《CBAM: Convolutional Block Attention Module》论文代码解析
本文解析的是一篇ECCV2018的文章,主要内容是对CVPR2017的SENet进行改进。
1.SENet回顾
此论文是由Momenta公司所作并发于2017 CVPR,论文中的SENet赢得了ImageNet最后一届(ImageNet 2017)的图像识别冠军。论文的核心点在对CNN中的feature channel(特征通道依赖性)利用和创新。 论文的动机是从特征通道之间的关系入手,希望显式地建模特征通道之间的相互依赖关系。另外,没有引入一个新的空间维度来进行特征通道间的融合,而是采用了一种全新的“特征重标定”策略。具体来说,就是通过学习的方式来自动获取到每个特征通道的重要程度,然后依照这个重要程度去增强有用的特征并抑制对当前任务用处不大的特征。
论文的核心就是Squeeze和Excitation两个操作。
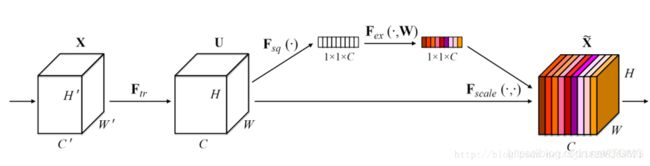
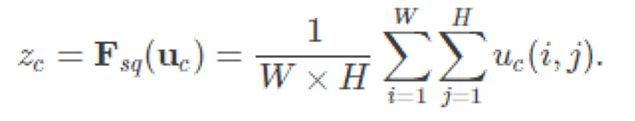
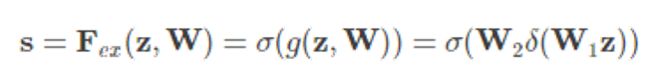

由此可以让我们考虑以下几个问题:
- SENet存在哪些不足?
- 全局平均池化是否就是最优选择?
- 除了特征通道还可以关注哪些方面?
- 有没有其他轻量级的通用模块?
让我们带着以上疑问进入到CBAM的论文中吧~
2.卷积块注意力模型CBAM
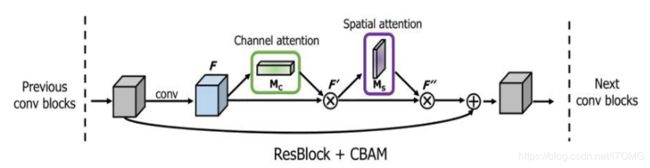
本文提出了卷积块注意模块(CBAM),这是一种用于前馈卷积神经网络的简单而有效的注意力模块。给定一个中间特征图谱,我们的模块沿着两个独立的维度(通道和空间)依次推断注意力映射,然后将权重乘以输入特征map以进行自适应特征细化。由于CBAM是一个轻量级的通用模块,它可以无缝地集成到任何CNN架构中,开销可以忽略不计,并且可以与基本CNN一起进行端到端的训练。
为了提高CNN的性能,以前的研究主要调查了网络的三个重要因素:深度,宽度和基数。
- depth:Inception、ResNet
- width:WideResNet 、GoogLeNet
- cardinality:ResNeXt 、Xception
除了这些因素,本文还研究了架构设计的一个不同方面,即注意力。注意力机制不仅要告诉重点在哪里,还要提高主要点的代表性。本文的目标是通过使用注意机制来提高有用特征的代表性:关注重要特征并抑制不必要的特征。在本文中,提出了一个新的网络模块,名为“卷积块注意模型”。由于卷积运算通过将跨通道和空间信息混合在一起来提取信息特征,采用模块来强调沿着通道和空间轴这两个主要维度提取有意义的特征。
为了实现这一点,本文依次应用通道和空间注意模块,这样每个分支都可以分别在通道和空间轴上学习“什么”和“在哪里”。因此,我们的模块通过了解要强调或抑制的信息,有效地帮助网络中的信息流动。

与SENet相比,在他们的Squeeze-and-Excitation(紧凑-激励)模块中,他们使用全局平均池化功能来计算通道的注意力。但是,我们表明这些是次优的特征,以便推断出细微的通道注意力,我们建议使用max-pooled(最大池化)功能。他们也错过了空间注意力,这在决定“聚焦在哪里”中起着重要作用。在我们的CBAM中,我们利用基于高效架构的空间和通道方面的注意,并凭经验验证两者的开发优于仅仅使用通道的注意。
3.Channel attention module
这部分的工作与SENet很相似,都是首先将feature map在spatial维度上进行压缩,得到一个一维矢量以后再进行操作。与SENet不同之处在于,对输入feature map进行spatial维度压缩时,作者不单单考虑了average pooling,额外引入max pooling作为补充,通过两个pooling函数以后总共可以得到两个一维矢量。global average pooling对feature map上的每一个像素点都有反馈,而global max pooling在进行梯度反向传播计算只有feature map中响应最大的地方有梯度的反馈,能作为GAP的一个补充。 多层感知机模型中W0和W1之间的feature需要使用ReLU作为激活函数去处理。

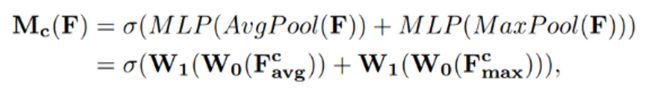
4.Spatial attention module
这部分工作是论文跟SENet区别开来的一个重要贡献,除了在channel上生成了attention模型,作者表示在spatial层面上也需要网络能明白feature map中哪些部分应该有更高的响应。首先,还是使用average pooling和max pooling对输入feature map进行压缩操作,只不过这里的压缩变成了通道层面上的压缩,对输入特征分别在通道维度上做了mean和max操作。最后得到了两个二维的feature,将其按通道维度拼接在一起得到一个通道数为2的feature map,之后使用一个包含单个卷积核的隐藏层对其进行卷积操作,要保证最后得到的feature在spatial维度上与输入的feature map一致,7x7比3x3实验后更好。
5.Experiments
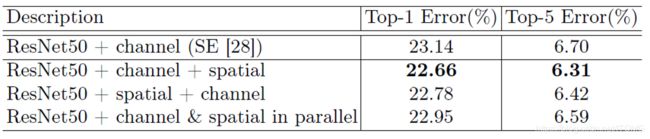
通过实验,作者发现顺序排列比并行排列能得到更好的结果。对于顺序过程的安排,实验结果表明,通道的第一顺序略好于空间第一顺序。
Grad-CAM是最近提出的可视化方法,它使用梯度来计算卷积层中空间位置的重要性。通过CAM显示对预测分类很重要的区域,目标分类的softmax分数也显示在图中。在图中,我们可以清楚地看到CBAM比其他方法更好地覆盖目标对象的区域。也就是说,CBAM很好地学习利用目标对象区域中的信息并从中聚合特征。请注意,目标分类的分数也相应增加。
6.代码解析
from keras.layers import GlobalAveragePooling2D, GlobalMaxPooling2D, Reshape, Dense, multiply, Permute, Concatenate, Conv2D, Add, Activation, Lambda
from keras import backend as K
from keras.activations import sigmoid
def cbam_block(cbam_feature, ratio=8):
"""Contains the implementation of Convolutional Block Attention Module(CBAM) block.
As described in https://arxiv.org/abs/1807.06521.
"""
cbam_feature = channel_attention(cbam_feature, ratio) #通道维度
cbam_feature = spatial_attention(cbam_feature) #空间维度
return cbam_feature
#通道维度
def channel_attention(input_feature, ratio=8):
#获取当前的维度顺序
channel_axis = 1 if K.image_data_format() == "channels_first" else -1
channel = input_feature._keras_shape[channel_axis]
#shareMLP-W0
shared_layer_one = Dense(channel//ratio,
activation='relu',
kernel_initializer='he_normal',
use_bias=True,
bias_initializer='zeros')
#shareMLP-W1
shared_layer_two = Dense(channel,
kernel_initializer='he_normal',
use_bias=True,
bias_initializer='zeros')
#经过全局平均池化
avg_pool = GlobalAveragePooling2D()(input_feature)
avg_pool = Reshape((1,1,channel))(avg_pool)
assert avg_pool._keras_shape[1:] == (1,1,channel) #[1:]分片操作,shape(1,1,1,channel)——>(1,1,channel)
#assert断言操作,如果为false抛出异常
#经过W1
avg_pool = shared_layer_one(avg_pool)
assert avg_pool._keras_shape[1:] == (1,1,channel//ratio)
#经过W2
avg_pool = shared_layer_two(avg_pool)
assert avg_pool._keras_shape[1:] == (1,1,channel)
#经过全局最大池化
max_pool = GlobalMaxPooling2D()(input_feature)
max_pool = Reshape((1,1,channel))(max_pool)
assert max_pool._keras_shape[1:] == (1,1,channel)
#经过W1
max_pool = shared_layer_one(max_pool)
assert max_pool._keras_shape[1:] == (1,1,channel//ratio)
#经过W2
max_pool = shared_layer_two(max_pool)
assert max_pool._keras_shape[1:] == (1,1,channel)
#逐元素相加,sigmoid激活
cbam_feature = Add()([avg_pool,max_pool])
cbam_feature = Activation('sigmoid')(cbam_feature)
#确定维度顺序
if K.image_data_format() == "channels_first":
cbam_feature = Permute((3, 1, 2))(cbam_feature)
#逐元素相乘,得到下一步空间操作的输入feature
return multiply([input_feature, cbam_feature])
#空间维度
def spatial_attention(input_feature):
kernel_size = 7 #卷积核7x7
if K.image_data_format() == "channels_first":
channel = input_feature._keras_shape[1]
cbam_feature = Permute((2,3,1))(input_feature) #permute实现维度的任意顺序排列(或称置换)
else:
channel = input_feature._keras_shape[-1] #取最后一个元素(channel)
cbam_feature = input_feature
#经过平均池化
avg_pool = Lambda(lambda x: K.mean(x, axis=3, keepdims=True))(cbam_feature)
#axis等于几,就理解成对那一维值进行压缩;二维矩阵(0为列1为行),x为四维矩阵(1,h,w,channel)所以axis=3,对矩阵每个元素求平均;
#keepdims保持其矩阵二维特性
assert avg_pool._keras_shape[-1] == 1 #检验channel压缩为1
#经过最大池化
max_pool = Lambda(lambda x: K.max(x, axis=3, keepdims=True))(cbam_feature)
assert max_pool._keras_shape[-1] == 1
#从channel维度进行拼接
concat = Concatenate(axis=3)([avg_pool, max_pool])
assert concat._keras_shape[-1] == 2 #检验channel为2
#进行卷积操作
cbam_feature = Conv2D(filters = 1,
kernel_size=kernel_size,
strides=1,
padding='same',
activation='sigmoid',
kernel_initializer='he_normal',
use_bias=False)(concat)
assert cbam_feature._keras_shape[-1] == 1
if K.image_data_format() == "channels_first":
cbam_feature = Permute((3, 1, 2))(cbam_feature)
#逐元素相乘,得到feature
return multiply([input_feature, cbam_feature])