吴恩达深度学习笔记四:卷积神经网络 基础和目标检测部分
1、卷积神经网络(CNN:Convolutional neural network):
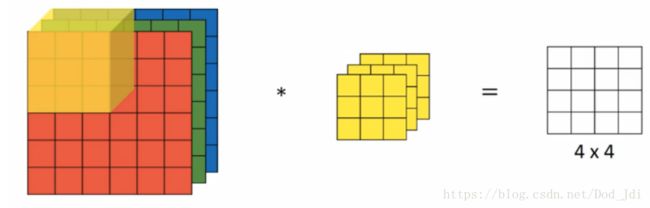
卷积运算:矩阵对应位元素相乘然后相加,主要作用是特征提取和减少参数。深度学习中使用的是“互相关”卷积,即不进行偏转的卷积。
滤波器(fliter):也叫“核(kernel)”,使用具有不同参数的滤波器可以检测图片中 垂直、水平边缘等 特征。
两个重要的特征,可以有效解决计算机视觉等存在的参数过多速度慢和过拟合等问题:
参数共享:一次图片遍历卷积使用的滤波器参数相同,即相当于一次使用同一个滤波器在图片所有区域进行卷积,这是因为滤波器参数决定的特征提取方式如垂直边缘提取可能是共同有效的。
稀疏连接:一个图中像素点只和特定的滤波器连接进行卷积操作。
padding填充:使用0在原图边界上进行扩展填充,每个方向扩展 p 像素,进行步长为 1 大小为 f 的卷积时,得到的特征图大小为:
- Valid 卷积: 不填充直接进行卷积, (n−f+1)∗(n−f+1),变小。 ( n − f + 1 ) ∗ ( n − f + 1 ) , 变 小 。
- same 卷积: 进行填充使大小不变的卷积,即 (n+2p−f+1)=n ( n + 2 p − f + 1 ) = n , 所以 p=f+12。 p = f + 1 2 。
使用padding,可以使图片不会过早的变得太小,也能避免边缘区域的权重过小。
Stride 步长: 滤波器在原始图片上每次水平或垂直移动的距离。
卷积大小的计算,滤波器大小为 f ,步长为 s , 填充为 p, 输入图片为 n×n n × n ,则卷积得到的特征图大小为, 下标 f 表示向下取整:
一个经典的卷积网络通常包含:卷积层(Convolutional layer),池化层(Pooling layer)和全连接层(FC:fully connected layer)。
池化层(pooling):其作用通过保留聚合提取的显著特征的,缩小图片达到缩小模型和减小噪声的目的。常用最大池化(Max pooling)保留一个区域中的最大值, 平均池化(Aver pooling)保留一个区域中的平均值。
由于一般池化层只具有大小和步长等超参数,没有需要学习的参数,所以一般在计算网络层数时,将其和卷积层作为一层。
高维卷积:在不同通道(channel)或者深度(depth)上分别进行卷积,然后将同一区域不同维度的卷积结果相加形成一维的。
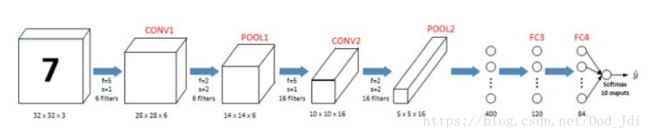
CNN模型实例:
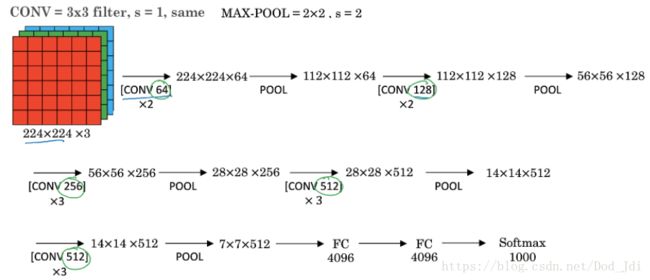
2、实例探究
主要讲了LeNet、ALexnet、VGG、ResNets和GoogLeNet (Inception), 详细的对比可以参看转载的一篇文章:http://mp.blog.csdn.net/postedit/78379855
VGG是一个很规则的网络,非常适合作为入门。其网络的规整在于使用了传统的网络结构:卷积–>最大池化—>全连接 结构的,并且体现了CNN中随着层数的增加,卷积得到的特征图(Feature Map)不断变小(即n_W和n_H变小),而通道数(也叫深度, 前文的n_C)增加的特性。
ResNets残差网络(Residual Nets): 将一层的输出 al a l 跨越一层或多层参加到下一层的激活函数当中,如 al+2=g(zl+2+al) a l + 2 = g ( z l + 2 + a l ) , 这和L2正则化类似作用也类似,可以有效避免梯度消失或爆炸、避免某些参数过大导致过拟合等情况。另外还可以更好的学习残差块中间的特征。

Inception网络:主要使用了 1x1 的filter(滤波器)减小计算量,增加模型的灵活度。
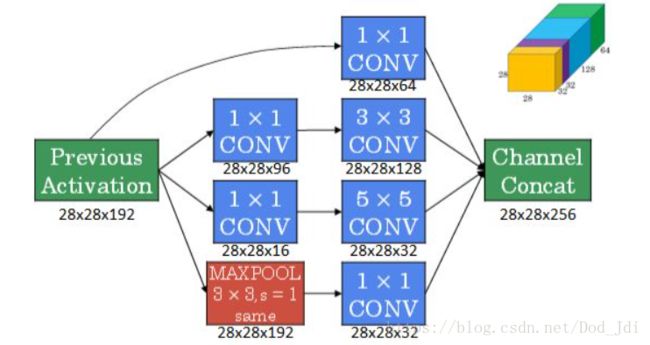
目前 Inception 的主要影响在于 1x1 卷积的应用,这一层也成为”瓶颈层(Bottleneck layer)”,即连接两边较大的层,通过same模型的卷积和改变通道的数量,将“大乘大”的计算变为“大乘小 + 小成大”,可以减少10倍左右的计算量(参数个数乘上大小)。如下图如果不使用 1x1的卷积,计算量为 (5x5)x(28x28)x192x32=1.2亿, 使用 1x1 后为 (1x1)x(28x28)x192x16 + (5x5)x(28x28)x16x32=0.1亿。这样理解,特征的种类是有限的,输出32个map是为了后面能够得到更多的组合方式,其实这些map有的差异很小,使用1x1提取复制,再进行特征提取就减少了工作量。

另外GoogLeNet在部分中间层增加了子输出单元,包括连接层和softmax等。
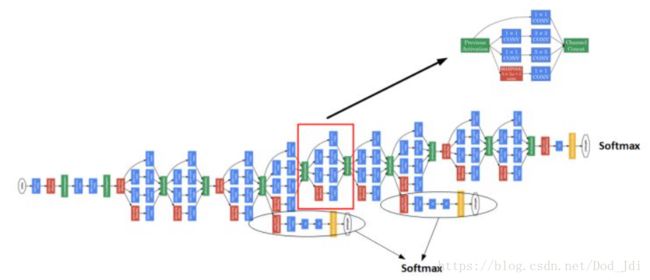
3、目标检测(Object Detection)
目标检测主要将图片或视频中的一个或多个物体定位并进行分类,进行目标检测模型的训练需要准备标注好的数据。如下图,bx和by一般指标注框 box 的中心点,且这些数据一般以比例的形式表示,这样: 0<bx,by<1 0 < b x , b y < 1 且 bw,bh>0 b w , b h > 0 。
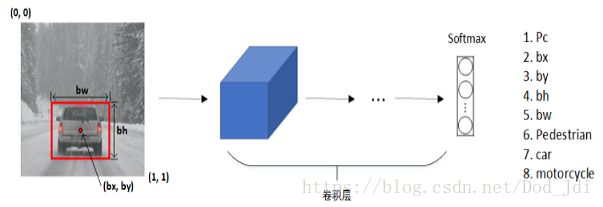
其中Pc表示该box是否包含有效类,0表示背景后面的数据作用不大,1表示有效,在坐标的后面以 ont-hot 编码 标识了所包含的类别。例子如下:

滑动窗口法(Sliding Windows),如R-CNN等,使用人为设定每次设定不同的窗口大小在图片上滑动遍历,通过线性或卷积运算检测窗口中是否包含物体,这个方法的问题在于人为设定的反锁,窗口大小形状相对固定预测框可能不够准确,计算量大等。
其中Fast R-CNN使用卷积运算加快速度,Faster R-CNN使用卷积找出图片的色块以出划定候选框,然后通过卷积进行分类,改善了候选框的选择效率。

上图体现了如何通过卷积进行窗口计算的思想,即蓝色色块在卷积过程中始终代表输入层的蓝色部分的特征。这也是卷积思想的重要体现,即将某部分区域不断提取深层次的特征并缩小面积,最后参与到全连接层的计算当中,而一个输入区域会往往有多个这样的全连接层的特征块,也就是说一个区域会参与多种不同的运算,这样既能提升了预测的准确性,又能够进行多分类任务。但由于全连接“小块“代表了固定的“大块”, 也使得Fast R-CNN预测框不够准确的问题。(后面部分是个人理解,视频中好像没有提到类似的说法,错了的请指教。)
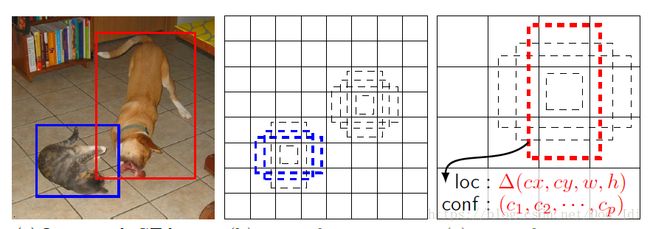
YOLO(You Look Only Once):为了能够将定位和分类的问题只通过一次完整(only once)的计算解决,YOLO算法将图片划分为 n×n n × n 的网格(grid cell), 然后使用类似滑动窗口的思想,使用卷积运算得到这些 cell 的特征图(就是卷积后的图层)且都具有 y 标签,如下图。由该网格学习如何检测该物体。
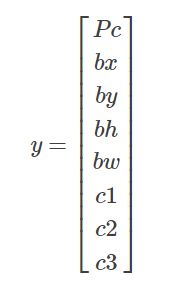
IoU(Intersection Over Union, 交集于并集比例): 评价以某个网格为中心检测的物体范围和物体表标注框的相和度。以下图为例,I 为绿色区域, U为两个集合点全部区域。 IoU=I/U I o U = I / U 。通过阀值进行分配,如 Iou > 0.5 时将上图中的 Pc = 1, 否则为0。

非最大抑制(Non-max Suppression):在检测过程中,由于网格密度一般较大,可能会有多个网格检测到同一区域内的一个或多个物体。这时候就需要计算以该网格为锚点的预测区域和物体的相合度,取最大者作为最终的锚点。类似于先在网格内进行分类(有Pc=1无Pc=0),然后以遍历 形式计算一个网格中心的预测范围(如下文的anchor box)内的Pc值和,取最大值然后剔除该网格附近 Iou>0.5 的区域。重复上述操作直至每个物体中心对应一个网格。
(思路大概是这样,不过实现的时候是在训练过程通过IoU等计算anchor box的置信度(confidence),然后乘以该box包含各个类的概率,最终确定哪个box表示哪个类,部分练习有关的代码见最后面)

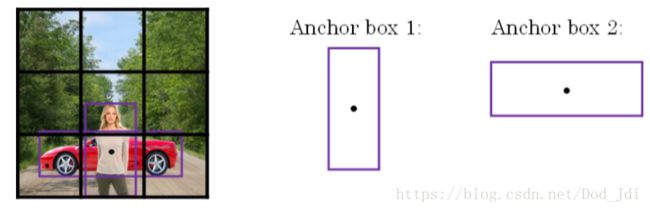
Anchor Boxes(锚箱):改进多个物体位置相近的情况。以网格为中心进行IoU和非最大抑制时,如果有多个物体在临近区域(虽然网格密度越大概率越低)那么一个网格为了获取更大的Pc值会偏向于作为更大物体的检测点,这样会使得漏检或者对小物体不友好。Anchor Boxes在划分网格之后,以网格为中心设定不同大小和比例的区域作为锚点,以此来获得不同的pc值,然后用这些区域作为锚点(即 Anchor Boxes)来代替网格作为检测锚点
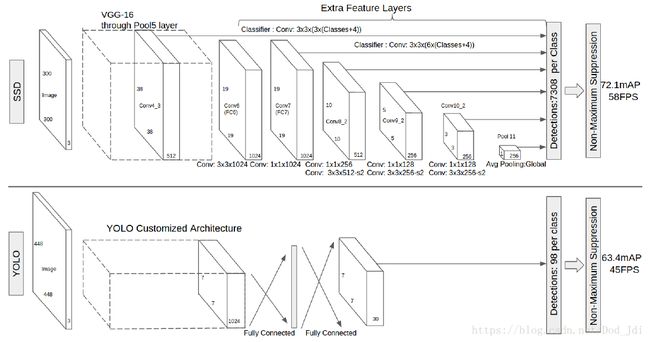
SSD(Single Shot MultiBox Detector): 使用比YOLO更多类型的 Anchor Boxes 来增加识别率和边框的准确性。
SSD还在卷积过程进行截断(分为 Base network 和 Extra feature layers),尝试将一部分较容易识别的物体在浅层网络中检测出来,并让一部分特征图继续进行卷积运算增加网络深度,从而提升运行速度和提升小物体或不同分辨率的物体的识别率。而YOLO使用同样大小的Feature Map进行全连接,计算量较大。
上述关于SSD和部分YOLO的内容是我以前看的,然后结合视频写的,可能会有一些理解上的错误。另外YOLO有了新的版本我还没看,这里说的是以前的版本。
YOLO编程作业代码:
yolo.h5下载地址:https://download.csdn.net/download/dod_jdi/10304693
"""
@Author : Peng
@Time : 2018/3/23
info : YOLO的使用, 80个类,5个anchor boxes,Feature Map(19*19)
"""
import numpy as np
import matplotlib.pyplot as plt
import keras
import tensorflow as tf
import os
import scipy.misc
from LearningDL.task4_3.yad2k.models import keras_darknet19, keras_yolo
from LearningDL.task4_3 import yolo_utils
import keras.backend as K
K.set_image_data_format('channels_last')
def yolo_filters_boxes(box_confidence, boxes, box_class_probs, threshold=0.6):
"""
通过阀值过滤候选框
:param box_confidence: shape[19,19,5,1], 包含19*19个单元中每5个anchor boxes的置信度, 训练出来的
:param boxes: shape[19.19,5,4], 包含19*19个单元每个对应的5个anchor boxes的[bx, by, bh, bw]
:param box_class_probs: shape[19, 19, 5, 80], 包含每个anchor boxes中含有80个类的概率系数
:param threshold: IoU阀值
:return: scores, boxes, classes, 选定的boxes对应的分数、位置和包含类
"""
box_scores = box_confidence * box_class_probs # shape[19,19,5,80]
box_classes = K.argmax(box_scores, axis=-1) # argmax返回最大值的“坐标”, 标识类, shape[19,19,5]
box_class_scores = K.max(box_scores, axis=-1) # max 返回最大值“的值”, 标识值, shape[19,19,5]
# 使用掩码获取IoU不小于阀值的anchor boxex及相关信息,即将19x19x5个box符合条件的写到一个列表中,shape[None,?]
filtering_mask = (box_class_scores >= threshold) # shape[19,19,5]
# [19,19,5] -> (?,) ?表示不确定,逗号后面没有数据表示一维
scores = tf.boolean_mask(box_class_scores, filtering_mask)
# (?,4)
boxes = tf.boolean_mask(boxes, filtering_mask)
# (?,)
classes = tf.boolean_mask(box_classes, filtering_mask)
return scores, boxes, classes
def iou(box1, box2):
"""
iou算法的实现
:param box1: 包含左上角坐标和右下角坐标(x1,y1,x2,y2)
:param box2: 包含左上角坐标和右下角坐标(x1,y1,x2,y2)
:return:
"""
# 求交集的左上和右下坐标,往中间“挤”
x1 = max(box1[0], box2[0])
y1 = max(box1[1], box2[1])
x2 = min(box1[2], box2[2])
y2 = min(box1[3], box2[3])
inter_area = np.abs(x2 - x1) * np.abs(y2 - y1) # 求交集面积,np.abs绝对值
box1_area = np.abs(box1[2] - box1[0]) * np.abs(box1[3] - box1[1])
box2_area = np.abs(box2[2] - box2[0]) * np.abs(box2[3] - box2[1])
union_area = box1_area + box2_area - inter_area
iou_value = inter_area / union_area
return iou_value
def yolo_non_max_suppression(scores, boxes, classes, max_boxes=10, iou_thsehold=0.5):
"""
非最大值抑制算法保留最佳boxes
:param scores: shape(None,),boxes含有某个类的概率
:param boxes: shape(None,4),boxes列表
:param classes: shape(None,),boxes含有的是什么类
:param max_boxes: int,保留少个max_boxes
:param iou_thsehold: float, 阀值
:return: scores[,None], boxes[4, None], classes[, None]
"""
max_boxes_tensor = K.variable(max_boxes, dtype=tf.int32)
K.get_session().run(tf.variables_initializer([max_boxes_tensor]))
# 获取非最大值过滤索引列表
nms_indices = tf.image.non_max_suppression(boxes, scores, max_boxes, iou_thsehold)
# 按索引抽取聚集
scores = K.gather(scores, nms_indices)
boxes = K.gather(boxes, nms_indices)
classes = K.gather(classes, nms_indices)
return scores, boxes, classes
def yolo_eval(yolo_outputs, image_shape=(720., 1280.), max_boxes=10, score_threshold=0.6, iou_threshold=0.5):
"""
将YOLO的预测框输出使用我们的过滤算法得到最终的scores,boxes,classes
YOLO 没有将非最大抑制算法作为核心部分,这里使用的YOLO预训练模型其输出结果仍然是未过滤的可能重叠的anchor boxes
:param yolo_outputs:
:param image_shape:
:param max_boxes:
:param score_threshold: 取最大值然后抛弃其他 scores>score_threshold 的boxes
:param iou_threshold:
:return:
"""
# 获取yolo的输出
box_confidence, box_xy, box_wh, box_class_probs = yolo_outputs
# 将(中点,宽高)改为坐标形式
boxes = keras_yolo.yolo_boxes_to_corners(box_xy, box_wh)
# 使用前面定义的过滤算法
scores, boxes, classes = yolo_filters_boxes(box_confidence, boxes, box_class_probs, score_threshold)
# 缩放图片以进行boxes标记
boxes = yolo_utils.scale_boxes(boxes, image_shape)
scores, boxes, classes = yolo_non_max_suppression(scores, boxes, classes, max_boxes, iou_threshold)
return scores, boxes, classes
def unit_test():
""" yolo_filters_boxes 通过阀值过滤候选框测试"""
# with tf.Session() as session:
# box_confidence = tf.random_normal([19, 19, 5, 1], mean=1, stddev=4, seed=1)
# boxes = tf.random_normal([19, 19, 5, 4], mean=1, stddev=4, seed=1)
# box_class_probs = tf.random_normal([19, 19, 5, 80], mean=1, stddev=4, seed=1)
# scores, boxes, classes = yolo_filters_boxes(box_confidence, boxes, box_class_probs, threshold=0.5)
# print("scores[2] = " + str(scores[2].eval()))
# print("boxes[2] = " + str(boxes[2].eval()))
# print("classes[2] = " + str(classes[2].eval()))
# print("scores.shape = " + str(scores.shape))
# print("boxes.shape = " + str(boxes.shape))
# print("classes.shape = " + str(classes.shape))
""" IoU 测试 """
# box1 = (2, 1, 4, 3)
# box2 = (1, 2, 3, 4)
# print('iou value is {}'.format(iou(box1, box2)))
"""yolo_non_max_suppression 非最大值抑制算法预测"""
# with tf.Session() as session:
# scores = tf.random_normal([54, ], mean=1, stddev=4, seed=1)
# boxes = tf.random_normal([54, 4], mean=1, stddev=4, seed=1)
# classes = tf.random_normal([54, ], mean=1, stddev=4, seed=1)
# scores, boxes, classes = yolo_non_max_suppression(scores, boxes, classes)
# print("scores[2] = " + str(scores[2].eval()))
# print("boxes[2] = " + str(boxes[2].eval()))
# print("classes[2] = " + str(classes[2].eval()))
# print("scores.shape = " + str(scores.eval().shape))
# print("boxes.shape = " + str(boxes.eval().shape))
# print("classes.shape = " + str(classes.eval().shape))
""" yolo_eval 过滤boxes的测试 """
with tf.Session() as session:
yolo_outputs = (tf.random_normal([19, 19, 5, 1], mean=1, stddev=4, seed=1),
tf.random_normal([19, 19, 5, 2], mean=1, stddev=4, seed=1),
tf.random_normal([19, 19, 5, 2], mean=1, stddev=4, seed=1),
tf.random_normal([19, 19, 5, 80], mean=1, stddev=4, seed=1))
scores, boxes, classes = yolo_eval(yolo_outputs)
print("scores[2] = " + str(scores[2].eval()))
print("boxes[2] = " + str(boxes[2].eval()))
print("classes[2] = " + str(classes[2].eval()))
print("scores.shape = " + str(scores.eval().shape))
print("boxes.shape = " + str(boxes.eval().shape))
print("classes.shape = " + str(classes.eval().shape))
def predict(sess, image_file, scores, boxes, classes, yolo_model, class_name):
"""
预测
:param sess:
:param image_file:
:param scores:
:param boxes:
:param classes:
:param yolo_model:
:param class_name:
:return:
"""
image, image_data = yolo_utils.preprocess_image("images/" + image_file, model_image_size=(608, 608))
out_scores, out_boxes, out_classes = sess.run([scores, boxes, classes],
feed_dict={yolo_model.input: image_data, K.learning_phase(): 0})
print("Found {} boxes for {}".format(len(out_boxes), image_file))
colors = yolo_utils.generate_colors(class_name)
yolo_utils.draw_boxes(image, out_scores, out_boxes, out_classes, class_name, colors)
image.save(os.path.join("out", image_file), quality=90)
# Display the results in the notebook
output_image = scipy.misc.imread(os.path.join("out", image_file))
plt.imshow(output_image)
plt.show()
return out_scores, out_boxes, out_classes
if __name__ == '__main__':
# unit_test()
# yolo 图片测试
sess = K.get_session()
class_name = yolo_utils.read_classes("model_data/coco_classes.txt")
anchors = yolo_utils.read_anchors("model_data/yolo_anchors.txt")
image_shape = (720., 1280.)
# 加载yolo_v2预训练模型
yolo_model = keras.models.load_model("model_data/yolo.h5")
yolo_model.summary()
# 获取yolo输出
yolo_outputs = keras_yolo.yolo_head(yolo_model.output, anchors, len(class_name))
# 获取过滤后的预测信息
scores, boxes, classes = yolo_eval(yolo_outputs, image_shape)
out_scores, out_boxes, out_classes = predict(sess, "test.jpg", scores, boxes, classes, yolo_model, class_name)
效果:
