机器学习的一些基本概念,模型、目标函数、优化算法等等,这些概念对于机器学习算法来说都是通用的套路。
基本形式
有一个实例x有d个属性\(x=(x_{1};x_{2};...x_{d})\),线性模型要通过属性的线性组合来预测函数,即\[y(x)=w_{1}x_{1}+w_{2}x_{2}+...w_{d}x_{d}+b\]
一般转换成向量的形式:\[y(x)=w^{T}x_i+b\]
其中w和b学的之后,模型就确定了。模型是根据输入x预测输出y的算法。$y(x)$函数叫做假设,$w$叫做属性,b是参数。$x_i$称为特征。
许多功能更为强大的非线性模型可在线性模型的基础上通过引入层级结构或高维映射而得。
监督学习和无监督学习
有监督学习:为了训练一个模型,我们要提供一堆训练样本:每个训练样本既包括输入特征x,也包括对应的输出y(标记),让模型既看到输入特征x,也看到对应标记y。当模型看到足够多的样本之后,它就能总结出其中的一些规律。然后,就可以预测那些它没看过的输入所对应的答案了。
无监督学习:这种方法的训练样本只知道输入特征x,没有输出标记。
线性回归
“线性回归”得到的结果是一个预测实值输出标记值\(y(x_{i})\)。给定数据集\(D={(x_{1},y_{1},(x_{2},y_{2}),(x_{3},y_{3}),...,(x_{m},y_{m})}\),我们简写为\(D={(x_{m},y_{m})}_{i=1}^{m}\)。对于离散属性,若属性间存在“序”的关系,可以通过连续化将其转换成连续值,例如一个属性高度有三个值{“高”,“中”,“矮”}可以转换为{1.5,1.0,0.5};若属性间不存在序的关系,例如有k个属性,则通常转换为k维向量,属性“瓜类”的取值“西瓜”“南瓜”“黄瓜”,可以转换为(0,0,1),(0,1,0),(1,0,0)。
多个数据所对应的一个属性
\[f(x)=wx_{i}+b\]
其中x表示对应数据的属性,w表示数据属性x的权值。\(y(x_{i})\)是预测标记,\(y_{i}\)是真实标记,我们就通过\(y(x_{i})\)和\(y_{i}\)差别最小的时候,求得w和b,模型就确定了。通常我们采用来度量了详细你回归中的性能,即:
$E=\sum_{i=1}^{n}e^{i}=(w^{*},b^{*})=arg\min_{(w,b)}\frac{1}{2}\sum_{i=1}^{m}(y(x_{i})-y_{i})^{2}=arg\min_{(w,b)}\sum_{i=1}^{m}(y_{i}-wx_{i}-b)^{2}$
均方误差对应了常用的欧几里得距离,基于均方误差最小化来进行模型求解的方法称为“最小二乘法”,在线性回归中,最小二乘法就是试图找到一条直线,使得所有样本到直线的距离之和最小。
求解w,b使得\(E_{(w,b)}=\sum_{i=1}^{m}(y_{i}-wx_{i}-b)^{2}\)最小化的过程,称为线性回归模型的最小二乘“参数估计”,我们将\(E_{(w,b)}\)分别对w,b求导,得到:
\[\frac{\partial E_{(w,b)}}{\partial W}=2(w\sum_{i=1}^{m}x_{i}^{2}-\sum_{i=1}^{m}(y_{i}-b)x_{i})\]
\[\frac{\partial E_{(w,b)}}{\partial b}=2(mb-\sum_{i=1}^{m}(y_{i}-wx_{i}))\]
令上面两个式子分别等于0,两个方程两个未知解,得到w和b的最优解:
\[w=\frac{\sum_{i=1}^{m}y_{i}(x_{i}-\bar{x})}{\sum_{i=1}^{m}x_{i}^{2}-\frac{1}{m}(\sum_{i=1}^{m}x_{i})^{2}}\]
\[b=\frac{1}{m}\sum_{i=1}^{m}(y_{i}-wx_{i})\]
其中$\bar{x}=\frac{1}{m}\sum_{i=1}^{m}x_{i}$为x的均值。
多个数据所对应的多个属性
“多元线性回归”线性模型为:$h_\theta (x)=\theta _0 +\theta _1x_1+\theta _2x_2....+\theta _Nx_N$
整理一下:$h_\theta (x)=\sum_{i=0}^{n}\theta _ix_i=\theta ^Tx$
$$\begin{array}{ccc}
\begin{pmatrix}\theta_{0} & \theta_{1} & \theta_{2}\end{pmatrix} & \times & \begin{pmatrix}1\\
x_{1}\\
x_{2}
\end{pmatrix}\end{array}=\theta_{0}+\theta_{1}x_{1}+\theta_{2}x_{2}$$
真实值和预测值之间肯定会有误差$\varepsilon $,所以对于每一个样本:
$$y^{(i)}=\theta ^Tx^{(i)}+\varepsilon ^{(i)}\rightarrow \varepsilon ^{(i)}=|y^{(i)}-\theta ^Tx^{(i)}|$$
$\varepsilon ^{(i)}$也称为残差,由于误差服从高斯分布$P(\varepsilon ^{(i)})=\frac{1}{\sqrt{2\pi}\sigma }exp(-\frac{(\varepsilon ^i)^2}{2\sigma ^2})$
即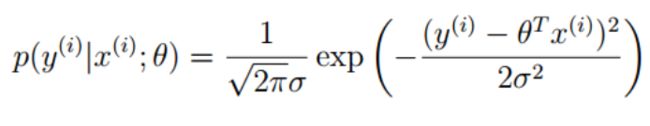
拟然函数: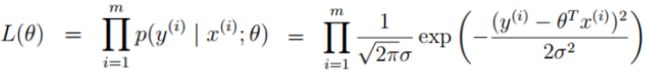
对数拟然:
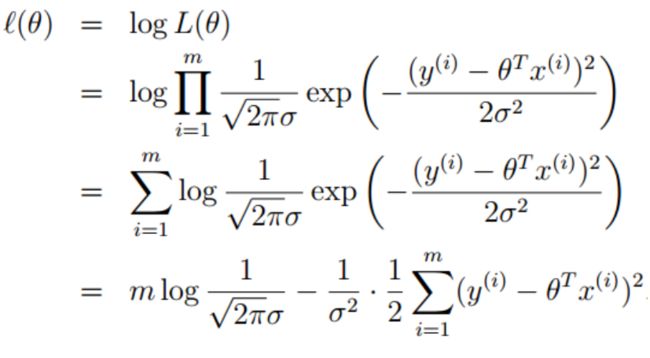
目标:让拟然函数(对数变换后的也一样)越大越好,也即最后一项的后半部分最小,同样利用最小二乘法来对w和b进行“参数估计”
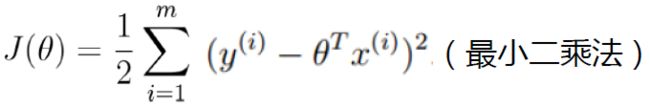

求偏导: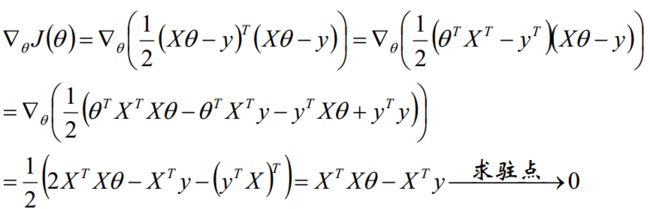
令导数等于0,求得属性们的权重$\theta $为:$$\theta =(X^TX)^{-1}X^Ty$$
我们最后求得的多元线性模型为:$$f(x_i^*)=\hat{x}_i^*(X^TX)^{-1}X^Ty$$
假如输出标记y是成指数增长的,那么我们的回归模型就应该写成:$lny=w^{T}x+b\Rightarrow y=e^{w^{T}x+b}$,这里的对数函数起到的作用是:将线性回归模型的预测值和真实标记联系起来。
还可通过线性单元的梯度下降算法求最小值。
更一般的我们考虑单调可微函数g(·),令$$y=g(·)(\theta^{T}x+b)$$,我们称之为“广义线性模型”。g(·)称之为联系函数。
对数几率回归(逻辑回归)
如果我们要用线性模型做分类任务,例如:二分类,那么输出标记就为$y\in {(0,1)}$,但线性模型$z=w^Tx+b$产生的预测值是一个确定值,我们怎么把这个预测值z转换为0/1呢,我们立马就想到了“单位阶跃函数”,但是单位阶跃函数是离散的,如下:
$$y=\left\{\begin{matrix}
0,&z<0\\1,&z>0
\end{matrix}\right.$$
即预测值z>0判别为正例,z<0判别为反例,临界值则任意的判别。所以我们找到了对数几率函数来近似单位阶跃函数,$$y=\frac{1}{1+e^{-z}}$$
对数几率函数是一种“Sigmoid函数”,将Sigmoid函数作为广义线性模型中的g(·)带进去,得到逻辑回归模型:$$h_\theta (x)=y(\theta^Tx)=\frac{1}{1+e^{-(\theta^Tx+b)}}$$
我们对上面式子进行化简:$In\frac{y}{1-y}=\theta^Tx+b$若将y视为正例的可能性,1-y则为反例的可能性,两者的比值$\frac{y}{1-y}$称为“几率”,取对数得到“对数几率”$In\frac{y}{1-y}$,所以我们是用线性回归模型的预测结果去逼近真实标记的对数几率,对应的模型称为“对数几率回归”,也有文献称之为“逻辑回归”,这是一种分类方法。
优点:
1、直接对分类可能性进行建模,无需事先假设数据分布,避免了假设分布不准确带来的问题。
2、不仅预测了“类别”,还得到了近似概率预测。
3、对数函数是任意阶可导的凸函数,有很好的新学性质。
接下来我们来求w和b,将y视为类后验概率估计p(y=1|x),则:$$In\frac{y}{1-y}=\theta^Tx+b\Rightarrow In\frac{p(y=1|x)}{p(y=0|x)}=\theta^*x+b$$
显然有:$$p(y=1|x)=h_\theta (x)=\frac{e^{\theta^Tx+b}}{1+e^{\theta^Tx+b}}$$
$$p(y=0|x)=1-h_\theta (x)=\frac{1}{1+e^{\theta^Tx+b}}$$
整合一下:$P(y|x;\theta )=(h_\theta (x))^y(1-h_\theta(x))^{1-y}$
拟然函数:$L(\theta)=\prod_{i=1}^{m}P(y_i|x_i;\theta)=\prod_{i=1}^{m}(h_\theta (x))^y(1-h_\theta(x))^{1-y_i}$
对数拟然:$l(\theta )=\log L(\theta)=\sum_{i=1}^{m}(y_i\log h_\theta (x_i)+(1-y_i)\log (1-h_\theta (x_i)))$
此时应用梯度上升求最大值,引用$J(\theta )=-\frac{1}{m}l(\theta)$转换为梯度下降任务。
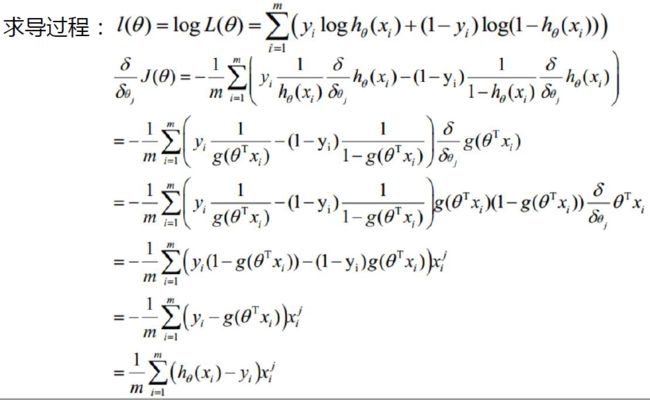
参数更新:$\theta_j=\theta_j-\alpha \frac{1}{m}\sum_{i=1}^{m}(h_\theta(x_i)-y_i)x_i^j$
线性判别分析
Linear Discriminant Analysis简称LDA,是一种线性学习方法,
思想:先给定训练样例集,设法将样例投影到一条直线上,使得同类样例的投影点尽可能的接近、异类的投影点尽可能远离;然后在对新样本进行分类时,将其投影到同样的这条直线上,再根据投影点的位置来确定新样本的类别。
目的:多分类LDA将样本投影到N-1维空间,N-1通常远小于数据原有的属性数。所以可以通过这个投影来减小样本点的维数,且投影过程使用了类别信息,因此LDA常被称为一种经典的监督降维技术。
具体算法:请参考周志华《西瓜书》
多分类学习
有些二分类问题可以直接推广到多分类,
实现:考虑N个类别$c^1,C^2....C^N$,利用拆分法,将多分类任务拆分为若干个二分类任务求解,然后为每个二分类任务训练一个分类器;在测试是对这些分类器的预测结果进行集成以获得最终的分类结果。
关键技术:“对多分类任务进行拆分”;“如何对多分类器进行集成”
拆分策略:一对一(OvO)一对其余(OvM)多对多(MvM)
具体算法:请参考周志华《西瓜书》
类别不均衡学习
当不同类别的数目差别很大时,例如:998个正例,2个反例。那么分类器只需返回一个永远将新样本预测为反例的学习器,就能达到99.8%的胜率。然而这样的分类器没有任何价值。
类别不平衡是指分类任务中不同类别的训练样例数目差别很大。
解决办法请参考周志华《西瓜书》
python实现线性回归
评估模型
用误差表示实际值与模型预测值之间的差值
衡量回归模型拟合效果的有以下几个重要指标。
平均值误差(mean absolute error):绝对误差平均值
均方误差(mean squared error):误差的平方的平均值
中位数误差(median absolute error):给定数据集中数据点的误差的中位数,可以排除异常值的干扰,测试数据集中的单个坏点不会影响到整个误差指标,均值误差指标会受到异常值的影响。
解释方差分(explained variance score):最好得分是1.0,反应模型对数据的波动的解释能力
R方得分(R2 score):最好的得分是1.0,值也可以是负数