Lucene从入门到使用
第一节:lucene入门阶段
1.什么是Lucene?
Lucene是一套用于全文检索和搜寻的开源程式库,由Apache软件基金会支持和提供。Lucene提供了一个简单却强大的应用程式接口,能够做全文索引和搜寻。在Java开发环境里Lucene是一个成熟的免费开源工具。就其本身而言,Lucene是当前以及最近几年最受欢迎的免费Java信息检索程序库。——《百度百科》
2.全文搜索原理
何为全文检索?举个例子,比如现在要在一个文件中查找某个字符串,最直接的想法就是从头开始检索,查到了就OK,这种对于小数据量的文件来说,很实用,但是对于大数据量的文件来说,就有点呵呵了。或者说找包含某个字符串的文件,也是这样,如果在一个拥有几十个G的硬盘中找那效率可想而知,是很低的。
文件中的数据是属于非结构化数据,也就是说它是没有什么结构可言的,要解决上面提到的效率问题,首先我们得即将非结构化数据中的一部分信息提取出来,重新组织,使其变得有一定结构,然后对此有一定结构的数据进行搜索,从而达到搜索相对较快的目的。这就叫全文搜索。即先建立索引,再对索引进行搜索的过程。
那么lucene中是如何建立索引的呢?假设现在有两个文档,内容如下:
文章1的内容为:Tom lives in Guangzhou, I live in Guangzhou too.
文章2的内容为:He once lived in Shanghai.
首先第一步是将文档传给分词组件(Tokenizer),分词组件会将文档分成一个个单词,并去除标点符号和停词。所谓的停词指的是没有特别意义的词,比如英文中的a,the,too等。经过分词后,得到词元(Token) 。如下:
文章1经过分词后的结果:[Tom] [lives] [Guangzhou] [I] [live] [Guangzhou]
文章2经过分词后的结果:[He] [lives] [Shanghai]
然后将词元传给语言处理组件(Linguistic Processor),对于英语,语言处理组件一般会将字母变为小写,将单词缩减为词根形式,如”lives”到”live”等,将单词转变为词根形式,如”drove”到”drive”等。然后得到词(Term)。如下:
文章1经过处理后的结果:[tom] [live] [guangzhou] [i] [live] [guangzhou]
文章2经过处理后的结果:[he] [live] [shanghai]
最后将得到的词传给索引组件(Indexer),索引组件经过处理,得到下面的索引结构:
| 关键词 | 文章号[出现频率] | 出现位置 |
|---|---|---|
| guangzhou | 1[2] | 3,6 |
| he | 2[1] | 1 |
| i | 1[1] | 4 |
| live | 1[2],2[1] | 2,5,2 |
| shanghai | 2[1] | 3 |
| tom | 1[1] | 1 |
以上就是lucene索引结构中最核心的部分。它的关键字是按字符顺序排列的,因此lucene可以用二元搜索算法快速定位关键词。实现时lucene将上面三列分别作为词典文件(Term Dictionary)、频率文件(frequencies)和位置文件(positions)保存。其中词典文件不仅保存有每个关键词,还保留了指向频率文件和位置文件的指针,通过指针可以找到该关键字的频率信息和位置信息。
搜索的过程是先对词典二元查找、找到该词,通过指向频率文件的指针读出所有文章号,然后返回结果,然后就可以在具体的文章中根据出现位置找到该词了。所以lucene在第一次建立索引的时候可能会比较慢,但是以后就不需要每次都建立索引了,就快了。当然了,这是针对英文的检索,针对中文的规则会有不同,后面我再看看相关资料。
3.代码案例
根据上文的分析,全文检索有两个步骤,先建立索引,再检索。所以为了测试这个过程,我写了两个java类,一个是测试建立索引的,另一个是测试检索的。首先建立个maven工程,pom.xml如下:
4.0.0
demo.lucene
demo.lucene
1.0-SNAPSHOT
org.apache.lucene
lucene-core
5.3.1
org.apache.lucene
lucene-queryparser
5.3.1
org.apache.lucene
lucene-analyzers-common
5.3.1
在写程序之前,首先得去弄一些文件,我随便找了一些英文的文档(中文的后面再研究),放到了G:\workspace\demolucene\src\main\java\data目录中,如下:
文档里面都是密密麻麻的英文,我就不截图了。
接下来开始写建立索引的java程序:
import org.apache.lucene.analysis.Analyzer;
import org.apache.lucene.analysis.standard.StandardAnalyzer;
import org.apache.lucene.document.Document;
import org.apache.lucene.document.Field;
import org.apache.lucene.document.TextField;
import org.apache.lucene.index.IndexWriter;
import org.apache.lucene.index.IndexWriterConfig;
import org.apache.lucene.store.Directory;
import org.apache.lucene.store.FSDirectory;
import java.io.File;
import java.io.FileReader;
import java.nio.file.Paths;
/**
* 建立索引的类
* Create by jenrey on 2018/7/12 13:16
*/
public class Indexer {
private IndexWriter writer; //写索引实例
//构造方法,实例化IndexWriter
public Indexer(String indexDir) throws Exception {
Directory dir = FSDirectory.open(Paths.get(indexDir));
Analyzer analyzer = new StandardAnalyzer(); //标准分词器,会自动去掉空格啊,is a the等单词
IndexWriterConfig config = new IndexWriterConfig(analyzer); //将标准分词器配到写索引的配置中
writer = new IndexWriter(dir, config); //实例化写索引对象
}
//关闭写索引
public void close() throws Exception {
writer.close();
}
//索引指定目录下的所有文件
public int indexAll(String dataDir) throws Exception {
File[] files = new File(dataDir).listFiles(); //获取该路径下的所有文件
for (File file : files) {
indexFile(file); //调用下面的indexFile方法,对每个文件进行索引
}
return writer.numDocs(); //返回索引的文件数
}
//索引指定的文件
private void indexFile(File file) throws Exception {
System.out.println("索引文件的路径:" + file.getCanonicalPath());
Document doc = getDocument(file); //获取该文件的document
writer.addDocument(doc); //调用下面的getDocument方法,将doc添加到索引中
}
//获取文档,文档里再设置每个字段,就类似于数据库中的一行记录
private Document getDocument(File file) throws Exception {
Document doc = new Document();
//添加字段
doc.add(new TextField("contents", new FileReader(file))); //添加内容
doc.add(new TextField("fileName", file.getName(), Field.Store.YES)); //添加文件名,并把这个字段存到索引文件里
doc.add(new TextField("fullPath", file.getCanonicalPath(), Field.Store.YES)); //添加文件路径
return doc;
}
public static void main(String[] args) {
String indexDir = "G:\\workspace\\demolucene\\src\\main\\java\\"; //将索引保存到的路径
String dataDir = "G:\\workspace\\demolucene\\src\\main\\java\\data\\"; //需要索引的文件数据存放的目录
Indexer indexer = null;
int indexedNum = 0;
long startTime = System.currentTimeMillis(); //记录索引开始时间
try {
indexer = new Indexer(indexDir);
indexedNum = indexer.indexAll(dataDir);
} catch (Exception e) {
e.printStackTrace();
} finally {
try {
indexer.close();
} catch (Exception e) {
e.printStackTrace();
}
}
long endTime = System.currentTimeMillis(); //记录索引结束时间
System.out.println("索引耗时" + (endTime - startTime) + "毫秒");
System.out.println("共索引了" + indexedNum + "个文件");
}
}
我是按照建立索引的过程来写的程序,在注释中已经解释的很清楚了,这里就不再赘述了。然后运行一下main方法看一下结果,如下:
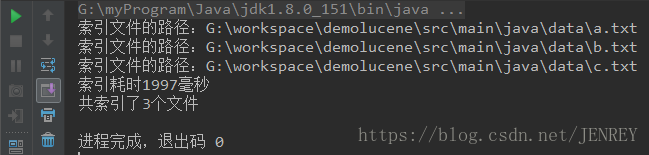
共索引了5个文件,耗时1997毫秒,还是蛮快的,而且索引文件的路径也是对的,然后可以看一下G:\workspace\demolucene\src\main\java\会生成一些文件,这些就是生成的索引。
现在有了索引了,我们可以检索想要查询的字符了,我随便打开了一个文件,在里面找了个比较丑的字符串“generate-maven-artifacts”来作为检索的对象。在检索之前先看一下检索的java代码:
import org.apache.lucene.analysis.Analyzer;
import org.apache.lucene.analysis.standard.StandardAnalyzer;
import org.apache.lucene.document.Document;
import org.apache.lucene.index.DirectoryReader;
import org.apache.lucene.index.IndexReader;
import org.apache.lucene.queryparser.classic.QueryParser;
import org.apache.lucene.search.IndexSearcher;
import org.apache.lucene.search.Query;
import org.apache.lucene.search.ScoreDoc;
import org.apache.lucene.search.TopDocs;
import org.apache.lucene.store.Directory;
import org.apache.lucene.store.FSDirectory;
import java.nio.file.Paths;
/**
* Create by jenrey on 2018/7/12 13:34
*/
public class Searcher {
public static void search(String indexDir, String q) throws Exception {
Directory dir = FSDirectory.open(Paths.get(indexDir)); //获取要查询的路径,也就是索引所在的位置
IndexReader reader = DirectoryReader.open(dir);
IndexSearcher searcher = new IndexSearcher(reader);
Analyzer analyzer = new StandardAnalyzer(); //标准分词器,会自动去掉空格啊,is a the等单词
QueryParser parser = new QueryParser("contents", analyzer); //查询解析器
Query query = parser.parse(q); //通过解析要查询的String,获取查询对象
long startTime = System.currentTimeMillis(); //记录索引开始时间
TopDocs docs = searcher.search(query, 10);//开始查询,查询前10条数据,将记录保存在docs中
long endTime = System.currentTimeMillis(); //记录索引结束时间
System.out.println("匹配" + q + "共耗时" + (endTime - startTime) + "毫秒");
System.out.println("查询到" + docs.totalHits + "条记录");
for (ScoreDoc scoreDoc : docs.scoreDocs) { //取出每条查询结果
Document doc = searcher.doc(scoreDoc.doc); //scoreDoc.doc相当于docID,根据这个docID来获取文档
System.out.println(doc.get("fullPath")); //fullPath是刚刚建立索引的时候我们定义的一个字段
}
reader.close();
}
public static void main(String[] args) {
String indexDir = "G:\\workspace\\demolucene\\src\\main\\java";
String q = "joint efforts"; //查询这个字符串
try {
search(indexDir, q);
} catch (Exception e) {
e.printStackTrace();
}
}
}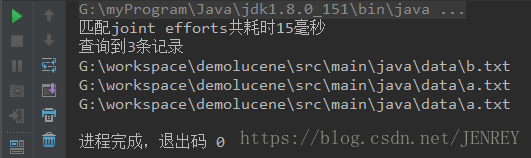
Lucene已经正确的帮我们检索到了,这也能说明Lucene中建立索引是以单词来划分的,而不是匹配检索(sadasdjoint efforts是检索不到的)
第二节:lucene全文检索引擎架构之构建索引
第一节博文中已经对全文检索有了一定的了解,这篇文章主要来总结一下全文检索的第一步:构建索引。其实上一篇博文中的示例程序已经对构建索引写了一段程序了,而且那个程序还是挺完善的。不过从知识点的完整性来考虑,我想从Lucene的添加文档、删除文档、修改文档以及文档域加权四个部分来展开对构建索引的总结,也便于我后期的查看。会重点分析一下删除文档(因为有两中方式)和文档域加权这(实际中会用到比较多)两个部分。
1.准备阶段
新建一个maven工程,pom.xml如下:
4.0.0
demo.lucene
demo.lucene
1.0-SNAPSHOT
org.apache.lucene
lucene-core
6.1.0
org.apache.lucene
lucene-queryparser
6.1.0
org.apache.lucene
lucene-analyzers-common
6.1.0
junit
junit
4.12
因为要测试的比较多,直接在工程中新建一个junit测试类IndexingTest1.java,然后在类中准备一下用来测试的数据,如下:
import org.apache.lucene.store.Directory;
/**
* Create by jenrey on 2018/7/12 14:04
*/
public class IndexingTest1 {
private Directory dir; //存放索引的位置
//准备一下用来测试的数据
private String ids[] = {"1", "2", "3"}; //用来标识文档
private String citys[] = {"shanghai", "nanjing", "qingdao"};
private String descs[] = {
"Shanghai is a bustling city.",
"Nanjing is a city of culture.",
"Qingdao is a beautiful city"
};
//等会写
//……
}这个数据就好比是数据库中存的三张表,文档标识表,城市表,城市描述表,那么每个文件中的内容实际上可以理解为包含id,城市和城市描述这样子。也就是说相当于有三个文件,每个文件中的内容描述了一个一个城市。下面开始每一部分的测试与分析了。
2.添加文档
添加文档其实就是建立索引,那么首先得获取写索引的对象,然后通过这个对象去添加文档,每个文档就是一个Lucene的Document,先来看下程序,继续在IndexingTest.java中添加:
import org.apache.lucene.analysis.Analyzer;
import org.apache.lucene.analysis.standard.StandardAnalyzer;
import org.apache.lucene.document.Document;
import org.apache.lucene.document.Field;
import org.apache.lucene.document.StringField;
import org.apache.lucene.document.TextField;
import org.apache.lucene.index.IndexWriter;
import org.apache.lucene.index.IndexWriterConfig;
import org.apache.lucene.store.Directory;
import org.apache.lucene.store.FSDirectory;
import org.junit.Test;
import java.nio.file.Paths;
/**
* Create by jenrey on 2018/7/12 14:04
*/
public class IndexingTest1 {
private Directory dir; //存放索引的位置
//准备一下用来测试的数据
private String ids[] = {"1", "2", "3"}; //用来标识文档
private String citys[] = {"shanghai", "nanjing", "qingdao"};
private String descs[] = {
"Shanghai is a bustling city.",
"Nanjing is a city of culture.",
"Qingdao is a beautiful city"
};
//生成索引
@Test
public void index() throws Exception {
IndexWriter writer = getWriter(); //获取写索引的实例
for (int i = 0; i < ids.length; i++) {
Document doc = new Document();
doc.add(new StringField("id", ids[i], Field.Store.YES));
doc.add(new StringField("city", citys[i], Field.Store.YES));
doc.add(new TextField("descs", descs[i], Field.Store.NO));
writer.addDocument(doc); //添加文档
}
writer.close(); //close了才真正写到文档中
}
//获取IndexWriter实例
private IndexWriter getWriter() throws Exception {
dir = FSDirectory.open(Paths.get("D:\\lucene2"));
Analyzer analyzer = new StandardAnalyzer(); //标准分词器,会自动去掉空格啊,is a the等单词
IndexWriterConfig config = new IndexWriterConfig(analyzer); //将标准分词器配到写索引的配置中
IndexWriter writer = new IndexWriter(dir, config); //实例化写索引对象
return writer;
}
//待会写
//……
} 可以看出,其实相当于id、城市名和城市描述是一个文档中的不同的部分,然后用这三个作为了一个Field,便于后面去查询。每个文档添加好了域之后,就添加到写索引的实例writer中写入。实际中是先获取一个文件,然后根据这个文件的信息去设定一些Field, 然后将这些Field封装到Document对象中传给写索引的实例,类似于上一篇博文中的那些代码。
然后运行一下index方法,即可在D:\lucene2\目录下看到生成的索引文件。我们也可以写一个测试方法,测试一下生成了几个文档:
public class IndexingTest1 {
//省略上面的代码
/*********** 下面来测试了 ****************/
//测试写入了几个文档
@Test
public void testIndexWriter() throws Exception {
IndexWriter writer = getWriter();
System.out.println("总共写入了" + writer.numDocs() + "个文档");
writer.close();
}
}3.读取文档
读取文档的话需要IndexReader对象,初始化的时候要传入读取文档所在的路径,也就是刚刚上面生成文档的路径D:\lucene2\,然后即可读取文档数量,测试一下:
public class IndexingTest1 {
//省略上面的代码
//测试读取文档
@Test
public void testIndexReader() throws Exception {
dir = FSDirectory.open(Paths.get("D:\\lucene2"));
IndexReader reader = DirectoryReader.open(dir);
System.out.println("最大文档数:" + reader.maxDoc());
System.out.println("实际文档数:" + reader.numDocs());
reader.close();
}
}因为从测试数据中看,只有三个文档,测试结果如下:
最大文档数:3
实际文档数:3
4.删除文档
这里我要着重说一下,删除文档有两种方式,这两种方式各有特点。一种是在合并前删除,另一种是在合并后删除,什么意思呢?合并前删除指的是并没有真正删除这个文档,只是在这个文档上做一个标记而已;而合并后删除指的是真正删掉了这个文档了。
这两个各有什么用呢?比如一个项目比较大的话,访问量也很多,那么在并发访问的情况下,频繁的删除操作会给系统的性能造成一定的影响,那么这个时候就可以用合并前删除,先不删,只是标记一下该文档属于已删除的文档,等到访问量比较小的时候(比如检测CPU比较闲的时候),我再调用删除程序统一删除标记过的文档,这样可以提升系统的性能。相反,如果数据量不大,删除操作也影响不了多大性能的话,那就直接删除好了,即使用合并后删除。下面针对这两个删除,各写一个测试程序测试一下:
public class IndexingTest1 {
//省略上面的代码
//测试删除文档,在合并前
@Test
public void testDeleteBeforeMerge() throws Exception {
IndexWriter writer = getWriter();
System.out.println("删除前有" + writer.numDocs() + "个文档");
writer.deleteDocuments(new Term("id", "1")); //删除id=1对应的文档
writer.commit(); //提交删除,并没有真正删除
System.out.println("删除后最大文档数:" + writer.maxDoc());
System.out.println("删除后实际文档数:" + writer.numDocs());
writer.close();
}
//测试删除文档,在合并后
@Test
public void testDeleteAfterMerge() throws Exception {
IndexWriter writer = getWriter();
System.out.println("删除前有" + writer.numDocs() + "个文档");
writer.deleteDocuments(new Term("id", "1")); //删除id=1对应的文档
writer.forceMergeDeletes(); //强制合并(强制删除),没有索引了
writer.commit(); //提交删除,真的删除了
System.out.println("删除后最大文档数:" + writer.maxDoc());
System.out.println("删除后实际文档数:" + writer.numDocs());
writer.close();
}
}在测试的时候要注意的是,测试完合并前删除后,要删掉索引路径中的所有索引,重新调用上面的index方法重新生成一下,再去测试合并后删除,因为之前删掉一个了,会影响后面的测试。看一下测试结果:
合并前删除:
删除前有3个文档
删除后最大文档数:3
删除后实际文档数:2
合并后删除:
删除前有3个文档
删除后最大文档数:2
删除后实际文档数:2
5.修改文档
修改文档也就是更新文档,思路是先新建一个Document对象,然后按照前面设置的字段自己再设置个新的,然后更新原来的文档,看一下测试程序:
public class IndexingTest1 {
//省略上面的代码
//测试更新
@Test
public void testUpdate() throws Exception {
IndexWriter writer = getWriter();
//新建一个Document
Document doc = new Document();
doc.add(new StringField("id", ids[1], Field.Store.YES));
doc.add(new StringField("city", "shanghai22", Field.Store.YES));
doc.add(new TextField("descs", "shanghai update", Field.Store.NO));
//将原来id为1对应的文档,用新建的文档替换
writer.updateDocument(new Term("id", "1"), doc);
writer.close();
System.out.println(doc.getField("descs"));
}
} 看一下执行结果,会打印出indexed,tokenized,从decs描述中可以看出,这个描述是我们新建的那个文档的描述,说明我们已经修改成功了。
6.文件域加权
这部分要着重说明一下,比如说我们在查询的时候,如果查询的字段在多个文档中都会存在,则会根据Lucene自己的排序规则给我们列出,但是如果我想优先看查询出来的某个文档呢?或者说我如何设定让Lucene按照自己的意愿的顺序给我列出查询出的文档呢?
这么说可能有点难以理解,举个通俗易懂的例子,有ABCD四个人都写了一篇关于java的文章,即文章标题都有java,现在我要查询有“java”这个字符串的文章,但是D是老板,我想如果查出来的文章中有老板写的,我要优先看老板的文章,也就是说要把老板的文章放在最前面,这个时候我就可以在程序中设定权重了。
要模拟这个场景,新建一个测试类IndexingTest2.java。我再造一下模拟的数据,如下:
public class IndexingTest2 {
private Directory dir; //存放索引的位置
//准备一下数据,四个人写了四篇文章,Json是boss
private String ids[]={"1","2","3","4"};
private String authors[]={"Jack","Marry","John","Json"};
private String positions[]={"accounting","technician","salesperson","boss"};
private String titles[]={"Java is a good language.","Java is a cross platform language","Java powerful","You should learn java"};
private String contents[]={
"If possible, use the same JRE major version at both index and search time.",
"When upgrading to a different JRE major version, consider re-indexing. ",
"Different JRE major versions may implement different versions of Unicode.",
"For example: with Java 1.4, `LetterTokenizer` will split around the character U+02C6."
};
}按照惯例,我们得先对这些数据生成索引,这个和上面添加文档的过程的是一样的,唯一区别的是,在生成索引的时候加了一下权重操作。如下:
public class IndexingTest2 {
//省略上面代码
@Test
public void index() throws Exception { //生成索引
dir = FSDirectory.open(Paths.get("D:\\lucene2"));
IndexWriter writer = getWriter();
for(int i = 0; i < ids.length; i++) {
Document doc = new Document();
doc.add(new StringField("id", ids[i], Field.Store.YES));
doc.add(new StringField("author", authors[i], Field.Store.YES));
doc.add(new StringField("position", positions[i], Field.Store.YES));
//这部分就是加权操作了,对title这个Field进行加权,因为等会我要查这个Field
TextField field = new TextField("title", titles[i], Field.Store.YES);
//先判断之个人对应的职位是不是boss,如果是就加权
if("boss".equals(positions[i])) {
field.setBoost(1.5f); //加权操作,默认为1,1.5表示加权了,小于1就降权了
}
doc.add(field);
doc.add(new TextField("content", contents[i], Field.Store.NO));
writer.addDocument(doc); //添加文档
}
writer.close(); //close了才真正写到文档中
}
//获取IndexWriter实例
private IndexWriter getWriter() throws Exception {
Analyzer analyzer = new StandardAnalyzer(); //标准分词器,会自动去掉空格啊,is a the等单词
IndexWriterConfig config = new IndexWriterConfig(analyzer); //将标准分词器配到写索引的配置中
IndexWriter writer = new IndexWriter(dir, config); //实例化写索引对象
return writer;
}
}从代码中看出,如果想对那个field进行加权,就直接用该field去调用setBoost()方法即可,在调用之前,根据自己设定的条件进行判断就行了。先运行一下上面的index方法生成索引,然后我们写一个测试类来测试一下:
public class IndexingTest2 {
//省略上面代码
//文档域加权测试
@Test
public void search() throws Exception {
dir = FSDirectory.open(Paths.get("D:\\lucene2"));
IndexReader reader = DirectoryReader.open(dir);
IndexSearcher search = new IndexSearcher(reader);
String searchField = "title"; //要查询的Field
String q = "java"; //要查询的字符串
Term term = new Term(searchField, q);
Query query = new TermQuery(term);
TopDocs hits = search.search(query, 10);
System.out.println("匹配" + q + "总共查询到" + hits.totalHits + "个文档");
for(ScoreDoc score : hits.scoreDocs) {
Document doc = search.doc(score.doc);
System.out.println(doc.get("author")); //打印一下查出来记录对应的作者
}
reader.close();
}
}看一下执行结果:
匹配java总共查询到4个文档
Json
John
Jack
Marry
所以Json排在了第一位,因为他是Boss!~如果没有上面的那段加权代码,那么匹配出来的顺序是Lucene中自己的一个算法,可以认为是Lucene默认的顺序,这个底层的算法我就不去研究了,但是我们可以自己根据需求自己设定一下权重,这是实际中用的比较多的。
第三节:lucene全文检索引擎架构之构建索引
上一节主要总结了一下Lucene是如何构建索引的,这一节简单总结一下Lucene中的搜索功能。主要分为几个部分,对特定项的搜索;查询表达式QueryParser的使用;指定数字范围内搜索;指定字符串开头搜索以及多条件查询。
1. 对特定项的搜索
要使用Lucene的搜索功能,首先得有索引,也就是说Lucene首先得针对特定的文件生成特定的索引,然后我们才能搜索,这在第一节里描述的很清楚,那么构建索引的例子也是使用第一节中的例子,在这就不再赘述了,然后生成了索引后,如何来搜索呢?先看第一种搜索方式:对特定项的搜索。使用的文件和建立的索引还是使用第一节的那些,生成好了索引后,就可以对特定项进行搜索了。
public class SearchTest {
private Directory dir;
private IndexReader reader;
private IndexSearcher search;
@Before
public void setUp() throws Exception {
dir = FSDirectory.open(Paths.get("D:\\lucene")); //索引的目录在D:\\lucene
reader = DirectoryReader.open(dir); //根据目录获取IndexReader
search = new IndexSearcher(reader); //根据IndexReader获取IndexSearcher
}
@After
public void tearDown() throws Exception {
reader.close(); //关闭InderxReader
}
//对特定项进行搜索
@Test
public void testTermQuery() throws Exception {
String searchField = "contents";
String q = "particular";
Term term = new Term(searchField, q);
Query query = new TermQuery(term);
TopDocs hits = search.search(query, 10);
System.out.println("匹配" + q + "总共查询到" + hits.totalHits + "个文档");
for(ScoreDoc score : hits.scoreDocs) {
Document doc = search.doc(score.doc);
System.out.println(doc.get("fullPath"));
}
}
}首先初始化IndexSearcher,在搜索的时候,要在特定的Field中对特定的字符串q进行搜索,由上面的程序可知,我要在contents字段中搜索particular这个字符串。contents是在建立索引的时候建立的,包括程序最后一行中的fullPath字段,都是在建立索引的时候创建的。有了Field和搜索字符串后,就可以生成一个搜索项Term了,然后根据这个搜索项创建一个搜索。最后就可以搜索出包含这个字符串的文件的路径。
这是针对特定项进行搜索,为什么叫针对特定项呢?因为如果我搜索particul,那么结果就为0,也就是说我必须是针对具体的一个单词,也就是说Lucene在建立索引的时候也是根据一个个单词来的,如果我只搜索单词的一部分,那么是搜不到的,所以这种针对特定项搜索其实用的不多,因为在实际中,我如果搜索particul的话,理论上应该能将particular搜出来才对。所以要用到查询表达式QueryParser。
2. 使用查询表达式QueryParser搜索
首先来看一下如何使用这个QueryParser。
@Test
public void testQueryParser() throws Exception {
Analyzer analyzer = new StandardAnalyzer(); //标准分词器,会自动去掉空格啊,is a the等单词
String searchField = "contents";
String q = "particular"; //OR AND particular~
QueryParser parser = new QueryParser(searchField, analyzer); //查询解析器
Query query = parser.parse(q); //通过解析要查询的String,获取查询对象
TopDocs docs = search.search(query, 10);//开始查询,查询前10条数据,将记录保存在docs中
System.out.println("匹配" + q + "总共查询到" + docs.totalHits + "个文档");
for(ScoreDoc scoreDoc : docs.scoreDocs) { //取出每条查询结果
Document doc = search.doc(scoreDoc.doc); //scoreDoc.doc相当于docID,根据这个docID来获取文档
System.out.println(doc.get("fullPath")); //fullPath是刚刚建立索引的时候我们定义的一个字段
}
}从程序中可以看出,初始化QueryParser需要传入一个分词器,这里使用的是标准分词器,然后跟上面一样,得指定具体的Field和要查询的字符串。这看起来好像和上面根据特定项来搜索没什么两样,其实不然,使用QueryParser的好处就在于初始化查询字符串q的时候,是有语法的,程序中只是简单的查询一个particular单词而已。
如果我将q改成”particular OR Unicode”,那么Lucene就会查询出所有包含particular或Unicode(不区分大小写)的文档,这里的OR也可以省略不写。同样的,如果我把OR改成AND,那么就是查询出所有包含particular且包含Unicode的文档。那么如果我要类似于上面提到的模糊查询呢?比如我输入particul想查出particular咋整呢?可以将q定义为“particul~”,这样就OK了。实际中用的比较多的是这个QueryParser,这一块更多的内容可以看一下官方文档。
3. 指定数字范围搜索
这个主要用于某个字段是int型的,然后可以根据这个字段来搜索,可以搜索某两个int值范围内的所有项。为了模拟这个场景,我使用上一节的例子来建立索引,因为里面有id,将其修改为Integer类型即可。然后看下如何指定数字范围内搜索。
@Test
public void testNumericRangeQuery() throws Exception {
NumericRangeQuery query = NumericRangeQuery.newIntRange("id", 1, 2, true, true);
TopDocs hits = search.search(query, 10);
System.out.println("总共查询到" + hits.totalHits + "个文档");
for (ScoreDoc score : hits.scoreDocs) {
Document doc = search.doc(score.doc);
System.out.println(doc.get("id"));
System.out.println(doc.get("city"));
System.out.println(doc.get("desc"));
}
} 首先得要创建一个NumericRangeQuery对象,初始化的时候第一个参数是字段名,第二个和第三个参数是始末数,后面两个是包含大小写,一般都设置为true,后面就跟之前的查询一样了。上面的程序可以查询到两个记录。
4. 指定字符串开头搜索
这个和上面的数字范围内搜索有点类似,只不过搜索的条件不同,初始化也不同,指定字符串开头搜索的话需要先创建一个PrefixQuery对象,将要搜索的字段和开头的字符串传进去,然后再搜索。如下搜索city中以s开头的所有项。
@Test
public void testPrefixQuery() throws Exception {
PrefixQuery query = new PrefixQuery(new Term("city", "s"));
TopDocs hits = search.search(query, 10);
System.out.println("总共查询到" + hits.totalHits + "个文档");
for (ScoreDoc score : hits.scoreDocs) {
Document doc = search.doc(score.doc);
System.out.println(doc.get("id"));
System.out.println(doc.get("city"));
System.out.println(doc.get("desc"));
}
}5. 多条件查询(组合查询)
多条件查询又称为组合查询,顾名思义,就是将多个查询条件组合到一起进行查询,这个就比较厉害了。比如我现在想组合上面两个查询,首先id为1到2之间,然后city又是s开头的,可以这么做:
@Test
public void testBooleanQuery() throws Exception {
NumericRangeQuery query1 = NumericRangeQuery.newIntRange("id", 1, 2, true, true);
PrefixQuery query2 = new PrefixQuery(new Term("city", "s"));
BooleanQuery.Builder booleanQuery = new BooleanQuery.Builder();
booleanQuery.add(query1, BooleanClause.Occur.MUST);
booleanQuery.add(query2, BooleanClause.Occur.MUST);
TopDocs hits = search.search(booleanQuery.build(), 10);
System.out.println("总共查询到" + hits.totalHits + "个文档");
for (ScoreDoc score : hits.scoreDocs) {
Document doc = search.doc(score.doc);
System.out.println(doc.get("id"));
System.out.println(doc.get("city"));
System.out.println(doc.get("desc"));
}
} 组合查询使用的是BooleanQuery,然后组合的条件还是上面的那些条件,这些条件中原来该使用什么类初始化还是使用那些类初始化,只是往BooleanQuery中加就行了。这很方便,一般查询条件多的时候,就可以采用这种组合的查询方式来查询。
第四节:lucene全文检索引擎架构之构建索引
前面总结的都是使用Lucene的标准分词器,这是针对英文的,但是中文的话就不顶用了,因为中文的语汇与英文是不同的,所以一般我们开发的时候,有中文的话肯定要使用中文分词了,这一篇博文主要介绍一下如何使用smartcn中文分词器以及对结果的高亮显示。
1. 中文分词
使用中文分词的话,首先到添加中文分词的jar包。
org.apache.lucene
lucene-analyzers-smartcn
5.3.1
然后弄一些数据,使用中文分词器来生成一下索引,以便于后面搜索用到。
public class Indexer {
private Directory dir; //存放索引的位置
//准备一下用来测试的数据
private Integer ids[] = {1, 2, 3}; //用来标识文档
private String citys[] = {"上海", "南京", "青岛"};
private String descs[] = {
"上海是个繁华的城市。",
"南京是一个有文化的城市。",
"青岛是一个美丽的城市。"
};
//生成索引
@Test
public void index(String indexDir) throws Exception {
dir = FSDirectory.open(Paths.get(indexDir));
IndexWriter writer = getWriter();
for(int i = 0; i < ids.length; i++) {
Document doc = new Document();
doc.add(new IntField("id", ids[i], Field.Store.YES));
doc.add(new StringField("city", citys[i], Field.Store.YES));
doc.add(new TextField("desc", descs[i], Field.Store.YES));
writer.addDocument(doc); //添加文档
}
writer.close(); //close了才真正写到文档中
}
//获取IndexWriter实例
private IndexWriter getWriter() throws Exception {
SmartChineseAnalyzer analyzer = new SmartChineseAnalyzer();//使用中文分词器
IndexWriterConfig config = new IndexWriterConfig(analyzer); //将标准分词器配到写索引的配置中
IndexWriter writer = new IndexWriter(dir, config); //实例化写索引对象
return writer;
}
public static void main(String[] args) throws Exception {
new Indexer().index("D:\\lucene2");
}
}建立好了索引,接下来就是查询了
public class Searcher {
public static void search(String indexDir, String q) throws Exception {
Directory dir = FSDirectory.open(Paths.get(indexDir)); //获取要查询的路径,也就是索引所在的位置
IndexReader reader = DirectoryReader.open(dir);
IndexSearcher searcher = new IndexSearcher(reader);
SmartChineseAnalyzer analyzer = new SmartChineseAnalyzer(); //使用中文分词器
QueryParser parser = new QueryParser("desc", analyzer); //查询解析器
Query query = parser.parse(q); //通过解析要查询的String,获取查询对象
long startTime = System.currentTimeMillis(); //记录索引开始时间
TopDocs docs = searcher.search(query, 10);//开始查询,查询前10条数据,将记录保存在docs中
long endTime = System.currentTimeMillis(); //记录索引结束时间
System.out.println("匹配" + q + "共耗时" + (endTime-startTime) + "毫秒");
System.out.println("查询到" + docs.totalHits + "条记录");
for(ScoreDoc scoreDoc : docs.scoreDocs) { //取出每条查询结果
Document doc = searcher.doc(scoreDoc.doc); //scoreDoc.doc相当于docID,根据这个docID来获取文档
System.out.println(doc.get("city"));
System.out.println(doc.get("desc"));
String desc = doc.get("desc");
}
reader.close();
}
public static void main(String[] args) {
String indexDir = "D:\\lucene2";
String q = "上海繁华"; //查询这个字符
try {
search(indexDir, q);
} catch (Exception e) {
e.printStackTrace();
}
}
}看一下查询结果:
匹配上海繁华共耗时15毫秒
查询到1条记录
上海
上海是个繁华的城市。
2. 高亮显示
一般查询出来的效果都要高亮显示的,例如百度里查出来的结果都会标红啥的,Lucene中也可以这么干。首先要引入高亮显示的jar包。
org.apache.lucene
lucene-highlighter
5.3.1
然后要在上面搜索的java代码中添加以下高亮显示的部分。
public class Searcher {
public static void search(String indexDir, String q) throws Exception {
//省略……
System.out.println("匹配" + q + "共耗时" + (endTime-startTime) + "毫秒");
System.out.println("查询到" + docs.totalHits + "条记录");
SimpleHTMLFormatter simpleHTMLFormatter = new SimpleHTMLFormatter("",""); //如果不指定参数的话,默认是加粗,即
QueryScorer scorer = new QueryScorer(query);//计算得分,会初始化一个查询结果最高的得分
Fragmenter fragmenter = new SimpleSpanFragmenter(scorer); //根据这个得分计算出一个片段
Highlighter highlighter = new Highlighter(simpleHTMLFormatter, scorer);
highlighter.setTextFragmenter(fragmenter); //设置一下要显示的片段
for(ScoreDoc scoreDoc : docs.scoreDocs) { //取出每条查询结果
Document doc = searcher.doc(scoreDoc.doc); //scoreDoc.doc相当于docID,根据这个docID来获取文档
System.out.println(doc.get("city"));
System.out.println(doc.get("desc"));
String desc = doc.get("desc");
//显示高亮
if(desc != null) {
TokenStream tokenStream = analyzer.tokenStream("desc", new StringReader(desc));
String summary = highlighter.getBestFragment(tokenStream, desc);
System.out.println(summary);
}
}
reader.close();
}
public static void main(String[] args) {
String indexDir = "D:\\lucene2";
String q = "上海繁华"; //查询这个字符
try {
search(indexDir, q);
} catch (Exception e) {
e.printStackTrace();
}
}
}看一下查询结果:
匹配上海繁华共耗时15毫秒
查询到1条记录
上海
上海是个繁华的城市。
上海是个繁华的城市。
这里简单解释一下上面程序中的那个得分,也就是说,在一段文本中,可能搜出来有关键字的地方不止一处,所以Lucene会自动计算每一处的得分,也就是最接近用户搜索,然后显示该位置附近的一些片段。上面的例子中描述部分太少了,就一句话,体现不出来,我把对南京的描述加长一点,如下:
南京是一个文化的城市南京,简称宁,是江苏省会,地处中国东部地区,长江下游,濒江近海。全市下辖11个区,总面积6597平方公里,2013年建成区面积752.83平方公里,常住人口818.78万,其中城镇人口659.1万人。[1-4] “江南佳丽地,金陵帝王州”,南京拥有着6000多年文明史、近2600年建城史和近500年的建都史,是中国四大古都之一,有“六朝古都”、“十朝都会”之称,是中华文明的重要发祥地,历史上曾数次庇佑华夏之正朔,长期是中国南方的政治、经济、文化中心,拥有厚重的文化底蕴和丰富的历史遗存。[5-7] 南京是国家重要的科教中心,自古以来就是一座崇文重教的城市,有“天下文枢”、“东南第一学”的美誉。截至2013年,南京有高等院校75所,其中211高校8所,仅次于北京上海;国家重点实验室25所、国家重点学科169个、两院院士83人,均居中国第三。[8-10] 。
这下够长了,如果我搜索“南京文化”,看一下结果:
南京是一个文化的城市南京,简称宁,是江苏省会,地处中国东部地区,长江下游,濒江近海。全市下辖11个区,总面积6597平方公里,2013年建成区面积752.83平方公里,常住人口818.78万,其中
如果我搜索“南京文明”,再看一下结果:
南京是一个文化的城市南京,简称宁,是江苏省会,地处中国东部地区,长江下游,濒江近海。全市下辖11个区,总面积6597平方公里,2013年建成区面积752.83平方公里,常住人口818.78万,其中
如果我搜索“南京文明”,再看一下结果:
城镇人口659.1万人。[1-4] “江南佳丽地,金陵帝王州”,南京拥有着6000多年文明史、近2600年建城史和近500年的建都史,是中国四大古都之一,有“六朝古都”、“十朝都会”之称,是中华文明的
这就是Lucene中所谓的得分,其实也就是最匹配的片段。可以看出,Lucene的中文检索也是很强大的