Hadoop生态系统模块功能分析
Hadoop生态系统模块框架如图1-1所示:
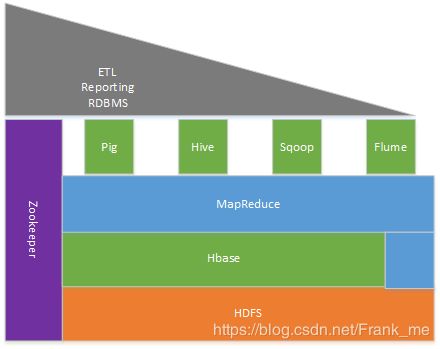
图1-1 Hadoop生态系统模块框架
Hadoop生态系统保护的模块有:
(一)HDFS:分布式文件系统
用于提供Hadoop体系中数据存储管理的基础。它是一个高度容错的系统,能检测和应对硬件故障,用于在低成本的通用硬件上运行。HDFS简化了文件的一致性模型,通过流式数据访问,提供高吞吐量应用程序数据访问功能,适合带有大型数据集的应用程序。HDFS这一部分主要有一下几个部分组成:
Client:切分文件;访问HDFS;与NameNode交互,获取文件位置信息;与DataNode交互,读取和写入数据。
NameNode:Master节点,在hadoop1.X中只有一个,管理HDFS的名称空间和数据块映射信息,配置副本策略,处理客户端请求。
DataNode:Slave节点,存储实际的数据,汇报存储信息给NameNode。
Secondary NameNode:辅助NameNode,分担其工作量;定期合并fsimage和edits,推送给NameNode;紧急情况下,可辅助恢复NameNode,但Secondary NameNode并非NameNode的热备。目前,在硬盘不坏的情况,我们可以通过secondarynamenode来实现namenode的恢复。
(二)Hbase:非关系数据库
HBase是Google Bigtable克隆版,HBase是一个针对结构化数据的可伸缩、高可靠、高性能、分布式和面向列的动态模式数据库。和传统关系数据库不同,HBase采用了BigTable的数据模型:增强的稀疏排序映射表(Key/Value),其中,键由行关键字、列关键字和时间戳构成。HBase提供了对大规模数据的随机、实时读写访问,同时,HBase中保存的数据可以使用MapReduce来处理,它将数据存储和并行计算完美地结合在一起。Hbase在Hadoop中的分布情况如图2-1所示:
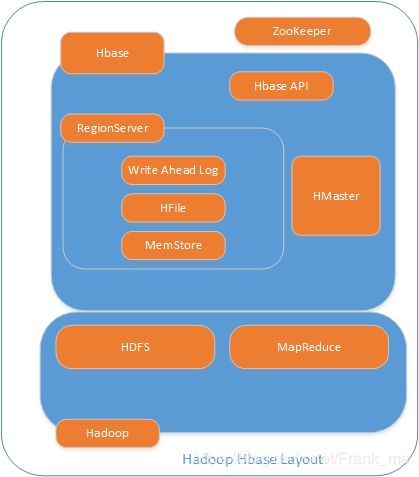
图2-1 Hbase在Hadoop中的分布情况
ZooKeeper主要实现Hmaster的高可用,Hmaster用来管理RegionServer,RegionServer用来管理所有的Region。Hmaster与RegionServer有着主从的关系。
(三)MapReduce:分布式计算框架
Hadoop MapReduce是google MapReduce 克隆版。MapReduce是一种计算模型,用以进行大数据量的计算。其中Map对数据集上的独立元素进行指定的操作,生成键-值对形式中间结果。Reduce则对中间结果中相同“键”的所有“值”进行规约,以得到最终结果。MapReduce这样的功能划分,非常适合在大量计算机组成的分布式并行环境里进行数据处理。
MapReduce计算框架发展到现在有两个版本的MapReduce的API,针对MR1主要组件有以下几个部分组成:
(1)JobTracker:Master节点,只有一个,主要任务是资源的分配和作业的调度及监督管理,管理所有作业,作业/任务的监控、错误处理等;将任务分解成一系列任务,并分派给TaskTracker。
(2)TaskTracker:Slave节点,运行Map Task和Reduce Task;并与JobTracker交互,汇报任务状态。
(3)Map Task:解析每条数据记录,传递给用户编写的map(),并执行,将输出结果写入本地磁盘。
(4)Reducer Task:从Map Task的执行结果中,远程读取输入数据,对数据进行排序,将数据按照分组传递给用户编写的reduce函数执行。
在这个过程中,有一个shuffle过程,对于该过程是理解MapReduce计算框架是关键。该过程包含map函数输出结果到reduce函数输入这一个中间过程中所有的操作,称之为shuffle过程。在这个过程中,可以分为map端和reduce端。
Map端:
1) 输入数据进行分片之后,分片的大小跟原始的文件大小、文件块的大小有关。每一个分片对应的一个map任务。
2) map任务在执行的过程中,会将结果存放到内存当中,当内存占用达到一定的阈值(这个阈值是可以设置的)时,map会将中间的结果写入到本地磁盘上,形成临时文件这个过程叫做溢写。
3) map在溢写的过程中,会根据指定reduce任务个数分别写到对应的分区当中,这就是partition过程。每一个分区对应的是一个reduce任务。并且在写的过程中,进行相应的排序。在溢写的过程中还可以设置conbiner过程,该过程跟reduce产生的结果应该是一致的,因此该过程应用存在一定的限制,需要慎用。
4) 每一个map端最后都只存在一个临时文件作为reduce的输入,因此会对中间溢写到磁盘的多个临时文件进行合并Merge操作。最后形成一个内部分区的一个临时文件。
Reduce端:
1) 首先要实现数据本地化,需要将远程节点上的map输出复制到本地。
2) Merge过程,这个合并过程主要是对不同的节点上的map输出结果进行合并。
3) 不断的复制和合并之后,最终形成一个输入文件。Reduce将最终的计算结果存放在HDFS上。
(四)Zookeeper:分布式协作服务
Zookeeper 作为一个分布式的服务框架,主要用来解决分布式集群中应用系统的一致性问题,它能提供基于类似于文件系统的目录节点树方式的数据存储, Zookeeper 作用主要是用来维护和监控存储的数据的状态变化,通过监控这些数据状态的变化,从而达到基于数据的集群管理。
1 Zookeeper基本框架
Zookeeper集群主要角色有Leader,Learner(Follower,Observer(当服务器增加到一定程度,由于投票的压力增大从而使得吞吐量降低,所以增加了Observer。)以及client:
Leader:领导者,负责投票的发起和决议,以及更新系统状态
Follower:接受客户端的请求并返回结果给客户端,并参与投票
Observer:接受客户端的请求,将写的请求转发给leader,不参与投票。Observer目的是扩展系统,提高读的速度。
Client:客户端,想Zookeeper发起请求。
基本概念如下:
1). Znode
Zookeeper数据结构中每个节点称为Znode,每个Znode都有唯一的路径,znode 可以有子节点目录,并且每个 znode 可以存储数据。znode是有版本的,每个 znode 中存储的数据可以有多个版本,也就是一个访问路径中可以存储多份数据。
Znode 基本类型 :
PERSISTENT:持久化znode节点,一旦创建这个znode点存储的数据不会主动消失,除非是客户端主动的delete。
PERSISTENT|SEQUENTIAL:顺序自动编号的znode节点,这种znoe节点会根据当前已近存在的znode节点编号自动加 1,而且不会随session断开而消失。
EPHEMERAL:临时znode节点,Client连接到zk service的时候会建立一个session,之后用这个zk连接实例创建该类型的znode,一旦Client关闭了zk的连接,服务器就会清除session,然后这个session建立的znode节点都会从命名空间消失。总结就是,这个类型的znode的生命周期是和Client建立的连接一样的。
PHEMERAL|SEQUENTIAL:临时自动编号节点,znode节点编号会自动增加,但是会随session消失而消失。
Zookeeper它只负责协调数据,一般 Znode上的数据都比较小以Kb为测量单位。Zookeeper的client和server的实现类都会验证znode存储的数据是否小于1M。如果数据比较大时,Server之间进行数据同步会消耗比较长的时间,影响系统性能。
2).Watcher
Zookeeper中znode产生某种行为(事件)时,如何让客户端得到通知,进行相关操作?Zookeeper中使用Watcher机制,可以针对ZooKeeper服务的“操作”来设置观察,该服务的其他操作可以触发观察。
Zookeeper中的watcher机制类型:
Exists:在path上执行NodeCreated ,NodeDeleted ,NodeDataChanged .
getData Watcher: 在path上执行 NodeDataChanged ,NodeDeleted .
getChildrenWatcher:在paht上执行NodeDeleted .或在子path上执行NodeCreated ,NodeDeleted 。
Zookeeper中对于某个节点设置Watcher是一次性的,在Znode上watcher触发后会删除该Watcher,所以如果需要对某个Znode节点进行长期关注,在事件触发后,需要在该Znode上重置Watcher。
3)基本操作
创建节点:
Stringcreate(String path,byte[] data, List acl,CreateMode createMode)
创建一个给定的目录节点 path, 并给它设置数据,CreateMode 标识有四种形式的目录节点
删除节点:
void delete(String path,int version)
删除 path 对应的目录节点,version 为 -1 可以匹配任何版本,也就删除了这个目录节点所有数据
查询节点是否存在:
Stat exists(String path,boolean watch/Watcher watcher)
判断某个 path 是否存在,并设置是否监控这个目录节点
获取节点数据:
byte[] getData(String path,boolean watch, Stat stat)
获取这个 path 对应的目录节点存储的数据,数据的版本等信息可以通过 stat 来指定,同时还可以设置是否监控这个目录节点数据的状态
设置节点数据:
Stat setData(String path,byte[] data, int version)
给 path 设置数据,可以指定这个数据的版本号,如果 version 为 -1 怎可以匹配任何版本
获取节点的子节点:
List getChildren(String path,boolean watch)
获取指定 path 下的所有子目录节点,同样 getChildren方法也有一个重载方法可以设置特定的 watcher 监控子节点的状态
(五)PIG:
Pig是一个基于Hadoop的大规模数据分析工具,它提供的SQL-LIKE语言叫Pig Latin,该语言的编译器会把类SQL的数据分析请求转换为一系列经过优化处理的MapReduce运算。相比Java的MapReduce api,Pig为大型数据集的处理提供了更高层次的抽象,与MapReduce相比,Pig提供了更丰富的数据结构,一般都是多值和嵌套的数据结构。Pig还提供了一套更强大的数据变换操作,包括在MapReduce中被忽视的连接Join操作
(六)Hive
(1)hive 是基于 Hadoop 的一个数据仓库工具,可以将结构化的数据文件映射为一张数据库表,并提供完整的 sql 查询功能,可以将 sql 语句转换为 MapReduce 任务进行运行。其优点是学习成本低,可以通过类 SQL 语句快速实现简单的 MapReduce 统计,不必开发专门的 MapReduce 应用,十分适合数据仓库的统计分析。
(2)Hive 是建立在 Hadoop 上的数据仓库基础构架。它提供了一系列的工具,可以用来进行数据提取转化加载(ETL),这是一种可以存储、查询和分析存储在 Hadoop 中的大规模数据的机制。Hive 定义了简单的类 SQL 查询语言,称为 HQL,它允许熟悉 SQL 的用户查询数据。同时,这个语言也允许熟悉 MapReduce 开发者的开发自定义的 mapper 和 reducer 来处理内建的 mapper 和 reducer 无法完成的复杂的分析工作。
(七)sqoop
Sqoop是SQL-to-Hadoop的缩写,主要用于传统数据库和Hadoop之间传输数据。数据的导入和导出本质上是Mapreduce程序,充分利用了MR的并行化和容错性。其中主要利用的是MP中的Map任务来实现并行导入,导出。Sqoop发展到现在已经出现了两个版本,一个是sqoop1.x.x系列,一个是sqoop1.99.X系列。对于sqoop1系列中,主要是通过命令行的方式来操作。
(八)flume
Cloudera开源的日志收集系统,具有分布式、高可靠、高容错、易于定制和扩展的特点。
它将数据从产生、传输、处理并最终写入目标的路径的过程抽象为数据流,在具体的数据流中,数据源支持在Flume中定制数据发送方,从而支持收集各种不同协议数据。同时,Flume数据流提供对日志数据进行简单处理的能力,如过滤、格式转换等。此外,Flume还具有能够将日志写往各种数据目标(可定制)的能力。总的来说,Flume是一个可扩展、适合复杂环境的海量日志收集系统。
总结:
Hadoop中的关键模块:
HDFS/HBase/MapReduce/Zookeeper
其中HDFS提供分布式系统文件系统支撑,提供读写接口;Hbase提供分布式系统中的数据库数据读写,具有强一致性的特点;MapReduce是关键的大数据计算模块;Zookeeper主要用于分布式系统中的一致性协同工作。
PIG/Hive/Flume/Sqoop主要是辅助工具,供用户使用Hadoop的HBase/MapReduce等模块。