2018年python基础面试题总结(持续更新)
- duoniu cm
1. 写一个冒泡排序
def Bubblesort(list):
for i in range(0, len(list)-1):
for j in range(0, len(list)-1-i):
list[j] > list[j+1]
list[j],list[j+1] = list[j+1], list[j]
return list2. 写一个快速排序
def Quicksort(myList,start,end):
if start < end:
i,j = start,end
base = myList[i]
while i= base):
j -= 1
myList[i] = myList[j]
while (i 3. 二分法查找(递归,非递归)
# 递归
def bs1(nums, target):
if not nums:
return False
middle = len(nums)//2
if nums[middle] > target:
return bs1(nums[:middle], target)
elif nums[middle] < target:
return bs1(nums[middle + 1:], target)
else:
return middle
# 非递归
def bs2(nums, target):
start = 0
end = len(nums)-1
while start <= end:
middle = (start+end)//2
if nums[middle] > target:
end = middle - 1
elif nums[middle] < target:
start = middle + 1
else:
return middle
return False4. 链表反转
def reverse(self,head):
if head is None:
return None
p = head
cur = None
pre = None
while p is not None:
cur = p.next
p.next = pre
pre = p
p = cur
return pre
- yunfu kj
1. 给定一个数组 a=[1,1,2,3,3,5]和一个整数n=1,找出出现大于这个整数次数的数组[1,3]
hint: 主要考察列表推导式
a = [1,1,2,3,3,5]
n = 1
b = [x for x in a if a.count(x) > n]
c = list(set(b))
print(c)2. "get_user"转换为小驼峰字符串"getUser", 将"get_used_my_id"转换为"getUsedMyId"
hint:先把'_'去掉并把str转为list;将第一个单词保持小写;其余单词首字母大写;list转为str
def convert(one_string, space_character):
string_list = str(one_string).split(space_character)
first = string_list[0].lower()
others = string_list[1:]
others_capital = [word.capitalize() for word in others]
others_capital[0:0] =[first]
final = ''.join(others_capital)
return final
print(convert('get_user','_')) # getUser
print(convert('get_used_my_id','_')) # getUsedMyId3. n=4,打印出高度为4的三角形(用*表示)
# 打印正三角
for i in range(5):
for j in range(0,5-i):
print(end=' ')
for k in range(5-i,5):
print('*',end=' ')
print('') *
* *
* * *
* * * *
- shuwang kj
1. 字符串'1.2.3.4.5'转换为'5|4|3|2|1'
hint: split()用法和join()用法
a = '1.2.3.4.5'
b = a.split('.')
b = b[::-1]
c = '|'.join(b)
print(c)2. python3.x和python2.x中,import包搜索路径顺序
hint: 没什么区别,但在python3.3以后引入了命名空间包
其特性如下:
1.优先级最低,在已有版本所有的import规则之后;
2.要导入的文件夹中不能有__init__.py文件
3.主要依赖于sys.path中从左到右的搜索顺序
当你导入一个模块,Python 解析器对模块位置的搜索顺序是:
1、当前目录
2、如果不在当前目录,Python 则搜索在 shell 变量 PYTHONPATH 下的每个目录。
3、如果都找不到,Python会察看默认路径。UNIX下,默认路径一般为/usr/local/lib/python/。
模块搜索路径存储在 system 模块的 sys.path 变量中。变量里包含当前目录,PYTHONPATH和由安装过程决定的默认目录。3. python中用正则表达式匹配时间信息
import re
t = '19:10:48'
m = re.match(r'(.*):(.*):(.*)', t)
print(m.groups()) # ('19', '10', '48')
t = '23:59:08'
p = re.compile(r'^(0?[0-9]|1[0-9]|2[0-3]):(0?[0-9]|[1-5][0-9]):(0?[0-9]|[1-5][0-9])$')
s = p.search(t)
print(s.groups()) # ('23', '59', '08')4. range和xrange区别,用python仿写一个xrange函数
- XDYH
一面基础笔试题
1.list切片
2.字符串逆序(尽可能多的方法)
3.lambda函数
4.单引号,双引号,三引号区别
5.补充缺失的代码
def print_directory_contents(sPath):
"""
这个函数接受文件夹的名称作为输入参数,
返回该文件夹中文件的路径,
以及其包含文件夹中文件的路径。
"""
# 补充代码def print_directory_contents(sPath):
import os
for sChild in os.listdir(sPath):
sChildPath = os.path.join(sPath,sChild)
if os.path.isdir(sChildPath):
print_directory_contents(sChildPath)
else:
print(sChildPath)6.阅读下面的代码,写出A0,A1至An的最终值。
A0 = dict(zip(('a','b','c','d','e'),(1,2,3,4,5)))
A1 = range(10)
A2 = [i for i in A1 if i in A0]
A3 = [A0[s] for s in A0]
A4 = [i for i in A1 if i in A3]
A5 = {i:i*i for i in A1}
A6 = [[i,i*i] for i in A1]A0 = {'a': 1, 'c': 3, 'b': 2, 'e': 5, 'd': 4}
A1 = [0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
A2 = []
A3 = [1, 3, 2, 5, 4]
A4 = [1, 2, 3, 4, 5]
A5 = {0: 0, 1: 1, 2: 4, 3: 9, 4: 16, 5: 25, 6: 36, 7: 49, 8: 64, 9: 81}
A6 = [[0, 0], [1, 1], [2, 4], [3, 9], [4, 16], [5, 25], [6, 36], [7, 49], [8, 64], [9, 81]]7.Python和多线程(multi-threading)。这是个好主意码?列举一些让Python代码以并行方式运行的方法。
Python并不支持真正意义上的多线程。Python中提供了多线程包,但是如果你想通过多线程提高代码的速度,使用多线程包并不是个好主意。Python中有一个被称为Global Interpreter Lock(GIL)的东西,它会确保任何时候你的多个线程中,只有一个被执行。线程的执行速度非常之快,会让你误以为线程是并行执行的,但是实际上都是轮流执行。经过GIL这一道关卡处理,会增加执行的开销。这意味着,如果你想提高代码的运行速度,使用threading包并不是一个很好的方法。
不过还是有很多理由促使我们使用threading包的。如果你想同时执行一些任务,而且不考虑效率问题,那么使用这个包是完全没问题的,而且也很方便。但是大部分情况下,并不是这么一回事,你会希望把多线程的部分外包给操作系统完成(通过开启多个进程),或者是某些调用你的Python代码的外部程序(例如Spark或Hadoop),又或者是你的Python代码调用的其他代码(例如,你可以在Python中调用C函数,用于处理开销较大的多线程工作)。
8.下面代码会输出什么:
def f(x,l=[]):
for i in range(x):
l.append(i*i)
print l
f(2)
f(3,[3,2,1])
f(3)答案:
[0, 1]
[3, 2, 1, 0, 1, 4]
[0, 1, 0, 1, 4]第一个函数调用十分明显,for循环先后将0和1添加至了空列表l中。l是变量的名字,指向内存中存储的一个列表。
第二个函数调用在一块新的内存中创建了新的列表。l这时指向了新生成的列表。之后再往新列表中添加0、1、2和4。很棒吧。
第三个函数调用的结果就有些奇怪了。它使用了之前内存地址中存储的旧列表。这就是为什么它的前两个元素是0和1了。
9.这两个参数是什么意思:*args,**kwargs?我们为什么要使用它们?
如果我们不确定要往函数中传入多少个参数,或者我们想往函数中以列表和元组的形式传参数时,那就使要用*args;
如果我们不知道要往函数中传入多少个关键词参数,或者想传入字典的值作为关键词参数时,那就要使用**kwargs。
10.下面这些是什么意思:@classmethod, @staticmethod, @property?
这些都是装饰器(decorator)。装饰器是一种特殊的函数,要么接受函数作为输入参数,并返回一个函数,要么接受一个类作为输入参数,并返回一个类。
@标记是语法糖(syntactic sugar),可以让你以简单易读得方式装饰目标对象。
11.写一个单例模式,保证线程安全
12.简要描述Python的垃圾回收机制(garbage collection)
- Python在内存中存储了每个对象的引用计数(reference count)。如果计数值变成0,那么相应的对象就会小时,分配给该对象的内存就会释放出来用作他用。
- 偶尔也会出现
引用循环(reference cycle)。垃圾回收器会定时寻找这个循环,并将其回收。举个例子,假设有两个对象o1和o2,而且符合o1.x == o2和o2.x == o1这两个条件。如果o1和o2没有其他代码引用,那么它们就不应该继续存在。但它们的引用计数都是1。 - Python中使用了某些启发式算法(heuristics)来加速垃圾回收。例如,越晚创建的对象更有可能被回收。对象被创建之后,垃圾回收器会分配它们所属的代(generation)。每个对象都会被分配一个代,而被分配更年轻代的对象是优先被处理的。
13.将下面的函数按照执行效率高低排序。它们都接受由0至1之间的数字构成的列表作为输入。这个列表可以很长。一个输入列表的示例如下:[random.random() for i in range(100000)]。你如何证明自己的答案是正确的。
def f1(lIn):
l1 = sorted(lIn) # 100000
l2 = [i for i in l1 if i<0.5] # 50000
return [i*i for i in l2] # 50000
def f2(lIn):
l1 = [i for i in lIn if i<0.5] # 50000
l2 = sorted(l1) # 50000
return [i*i for i in l2] # 50000
def f3(lIn):
l1 = [i*i for i in lIn] # 100000
l2 = sorted(l1) # 100000
return [i for i in l1 if i<(0.5*0.5)] # 100000f2>f1>f3,原因如注释所写
14.赋值,深拷贝,浅拷贝区别
赋值:对象的引用
浅拷贝:只拷贝表面一层,如果有嵌套内容,为对象引用,跟着变。
深拷贝:不管嵌套多少层, 全部拷贝,相互不受影响。
举例:
import copy
l1 = [1,2,3,[4,5]]
l2 = copy.copy(l1)
l1.append(4)
print(l2) # [1,2,3,[4,5]]
l1[3].append(6)
print(l2) # [1,2,3,[4,5,6]]
l4 = [1,2,[3,4]]
l5 = copy.deepcopy(l4)
l4.append(3)
print(l5) # 无变化
l4[2].append(5)
print(l5) # 无变化二面技术面
装饰器了解吗?
MVC框架了解吗?优缺点是什么?耦合度是相互依赖程度,越低越好
前端后端如何交互?
单例模式?设计模式?可以用于重构代码,之前写的业务代码逻辑有重复,可以用这个减少冗余度
总结一下:
如果想转web开发,基础框架得会用,且了解整体流程,构造,答得不好的地方:装饰器,非关键参数,关键参数,单例模式,递归等。总的来说有收获,认识到自己的不足。
JYZT(软件工程师岗位)
1. 有一个数组,只有一对重复数字,其余数字都是不重复的,如何高效的找出重复的数字?(剑指offer)
个人理解这个高效指的就是时间复杂度要低,可以用空间换时间。
当时没有反应过来,写的代码时间复杂度是O(n),现在想想是很有问题的0.0
如果用二分法的话时间复杂度就是O(logn),会好一些
2. 生孩子,想要男孩,如果生的女孩就直到生到男孩为止,问男女比例?对人口比例的影响?
当时是懵逼的,后面百度了据说是Google的面试题,其实是一道概率学的问题。
正解:
男女比例1:1
假设这个国家有n对夫妇,那么n对夫妇将生下n个男孩,这n个男孩是这样生下的,假设生男生女的概率是50%,那么n/2个男孩是第一胎生下的,同时将有 n/2个女孩生下,n/2对生女孩的夫妇将继续生,其中n/4的夫妇生下男孩,n/4的夫妇继续生下女孩,然后是n/8的夫妇顺利得到男孩,又有n/8的 夫妇生下女孩,依此类推,这个国家将生下n/2 + n/4 + n/8 + ...的女孩,所以男女比例是n : (n/2 + n/4 + n/8 + ...) = n : n = 1 : 1 过程都是一样的,出生男孩子和女孩子的概率都是50%,所以每次出生的男女比例是相同的。
3. 两个栈实现一个队列,实现添加元素和弹出元素的功能(剑指offer)
class QueueWithTwoStacks(object):
def __init__(self,stack1,stack2):
self.stack1 = []
self.stack2 = []
def append_element(self,x):
self.stack1.append(x)
def pop_element(self):
if self.stack2:
return self.stack2.pop()
else:
if self.stack1:
while self.stack1:
self.stack2.append(self.stack1.pop())
return self.stack2.pop()
else:
return None
q = QueueWithTwoStack()
q.append_element(1)
q.append_element(2)
q.append_element(3)
q.pop_element()
q.pop_element()
q.pop_element()
4. 八进制数,a对应1,z对应26,aa对应27,aaa对应703,输入一个数字,输出字符串
如:输入 32, 输出 af
答案暂时不清楚。
5. 模拟银行排队办理业务
LS
1. 用列表生成器1到100的偶数列表,a[50:100]返回值是多少?
a = [i for i in range(1,101) if i%2 == 0] # [2,4,6,8....100]
print(a[50:100]) # []2. a=1,b=2不用中间变量交换a,b的值
a = 1
b = 2
a,b = b,a
print(a) # 2
print(b) # 13. 将字符串倒叙,a = 'abcdefg'变为'gfedcba' (7种方法)
# 切片
def func1(str1):
return str1[::-1]
# 列表reverse方法
def func2(str1):
str1_list = list(str1)
str1_list.reverse()
return "".join(str1_list)
# 列表sort方法
def func3(str1):
str1_list = list(str1)
str1_list.sort(reverse=True)
return "".join(str1_list)
# sorted函数
def func4(str1):
str1_list = list(str1)
sorted_str1_list = sorted(str1_list,reverse=True)
return "".join(sorted_str1_list)
# 新建一个列表,从后往前添加元素
def func5(str1):
temp = []
for i in range(len(str1)-1, -1, -1):
temp.append(str1[i])
return "".join(temp)
# 双端队列
from collections import deque
def func6(str1):
deque1 = deque(str1)
deque2 = deque()
for i in deque1:
deque2.extendleft(i)
return "".join(deque2)
# 递归实现
def func7(str1):
if len(str1) <= 1:
return str1
return str[-1] + func5(str[:-1])4. 数据库里有一张订单表,统计最近30天每天的订单数?订单表名:order,订单时间字段create_time(datetime)
SELECT * FROM order WHERE DATE_SUB(CURDATE(), INTERVAL 30 DAY) <= create_time(datetime)
5. 对计算量大的函数的值进行缓存,如对这个函数,def calc(a,b): return a**b如何实现?
rs = redis.StrictRedis(host='localhost')
def cache_result(func):
# 请实现该函数
@cache_result
def calc(a,b):
return a**b6. 用最少行数计算某字符串(只有数字和空格)中偶数的和,a = '12 21 23 22 5 67'
a = '12 21 23 22 5 67'
b = sum([int(i) for i in a if int(i)%2 == 0]) # 12+22 = 347. 一般怎么优化响应慢的接口?
从硬件方面,
服务器配置提升,系统整体的执行效率提升
从数据库方面,
sql优化,适当使用链表查询,使用连接JOIN来代替子查询,一般大表和多表的情况避免使用JOIN
sql优化,查询表数据时,精确字段名进行查询,避免不必要的字段查询
sql优化,适当使用主外键和索引
sql优化,适当使用in查询,适当使用模糊查询
数据库的优化,字段使用合理的字段类型,尽量把字段设置为NOTNULL,避免空间浪费
数据库的优化,合理设计表结构
从代码方面,
for合理运用,尽量少在循环中嵌套循环,在循环次数过多的情况下,非常耗性能
循环中,尽量避免数据操作,特别是查询操作,在循环次数过多的情况下,多次调用效率很低,可一次获取数据再拼接
可以用上字典的概念,将数组以新索引形式存储起来
根据场景,合理使用缓存可以减少重复的数据查询,提高效率
8. 针对接口设计还有哪些安全设计?
Token授权机制:用户使用用户名密码登录后服务器给客户端返回一个Token(通常是UUID),并将Token-UserId以键值对的形式存放在缓存服务器中。服务端接收到请求后进行Token验证,如果Token不存在,说明请求无效。Token是客户端访问服务端的凭证。
时间戳超时机制:用户每次请求都带上当前时间的时间戳timestamp,服务端接收到timestamp后跟当前时间进行比对,如果时间差大于一定时间(比如5分钟),则认为该请求失效。时间戳超时机制是防御DOS攻击的有效手段。
签名机制:将 Token 和 时间戳 加上其他请求参数再用MD5或SHA-1算法(可根据情况加点盐)加密,加密后的数据就是本次请求的签名sign,服务端接收到请求后以同样的算法得到签名,并跟当前的签名进行比对,如果不一样,说明参数被更改过,直接返回错误标识。签名机制保证了数据不会被篡改。
9. 列举工作中经常用到的数据结构?
列表,字典,元组,栈,队列,链表
DSYD(数据挖掘工程师岗位)
电面
1.冒泡排序和快速排序,原理,时间复杂度?
冒泡排序:相邻元素作为一对比大小,最大的数放在最后,然后再从索引0的位置开始,直到N-1-1,时间复杂度O(n2)
快速排序:选取一个数为基准数,所有比它小的放左边,比它大的放右边,用两个变量i和j分别指向序列最左边和最右边,j--,i++,交换i和j所指向的值,i和j相遇,基准数交换,再分别处理左边和右边的序列,时间复杂度O(nlogn)
2.如果有N个数(很大,比如说1亿)从中找出最大的k个数?
有名的TopK问题,这个问题非常常见,比如从1千万搜索记录中找出最热门的10个关键词
如果n很大呢?100亿?这个时候数据不能全部装入内存,所以要求尽可能少地遍历所有数据。
前K个数中最大的K个数是一个退化的情况,所有K个数就是最大的K个数,如果考虑第K+1个数,则它和前面K个数的最小值进行比较,比其大则替换它。
如果用一个数组来存储最大的K个数,每加入一个数X,就扫描一遍数组,得到数组中最小的数Y。X和Y进行比较,替换它或者保持原数组不变。这种方法,所耗费的时间复杂度为O(n * K)。
进一步,可以用容量为K的最小堆来存储最大的K个数。最小堆的堆顶元素就是最大K个数中最小的一个。每次新考虑一个数X,如果X小于堆顶则舍弃,如果X大于堆顶,那么用X替换堆顶,然后更新堆来维持堆的性质。(因为X可能并不是最小值,所以堆结构需要更新)。更新过程花费的时间复杂度为O(log2K)。
因此,算法的时间复杂度为O(n * log2K),这实际上是部分执行了堆排序的算法。
方法一:
先排序,然后截取前k个数.
时间复杂度:O(n*logn)+O(k)=O(n*logn)。
这种方式比较简单粗暴,提一下便是。
方法二:最大堆
我们可以创建一个大小为K的数据容器来存储最小的K个数,然后遍历整个数组,将每个数字和容器中的最大数进行比较,如果这个数大于容器中的最大值,则继续遍历,否则用这个数字替换掉容器中的最大值。这个方法的理解也十分简单,至于容器的选择,很多人第一反应便是最大堆,但是python中最大堆如何实现呢?我们可以借助实现了最小堆的heapq库,因为在一个数组中,每个数取反,则最大数变成了最小数,整个数字的顺序发生了变化,所以可以给数组的每个数字取反,然后借助最小堆,最后返回结果的时候再取反就可以了
import heapq
def get_least_numbers_big_data(self, alist, k):
max_heap = []
length = len(alist)
if not alist or k <= 0 or k > length:
return
k = k - 1
for ele in alist:
ele = -ele
if len(max_heap) <= k:
heapq.heappush(max_heap, ele)
else:
heapq.heappushpop(max_heap, ele)
return map(lambda x:-x, max_heap)
if __name__ == "__main__":
l = [1, 9, 2, 4, 7, 6, 3]
min_k = get_least_numbers_big_data(l, 3)
方法三:quick select
quick select算法.其实就类似于快排.不同地方在于quick select每趟只需要往一个方向走.
时间复杂度:O(n).
def qselect(A,k):
if len(A)=pivot]
rlen = len(right)
if rlen==k:
return right
if rlen>k:
return qselect(right, k)
else:
left = [x for x in A[:-1] if x 3.如果有N个数(很大,比如说1亿)从中找出最大的1个数?最大的两个数呢?
将这一个数放入一个数组,将N个数分别与其比较,大的就交换,时间复杂度O(n)
将这两个数放入一个数组,每来一个数分别与这两个数比较,最小的那个被替换,时间复杂度O(2n),由此可以看出找出最大的k个数,时间复杂度就是O(k*n)
4.堆?堆排序?
5.定义类时继承object和不继承object有什么区别?
例如:
class Solution(object):
class Solution():
在python2.x中,通过分别继承自object和不继承object定义不同的类,之后通过dir()和type分别查看该类的所有方法和类型:
>>> class test(object):
... pass
...
>>> dir(test)
['__class__', '__delattr__', '__dict__', '__doc__', '__format__', '__getattribute__', '__hash__', '_
_init__', '__module__', '__new__', '__reduce__', '__reduce_ex__', '__repr__', '__setattr__', '__size
of__', '__str__', '__subclasshook__', '__weakref__']
>>> type(test)
>>> class test2():
... pass
...
>>> dir(test2)
['__doc__', '__module__']
>>> type(test2)
在3.x中:两者是一致的,因为在3.x中,默认继承就是object了
>>> class test(object):
pass
>>> class test2():
pass
>>> type(test)
>>> type(test2)
>>> dir(test)
['__class__', '__delattr__', '__dict__', '__dir__', '__doc__', '__eq__', '__format__', '__ge__', '__getattribute__', '__gt__', '__hash__', '__init__', '__init_subclass__', '__le__', '__lt__', '__module__', '__ne__', '__new__', '__reduce__', '__reduce_ex__', '__repr__', '__setattr__', '__sizeof__', '__str__', '__subclasshook__', '__weakref__']
>>> dir(test2)
['__class__', '__delattr__', '__dict__', '__dir__', '__doc__', '__eq__', '__format__', '__ge__', '__getattribute__', '__gt__', '__hash__', '__init__', '__init_subclass__', '__le__', '__lt__', '__module__', '__ne__', '__new__', '__reduce__', '__reduce_ex__', '__repr__', '__setattr__', '__sizeof__', '__str__', '__subclasshook__', '__weakref__'] 6.@classmethod和@staticmethod区别?
@classmethod和@staticmethod很相似,它们装饰的方法在使用上只有一点区别:@classmethod装饰的方法第一个参数必须是一个类(通常为cls),而@staticmethod装饰的方法则按业务需求设置参数,也可以根本没有参数。
对于classmethod方法
当实例调用classmethod方法时,默认会把当前实例所对应的类传进去
当类调用classmethod方法时,默认把此类传进去
对于staticmethod方法
实例和类调用,没有默认的参数传进函数
class Locker(object):
a = 'aa'
@staticmethod
def show():
print 'show'
@classmethod
def display(cls):
print 'display'
def out(self):
print 'out'
cc = Locker()
Locker.show() # show
cc.show() # show
Locker.display() # display
cc.display() # display
Locker.out(cc) # out
cc.out() # out
我们修改classmethod方法:
class Locker(object):
a = 'aa'
@staticmethod
def show():
print 'show'
@classmethod
def display(cls):
print cls.a
def out(self):
print 'out'
cc = Locker()
cc.a = 'vv'
Locker.display() # aa
cc.display() # aa
当实例调用classmethod方法时,默认传入的参数是实例对应的类
总结:
classmethod 和普通函数调用时都有默认参数传入,只有staticmethod调用时没有任何默认参数传入
7.多线程和多进程?什么情况下用多线程?什么情况下不用多线程?
多线程:由于GIL全局解释锁的存在,一个线程在执行的时候,加上GIL锁,如果线程遇到耗时操作,释放GIL锁,其他线程执行,所以多个线程执行顺序是有先后的,不存在多个线程同时运行的情况。
多进程:因为每个进程都能被分配系统资源,相当于每个进程都有一个python解释器,所以多进程可以实现同时运行,缺点是系统资源开销大。
应用:
IO密集(如socket server 网络并发这一类的)的用多线程,在用户输入,sleep的时候,可以切换到其他线程执行,减少等待的时间
python多线程不适合CPU操作密集的任务
CPU密集的用多进程,假如IO操作少,用多线程的话,因为线程共享一个GIL锁,当前运行的线程会霸占GIL,其他线程没有GIL,就不能充分利用多核CPU的优势
io 操作不占用CPU(从硬盘、从网络、从内存读数据都算io)
计算占用CPU(如1+1计算)
总结:
所以在python中,多进程的执行效率优先于多线程(仅仅对多核cpu而言)。
多核下,想做并行提升效率,比较通用的方法是使用多进程,能够有效提高执行效率。
weego(Python开发)
一面 笔试
1. 拷贝的区别
浅拷贝,深拷贝
# 浅拷贝
import copy
l1 = [1,2,3,[4,5]]
l2 = copy.copy(l1)
print(l2) # [1,2,3,[4,5]]
l1.append(4)
l1[3].append(6)
print(l2) # [1,2,3,[4,5,6]]
# 深拷贝
l3 = [1,2,3,[4,5]]
l4 = copy.deepcopy(l3)
print(l4) # [1,2,3,[4,5]]
l3.append(4)
l3[3].append(6)
print(l4) # [1,2,3,[4,5]]
2. python垃圾回收机制
1) python在内存中存储了每个对象的引用计数,当对象的引用计数为0时,对象消失,分配给该对象的内存会被释放
2)偶尔也会出现引用循环reference cycle,垃圾回收器会定时寻找这个循环,并将其回收
3)python中使用了某些启发式算法来加速垃圾回收,例如越晚创建的对象更有可能被回收,对象被创建之后,垃圾回收器会分 配他们所属的代generation,每个对象会被分配一个代,被分配更年轻代的对象是优先被处理的
3.多线程,多进程,协程区别
多线程:线程是CPU进行资源分配和调度的基本单位,多个线程相互独立,一个线程在运行时会霸占python解释器(加了GIL锁),其他线程无法运行,如果线程运行过程中遇到耗时操作,则GIL锁解开,使其他线程运行,所以在多线程中,线程的运行有先后顺序,并不是同时运行
多进程:进程是系统进行资源分配和调度的基本单位,多个进程相互独立,优点是稳定性好,一个进程崩溃不影响其他进程,缺点是进程消耗资源大,开启的进程数量有限
应用:
IO密集的用多线程,sleep的时候可以切换到其他线程执行,减少等待时间,假如IO操作少,用多线程的话当前线程会霸占GIL锁,其他线程没有GIL,不能充分利用多核CPU的优势
CPU密集的用多进程
协程:微线程,特点在于是一个线程执行,执行效率高,我们把一个线程中的一个个函数叫做子程序,那么子程序在执行过程中可以中断去执行别的子程序,别的子程序也可以中断回来继续执行之前的子程序,子程序切换不是线程切换,是程序自身控制。
# 执行顺序
# 先进入test1,打印12,遇到gevent.sleep(0),test1被阻塞,自动切换到协程test2,打印56
# test2被阻塞,test1阻塞结束,自动切换回test1,打印34
# 当test1运行完毕后,test2阻塞结束,再自动切换回test2,打印78
import gevent
def test1():
print(12)
gevent.sleep(0)
print(34)
def test2():
print(56)
gevent.sleep(0)
print(78)
gevent.joinall([gevent.spawn(test1),gevent.spawn(test2)])
4.list,dict,tuple,set的特性和区别
| 名称 | 可变性 | 存在形式 | 可重复性 | 有序性 | 其他特点 |
| list | 可修改 | [1,2] | 可 | 有序 | 占用内存小,常用于堆栈处理 |
| tuple | 不可修改 | (1,2) | 可 | 有序 | 本身不可变,相对稳定 |
| dict | 键不可变,值可变 | {1:1,2:2} | 键不可,值可 | 无序 | 符合用内存换速度思想,常用于查找 |
| set | 可修改 | set([1,2]) | 不可 | 无需 | 常用于判断值是否存在 |
5.快速排序原理,递归,非递归实现
递归:
1)将数组的第一位元素设为基准数
2)设置两个变量i和j,i为0,j为N-1(数组的索引)
3)j向左移动,直到找到一个比基准数小的停下
4)i向右移动,直到找到一个比基准数大的停下
5)交换i和j指向的值
6)当i和j汇合时,基准数交换
7)所以比基准数小的都在左边,比基准数大的都在右边,再分别进行递归操作
def qucik_sort(l1,left,right):
if len(l1) < 2:
return l1
else:
if left < right:
i,j = left,right
base = l1[i]
while i < j:
while i < j and l1[j] >= base:
j -= 1
l1[i] = l1[j]
while i < j and l1[i] <= base:
i += 1
l1[j] = l1[i]
l1[i] = base
quick_sort(l1,left,i-1)
quick_sort(l1,j+1,right)非递归:
每次把待排序数组分为两部分,左边小于轴右边大于轴,把分开的数组的收尾数组的索引存到辅助栈空间里,替换递归。
二面 技术面
1.魔法方法有哪些?
基础魔法方法
__new__(cls,...) 实例化对象时第一个被调用的方法,其参数直接传递给__init__方法处理,一般不会重写该方法
__init__(self,...) 构造方法,初始化类的时候调用
__len__(self) 定义当被len()调用时的行为
__repr__(self) 定义当被 repr() 调用时的行为
__str__(self) 定义当被 str() 调用时的行为
属性相关的方法
__getattr__(self, name) 定义当用户试图获取一个不存在的属性时的行为
__getattribute__(self, name) 定义当该类的属性被访问时的行为
__get__(self, instance, owner) 定义当描述符的值被取得时的行为
2.二叉树遍历
3.mysql中,两个表A,B,A表中有id,name字段,B表中有id,nickname,salary字段,现要找出A表中以em开头的姓名中的A.name,B.salary,写出sql语句
考察点:模糊查询和多表查询
select A.name,B.salary from A,B where A.id = B.id and A.name like "em%";
GaoYuHaiHui(Python开发)
一面技术面
1. is和==区别?
==用来判断两个对象的value值是否相等
is用来判断两个对象的id是否相同
list和dict存在value值相同id不同的情况,就叫可变对象;str,数据型,value值相同id相同,叫做不可变对象
2. copy和deepcopy的本质区别?
寻常意义的复制指的就是deepcopy,将对象完全复制一遍作为独立的新个体存在,所以改变原有对象不会对复制出来的新对象产生影响。
浅复制并不会产生一个独立的新对象,只是将原有的数据打上一个新标签,所以当标签改变时,数据块会发生变化。
3. classmethod和staticmethod?
classmethod类方法;staticmethod静态方法
classmethod 必须使用类对象作为第一个参数传入,表示接下来的是一个类方法,对于我们平时见到的称为实例方法,类方法的第一个参数是cls,实例方法的第一个参数是self,表示该类的一个实例
当实例调用classmethod方法时,默认传入的参数是实例对应的类
staticmethod调用时没有任何默认参数传入
class A(object):
@classmethod
def cm(cls):
print('类方法调用者:',cls.__name__)
@staticmethod
def sm():
print('静态方法被调用')
class B(A):
pass
A.cm() # 类方法调用者:A
B.cm() # 类方法调用者:B
A.sm() # 静态方法被调用
B.sm() # 静态方法被调用4. 字符串倒序,a='afdcx'
因为是乱序的,所以sort和sorted不能用
a = 'afcgzb'
# 方法一 切片
print(a[::-1])
# 方法二 list.reverse()
l1 = list(a)
print(l1)
l1.reverse()
print(''.join(l1))
# 方法三 新建列表,从后往前添加元素
temp = []
b = list(a)
for i in range(len(b)-1,-1,-1):
temp.append(b[i])
print("".join(temp))
# 方法四 双端队列
from collections import deque
deque1 = deque(a)
deque2 = deque()
for i in deque1:
deque2.extendleft(i)
print("".join(deque2))
# 方法五 递归
def fnc(a):
if len(a) <= 1:
return a
return a[-1] + fnc(a[:-1])
print(fnc(a))5. 单例模式本质?写一个
单例模式:当业务并发量非常大时,就会出现重复创建相同的对象,每创建一个对象就会开辟一块内存空间,单例模式可以让内存对象只创建一次,然后随意使用。
class A(object):
__instance = None
@staticmethod
def create_obj():
if not A.__instance:
A.__instance = A()
return A.__instance
else:
return A.__instance
obj1 = A.create_obj()
obj2 = A.create_obj()
obj3 = A.create_obj()
print(id(obj1),id(obj2),id(obj3)) # id相同6. mysql中如何通过优化?假如几百万条数据,如何让其查询速度更快
不要盲目的创建索引,只为查询操作频繁的列创建索引,创建索引会使查询操作变得更加快速,但是会降低增加、删除、更新操作的速度,因为执行这些操作的同时会对索引文件进行重新排序或更新。
但是,在互联网应用中,查询的语句远远大于DML的语句,甚至可以占到80%~90%,所以也不要太在意,只是在大数据导入时,可以先删除索引,再批量插入数据,最后再添加索引。
二、索引优化
1、ORDER BY 子句,尽量使用Index方式排序,避免使用FileSort方式排序
MySQL支持两种方式的排序,FileSort和Index,Index效率高。它指MySQL扫描索引本身完成排序。FileSort方式效率较低。
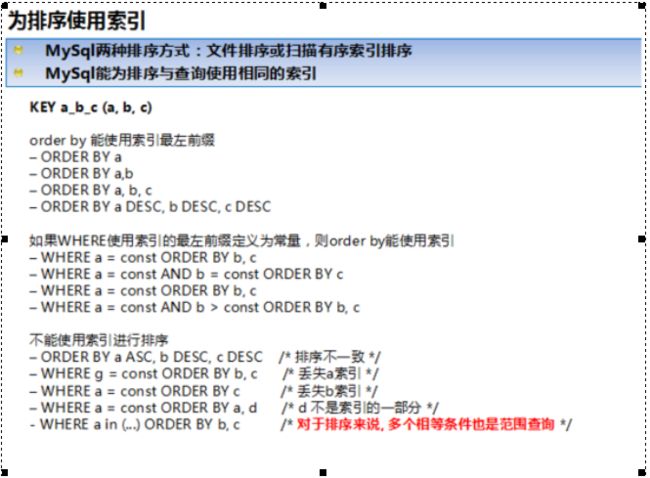
ORDER BY 满足两种情况,会使用Index方式排序
①ORDER BY语句使用索引最左前列
②使用WHERE 子句与ORDER BY子句条件列组合满足索引最左前列

2、GROUP BY 关键字优化
1、group by 实质是先排序后分组,遵照索引的最佳左前缀。
2、当无法使用索引列,增大max_length_for_sort_data参数的设置+增大sort_buffer_size参数的设置
3、where 高于having,能写在where限定的条件就不要去having去限定了。
1、应尽量避免在 where 子句中使用!=或<>操作符,否则将引擎放弃使用索引而进行全表扫描。 2、对查询进行优化,应尽量避免全表扫描,首先应考虑在 where 及 order by 涉及的列上建立索引。 3、应尽量避免在 where 子句中对字段进行 null 值判断,否则将导致引擎放弃使用索引而进行全表扫描,如: select id from t where num is null 可以在num上设置默认值0,确保表中num列没有null值,然后这样查询: select id from t where num=0 4、尽量避免在 where 子句中使用 or 来连接条件,否则将导致引擎放弃使用索引而进行全表扫描,如: select id from t where num=10 or num=20 可以这样查询: select id from t where num=10 union all select id from t where num=20 5、下面的查询也将导致全表扫描:(不能前置百分号) select id from t where name like ‘%c%’ 若要提高效率,可以考虑全文检索。 6、in 和 not in 也要慎用,否则会导致全表扫描,如: select id from t where num in(1,2,3) 对于连续的数值,能用 between 就不要用 in 了: select id from t where num between 1 and 3 7、如果在 where 子句中使用参数,也会导致全表扫描。因为SQL只有在运行时才会解析局部变量,但优化程序不能将访问计划的选择推迟到运行时;它必须在编译时进行选择。 然 而,如果在编译时建立访问计划,变量的值还是未知的,因而无法作为索引选择的输入项。如下面语句将进行全表扫描: select id from t where num=@num 可以改为强制查询使用索引: select id from t with(index(索引名)) where num=@num 8、应尽量避免在 where 子句中对字段进行表达式操作,这将导致引擎放弃使用索引而进行全表扫描。如: select id from t where num/2=100 应改为: select id from t where num=100*2 9、应尽量避免在where子句中对字段进行函数操作,这将导致引擎放弃使用索引而进行全表扫描。如: select id from t where substring(name,1,3)=’abc’–name以abc开头的id select id from t where datediff(day,createdate,’2005-11-30′)=0–’2005-11-30′生成的id 应改为: select id from t where name like ‘abc%’ select id from t where createdate>=’2005-11-30′ and createdate<’2005-12-1′ 10、不要在 where 子句中的“=”左边进行函数、算术运算或其他表达式运算,否则系统将可能无法正确使用索引。 11、在使用索引字段作为条件时,如果该索引是复合索引,那么必须使用到该索引中的第一个字段作为条件时才能保证系统使用该索引, 否则该索引将不会被使 用,并且应尽可能的让字段顺序与索引顺序相一致。 12、不要写一些没有意义的查询,如需要生成一个空表结构: select col1,col2 into #t from t where 1=0 这类代码不会返回任何结果集,但是会消耗系统资源的,应改成这样: create table #t(…) 13、很多时候用 exists 代替 in 是一个好的选择: select num from a where num in(select num from b) 用下面的语句替换: select num from a where exists(select 1 from b where num=a.num) 14、并不是所有索引对查询都有效,SQL是根据表中数据来进行查询优化的,当索引列有大量数据重复时,SQL查询可能不会去利用索引, 如一表中有字段 sex,male、female几乎各一半,那么即使在sex上建了索引也对查询效率起不了作用。 15、索引并不是越多越好,索引固然可以提高相应的 select 的效率,但同时也降低了 insert 及 update 的效率,因为 insert 或 update 时有可能会重建索引,所以怎样建索引需要慎重考虑,视具体情况而定。 一个表的索引数最好不要超过6个,若太多则应考虑一些不常使用到的列上建的索引是否有 必要。 16.应尽可能的避免更新 clustered 索引数据列,因为 clustered 索引数据列的顺序就是表记录的物理存储顺序,一旦该列值改变将导致整个表记录的顺序的调整,会耗费相当大的资源。 若应用系统需要频繁更新 clustered 索引数据列,那么需要考虑是否应将该索引建为 clustered 索引。 17、尽量使用数字型字段,若只含数值信息的字段尽量不要设计为字符型,这会降低查询和连接的性能,并会增加存储开销。 这是因为引擎在处理查询和连接时会 逐个比较字符串中每一个字符,而对于数字型而言只需要比较一次就够了。 18、尽可能的使用 varchar/nvarchar 代替 char/nchar ,因为首先变长字段存储空间小,可以节省存储空间,其次对于查询来说,在一个相对较小的字段内搜索效率显然要高些。 19、任何地方都不要使用 select * from t ,用具体的字段列表代替“*”,不要返回用不到的任何字段。 20、尽量使用表变量来代替临时表。如果表变量包含大量数据,请注意索引非常有限(只有主键索引)。 21、避免频繁创建和删除临时表,以减少系统表资源的消耗。 22、临时表并不是不可使用,适当地使用它们可以使某些例程更有效,例如,当需要重复引用大型表或常用表中的某个数据集时。但是,对于一次性事件,最好使 用导出表。 23、在新建临时表时,如果一次性插入数据量很大,那么可以使用 select into 代替 create table,避免造成大量 log ,以提高速度;如果数据量不大,为了缓和系统表的资源,应先create table,然后insert。 24、如果使用到了临时表,在存储过程的最后务必将所有的临时表显式删除,先 truncate table ,然后 drop table ,这样可以避免系统表的较长时间锁定。 25、尽量避免使用游标,因为游标的效率较差,如果游标操作的数据超过1万行,那么就应该考虑改写。 26、使用基于游标的方法或临时表方法之前,应先寻找基于集的解决方案来解决问题,基于集的方法通常更有效。 27、与临时表一样,游标并不是不可使用。对小型数据集使用 FAST_FORWARD 游标通常要优于其他逐行处理方法,尤其是在必须引用几个表才能获得所需的数据时。 在结果集中包括“合计”的例程通常要比使用游标执行的速度快。如果开发时 间允许,基于游标的方法和基于集的方法都可以尝试一下,看哪一种方法的效果更好。 28、在所有的存储过程和触发器的开始处设置 SET NOCOUNT ON ,在结束时设置 SET NOCOUNT OFF 。无需在执行存储过程和触发器的每个语句后向客户端发送 DONE_IN_PROC 消息。 29、尽量避免向客户端返回大数据量,若数据量过大,应该考虑相应需求是否合理。 30、尽量避免大事务操作,提高系统并发能力。