新闻联播也可以拿来做数据分析?
戳蓝字“CSDN云计算”关注我们哦!
作者 | 米哥
来源 | 挖地兔

在Tushare Pro数据开放平台上,最近上线了近10年CCTV新闻联播文本数据,以及各大财经网站的即时资讯文本。
很多用户表示出了比较高的兴趣,纷纷要求开通权限获取数据。也有一些用户看到这种文本类型的非结构化数据,表示一脸懵逼两眼茫然。
今天从一个极简角度,给大家展示如何利用文本数据做点有意思的统计,并通过可视化工具展示出来,希望对大家有所帮助。
数据准备
获取近10年的新闻联播文本有两个方法,一是自己写爬虫,将CCTV网站的新闻联播网页爬取下来,二是通过Tushare SDK的API免费获取数据。
如果是自己爬,好处是可以锻炼自己的爬虫编程能力,磨练自己被可能不统一的网页格式虐心千百遍还不砸电脑的心态意志。
坏处是爬数据,清洗数据确实浪费时间,搞不好真有可能费电脑。
当然如果直接通过Tushare SDK调取数据,只需要一行代码即可获取到格式统一的数据。
df = pro.cctv_news(date='20181222')
数据格式效果如下:
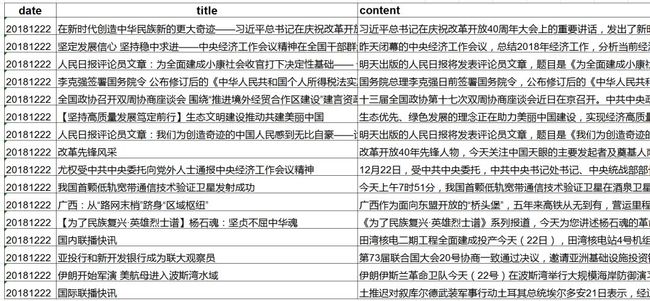
如果要获取其他新闻资讯,也很简单:
df = pro.news(src='sina', start_date='20181223', end_date='20181224')
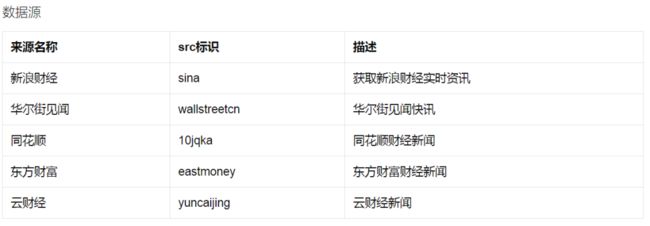
新闻源目前支持如下:
获取获取后,可以存csv也可以存Excel,或者存数据库都可以,这样就完成了原始数据准备。
分词处理
借助Python jieba分词工具,我们可以快速的实现文本的分词功能。同时可以设置关键字黑名单和白名单,过滤不需要的,提取想要的关键词。
import jieba
#过滤关键词
blacklist = ['责任编辑', '一定','一年', '一起', '一项', '一点儿', '一度','一系列','一道','一次','一亿','进行', '实现', '已经', '指出',
'为什么', '是不是', '”', '一个', '一些', 'cctv', '一边', '一部', '一致', '一窗', '万亿元', '亿元', '一致同意', '本台记住', '发生',
'上述', '不仅', '不再 ', '下去', '首次', '合作', '发展', '国家', '加强', '共同', '重要', '我们', '你们', '他们', '目前',
'领导人', '推进', '中方', '坚持', '支持', '表示', '时间', '协调', '时间', '制度', '工作', '强调', '进行', '推动', '通过',
'北京时间', '有没有', '新闻联播', '本台消息', '这个', '那个', '就是', '今天', '明天', '参加', '今年', '明天']
#新增关键词
stopwords = ['一带一路', '雄安新区', '区块链', '数字货币', '虚拟货币', '比特币', '对冲基金', '自贸区', '自由贸易区','乡村振兴','美丽中国','共享经济','租购同权','新零售',
'共有产权房','楼市调控', '产权保护', '互联网金融', '5G', '4G', '国企改革', '大湾区', '长江经济带']
for word in stopwords:
jieba.add_word(word)
df = pd.read_csv(file, encoding='utf8')
list = []
df = df[df.content.isnull() == False]
for idx, row in df.iterrows():
data = jieba.cut(row['content'])
data = dict(Counter(data))
df = pd.DataFrame(list, columns=['date', 'keyword', 'count'])
按日期处理分词之后,我们可以对词频进行统计,生成一个完整的词频csv文件。
为了让大家更好地完成本次实验,我们直接提供已经完成统计的csv文件供大家下载,请在文章末尾获取下载方式。
词频统计分析
新闻词云统计
对于最具影响力的新闻节目,可能很多人第一想到的是哪些关键词出现的次数最多?对于常见新闻词语,一定逃不出你的预料之中,下面这个词云图可以验证你的判断。
实现词云非常方便,前提是你已经准备好了词频统计。幸运的是,我们为你提供了现成的词云统计csv文件,在下载的文件中可以找到一个all.csv的文件。
from pyecharts import WordCloud
all = pd.read_csv('all.csv', encoding='utf8')
name = list(all.head(80)['keyword'].values)
val = list(all.head(80)['count'].values)
wordcloud = WordCloud(width=1300, height=620)
wordcloud.add("", name, val, word_size_range=[20, 100])
wordcloud.render('')
正如你所看到的,我们借助了pyecharts这个工具来实现可视化。以下所有图形效果都是借助pyecharts来实现的,更多具体的使用可以自行学习echarts和pyecharts的知识来加强图形制作能力,这里不做太多的介绍。
新闻分类统计
除了新闻联播常见关键词,我们可能还想知道一些特定词语出现在新闻联播的次数,以便了解该类信息受关照程度,比如在过去10年当中,哪些省份和省会城市最受新闻联播关注?
我们将各省在新闻联播出现的数据进行分年统计,然后通过柱状图的形式展示出来。
from pyecharts import Bar
pro_data = pd.read_csv('pro_count_list.csv', encoding='utf8')
bar = Bar("", width=1000, height=500)
ps = pro_data.groupby(['key', 'year']).sum().reset_index()
attr = list(ps['key'].drop_duplicates().values)
for x in range(2009, 2019):
val = ps[ps.year == x]
val = list(val['count'].values)
bar.add(str(x), attr, val, is_stack=True, xaxis_interval=0, xaxis_rotate=60, yaxis_rotate=30)
bar.render('')
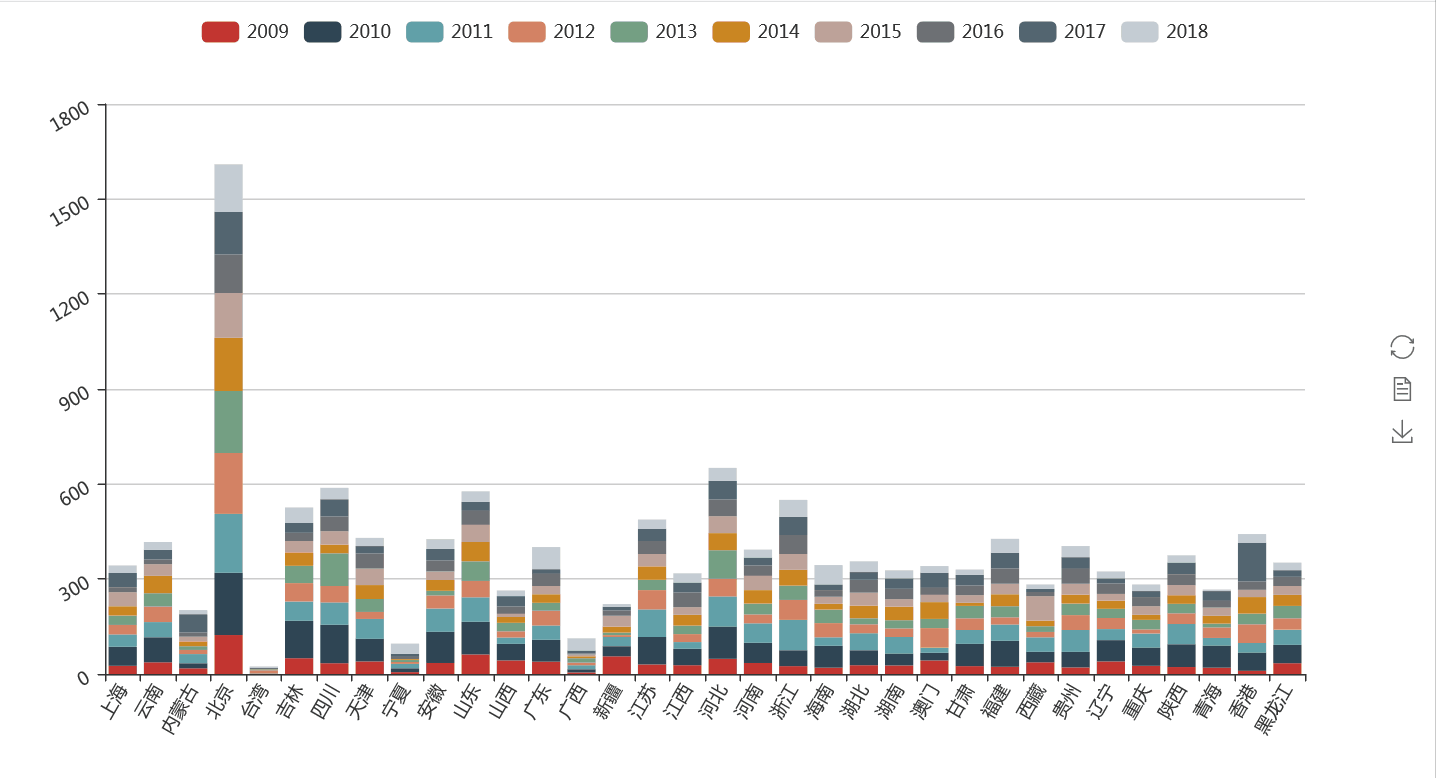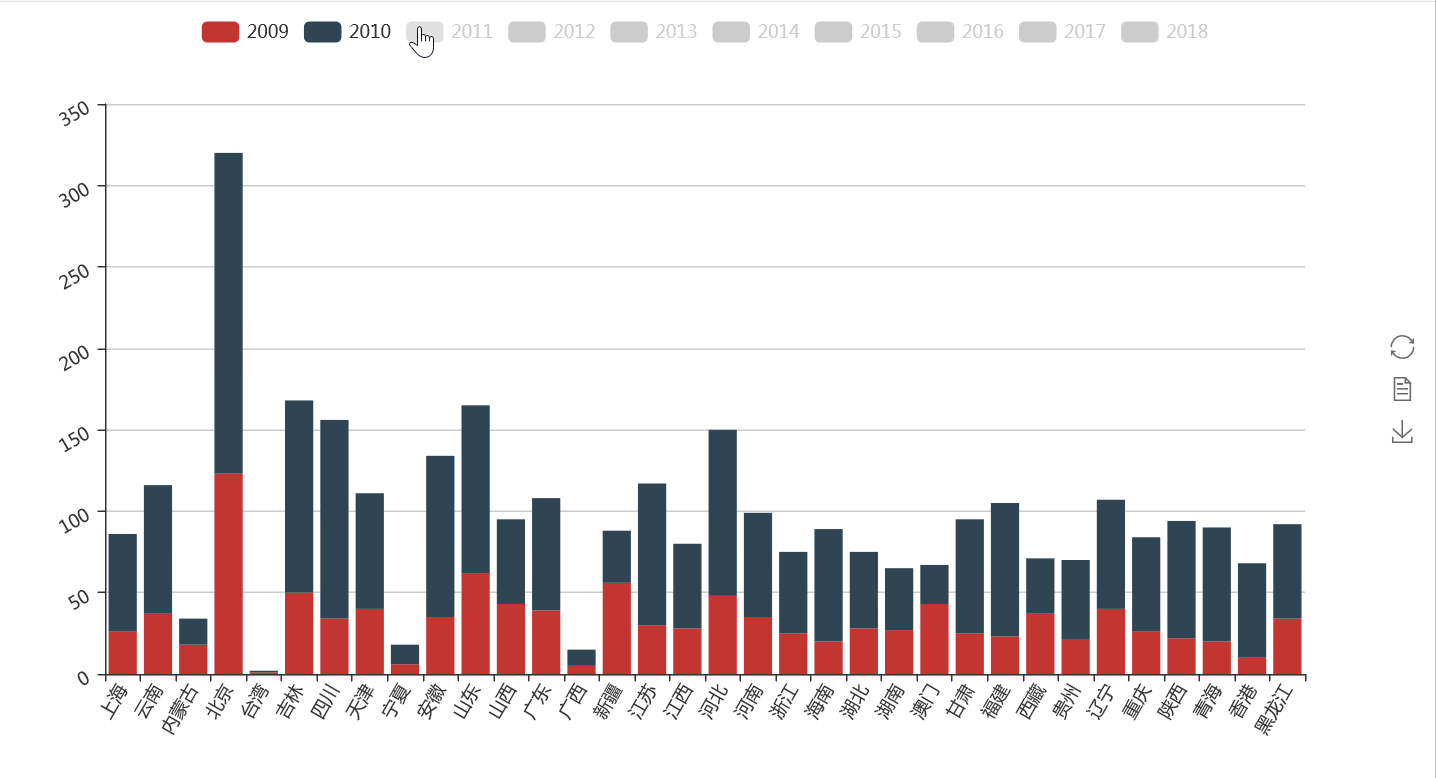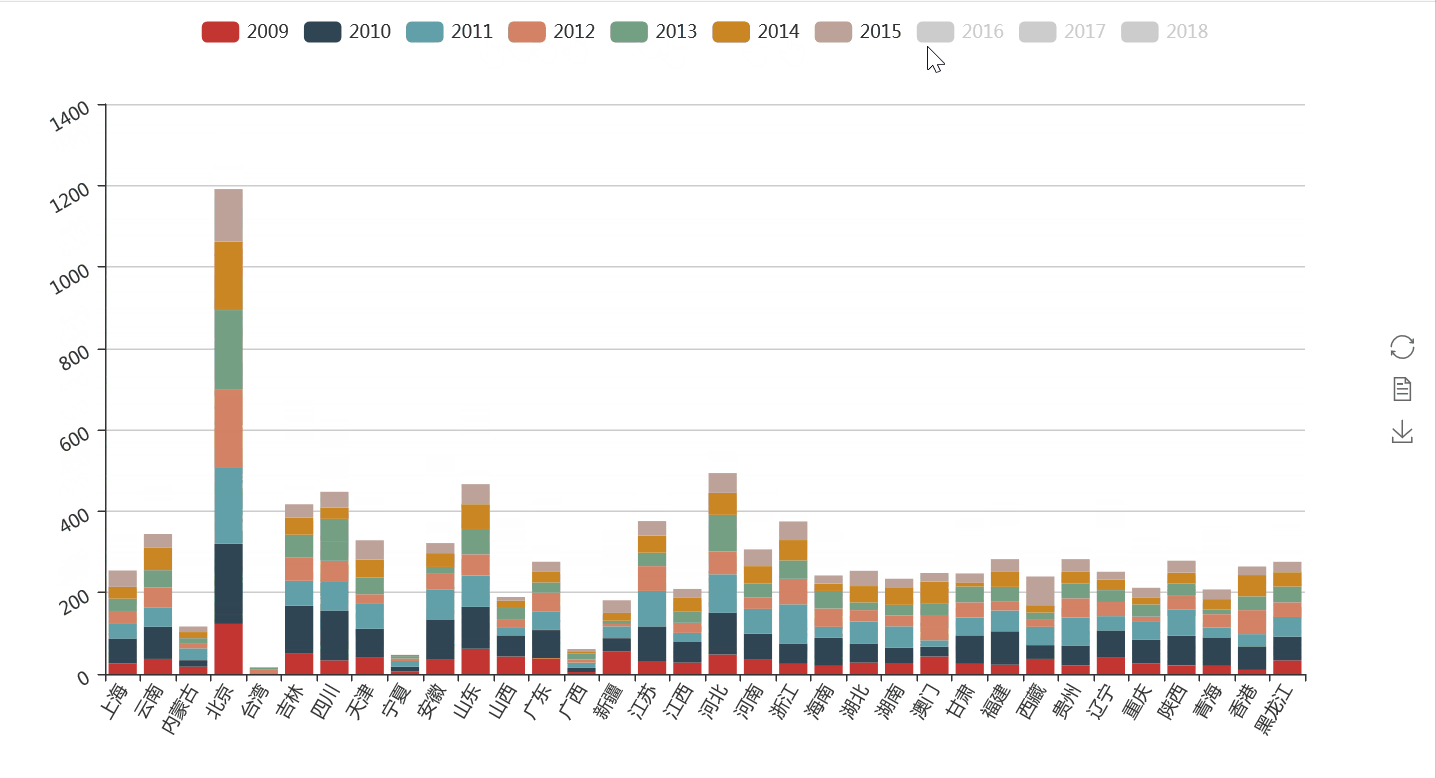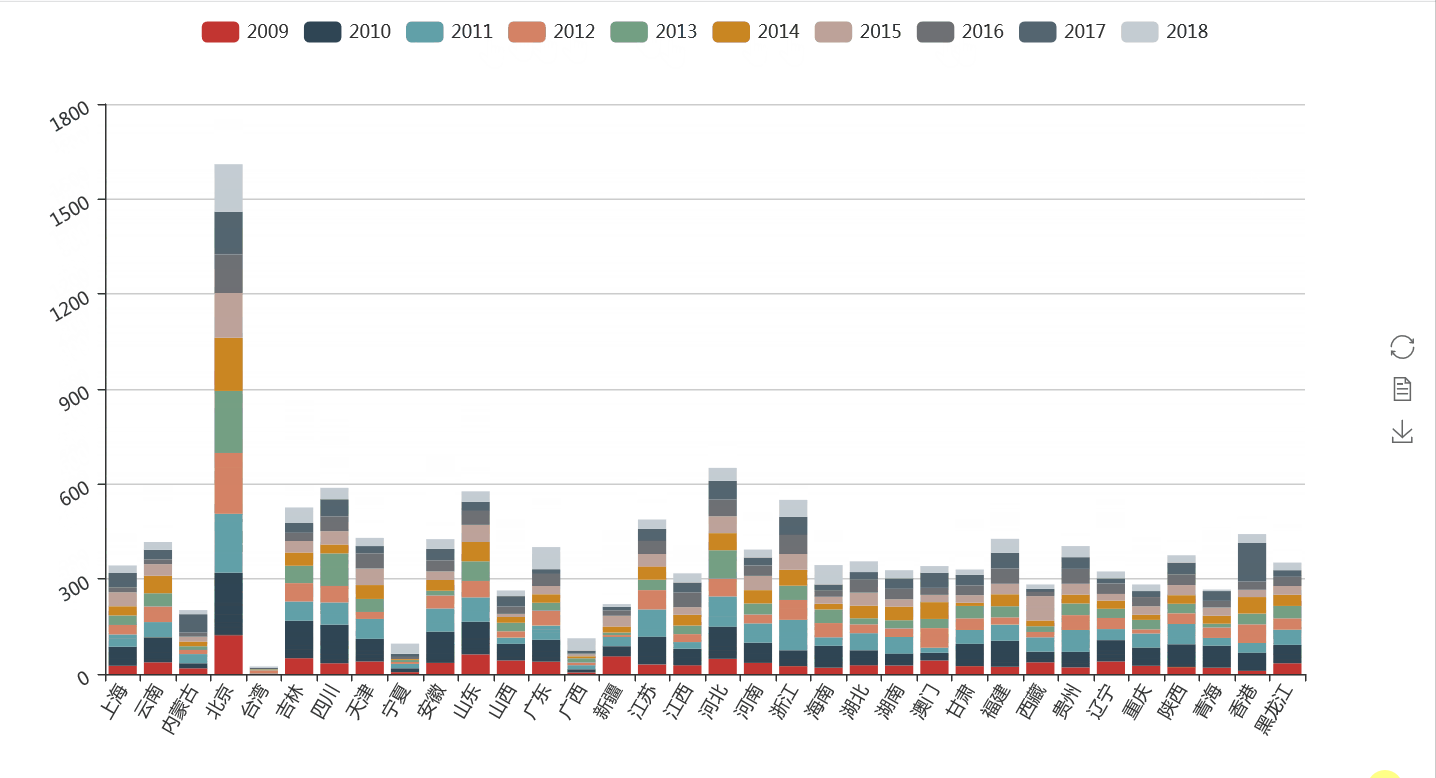
通过上图我们可以知道,作为首都的北京毫无疑问是关注最多的地方。而在每年因为不同的政治、经济或者文化事件,不同的省出现的频次也呈现出一些差异。
比如2018年在政策上对海南的倾斜,对珠三角的关注等,而在2017年香港回归20年,河北雄安新区的提出等事件,让这些地方备受关注。
同样的方法,我们也可以对各省会城市出现的频次进行按年份统计。
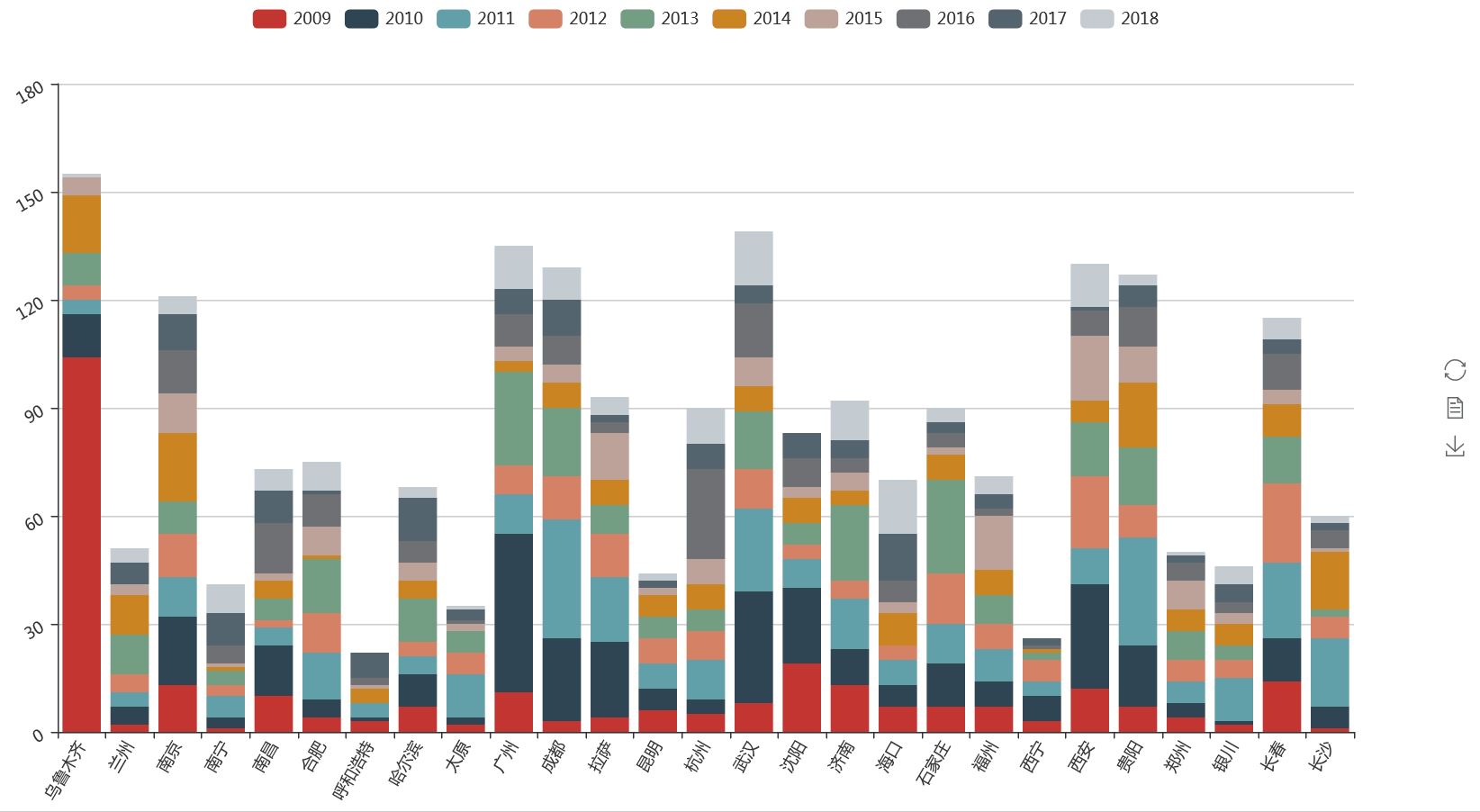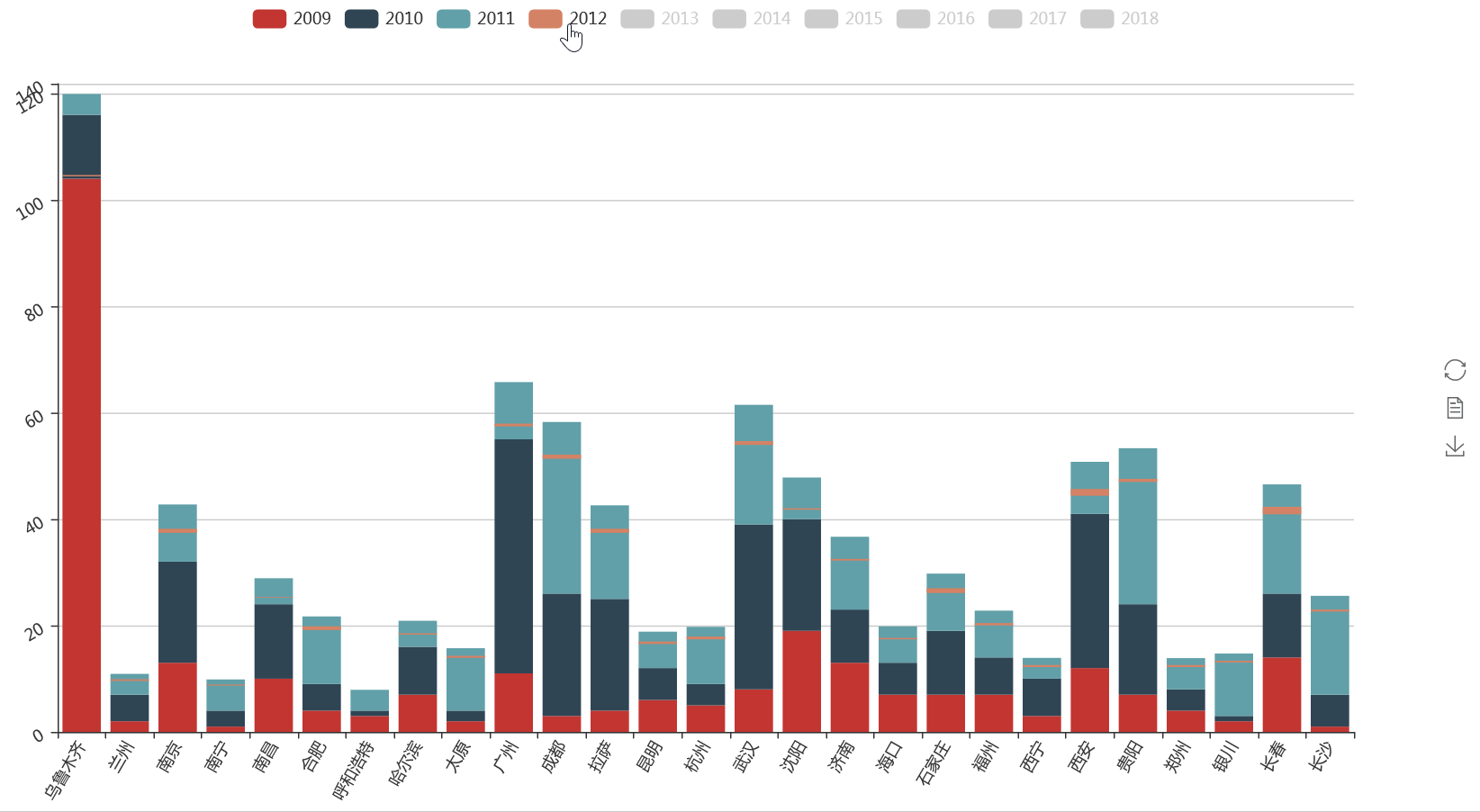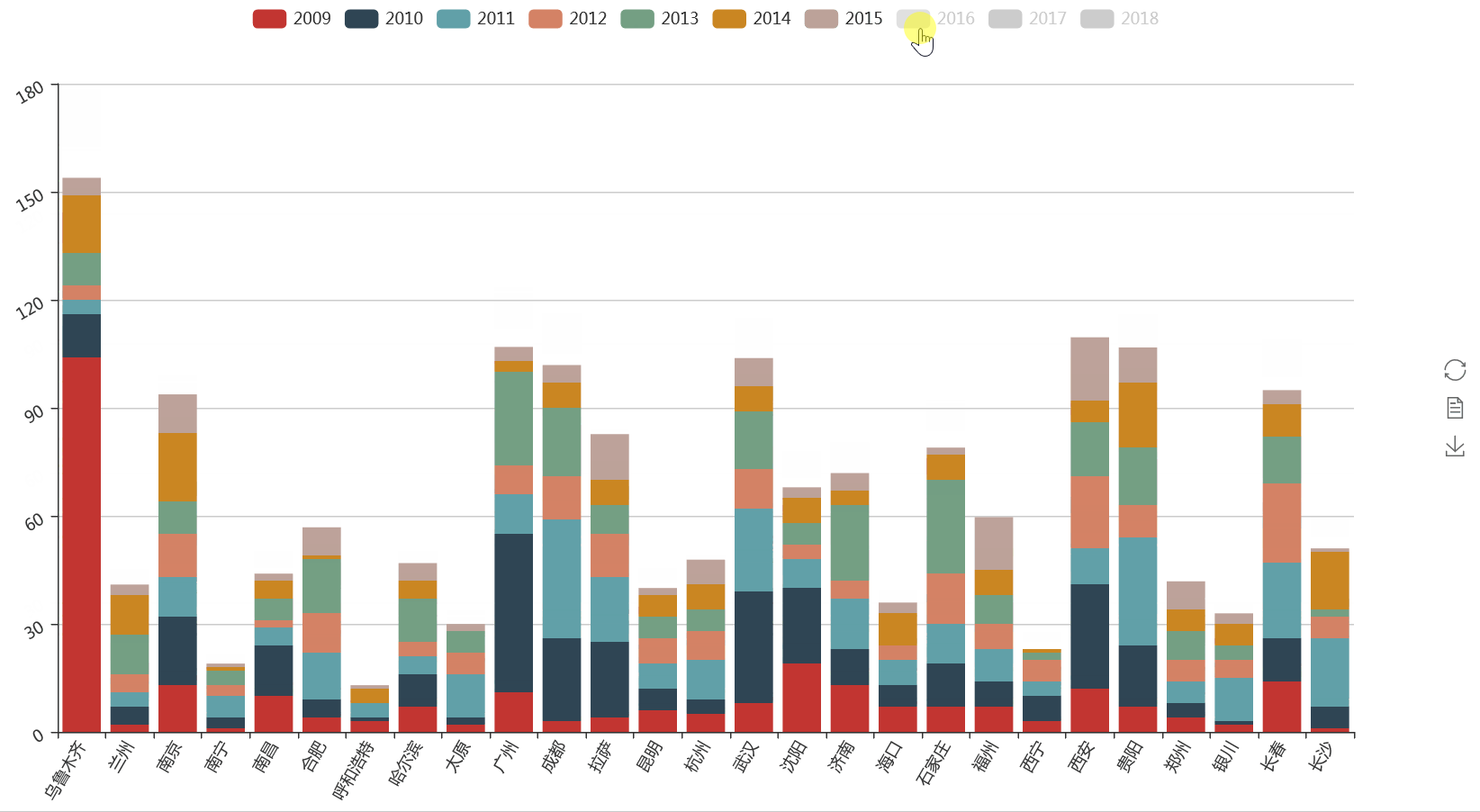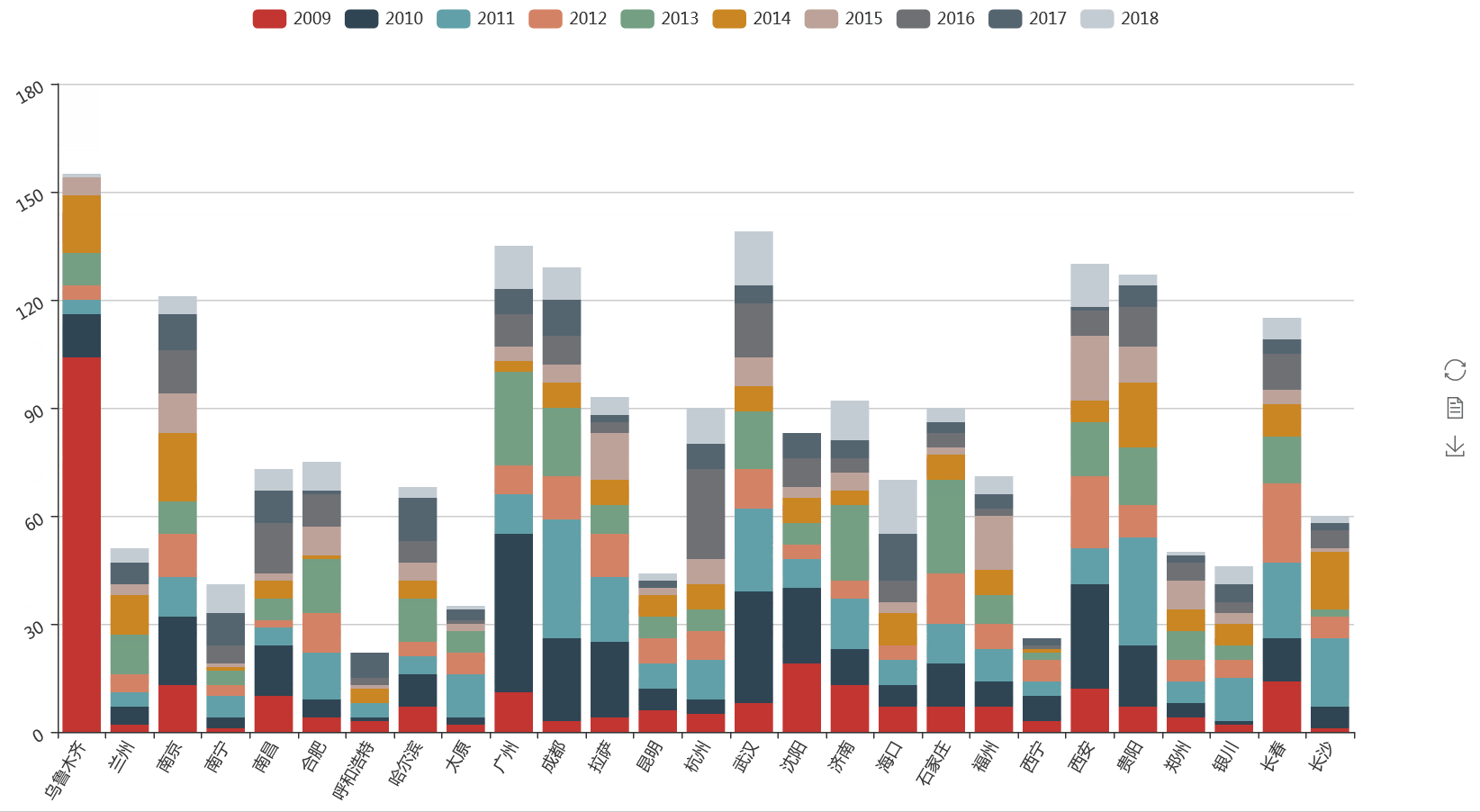
可以清楚的看到,在2009年乌鲁木齐因暴恐事件受到了极大的新闻关注,而海口在近两年开放海南的大背景下也成了新闻联播的常客。
如果柱状图看的不够清晰,我们可以借助地图热力方式来显示各省收关注程度可能更清楚。
from pyecharts import Map
pros = pro_data.groupby(['key'])['count'].sum().reset_index()
pros['count'] = pros['count']/10
pro_att = list(pros['key'].values)
pro_val = list(pros['count'].values)
map = Map("近十年新闻联播提到各省的频次", width=1200, height=600)
map.add(
"",
pro_att,
pro_val,
maptype="china",
is_visualmap=True,
visual_text_color="#000",
)
map.render('')
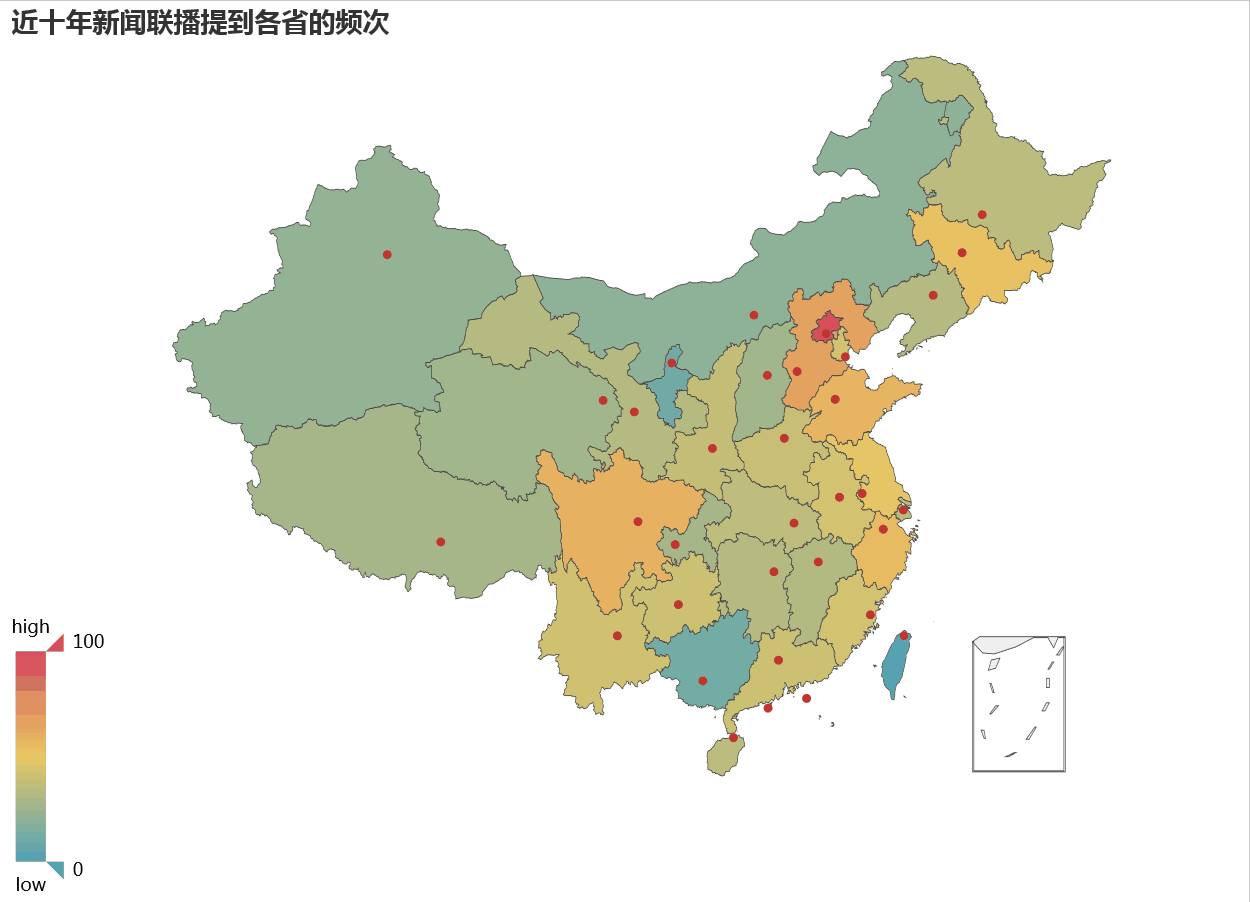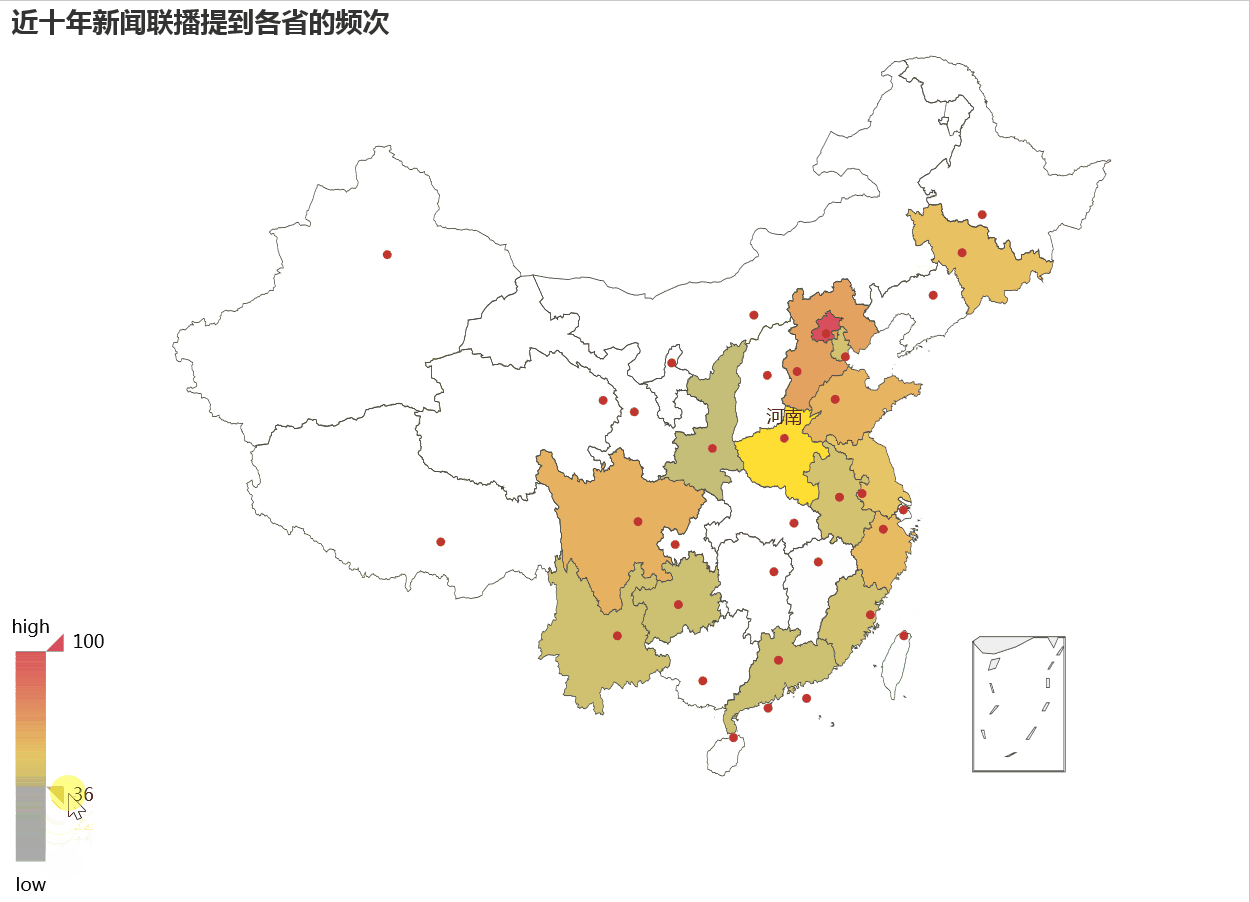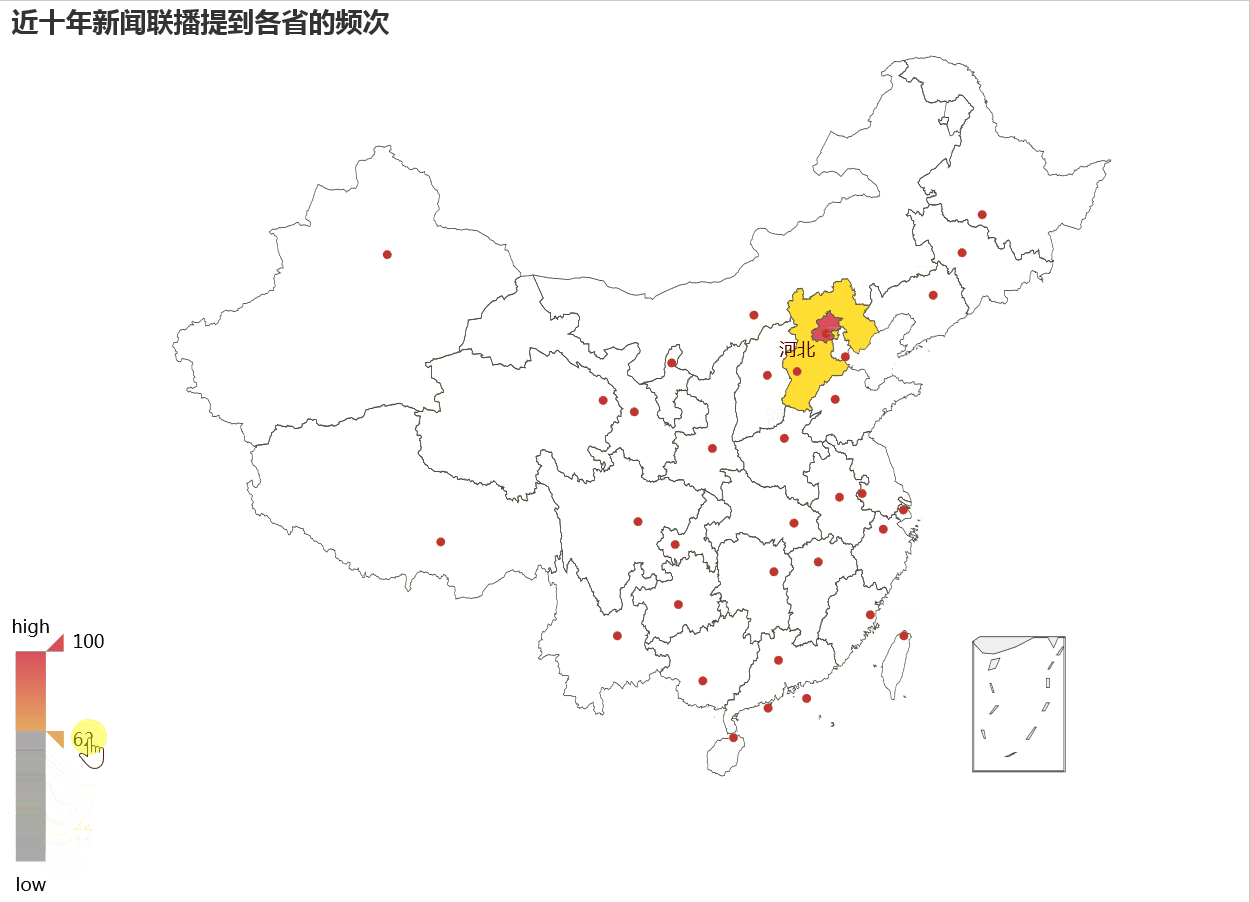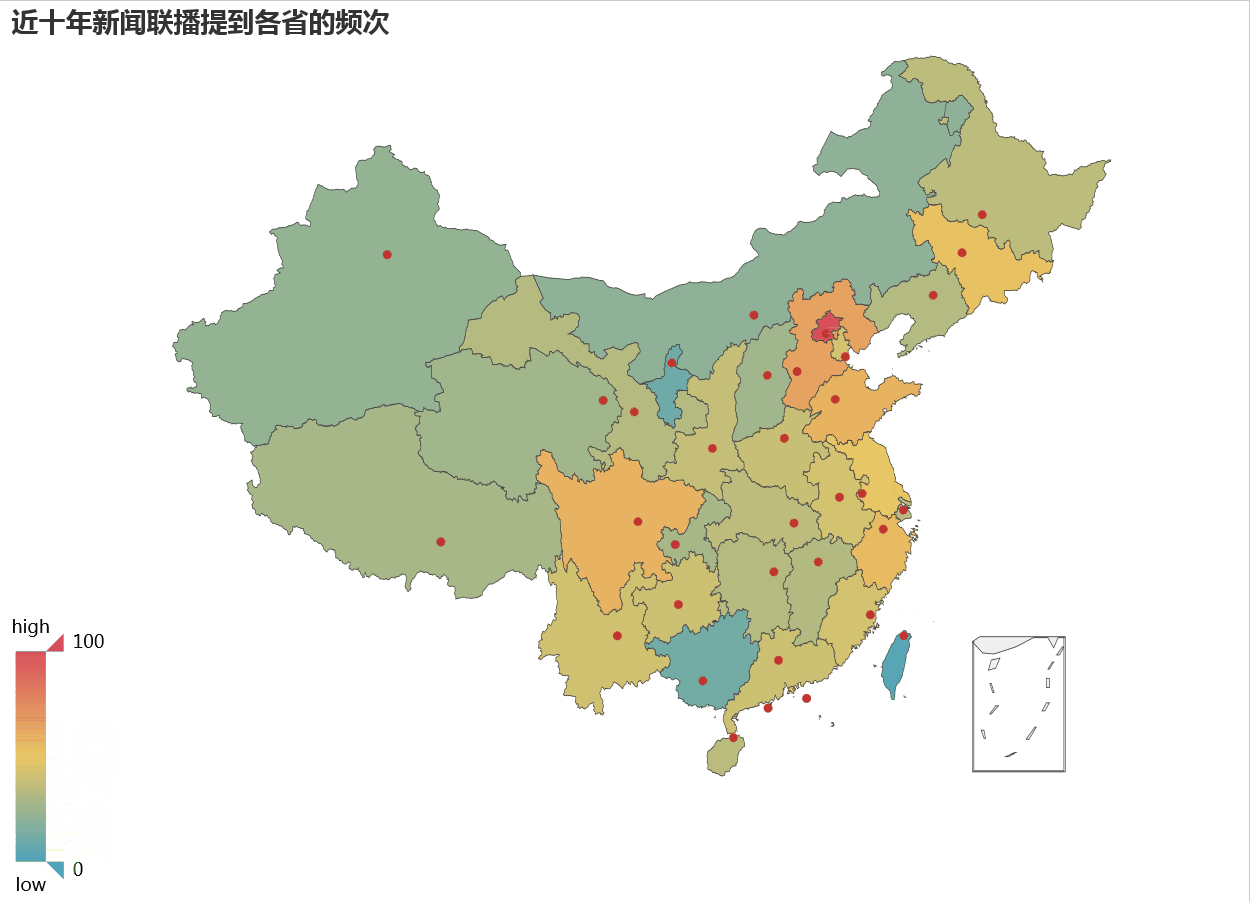
在热力地图上,颜色越深表示受关注越大,我们看到北京最红,而东部沿海比西部,东北要比内蒙受关注更多。
如果想要了解各地级市或者县级在新闻联播出现的次数,我们同样可以借助地图效果来展示,通过散点效果可以大致看出在新闻联播出现的情况。

新闻占比统计
可能有些人很想了解哪些大学在新闻联播出现的次数最多,就像北京被关注最多一样,北京的清华北大应该也是关注最多的?
我们来通过数据统计,根据排名前30位的占比来分析一下。
from pyecharts import Pie
dx = pd.read_csv('d:\\cctv_done\\u.csv', encoding='utf8')
dx = dx.head(30)
attr = list(dx['key'].values)
val = list(dx['count'].values)
pie = Pie("近十年新闻联播提到的大学频次", title_pos='center')
pie.add("", attr, val, is_label_show=True, is_legend_show=False)
pie.render()
我们对清华、北大、人大等知名大学的排名可能并不会觉得奇怪,但在受关注度排名前30的大学中,发现了一所国外的大学,那就是莫斯科大学,在接近10年的历史里,总共提到了31次。
通过新闻内容我们知道,国家领导人曾经在大学演讲过,以及国家领导人勉励在莫斯科大学留学的中国学子等活动获得了关注。
而在与世界各国的往来方面,我们同样可以借助上述的方法,统计出各国在新闻联播出现的次数来得到体现。
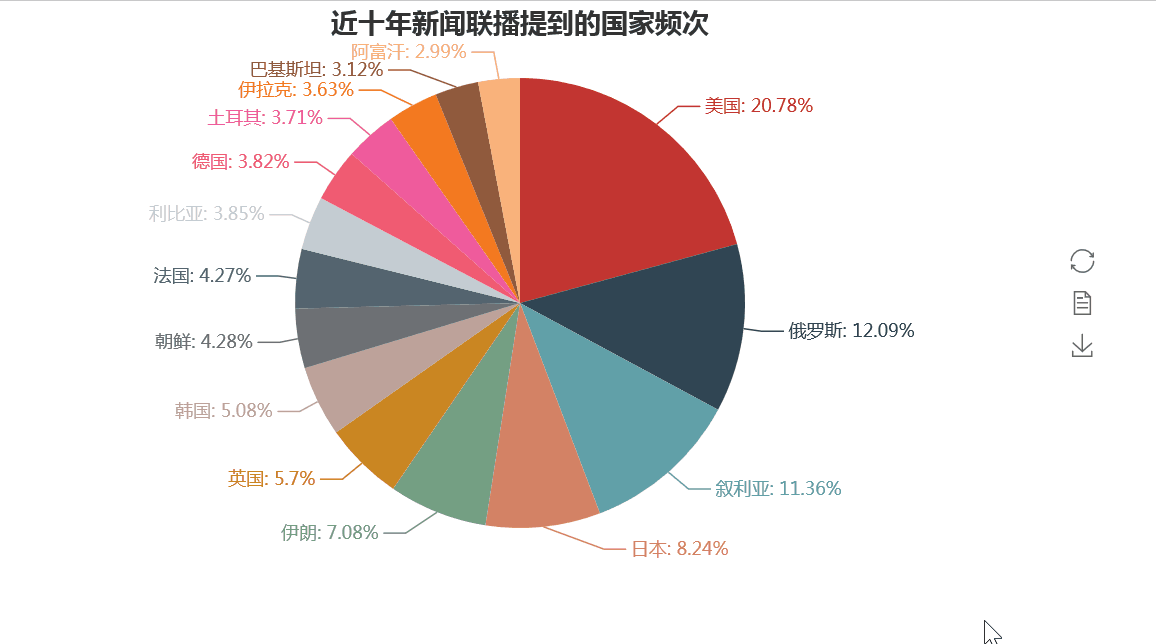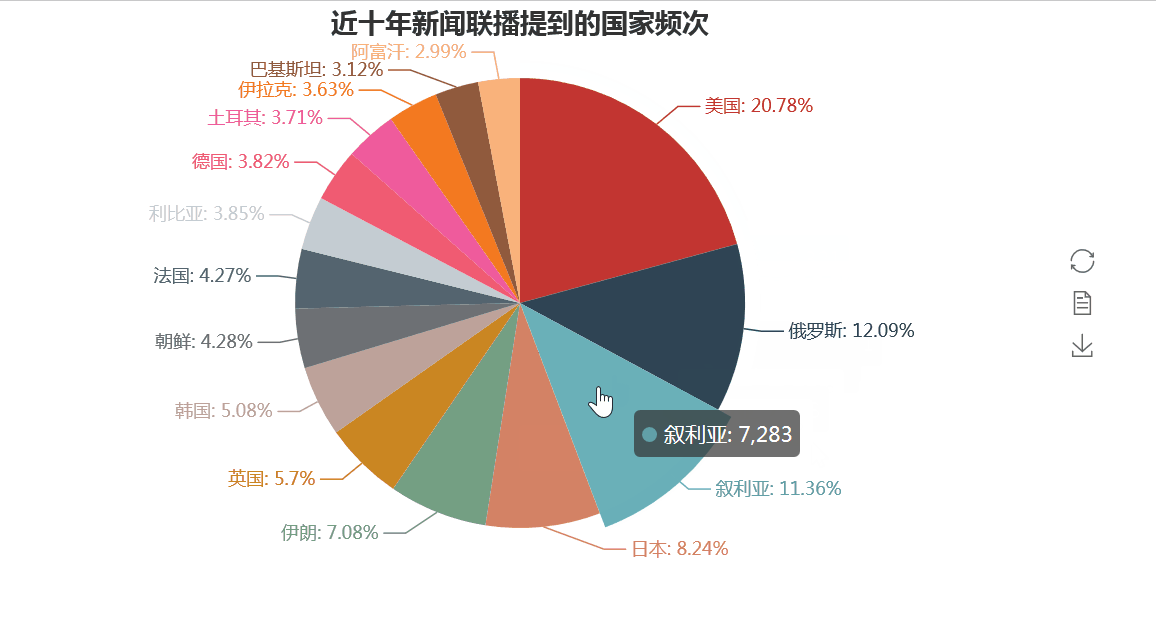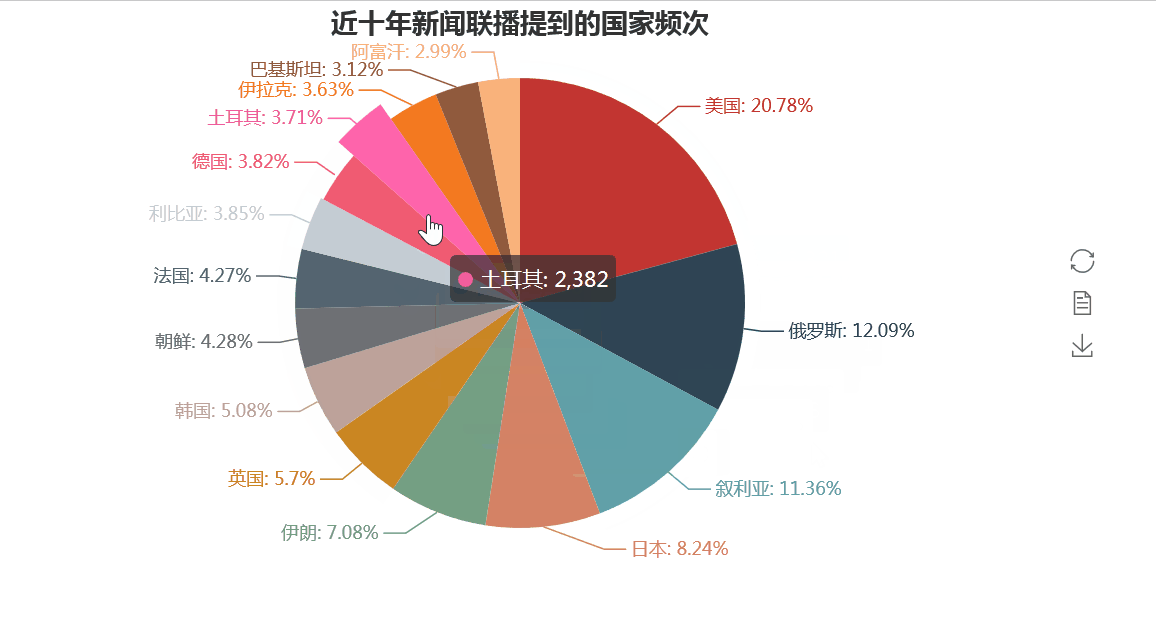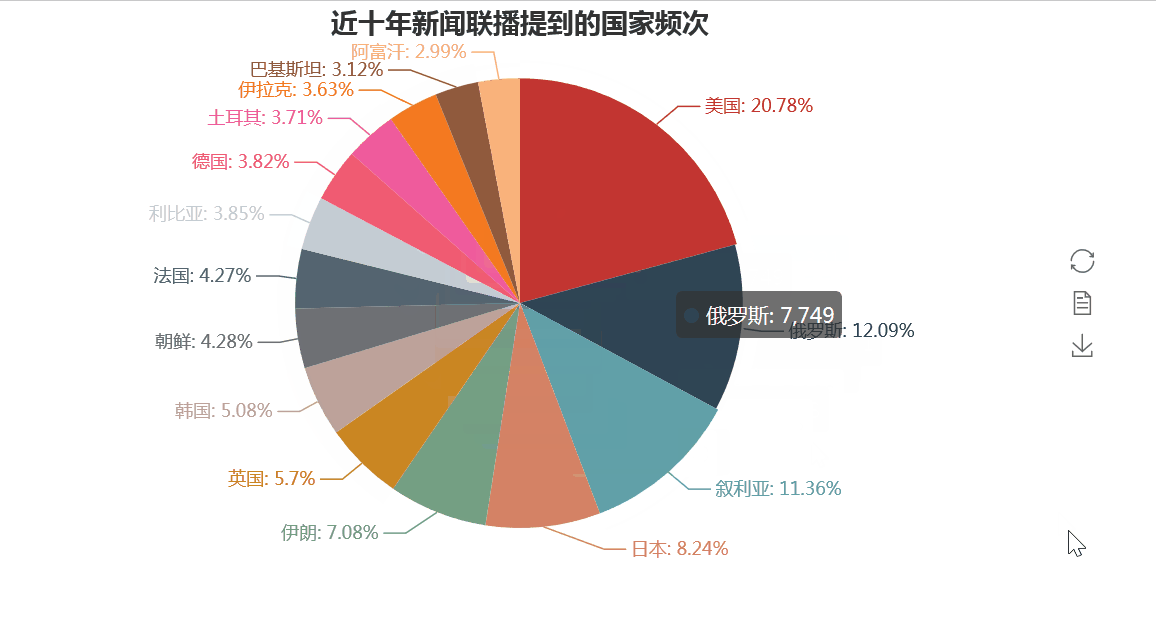
正如我们所知,中国与美国的关系是中国外交关系最紧密的,而中俄,中日关系也是非常重要。但同时我们也看到,诸如叙利亚、伊朗、朝鲜、伊拉克、巴基斯坦等战乱和动荡的国家让世界人民也让中国人民操碎了心。
新闻分时统计
在国际关系方面,我们从上面各国出现在新闻联播的次数基本上得到了体现,但从每年的关注情况方面,我们可以通过折线图更加清楚的了解到一些细节。
from pyecharts import Line
cdss = ctdf_all.head(10)
attr = [str(year) for year in range(2009, 2019)]
line = Line("")
for ckey in cdss['key'].values:
val = ctdfs[ctdfs.key == ckey]['count'].values
line.add(ckey, attr, val, is_smooth=True)
line.render()
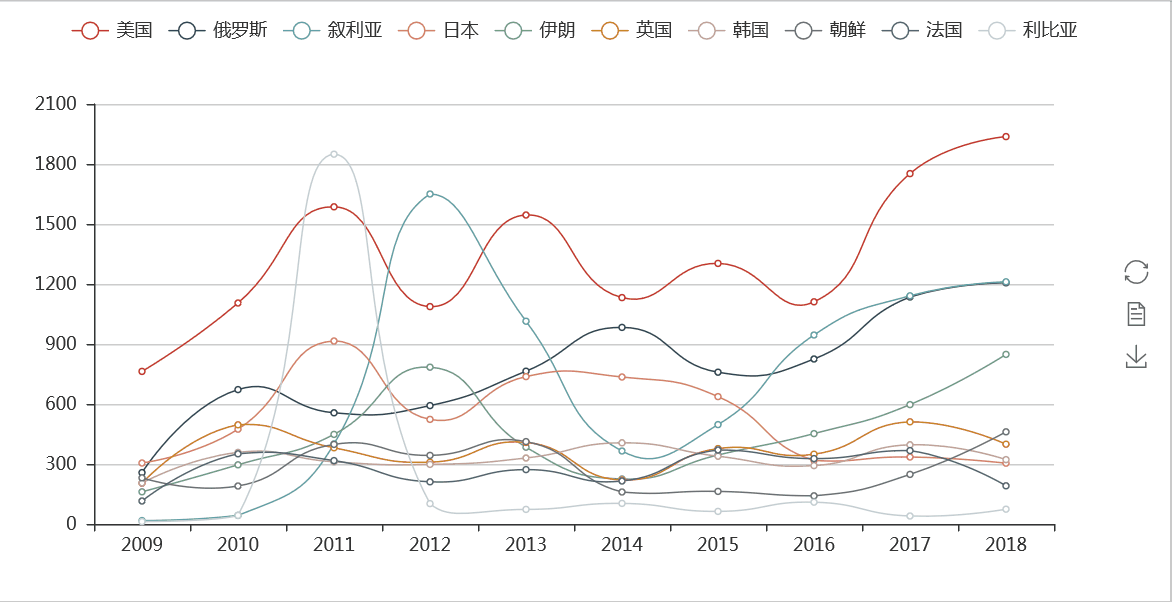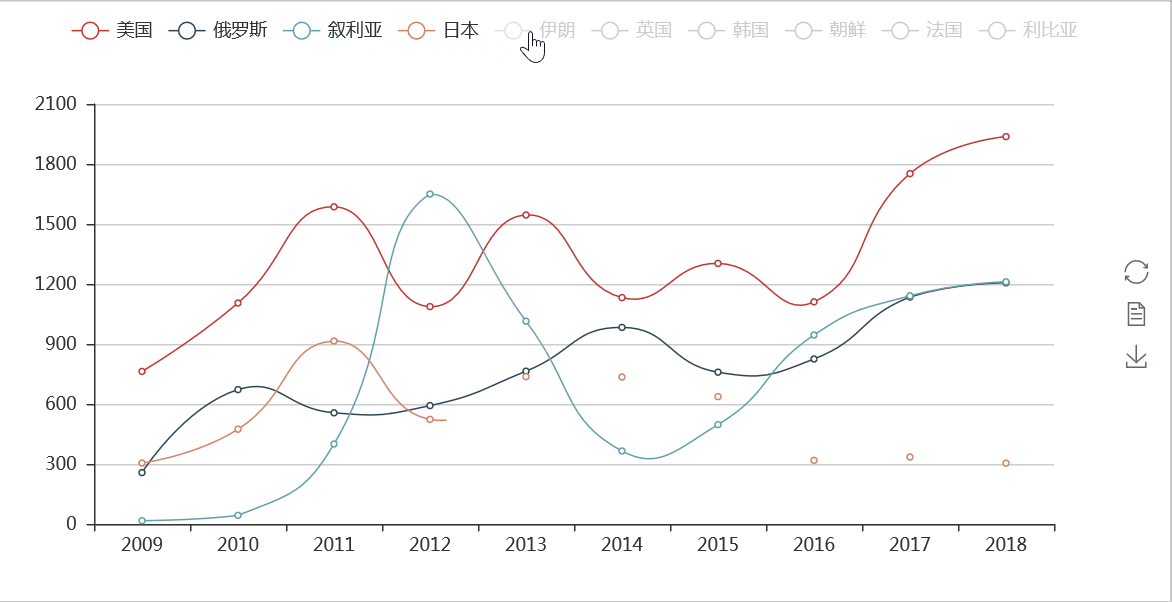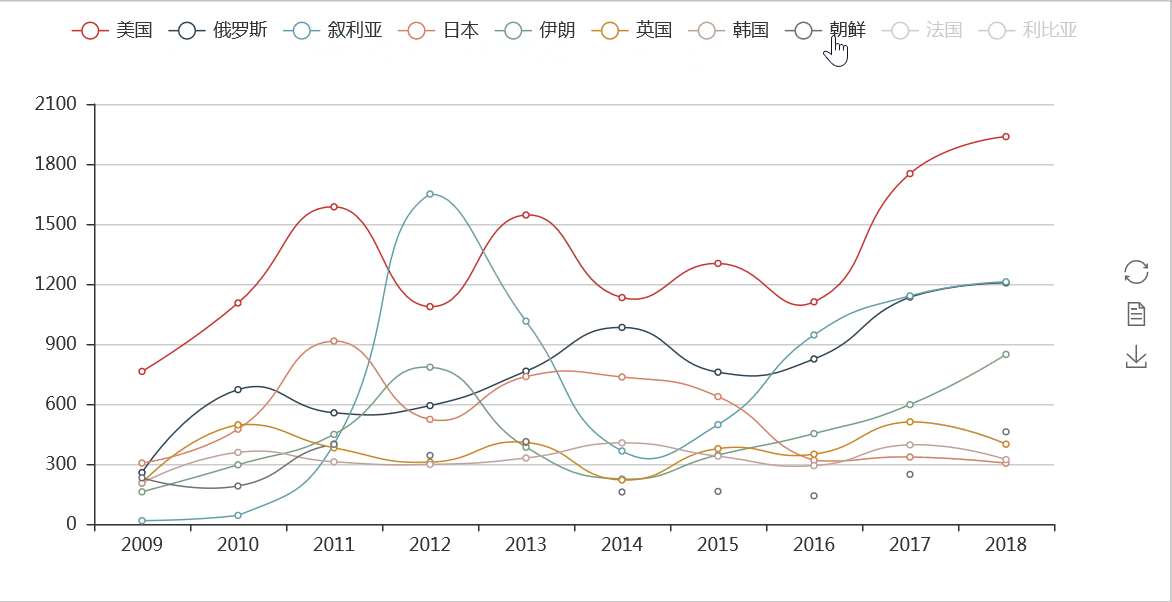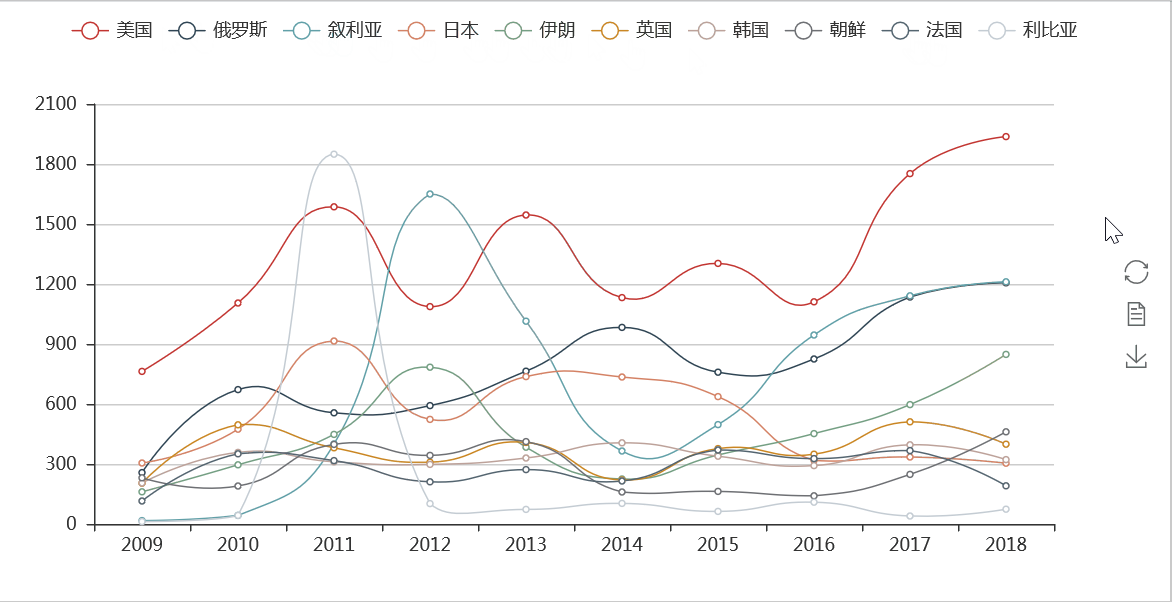
从分时图可以看出,美国、俄罗斯出现在新闻联播出现的频次一直很高,而且近年呈上升趋势,而日本在2015年以后,提到的次数越来越少,反映出与日本的关系的变化。
在其他新闻和经济热词方面,我们也进行了一些检验,比如人工智能、智能制造和5G等近年来越来越多的被提到,而在提到“金融风险”的次数也伴随提及“金融”二字出现的越来越多。
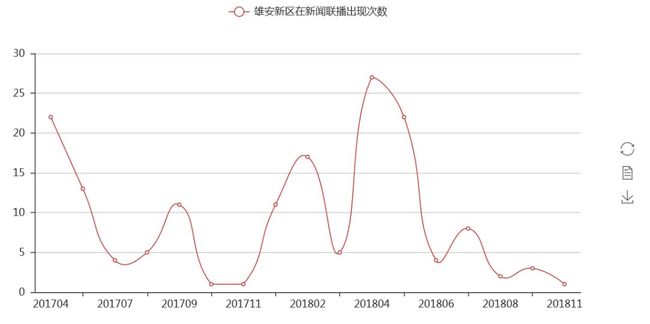
另外,我们也跟踪了一带一路、自贸区、雄安新区等热词的频次,比如雄安新区,在2017年4月1日首次出现之后,也是经常出现在新闻联播里,通常快要到事件或概念提出的周年的时候,出现的频次会更多。
总结
对于新闻等非结构化数据的统计分析,是一个很有意思的过程,也许你会发现一些意外的惊喜。尤其是结合互联网社区的数据,比如微信微博等,可以从中挖掘出很有价值的信息。
本次实验过程只是一个简单的开始,还有很多更值得分析的角度和方法,只为抛砖引玉,希望对大家有所助益。
推荐阅读
关于云原生,这是最详细的技术知识
用“AI”给吴秀波测面相,发现……
程序员一毕业就年薪 110 万竟然是靠……
程序员锁死服务器失踪,公司解散 600 万项目彻底黄了!
史上最全新媒体运营工具(121种)
一年省下1000亿? 原来零售玩的是闷声发大财
Spark+Alluxio性能调优十大技巧
从云计算到AI:NetApp的数据网络转型之道
1.微信群:
添加小编微信:color_ld,备注“进群+姓名+公司职位”即可,加入【云计算学习交流群】,和志同道合的朋友们共同打卡学习!
2.征稿:
投稿邮箱:[email protected];微信号:color_ld。请备注投稿+姓名+公司职位。