OpenCV--使用dnn+googlenet进行目标分类(附源码)
今天我来简单说一下,基于opencv+googlenet模型进行图像分类教程
部署环境:vs2017 +opencv3.3+C+++googlenet
1、添加引用库和命名空间
添加我们所需要使用的库,和相关依赖
#include
#include//opencv2的dnn模块
#include
using namespace std;
using namespace cv;
using namespace cv::dnn; ![]()
2、指定模型文件和描述文件位置
cv::String model_gbin_file = "D:/new_cv/opencv/sources/samples/data/dnn/bvlc_googlenet.prototxt";
cv::String model_gtxt_file = "D:/new_cv/opencv/sources/samples/data/dnn/bvlc_googlenet.caffemodel";
String label_gtxt_file = "D:/new_cv/opencv/sources/samples/data/dnn/synset_words.txt";![]()
3、读取label文件内容
label文本:
//部分内容如下
n01440764 tench, Tinca tinca
n01443537 goldfish, Carassius auratus
n01484850 great white shark, white shark, man-eater, man-eating shark, Carcharodon carcharias
n01491361 tiger shark, Galeocerdo cuvieri
n01494475 hammerhead, hammerhead shark
n01496331 electric ray, crampfish, numbfish, torpedo![]()
我们的label文本主要是模型文件中可以识别的种类信息,我们用cv::String 进行存储,方法如下
vector readfromgtxt()
{
ifstream fp(label_gt_file);
vector result;
if (!fp.is_open())
{
cout << "count not open the file" << endl;
exit(-1);
}
string name;//声明字段接收每一行的值
while (!fp.eof())
{
getline(fp, name);//结果读到name中
string tmp = name.substr(name.find(" ") + 1);
result.push_back(tmp);
}
for (vector::iterator it = result.begin(); it != result.end(); it++)
{
cout << *it << endl;
}
return result;
}
4、输入待分类目标图片
接下来我们输入我们需要分类的图片,并验证可以访问
Mat src = imread("D:/test/test.jpg");
if (src.empty())
{
cout << "load image error" << endl;
return -1;
}
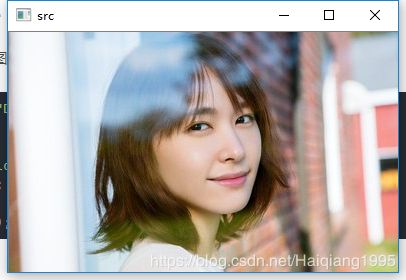
imshow("src", src);原始src:仍然用最治愈的微笑,哈哈
5、查看模型描述文件,确定图像width和height
对于定义好的caffemodel,我们在进行分类和训练的过程中,都要按模型的需要resize成目标大小,下面是样例的描述文件(bvlc_googlenet.prototxtt)的起始位置,data是我们输入的层级名称(后面会用到),
name: "GoogleNet"
input: "data"
input_dim: 10
input_dim: 3
input_dim: 224
input_dim: 224
dim:10 ——表示对待识别样本进行数据增广的数量,该值的大小可自行定义。但一般会进行5次crop,将整幅图像分为多个flip。该值为10则表示会将待识别的样本分为10部分输入到网络进行识别。如果相对整幅图像进行识别而不进行图像数据增广,则可将该值设置为1.
dim:3 ——该值表示处理的图像的通道数,若图像为RGB图像则通道数为3,设置该值为3;若图像为灰度图,通道数为1则设置该值为1.
dim:224——图像的长度,可以通过网络配置文件中的数据层中的crop_size来获取。
dim:224——图像的宽度,可以通过网络配置文件中的数据层中的crop_size来获取。我们可以看到,该模型需要输入单个3通道的300*300的图像,因此,我们在程序中指定输入固定的width和height如下
const size_t width = 224;//const表示不能被修改
const size_t height = 224;//size_t 表示vector的下标类型,一般是sizeof(*)的返回值6、初始化网络模型
常见初始化caffe网络模型接口有两种方法:
方法1)
Ptr importer;//智能指针的用法
try {
importer = dnn::createCaffeImporter(caffe_txt_file, caffe_bin_file);
}
catch (const cv::Exception &err)//Importer can throw error which we can catch
{
cerr << err.msg << endl;
}
Net net;
importer->populateNet(net);//填充网络
importer.release(); 这种方法:在opencv3.3 之前可以用,之后的版本,Importer被禁掉了,可以使用
方法2)
Net net = readNetFromCaffe(caffe_txt_file, caffe_bin_file);
7、数据载入和分类
Mat blobImg = blobFromImage(src, 1.0, Size(224, 224), Scalar(104, 103, 127));
Mat out_p;//输出1*1000 的矩阵
for (int i = 0; i < 10; i++)//一般与信息增广数量一致,用于输入不同维度下同一个图片的效果
{
net.setInput(blobImg, "data");
out_p = net.forward("prob");
// cout << out_p.at(0, 40)<<" ";
}
cout << out_p.size() << out_p.rows << " " << out_p.cols << endl;
Mat probMat = out_p.reshape(1, 1);
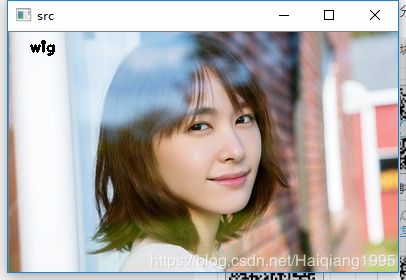
cout << probMat.size() << probMat.rows<<" "< 分类图像:
源代码:https://github.com/haiqiang2017/open-dnn