到配置文件schema.xml,添加中文分词器的配置。
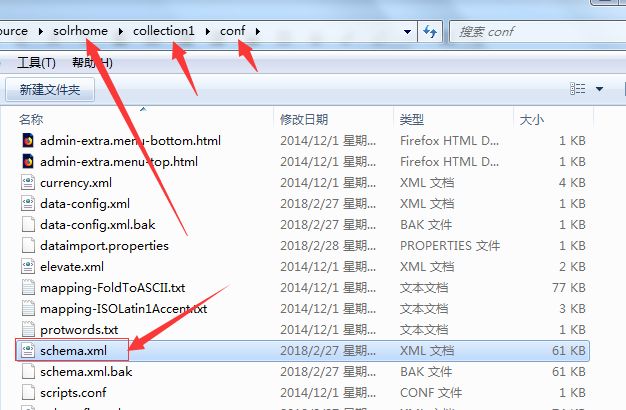
添加如下内容:
(4)重启tomcat,进行测试是否配置完成。
(5)访问Solr主页,进行测试
四:配置solr服务器导入数据库数据
步骤:
(1)导包
首先是需要在solr的核心库中添加一些导入数据的包,需要如下:

注意:因为在collection中,最初是没有lib这个文件目录的,所以需要自己创建一个lib目录,然后把相应的jar包添加进去。

(2)在collection中的config目录下的solrconfig.xml中添加数据导入处理器
data-config.xml
(3)在collection中的config目录添加一个data-config.xml(这个与上面一步配置的名字要相同)
备注:上面的内容,其实一看就大体明白了什么意思,主要就是配置要导入哪个数据库,导入的字段有什么,如果不配置的话,那么solr服务器是无法判断得到的字段的,所以需要进行配置,相当于一个映射配置。
注意:我上面的entity里面的内容就是我需要导入数据的字段的些内容,所以,根据需求进行自行匹配。
(4)在collection中config目录下的schema.xml添加如下内容:(这个是为了能够便于对导入数据库中的数据,与solr中的域进行匹配,因为我们都知道,如果solr域中不存在相应的域,那么是无法进行查询修改删除操作的,那么就不利于我们在以后的项目中对数据库相应字段的处理,所以,这一步是可有可无,但是配置了就有很多的好处)
(5)重启tomcat,然后登陆solr服务
(6)进行添加数据的处理
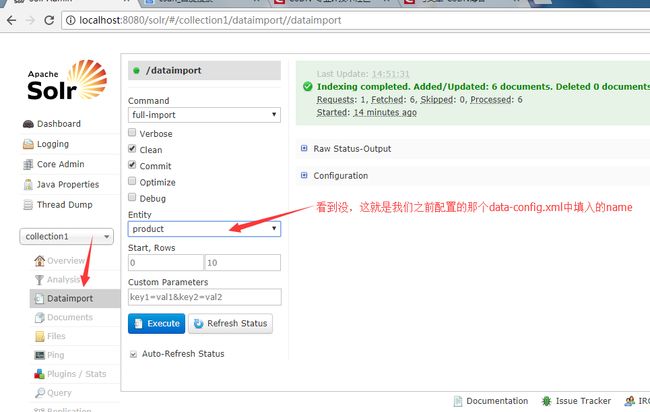
(7)点击上面图中的Execute按钮即可进行数据的导入了,然后再进去Query就可查询到导入的数据了哦!!
五:SolrJ进行数据的增删改查的处理
package com.hnu.scw.solr;
import java.io.IOException;
import java.util.List;
import java.util.Map;
import org.apache.solr.client.solrj.SolrQuery;
import org.apache.solr.client.solrj.SolrServer;
import org.apache.solr.client.solrj.SolrServerException;
import org.apache.solr.client.solrj.SolrQuery.ORDER;
import org.apache.solr.client.solrj.impl.HttpSolrServer;
import org.apache.solr.client.solrj.response.QueryResponse;
import org.apache.solr.common.SolrDocument;
import org.apache.solr.common.SolrDocumentList;
import org.apache.solr.common.SolrInputDocument;
import org.junit.Test;
/**
* solrj的相关开发
* @author scw
*2018-02-26
*/
public class SolrManager {
/**
* 添加文档数据到solr服务器中
* @throws Exception
*/
@Test
public void addContent() throws Exception{
//设置solr服务器的路径,默认是使用第一个collection库,所以路径最后可以不加collection1
String baseURL = "http://localhost:8080/solr";
//如果要使用第二个collection库,那么就使用下面的链接
//String baseURL2 = "http://localhost:8080/solr/collection2";
//创建服务器连接对象
HttpSolrServer httpSolrServer = new HttpSolrServer(baseURL);
//创建新的文档对象
SolrInputDocument solrInputDocument = new SolrInputDocument();
//设置文档的域
solrInputDocument.setField("id", "haha222");
solrInputDocument.setField("name", "佘超伟123");
//进行添加
httpSolrServer.add(solrInputDocument);
//进行手动提交,否则无法进行添加
httpSolrServer.commit();
}
/**
* 进行删除文档操作
* @throws SolrServerException
* @throws IOException
*/
@Test
public void deleteContent() throws Exception{
String baseURL = "http://localhost:8080/solr";
SolrServer httpSolrServer = new HttpSolrServer(baseURL);
//删除全部,第一个参数是设置需要删除的数据的域和值,第二个是执行后多久进行删除操作
//httpSolrServer.deleteByQuery("*:*",1000);
//删除某个特定域的特定值的数据
httpSolrServer.deleteByQuery("id:haha",1000);
}
/**
* 修改文档内容
* 修改其实和添加是一样的,因为只要添加的ID是一样的,那么就会把原来的删除了,然后再添加一个
* @throws IOException
* @throws SolrServerException
*/
@Test
public void updateContent() throws SolrServerException, IOException{
String baseURL = "http://localhost:8080/solr";
SolrServer httpSolrServer = new HttpSolrServer(baseURL);
//创建新的文档对象
SolrInputDocument solrInputDocument = new SolrInputDocument();
//设置文档的域
solrInputDocument.setField("id", "haha123");
solrInputDocument.setField("name", "哈哈123");
httpSolrServer.add(solrInputDocument);
}
/**
* 查询数据(多功能的显示处理)
* @throws Exception
*/
@Test
public void queryContent() throws Exception{
String baseURL = "http://localhost:8080/solr";
SolrServer httpSolrServer = new HttpSolrServer(baseURL);
//创建查询数据对象(便于设置查询条件)
SolrQuery solrQuery = new SolrQuery();
//设置查询的域和值,这个在之后的项目中可以用于动态
//方法一:参数q就代表query查询
//solrQuery.set("q","name:佘超伟123");
//方法二:(一般使用该方法)
solrQuery.setQuery("name:佘超伟");
//方法三:通过设置默认域
//solrQuery.set("df", "name");
//solrQuery.setQuery("佘超伟");
//设置查询过滤条件(可以设置多个,只要域和值有改变就可以了)
//solrQuery.set("fq", "id:haha123");
//添加排序方式(可选内容)
//solrQuery.addSort("需要排序的域",ORDER.asc);//升序
//solrQuery.addSort("需要排序的域",ORDER.desc);//降序
//设置分页处理(比如这是设置每次显示5个)
solrQuery.setStart(0);
solrQuery.setRows(5);
//设置只查询显示指定的域和值(第二个参数可以是多个,之间用“逗号”分割)
//solrQuery.set("fl", "name");
//设置某域进行高亮显示
solrQuery.setHighlight(true);
solrQuery.addHighlightField("name");
//设置高亮显示格式的前后缀
solrQuery.setHighlightSimplePre("");
solrQuery.setHighlightSimplePost(">> highlighting = query.getHighlighting();
//遍历结果集
for (SolrDocument solrDocument : results) {
String idStr = (String) solrDocument.get("id");
System.out.println("id----------------" + idStr);
String nameStr = (String) solrDocument.get("name");
System.out.println("name----------------" + nameStr);
System.out.println("===========高亮显示=====================");
Map> map = highlighting.get(idStr);
List list = map.get("name");
String resultString = list.get(0);
System.out.println("高亮结果为:-----" + resultString);
}
}
} 六:Solr服务器中的后台数据的增删改查处理
这个其实就类似SolrJ的代码,代码看懂的话,这个后台操作是一样的,而且不需要进行代码处理,相对更加方便,但是对于实际的项目开发中,这样肯定是不好的,所以还是需要通过代码进行编写更为有效。
七:京东商城的站内搜索项目实践
效果图:

步骤:
(1)环境搭建-------SpringMVC+Solr+mysql
1:导包------Springmvc+Solr+数据库驱动的jar包
2:编写web.xml文件
JingDongSolr
index.html
index.htm
index.jsp
default.html
default.htm
default.jsp
CharacterEncodingFilter
org.springframework.web.filter.CharacterEncodingFilter
encoding
utf-8
CharacterEncodingFilter
/*
JingDongSolr
org.springframework.web.servlet.DispatcherServlet
contextConfigLocation
classpath:springmvc.xml
1
JingDongSolr
/
3:编写springmvc.xml
4:编写jsp,css,js和添加需要的图片资源
product_list.jsp-------------显示商品信息,即主页
<%@ page language="java" contentType="text/html; charset=UTF-8"
pageEncoding="UTF-8"%>
<%@ taglib prefix="c" uri="http://java.sun.com/jsp/jstl/core"%>
<%@ taglib prefix="fmt" uri="http://java.sun.com/jsp/jstl/fmt" %>
T恤 - 商品筛选
北京市公安局朝阳分局备案编号110105014669 | 京ICP证070359号 | 互联网药品信息服务资格证编号(京)-非经营性-2011-0034
音像制品经营许可证苏宿批005号| 出版物经营许可证编号新出发(苏)批字第N-012号 | 互联网出版许可证编号新出网证(京)字150号
网络文化经营许可证京网文[2011]0168-061号Copyright © 2004-2015 京东JD.com 版权所有
京东旗下网站:English Site




(2)代码开发
实体pojo:
商品实体类:
package com.hnu.scw.model;
/**
* 商品实体
* @author scw
*
*/
public class ProductModel {
// 商品编号
private String pid;
// 商品名称
private String name;
// 商品分类名称
private String catalog_name;
// 价格
private float price;
// 商品描述
private String description;
// 图片名称
private String picture;
public String getPid() {
return pid;
}
public void setPid(String pid) {
this.pid = pid;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public String getCatalog_name() {
return catalog_name;
}
public void setCatalog_name(String catalog_name) {
this.catalog_name = catalog_name;
}
public float getPrice() {
return price;
}
public void setPrice(float price) {
this.price = price;
}
public String getDescription() {
return description;
}
public void setDescription(String description) {
this.description = description;
}
public String getPicture() {
return picture;
}
public void setPicture(String picture) {
this.picture = picture;
}
}检索实体类:
package com.hnu.scw.model;
/**
* 搜索商品的实体类
* @author scw
*
*/
public class ProductSearch {
private String queryString; //关键字
private String catalog_name; //类别
private String price; //价格
private String sort; //排序类型
public String getQueryString() {
return queryString;
}
public void setQueryString(String queryString) {
this.queryString = queryString;
}
public String getCatalog_name() {
return catalog_name;
}
public void setCatalog_name(String catalog_name) {
this.catalog_name = catalog_name;
}
public String getPrice() {
return price;
}
public void setPrice(String price) {
this.price = price;
}
public String getSort() {
return sort;
}
public void setSort(String sort) {
this.sort = sort;
}
}dao层:
package com.hnu.scw.dao;
import java.util.List;
import com.hnu.scw.model.ProductModel;
import com.hnu.scw.model.ProductSearch;
public interface SearchProductDao {
public List searchProduct(ProductSearch productSearch) throws Exception;
}
package com.hnu.scw.dao.impl;
import java.util.ArrayList;
import java.util.List;
import java.util.Map;
import org.apache.solr.client.solrj.SolrQuery;
import org.apache.solr.client.solrj.SolrQuery.ORDER;
import org.apache.solr.client.solrj.SolrServer;
import org.apache.solr.client.solrj.SolrServerException;
import org.apache.solr.client.solrj.response.QueryResponse;
import org.apache.solr.common.SolrDocument;
import org.apache.solr.common.SolrDocumentList;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Repository;
import com.hnu.scw.dao.SearchProductDao;
import com.hnu.scw.model.ProductModel;
import com.hnu.scw.model.ProductSearch;
@Repository
public class SearchProductDaoImpl implements SearchProductDao {
//通过springmvc来进行注入solr服务器
@Autowired
private SolrServer solrServer;
@Override
public List searchProduct(ProductSearch productSearch) throws Exception {
SolrQuery solrQuery = new SolrQuery();
//设置关键字
solrQuery.setQuery(productSearch.getQueryString());
//设置默认检索域
solrQuery.set("df", "product_keywords");
//设置过滤条件
if(null != productSearch.getCatalog_name() && !"".equals(productSearch.getCatalog_name())){
solrQuery.set("fq", "product_catalog_name:" + productSearch.getCatalog_name());
}
if(null != productSearch.getPrice() && !"".equals(productSearch.getPrice())){
//0-9 50-* 对价格进行过滤
String[] p = productSearch.getPrice().split("-");
solrQuery.set("fq", "product_price:[" + p[0] + " TO " + p[1] + "]");
}
// 价格排序
if ("1".equals(productSearch.getSort())) {
solrQuery.addSort("product_price", ORDER.desc);
} else {
solrQuery.addSort("product_price", ORDER.asc);
}
// 分页
solrQuery.setStart(0);
solrQuery.setRows(16);
// 只查询指定域
solrQuery.set("fl", "id,product_name,product_price,product_picture");
// 高亮
// 打开开关
solrQuery.setHighlight(true);
// 指定高亮域
solrQuery.addHighlightField("product_name");
// 前缀
solrQuery.setHighlightSimplePre("");
solrQuery.setHighlightSimplePost("");
// 执行查询
QueryResponse response = solrServer.query(solrQuery);
// 文档结果集
SolrDocumentList docs = response.getResults();
Map>> highlighting = response.getHighlighting();
List productModels = new ArrayList();
for (SolrDocument doc : docs) {
ProductModel productModel = new ProductModel();
productModel.setPid((String) doc.get("id"));
productModel.setPrice((Float) doc.get("product_price"));
productModel.setPicture((String) doc.get("product_picture"));
Map> map = highlighting.get((String) doc.get("id"));
List list = map.get("product_name");
productModel.setName(list.get(0));
productModels.add(productModel);
}
return productModels;
}
} service层:
package com.hnu.scw.service;
import java.util.List;
import com.hnu.scw.model.ProductModel;
import com.hnu.scw.model.ProductSearch;
public interface SearchProductService {
public List searchProduct(ProductSearch productSearch) throws Exception;
}
package com.hnu.scw.service.impl;
import java.util.List;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Service;
import com.hnu.scw.dao.impl.SearchProductDaoImpl;
import com.hnu.scw.model.ProductModel;
import com.hnu.scw.model.ProductSearch;
import com.hnu.scw.service.SearchProductService;
@Service
public class SearchProductImpl implements SearchProductService{
@Autowired
private SearchProductDaoImpl searchProductDaoImpl;
@Override
public List searchProduct(ProductSearch productSearch) throws Exception {
return searchProductDaoImpl.searchProduct(productSearch);
}
} controller层:
package com.hnu.scw.controller;
import java.util.List;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Controller;
import org.springframework.ui.Model;
/**
* 进行商品搜索处理(通过solr)
* @author scw
*2018-02-27
*/
import org.springframework.web.bind.annotation.RequestMapping;
import com.hnu.scw.model.ProductModel;
import com.hnu.scw.model.ProductSearch;
import com.hnu.scw.service.impl.SearchProductImpl;
@Controller
public class SearchProductController {
@Autowired
private SearchProductImpl searchProductImpl ;
/**
* 对于搜索的处理,包括关键字,价格,类别,还有排序方式
* @param productSearch
* @return
* @throws Exception
*/
@RequestMapping(value="/list")
public String searchProduct(ProductSearch productSearch , Model model) throws Exception{
//获取到检索的所有结果
List searchProducts = searchProductImpl.searchProduct(productSearch);
//设置回显内容
model.addAttribute("productModels", searchProducts);
model.addAttribute("queryString", productSearch.getQueryString());
model.addAttribute("catalog_name", productSearch.getCatalog_name());
model.addAttribute("price", productSearch.getPrice());
model.addAttribute("sort", productSearch.getSort());
return "product_list";
}
} (3)进行测试
注意事项:
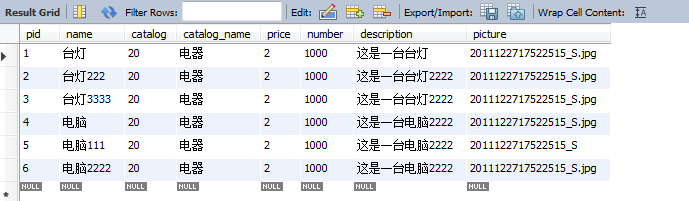
第一点:商品的信息最初是存放在mysql数据库中,而要实现Solr的站内搜索,就需要把数据库中的商品数据导入到Solr服务器中,这个在上面的知识点已经提到过了,所以就不多介绍,可以翻到上面进行查阅。大体的数据如下:
第二点:因为,这是单机的Solr检索,而且Solr服务器也是在本地开启的,而现在又有一个Web项目,所以端口就需要进行修改下,我这里Solr服务器是用的8080端口,而Web项目是用的8081端口。。修改端口方式如下:

进行测试,访问项目链接,
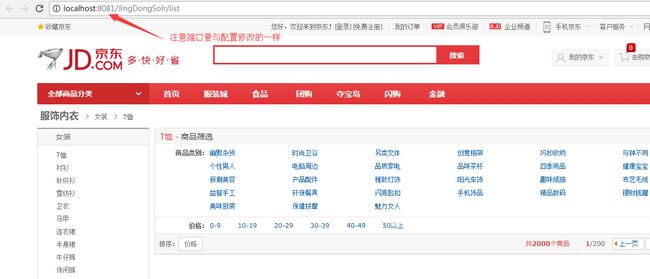
由于我本身的数据中就只有部分,所以,我进行检索台灯,得到如下的结果:
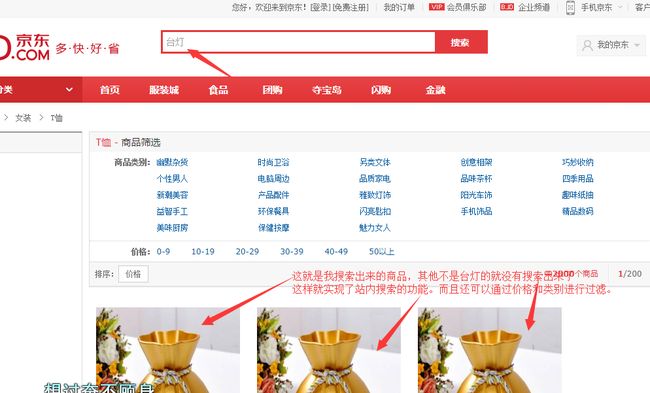
如果有需要这个Demo的小伙伴,那么可以通过百度云链接来进行获取,如果写得不明白的地方,也欢迎各位进行交流。
https://pan.baidu.com/s/1dRClm2 密码:olio
好了,对于Solr的单机运行就到这里了,当然,比如像真正的京东和淘宝,都不是单机的Solr,肯定是集群的,这样的话,又存在着有不同的地方,另外,还有一种比较好的搜索架构也是挺不错的---Elasticsearch,它也是基于Lucene的系统架构,但是是一种分布式的检索,所以,与Solr各有优势,这个就需要看具体的需求来决定了。总而言之,技术没有总结,只有不断的努力学习和研究。。。。。