4、监督学习--分类--神经网络
0、
神经网络:Neural Network
1、什么是神经网络算法?
神经网络算法中最著名的算法是1980年的反向传播(backpropagation)算法,其原理是以人脑中的神经网络为启发
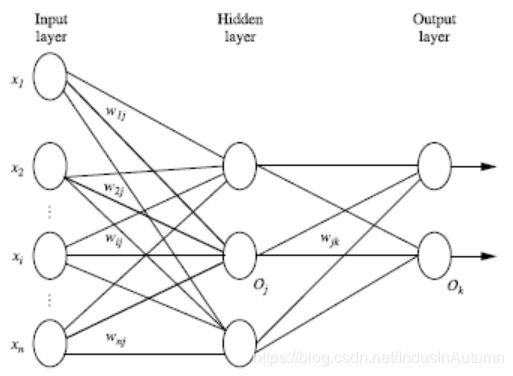
2、多层向前神经网络(Multilayer Feed-Forward Neural Network)
2.1 多层向前神经网络使用了反向传播算法,由以下部分组成:
输入层(input layer),隐藏层(hidden layers),输入层(output layers)

2.2 解析
- 每层由单元(units)组成
- 输入层是由训练集的实例特征向量传入
- 经过连接结点的权重(weight)传入下一层,一层的输出是下一层的输入
- 隐藏层的个数可以是任意的,输入层有一层,输出层有一层
- 每个单元(unit)也可以被称为神经结点,根据生物学来源定义
- 以上成为2层的神经网络(输入层不算)
- 一层中加权的求和,然后根据非线性方程转化输出
- 作为多次向前神经网络,理论上,如果有足够多的隐藏层(hidden layers)和足够大的训练集,可以模拟出任何方程
3、设计神经网络结构
3.1 使用神经网络训练数据之前,必须确定神经网络的层数,以及每层单元的个数
3.2 特征向量在被传入输入层时通常被先标准化(normalize)到0和1之间 (为了加速学习过程)
3.3 离散型变量可以被编码成每一个输入单元对应一个特征值可能赋的值
比如:特征值A可能取三个值(a0, a1, a2), 可以使用3个输入单元来代表A。
如果A=a0, 那么代表a0的单元值就取1, 其他取0;
如果A=a1, 那么代表a1de单元值就取1,其他取0,以此类推
3.4 神经网络即可以用来做分类(classification)问题,也可以解决回归(regression)问题
3.4.1 对于分类问题,如果是2类,可以用一个输出单元表示(0和1分别代表2类);如果多余2类,每一个类别用一个输出单元表示。所以输入层的单元数量通常等于类别的数量
3.4.2 没有明确的规则来设计最好有多少个隐藏层。根据实验测试和误差,以及准确度来实验并改进
4、交叉验证方法(Cross-Validation)
将数据集分为n份,每次取k份作为训练集,n-k作为测试集,迭代k次,将最终验证的结果求和除以k,就得到交叉验证的结果
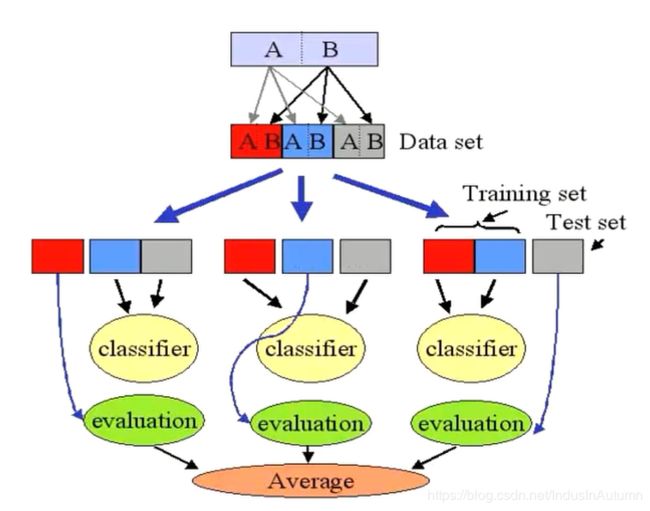
k-fold cross validation
5、反向传播算法(Backpropagation)
5.1 通过迭代性的来处理训练集中的实例
5.2 对比经过神经网络后输入层预测值(predicted value)与真实值(target value)之间
5.3 反方向(从输出层=>隐藏层=>输入层)来以最小化误差(error)来更新每个连接的权重(weight)
5.4 算法详细介绍
- 输入:D:数据集,l 学习率(learning rate), 一个多层前向神经网络
- 输出:一个训练好的神经网络(a trained neural network),即一个确定好所有权重参数的模型
5.4.1 初始化权重(weights)和偏向(bias): 随机初始化在-1到1之间,或者-0.5到0.5之间,每个单元有一个偏向
5.4.2 对于每一个训练实例X,执行以下步骤:
- 由输入层向前传送
更新过程:I_j = \sum_i w_{ij}O_i + \theta_i,I表示单元的值,w表示对应连线上的权重,O表示单元之前的值,\theta表示每一层神经网络的偏向
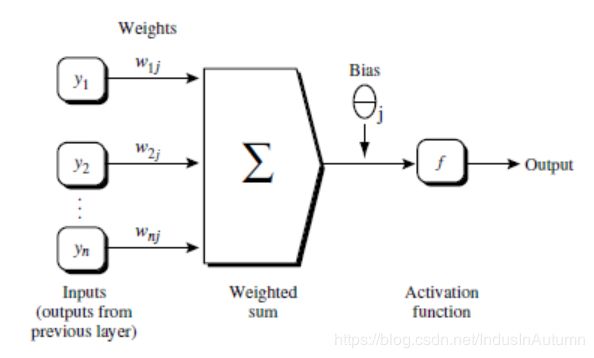
激活函数f(非线性方程):O_j = \frac{1}{1+e^{-I_j}}
- 根据误差(error)反向传送
对于输出层:Err_j = O_j(1 - O_j)(T_j - O_j),对于输出层等于该层的预测值*(1-预测值)*(真实值-预测值)
对于隐藏层:Err_j = O_j(1 - O_j)\sum_k Err_k w_{jk},对于隐藏层等于该层的预测值*(1-预测值)*前一层误差与对应权重的积的总和
权重更新:\Delta w_{ij} = (l)*Err_j O_i,l表示learn rate,为手动设置参数(表示迭代/求导步长)
w_{ij} = w_{ij} + \Delta w_{ij}
偏向更新:\Dalta \theta_j = (l)*Err_j
\theta_j = \theta_j + \Dalta \theta_j
5.4.3 终止条件
- 权重的更新低于某个阈值,表示误差接近最小值
- 预测的错误率低于某个阈值,表示预测值到达预期目标
- 达到预设一定的循环次数,表示强制终止条件
6、Backpropagation 算法举例


7、关于非线性转化方程(non-linear transformation function)
sigmoid函数(S 曲线)用来作为activation function:
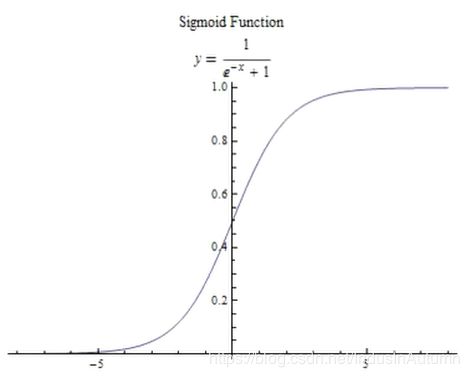
sigmoid函数的数学公式为(逻辑函数形式) y = f(x) = \frac{1}{1+e^{-x}}
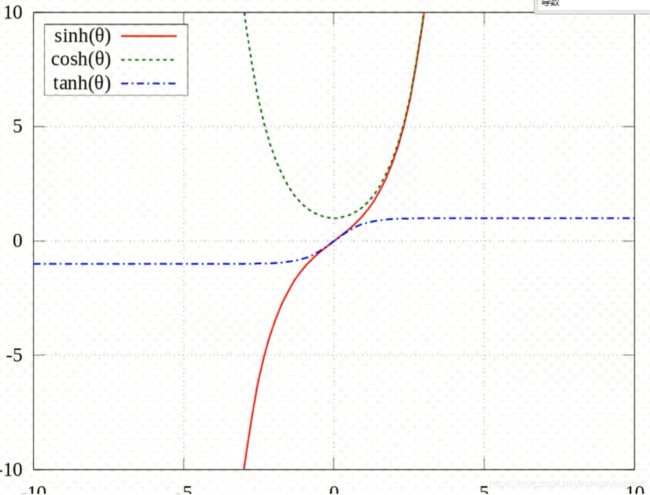
- 双曲函数(tanh):是一类与常见的三角函数类似的函数。最基本的双曲函数是双曲正弦函数sinh = \frac{e^x - e^{-x}}{2}和双曲余弦函数cosh = \frac{e^x + e^{-x}}{2};这里使用的是双曲正切函数tanh = \frac{sinh x}{cosh x} = \frac{e^x - e^{-x}}{e^x + e^{-x}};tanh x的导数为\frac{d}{dx}tanh x = 1 - tanh^2 x = sech^2 x = 1/cosh^2 x
- 逻辑函数(logistic function):f(x) = \frac{1}{1 + e^{-x}};f(x)的导数为\frac{d}{dx}f(x) = f(x)(1 - f(x))
8、实现一个简单的神经网络算法
import numpy as np
# 激活函数tanh及其导数
def tanh(x):
return np.tanh(x)
def tanh_deriv(x):
return 1.0 - np.tanh(x)*np.tanh(x)
#激活函数logistic及其导数
def logistic(x):
return 1/(1 + np.exp(-x))
def logistic_derivative(x):
return logistic(x)*(1-logistic(x))
class NeuralNetwork:
# _init_ 构造函数,self表示指向当前类的指针(相当于java中的this)
def __init__(self, layers, activation='tanh'):
"""
:param layers: A list containing the number of units in each layer.
Should be at least two values
:param activation: The activation function to be used. Can be
"logistic" or "tanh"
"""
# 选择激活函数及其导数
if activation == 'logistic':
self.activation = logistic
self.activation_deriv = logistic_derivative
elif activation == 'tanh':
self.activation = tanh
self.activation_deriv = tanh_deriv
self.weights = []
for i in range(1, len(layers) - 1): # 从第二层开始,对所有连线更新weight
self.weights.append((2*np.random.random((layers[i - 1] + 1, layers[i] + 1))-1)*0.25)
self.weights.append((2*np.random.random((layers[i] + 1, layers[i + 1]))-1)*0.25)
# X表示训练集(一般是二维矩阵,行表示实例,列表示维数/特征值数),y表示class label,epochs表示预设的循环次数
# 一般的,当训练集极大的时候,全部使用运算极慢,可以使用抽样方法,每次使用部分/一组训练集来训练
# 该函数的目的就是计算得到符合预期的神经网络上所有的weight
def fit(self, X, y, learning_rate=0.2, epochs=10000):
X = np.atleast_2d(X) # 确认X的最小维度至少是2维矩阵
temp = np.ones([X.shape[0], X.shape[1]+1]) # 初始化一个矩阵(行数:X的行数,列数:X的列数+1,多出来一列是为了给bias赋值),初始值全1
temp[:, 0:-1] = X
X = temp # adding the bias unit to the input layer
y = np.array(y) # 将y转换成numpy的格式
# 运行预设循环次数
for k in range(epochs):
# 随机抽取一行/一个实例给a
i = np.random.randint(X.shape[0])
a = [X[i]]
# 正向传播:循环神经网络层数,对于每一层:将当前层的实例与对应权重内积(np.dot),调用激活函数,然后将结果更新到a中
for l in range(len(self.weights)): #going forward network, for each layer
a.append(self.activation(np.dot(a[l], self.weights[l]))) #Computer the node value for each layer (O_i) using activation function
# 计算输出层Error
error = y[i] - a[-1] #Computer the error at the top layer # 计算输出层的误差的(T_j - O_j)
deltas = [error * self.activation_deriv(a[-1])] #For output layer, Err calculation (delta is updated error) # 计算出输出层的误差
#Staring backprobagation
# 计算隐藏层Error
# 反向传播:循环次数为从最上一层之前一层(减2,避免计算第一层(输入层)和最后一层(输出层)),到第0层,每次向前一层
for l in range(len(a) - 2, 0, -1): # we need to begin at the second to last layer
#Compute the updated error (i,e, deltas) for each node going from top layer to input layer
deltas.append(self.activation_deriv(a[l])*deltas[-1].dot(self.weights[l].T))
deltas.reverse()
# 权重更新
for i in range(len(self.weights)):
layer = np.atleast_2d(a[i])
delta = np.atleast_2d(deltas[i])
deltawij = learning_rate * layer.T.dot(delta) # \Delta w_ij = (l)*Err_jO_i
self.weights[i] = self.weights[i] + deltawij # w_ij = w_ij + \Delta w_ij
# 神经网络/模型训练好了,将新的实例走一遍正向传播的过程
def predict(self, x):
x = np.array(x)
temp = np.ones(x.shape[0]+1)
temp[0:-1] = x
a = temp
for l in range(0, len(self.weights)):
a = self.activation(np.dot(a, self.weights[l]))
return aPS:这里的.py文件要命名为NeuralNetwork.py,否则影响下面示例的使用。
9、神经网络算法的简单应用
9.1 简单非线性关系数据集测试(XOR):
X: Y
0 0 0
0 1 1
1 0 1
1 1 0
from NeuralNetwork import NeuralNetwork
import numpy as np
nn = NeuralNetwork([2,2,1], 'tanh')
X = np.array([[0, 0], [0, 1], [1, 0], [1, 1]])
y = np.array([0, 1, 1, 0])
nn.fit(X, y)
for i in [[0, 0], [0, 1], [1, 0], [1, 1]]:
print(i, nn.predict(i))
结果:
[0, 0] [0.00056865]
[0, 1] [0.9982527]
[1, 0] [0.99830321]
[1, 1] [0.000747]
因为使用的激活函数是tanh,并且该函数在0~1上是连续的,所以得到的预测结果不是直接的0和1,但是我们可以将<0.5的设置为0,>0.5的设置为1:print(i, nn.predict(i)<0.5?0:1)
9.2 手写数字识别
来识别数字:0,1,2,3,4,5,6,7,8,9
# 科学计算矩阵库
import numpy as np
# 使用sklearn.datasets自带的简单数据集(没有就现下)
# 其中使用的是load_digitsa阿拉伯数字库,其中每个数字图片都是8x8的矩阵,64个像素点,一共1797张图片
from sklearn.datasets import load_digits
# sklearn.metrics包是用于对结果进行衡量的工具,confusion_matrix和classification_report分别是绘制准确率的表和记录具体准确率的结果
from sklearn.metrics import confusion_matrix, classification_report
# sklearn不接受0和1以外的数据类型,因此需要使用LabelBinarizer来对阿拉伯数字进行处理:将每一位数字转化为一个二维的数据形式
from sklearn.preprocessing import LabelBinarizer
from NeuralNetwork import NeuralNetwork
# 使用sklearn.cross_validation(交叉验证)包中的train_test_split来对数据进行快速的拆分(训练集和测试集)
from sklearn.cross_validation import train_test_split
digits = load_digits()
# X 特征点/输入;y 标签/输出;
X = digits.data
y = digits.target
# normalize the values to bring them into the range 0-1
# 转换X的值域为[0, 1]
X -= X.min()
X /= X.max()
nn = NeuralNetwork([64,100,10], 'logistic')
X_train, X_test, y_train, y_test = train_test_split(X, y)
# 转换y的值域为[0, 1]
labels_train = LabelBinarizer().fit_transform(y_train)
labels_test = LabelBinarizer().fit_transform(y_test)
print('start fitting')
nn.fit(X_train, labels_train, epochs=3000)
predictions = []
for i in range(X_test.shape[0]):
o = nn.predict(X_test[i] )
predictions.append(np.argmax(o))
print(confusion_matrix(y_test,predictions))
print(classification_report(y_test,predictions))
结果:
[[43 0 0 0 1 1 0 0 0 0]
[0 35 0 0 0 0 1 0 3 5]
[0 2 42 3 0 0 0 0 0 0]
[0 0 0 41 0 0 0 0 1 0]
[0 0 0 0 40 0 0 0 2 0]
[0 0 0 0 0 44 0 0 0 1]
[0 0 0 0 0 0 44 0 1 0]
[0 0 0 0 1 0 0 53 0 1]
[0 1 0 2 0 2 0 0 36 0]
[0 0 0 0 0 2 0 3 0 39]]
precision recall f1-score support
0 1.00 0.96 0.98 45
1 0.92 0.80 0.85 44
2 1.00 0.89 0.94 47
3 0.89 0.98 0.93 42
4 0.95 0.95 0.95 42
5 0.90 0.98 0.94 45
6 0.98 0.98 0.98 45
7 0.95 0.96 0.95 55
8 0.84 0.88 0.86 41
9 0.85 0.89 0.87 44
avg / total 0.93 0.93 0.93 450
precision:精确率,测试图片中被预测正确的概率
recall:召回率,所有测试图片中对应数字的图片被正确预测的概率,比如所有数字为0的图片,只有96%被预测为0
f1-score:平衡F分数,是精确率和召回率的调和平均数。F1 = 2 * \frac{precision * recall}{precision + recall}
support:测试图片的数目
PS:材料学习自麦子学院,如有雷同,纯属学习
PS:注意事项,在Python2.7.5中,print推荐使用print()