【Keras之父】机器学习基础
一. 机器学习的四个分支
1. 监督学习 (supervised learning)
给定一组样本(通常人工标注),它可以学会将输入数据映射到已知目标(也叫标注 annotation)。三种类型的机器学习问题:二分类问题、多分类问题和标量回归问题都是监督学习。比如:光学字符识别、语音识别、图像分类和语言翻译。
虽然监督学习主要包括分类和回归,但有更多的奇特变体,主要包括如下几种:
A. 序列生成(sequence generation) : 给定一张图像,预测描述图像的文字。序列生成有时 可以被重新表示为一系列分类问题,比如反复预测序列中的单词或标记。
B. 语法树预测(syntax tree prediction) : 给定一个句子,预测其分解生成的语法树。
C. 目标检测(object detection) : 给定一张图像,在图中特定目标的周围画一个边界框。这 个问题也可以表示为分类问题(给定多个候选边界框,对每个框内的目标进行分类)或分类与回归联合问题(用向量回归来预测边界框的坐标)。
D. 图像分割(image segmentation) : 给定一张图像,在特定物体上画一个像素级的掩模(mask)。
2. 无监督学习 (unsupervised learning)
指在没有目标的情况下寻找输入数据的有趣变换,其目的在于数据可视化、数据压缩、数据去燥或更好地理解数据中的相关性。无监督学习是数据分析的必备技能,在解 决监督学习问题之前,为了更好地了解数据集,它通常是一个必要步骤。降维(dimensionality reduction)和聚类(clustering)都是众所周知的无监督学习方法。
3. 自监督学习 (Self-supervised learning)
自监督学习是没有 人工标注的标签的监督学习,可以将它看作没有人类参与的监督学习。标签仍然存在(因为总要有什么东西来监督学习过程),但它们是从输入数据中生成的,通常是使用启发式算法生成的。典型例子:
1. 自编码器(autoencoder)是有名的自监督学习的例子,其生成的目标就是未经 修改的输入。
2. 给定视频中过去的帧来预测下一帧,或者给定文本中前面的词来预测下一个词, 都是自监督学习的例子[这两个例子也属于时序监督学习(temporally supervised learning),即用未来的输入数据作为监督]
4. 强化学习 (Reinforcement learning)
在强化学习中,智能体(agent)接收有关其环境的信息,并学会选择使某种奖励最大化的行动。 例如,神经网络会“观察”视频游戏的屏幕并输出游戏操作,目的是尽可能得高分,这种神经 网络可以通过强化学习来训练。
目前,强化学习主要集中在研究领域,除游戏外还没有取得实践上的重大成功。但是,我 们期待强化学习未来能够实现越来越多的实际应用:自动驾驶汽车、机器人、资源管理、教育等。 强化学习的时代已经到来,或即将到来。
二. 评估机器学习模型
机器学习的目的是得到可以泛化(generalize)的模型,而过拟合则是核心难点。我们会将数据划分为 训练集、验证集和测试集 。
- 为什么不是2个集合:一个训练集和一个测试集?
原因在于开发模型时总是需要调节模型配置,比如选择层数或每层大小[这叫作模型的超 参数(hyperparameter),以便与模型参数(即权重)区分开]。这个调节过程需要使用模型在验证数据上的性能作为反馈信号。这个调节过程本质上就是一种学习:在某个参数空间中寻找良好的模型配置。因此,如果基于模型在验证集上的性能来调节模型配置,会很快导致模型在验证集上过拟合,即使你并没有在验证集上直接训练模型也会如此。
造成这一现象的关键在于信息泄露(information leak)。每次基于模型在验证集上的性能来调节模型超参数,都会有一些关于验证数据的信息泄露到模型中。如果对每个参数只调节一次, 那么泄露的信息很少,验证集仍然可以可靠地评估模型。但如果你多次重复这一过程(运行一 次实验,在验证集上评估然后据此修改模型),那么将会有越来越多的关于验证集的信息泄漏到模型中。
最后,你得到的模型在验证集上的性能非常好(人为造成的),因为这正是你优化的目的。 你关心的是模型在全新数据上的性能,而不是在验证数据上的性能,因此你需要使用一个完全不同的、前所未见的数据集来评估模型,它就是测试集。你的模型一定不能读取与测试集有关的任何信息,既使间接读取也不行。如果基于测试集性能来调节模型,那么对泛化能力的衡量 是不准确的。
- 那么如果数据量很小,如何评估???介绍三种典型的评估方法:
1. 简单的留出验证 (Simple Hold-out validation) :
留出一定比例的数据作为测试集,在剩余的数据上训练模型,然后在测试集少评估模型。
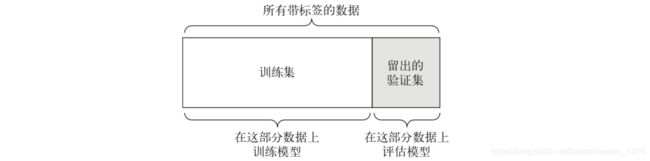
缺点:如果可用的数据很少,那么可能验证集和测试集包含的样本就很少,从而无法在统计学上代表数据。这个很容易发现,如果在划分数据前进行不同的随机打乱( shuffle(data)) ,最终得到的模型性能差别很大。
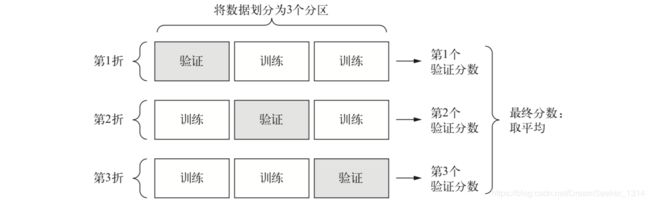
2. K折验证(K-fold validation)
将数据划分为大小相同的K个分区。对于每个分区i,在剩余的K-1 个分区上训练模型,然后在分区i上评估模型。最终分数风雨K个分数的平均值。对于不同的训练集-测试集划分,如果模型性能的变化很大,那么这种方法很有用。K折验证也需要独立的验证集进行模型校正。3折验证如下:
3.带打乱数据的 K折验证(Iterated K-fold validation with shuffle)
具体做法是多次使用 K 折验证,在每次将数据划分为 K 个分区之前都先将数据打乱。最终分数是每次 K 折验证分数的平均值。注意,这种方法一共要训练和评估 P×K 个模型(P 是重复次数),计算代价很大。K一般取值4或5。
- 评估模型的注意事项
1. 数据代表性(data representativeness):在将数据划分为训练集和测试集之前,通常应该随机打乱/Shuffle数据。
2. 时间箭头(the arrow of time): 如果想要根据过去预测未来(比如明天的天气、股票走势 等),那么在划分数据前你不应该随机打乱数据,因为这么做会造成时间泄露(temporal leak): 你的模型将在未来数据上得到有效训练。在这种情况下,你应该始终确保测试集中所有数据的时间都晚于训练集数据。
3. 数据冗余(redundancy): 如果数据中的某些数据点出现了两次(这在现实中 的数据里十分常见),那么打乱数据并划分成训练集和验证集会导致训练集和验证集之 间的数据冗余。从效果上来看,你是在部分训练数据上评估模型,这是极其糟糕的!一定要确保训练集和验证集之间没有交集。
三. 数据预处理 & 特征工程
A. 数据预处理Data preprocessing
1. 向量化 Vectorization:神经网络的所有输入和目标都必须是浮点数张量(在特定情况下可以是整数张量)。无论处理什么数据(声音、图像还是文本),都必须首先将其转换为张量。方法:One-hot编码和填充列表。
2. 值标准化 Value Normalization:一般来说,将取值相对较大的数据(比如多位整数,比网络权重的初始值大很多)或异质数据(heterogeneous data,比如数据的一个特征在 0~1 范围,另一个特征在 100~200 范围) 输入到神经网络中是不安全的。这么做可能导致较大的梯度更新,会导致网络无法收敛。为 了让网络的学习变得更容易,输入数据应具有的特征:

3. 处理缺失值 Handling Missing Value:一般来说,对于神经网络,将缺失值设置为 0 是安全的,只要 0 不是一个有意义的值。网络能够从数据中学到 0 意味着缺失数据,并且会忽略这个值。
【注意】如果测试数据中可能有缺失值,而网络是在没有缺失值的数据上训练的,那么网络不可能学会忽略缺失值。在这种情况下,应该人为生成一些有缺失项的训练样本: 多次复制 一些训练样本,然后删除测试数据中可能缺失的某些特征。
B. 特征工程 Feature Engineering
特征工程(feature engineering)是指将数据输入模型之前,利用关于数据和机器学习算法(如神经网络)的知识对数据进行硬编码的变换(不是模型学到的),以改善模型的效果。多数情况下,一个机器学习模型无法从完全任意的数据中进行学习。呈现给模型的数据应该便于模型进行学习。
其本质是:用更简单的方式表述问题,从而使问题变得更容器。将数据呈现给算法的方式对解决问题至关重要。对于现代深度学习,大部分特征工程都是不需要的,因为神经网络能够从原始数据中自动提取有用的特征。为什么使用DL就不需要担心特征工程???
1.良好的特征仍然可以用更少的资源更优雅地解决问题。例如,使用卷积神经网络来读取钟面上的时间是非常可笑的。
2.良好的特征可以用更少的数据解决问题。深度学习模型自主学习特征的能力依赖于大量的训练数据。如果只有很少的样本,那么特征的信息价值就变得非常重要。
四. 过拟合Overfitting & 欠拟合Underfitting
机器学习的根本问题是优化和泛化之间的对立。优化(optimization)是指调节模型以在训练数据上得到最佳性能(即机器学习中的学习),而泛化(generalization)是指训练好的模型在前所未见的数据上的性能好坏。机器学习的目的当然是得到良好的泛化,但泛化无法控制只能基于训练数据调节模型。
过拟合:随着训练的进行,模型在训练数据上的性能始终在提高,但在前所未见的数据上的性能则不再变化或者开始下降。也就是说训练的太过了,把一些无关的、非重要的特征也训练出来了。
欠拟合:训练数据上的损失越小,测试数据上的损失也越小。即仍有改进的空间,网络还没有对训练数据中所有相关模式建模。也就是说训练数据中还有一些有价值的特征没有训练出来。
~~~~~~~防止神经网络过拟合Overfitting的常用方法~~~~~
1.获取更多的训练数据(最优解)
2. 减小网络容量(最简单的方法)
3. 添加权重正则化(最常见的方法)---L1正则化和L2正则化
4.添加dropout正则化(最有效并且最常用的方法)
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
详细介绍:
1.减小网络大小--reduce the network’s size
防止过拟合的最简单的方法就是减小模型大小,即减少模型中可学习参数的个数(这由层数和每层的单元个数决定 Hyperparameter)。在深度学习中,模型中可学习参数的个数通常被称为模型的容量 (capacity)。直观上来看,参数更多的模型拥有更大的记忆容量(memorization capacity),因此能够在训练样本和目标之间轻松地学会完美的字典式映射,这种映射没有任何泛化能力。
没有一个魔法公式能够确定最佳层数或每层的最佳大小。必须评估一系列不同的网络架构(当然是在验证集上评估,而不是在测试集上),以便为数据找到最佳的模型大小(即在容量过大与容量不足之间要找到一个折中)。一般的工作流程是开始时选择相对较少的层和参数,然后逐渐增加层的大小或增加新层,直到这种增加对验证损失的影响变得很小。
更大网络的训练损失很快就接近于零。网络的容量越大,它拟合训练数据(即得到很小的训练损失)的速度就越快,但也更容易过拟合(导致训练损失和验证损失有很大差异)。
2.添加权重正则化—add weight regularization
奥卡姆剃刀(Occam’s razor):如果一件事情有两种解释,那么最可能正确的解释就是最简单的那个,即假设更小的那个(为啥想起了墨菲定律?!)。给定一些训练数据和一种网络架构,很多组权重值(即很多模型)都可以解释这些数据,简单模型比复杂模型更不容易过拟合。
简单的模型:是指参数值分布的熵(entropy)更小的模型(或参数更少的模型)。一种常见的降低过拟合的方法就是强制让模型权重只能取较小的值, 从而限制模型的复杂度,这使得权重值的分布更加规则(regular),即权重正则化(weight regularization),其实现方法是向网络损失函数中添加与较大权重值相关的成本(cost)。 这个成本有两种形式。
1. L1 正则化(L1 regularization): 添加的成本与权重系数的绝对值[权重的 L1 范数(norm)] 成正比。
2. L2 正则化(L2 regularization): 添加的成本与权重系数的平方(权重的 L2 范数)成正比。 神经网络的 L2 正则化也叫权重衰减(weight decay)。
form keras import regularizers
regularizers.l1(0.001)
regularizers.l1_l2(l1 = 0.001, l2 = 0.001)
L2(0.001)的意思是该层权重矩阵的每个系数都会使网络总损失增加0.001 * weight_ coefficient_value。
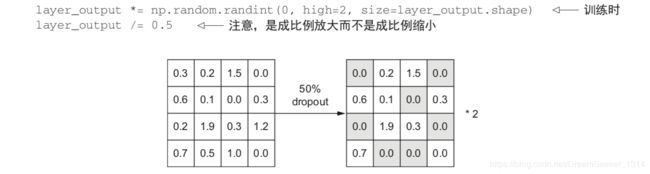
3.添加dropout正则化—add dropout regularization
对某一层使用 dropout,就是在训练过程中随机将该层的一些输出特征舍弃(设置为 0)。假设在训练过程中,某一层对给定输入样本的返回值应该是向量 [0.2, 0.5, 1.3, 0.8, 1.1]。使用 dropout 后,这个向量会有几个随机的元素变成 0,比如 [0, 0.5, 1.3, 0, 1.1]。dropout 比率(dropout rate)是被设为 0 的特征所占的比例,通常在 0.2~0.5 范围内。测试时没有单元被舍弃,而该层的输出值需要按 dropout 比率缩小,因为这时比训练时有更多的单元被激活,需要加以平衡。
题外话:为什么能降低过拟合???灵感来自于银行的防欺诈机制。其核心思想是在层的输出值中引入噪声, 打破不显著的偶然模式(Hinton 称之为阴谋)。如果没有噪声的话,网络将会记住这些偶然模式。
五. 机器学习的通用工作流程
1.定义问题,收集数据集 --Defining the problem and assembling a dataset
- 输入数据是什么?要预测什么?数据可用性通常是这一个阶段的限制因素。
- 什么类型的问题?是二分类问题、多分类问题、标量回归问题、向量回归问题,还是多分类、多标签问题?或者是其他问题,比如聚类、生成或强化学习?确定问题,确定模型架构、Loss函数等。

- 假设输出是可以根据输入进行预测的
- 假设可用数据包含足够多的信息,足以学习输入和输出之间的关系
收集的包含输入 X 和目标 Y 的很多样例,并不意味着 X 包含足够多的信息来预测 Y。例如,如果你想根据某支股票最近的历史价格来预测其股价走势,那你成功的可能性不大,因为历史价格 并没有包含很多可用于预测的信息。并非所有问题都可以解决:有一类无法解决的问题,那就是非平稳问题(nonstationary problem) 。
机器学习只能用来记忆训练数据中存在的模式,只能识别出曾经见过的东西。 在过去的数据上训练机器学习来预测未来,这里存在一个假设,就是未来的规律与过去相同。 但事实往往并非如此。
2.选择衡量成功的指标-- Choosing a measure of success
成功的指标:精度? 准确率(precision)和召回率(recall)? 客户保留率?衡量成功的指标影响如何选择损失函数,即模型要优化什么。
1. 平衡分类问题(balanced-classification problem)---> 精度和接收者操作特征曲线下面积(area under the receiver operating characteristic curve,ROC AUC)是常用的指标。
2. 类别不平衡问题(class-imbalanced problems)---> 准确率和召回率
3.排序问题或多标签分类---> 平均准确率均值(mean average precision)
3.确定评估方法-- Deciding on an evaluation protocol
总结一下前面介绍了三种常见的评估方法。如下:
- 留出验证集。数据量很大时可以采用这种方法。
- K 折交叉验证。如果留出验证的样本量太少,无法保证可靠性,那么应该选择这种方法。
- 重复的 K 折验证。如果可用的数据很少,同时模型评估又需要非常准确,那么应该使用这种方法。
4.准备数据-- Preparing your data
- 应该将数据格式化为张量。
- 这些张量的取值通常应该缩放为较小的值,比如在 [0, 1] 区间。
- 如果不同特征具有不同的取值范围(异质数据),应该做数据标准化。
- 可能需要做特征工程,尤其是对于小数据问题。
5.开发模型--Developing a model that does better than a baseline
统计功效(statistical power),即开发一个小型模型,它能够打败纯 随机的基准(dumb baseline),不一定总是能获得统计功效。如果尝试了多种合理架构之后仍然无法打败随机基准, 那么原因可能是问题的答案并不在输入数据中----体现元认知能力。
- 假设输出是可以根据输入进行预测的。
- 假设可用数据包含足够多的信息足以学习输入和输出之间的关系
需要选择以下三个关键参数来构建第一个工作模型 :
- 最后一层的激活: 对网络输出进行有效的限制。
- 损失函数:它应该匹配你要解决的问题的类型。损失函数需要在只有小批量数据时即可计算(理想情况下,只有一个数据点时,损失函数应该也是可计算的),而且还必须是可微的(否则无法用反向传播来训练网络)。
- 优化配置:要使用哪种优化器?学习率是多少?大多数情况下,使用 RMSprop 及其默认的学习率是稳妥的。
6.扩大模型规模:开发过拟合的模型--Scaling up: developing a model that overfits
机器学习中到处都是优化和泛化的对立,理想的模型是刚好在欠拟合和过拟合的界线上,在容量不足和容量过大的界线上。要搞清楚需要多大的模型,就必须开发一个过拟合的模型,如下操作即可:
(1) 添加更多的层。
(2) 让每一层变得更大。
(3) 训练更多的轮次。
要始终监控训练损失和验证损失,以及所关心的指标的训练值和验证值。如果发现模型在验证数据上的性能开始下降,那么就出现了过拟合。
7. 模型正则化与调节超参数--Regularizing your model and tuning your hyperparameters
这一步是最费时间的: 将不断地调节模型、训练、在验证数据上评估(而不是测试数据)、 再次调节模型,然后重复这一过程,直到模型达到最佳性能。主要调节如下几项:
- 添加 dropout。
- 尝试不同的架构: 增加或减少层数。
- 添加 L1 和 / 或 L2 正则化。
- 尝试不同的超参数(比如每层的单元个数或优化器的学习率),以找到最佳配置。
- (可选)反复做特征工程: 添加新特征或删除没有信息量的特征。
【请注意】每次使用验证过程的反馈来调节模型,都会将有关验证过程的信息泄露到模型中。如果只重复几次,那么无关紧要; 但如果系统性地迭代许多次,最终会导致模型对验证过程过拟合(即使模型并没有直接在验证数据上训练),这会降低验证过程的可靠性。
一旦开发出令人满意的模型配置,就可以在所有可用数据(训练数据 + 验证数据)上训练最终的生产模型,然后在测试集上最后评估一次。如果测试集上的性能比验证集上差很多, 那么这可能意味着验证流程不可靠,或者在调节模型参数时在验证数据上出现了过拟合。 在这种情况下,可能需要换用更加可靠的评估方法,比如重复的 K 折验证。

微信公众号: