【学习笔记】python爬虫---代理池
背景:崔庆才的爬虫学习笔记
整体架构:

获取模块【各大网址爬取代理】----->存储模块【redis有序集合存储】<==========>检测模块
||
V
接口模块【web接口】
============================================================================================
创建代理池项目
项目结构如下:
第一:存储模块
1、存储模块,选中redis数据库中的有序集合。
------------------------------------------------------------------------------------------------------------------------
说明:1、redis有序集合:
- a、有序集合,有键值对构成的数据集合,键又叫成员member,值又叫分值score。
- b、分值必须是浮点数/整数型,并且按照分值的由低到高排序。
- c、键【member】必须唯一,分值可重复
例子:键【member】:220.12.23.62 :6666 值【score】:98
-------------------------------------------------------------------------------------------------------------------------
2、代理作为键【member】,每个代理设置对应的值【score】
a、初始值init_score设置为10
b、最大值设置为100
c、检测不通过减一分,通过设置满分,得分为0自动删除
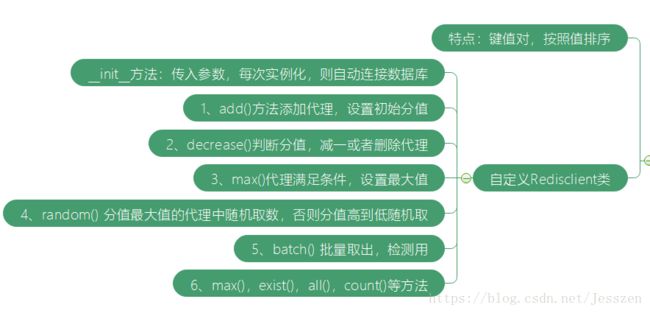
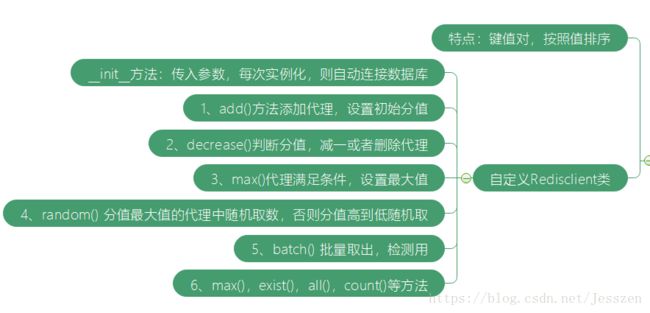
3、定义一个类RedisClient()实现如下功能
a、一旦实例化该类,自动初始化【连接数据库】,并作为该实例的一个属性
b、类实现以下方法:
4、相关代码
import redis
from proxy_pool_new.settings import REDIS_HOST,REDIS_PORT,REDIS_PASSWORD,REDIS_KEY
from proxy_pool_new.settings import MAX_SCRORE,MIN_SCORE,INITIAL_SCORE
from proxy_pool_new.error import PoolEmptyerror
from random import choice
import re
from .logger_proxy import mylogger
logger=mylogger.get_logger(name='db')
class RedisClient(object):
def __init__(self, host=REDIS_HOST, port=REDIS_PORT, password=REDIS_PASSWORD):
"""
初始化
:param host: redis 地址
:param part: redis 端口
:param password: redis 密码
decode_responses=True,写入的键值对中的value为str类型,不加这个参数写入的则为字节类型。
例子:不加,结果前多一个b, b'hello world'
"""
self.db = redis.StrictRedis(host= host, port=port, password=password, decode_responses=True)
def add(self,proxy,score=INITIAL_SCORE):#score 已经又默认值,如果不特别指定
"""
添加代理,至代理池,并设置初始分值
:param proxy: 获取的单个代理
:param intial_socore: 初始评分值
:return:
"""
if not re.match('\d+\.\d*\.\d*\.\d+\:\d*',proxy):
logger.info('不符合规范 %s' % proxy)
return
if not self.db.zscore(REDIS_KEY,proxy):
logger.info('代理添加到数据库')
#语法 zscore(key,member),key为有序集合名,member为有序集合的键名,返回值为member对应的值,若不存在,返回nil
return self.db.zadd(REDIS_KEY,score,proxy)#语法zadd(key,score,member),key有序集合名,scrore默认分值,proxy为member值
def random(self):
"""
随机获取有效代理,首先尝试获取最高分数的代理,如果不存在,则按照排名顺序获取,否则异常
:return: 随机代理
"""
result = self.db.zrangebyscore(REDIS_KEY,MAX_SCRORE,MAX_SCRORE)
#语法 zrangebyscore(key,min_score,max_score) y有序集合名,最低分,最高分、、、、返回有序集中指定分数区间内的所有的成员
if len(result):#最高非空,则len()为真,执行
return choice(result)#语法random.choice(seq),seq为一个列表,集合或者元组;返回值为seq的一个随机数。
else:
result = self.db.zrevrange(REDIS_KEY,0,100)# zvreverange(key,start,end) ,Redis Zrevrange 命令返回有序集中,指定区间内的成员。其中成员的位置按分数值递减(从大到小)来排列。
# 除此之外和ZRANGE命令一样,此处返回值数量是100个。即最高分至最低分数排序的,前101个代理
#0,100 指的是redis数据库的下标!!!
try:
if len(result):
return choice(result)
except PoolEmptyerror as e:
logger.exception(e) #记录异常
def decrease(self,proxy):
"""
代理值减一分,分数小于最小值,则对应的代理,删除
:param proxy: 代理
:return: 修改后的代理分数
"""
score = self.db.zscore(REDIS_KEY,proxy)
if score and score>MIN_SCORE:
logger.info('代理 %s 当前分数 %d 减一' %(proxy,score))
return self.db.zincrby(REDIS_KEY,proxy,-1) #为有序集合,member对应的值减1
else:
logger.info('代理 %s 当前分数 %d 移除'%(proxy,score))
return self.db.zrem(REDIS_KEY,proxy)#删除指定的键值对
def exists(self,proxy):
"""
判断是否存在
:param proxy: 代理
:return: 返回是否存在
"""
return not self.db.zscore(REDIS_KEY,proxy) == None
def max(self,proxy):
"""
将代理的分值设为最大值
:param proxy: 代理
:return: 设置最大值
"""
logger.info('代理 %s 可设置最大值 %d' %(proxy,MAX_SCRORE))
return self.db.zadd(REDIS_KEY,MAX_SCRORE,proxy)
def count(self):
return self.db.zcard(REDIS_KEY)
def all(self):
"""
获取全部有效代理
:return:
"""
return self.db.zrangebyscore(REDIS_KEY,MIN_SCORE,MAX_SCRORE)
def batch(self,start,stop):
"""
批量获取代理
:param start:
:param stop:
:return:
"""
return self.db.zrevrange(REDIS_KEY,start,stop)第二:获取模块
1、主要解决实现爬取方法的动态维护性【从另一个网址爬取代理,自动添加】
- a、涉及到先定义一个元类proxy_metaclass,增加两个属性
- b、定义一个类crawler(metaclass=proxy_metaclass),封装各爬虫方法
- c、定义一个类getter(),初始化一个Redisclient(),动态调用crawler()封装的爬虫方法,添加爬取的代理到数据库
2、定义crawler()类
from lxml import etree
import re
from .utils import get_page
from random import choice
from pyquery import PyQuery as pq
from .logger_proxy import mylogger
logger=mylogger.get_logger('crawler')
class proxy_mataclass(type):
"""
定义元类
"""
def __new__(cls, name,bases,attrs):
count=0
attrs['__crawlfunc__']=[]
for k,v in attrs.items():
if 'crawl_' in k:
attrs['__crawlfunc__'].append(k)
count +=1
attrs['__crawlcount__']=count
return type.__new__(cls,name,bases,attrs)
class crawler(object,metaclass=proxy_mataclass):
"""
metaclas取自定的元类。
第一:元类的attrs参数,收录自定义类的所有属性。
第二:我们自定义的这个proxy mataclass,的attrs属性,额外添加了两个属性,一个是’__crawlfunc__'属性,其对应的值为列表,用来存储包含crawl_字段的所有属性名称。
另一个额外的属性是"__crawlcount__",对应的值,存储了crawlfunc属性的个数。
"""
def get_crawler(self,callback):
proxies=[]
for proxy in eval('self.{}()'.format(callback)):
logger.info('成功获取代理')
proxies.append(proxy)
return proxies
def crawl_daili666(self,page_count=800):
url='http://www.66ip.cn/{}.html'
urls=[url.format(page) for page in range(page_count)]
for u in urls:
logger.info('begain crawl %s'%u)
html=get_page(u)
if html:
doc=etree.HTML(html)#解析网页地址
ip=doc.xpath('//div[@align="center"]//table//tr[position()>1]//td[1]/text()')
prot=doc.xpath('//div[@align="center"]//table//tr[position()>1]//td[2]/text()')
ip_address=list(zip(ip,prot))#元组列表
for ip,port in ip_address:
yield ':'.join([ip,port])#join的对象只能数字符型,此外join只接受一个参数,可以是列表,元组,字典,所以此处要用【】列表
def crawl_ip181(self):
start_url = 'http://www.ip181.com/'
html = get_page(start_url)
ip_address = re.compile('\s*(.*?) \s*(.*?) ')
# \s* 匹配空格,起到换行作用
re_ip_address = ip_address.findall(html)
for address,port in re_ip_address:
result = address + ':' + port
yield result.replace(' ', '') 3、定义getter()类
from .db import RedisClient
from .crawler import crawler
from .logger_proxy import mylogger
logger=mylogger.get_logger('getter')
POOL_UPPER_THRESHOLD=1000
class getter(object):
def __init__(self):
self.redis=RedisClient()
self.crawl=crawler()
def is_over_threshold(self):
if self.redis.count() >= POOL_UPPER_THRESHOLD:
return True
else:
return False
def run(self):
logger.info('获取器开始执行')
if not self.is_over_threshold():
for callback_label in range(self.crawl.__crawlcount__):
callback=self.crawl.__crawlfunc__[callback_label]
proxies=self.crawl.get_crawler(callback)#可迭代对象
for proxy in proxies:
self.redis.add(proxy)第三:检测模块
1、难点:运用异步处理,加快检测速度
2、定义一个tester()类
- a、初始化Redisclient()数据库实例
- b、定义一个协程方法def test_single_proxy:检测通过,对应代理score设置最大值,否则执行redisclient()类的decrease方法
- c、定义一个run()方法,协程加入事件循环中

3、对应代码
import asyncio
import aiohttp
from .db import RedisClient
import time
import sys
from .settings import *
from .logger_proxy import mylogger
logger=mylogger.get_logger('test')
try:
from aiohttp import ClientError
except:
from aiohttp import ClientProxyConnectionError as ProxyConnectionError
class tester(object):
def __init__(self):
self.redis=RedisClient()
async def test_single_proxy(self,proxy):
conn = aiohttp.TCPConnector(verify_ssl=False) #
async with aiohttp.ClientSession(connector=conn) as session:#aiohttp则是基于asyncio实现的HTTP框架;这里要引入一个类,aiohttp.ClientSession.
# 首先要建立一个session对象,然后用该session对象去打开网页
try:
if isinstance(proxy,bytes):
proxy=proxy.decode('utf-8')#将bytes对象解码成字符串,默认使用utf-8进行解码。防止数据库提取的proxy是bytes格式。
real_proxy = 'http://' + proxy
logger.info('正在测试代理')
async with session.get(Test_url,proxy=real_proxy,timeout=15,allow_redirects=False) as response:
if response.status in VALID_STATUS_CODES:
self.redis.max(proxy)# 将可用代理分值设为100
logger.info('proxy is enable %s' %proxy)
else:
self.redis.decrease(proxy)
logger.info('请求响应码不合适 %s %s'%(response.status,proxy))
except (ConnectionError,ClientError,TimeoutError,ArithmeticError):
self.redis.decrease(proxy)
logger.info('代理请求失败 %s'%proxy)
def run(self):
"""
测试主函数
:return:
"""
logger.info('测试器开始运行')
try:
count=self.redis.count()
logger.info('当前剩余 %d 个代理'%count)
for i in range(0,count,Batch_test_size):#所有代理,按照批次检测的个数,分段
start = i
stop=min(i+Batch_test_size,count)
logger.info('正在检测第 %s 到%s之间的代理'%(start + 1,stop))
test_proxies = self.redis.batch(start=start,stop=stop)
loop = asyncio.get_event_loop()#asyncio实现并发,就需要多个协程组成列表来完成任务【创建多个协程的列表,然后将这些协程注册到事件循环中】,
# 每当有任务阻塞的时候就await,然后其他协程继续工作,所以下面是协程列表;
# 所谓的并发:多个任务需要同时进行;
tasks=[self.test_single_proxy(proxy) for proxy in test_proxies]
loop.run_until_complete(asyncio.wait(tasks))#asyncio.wait(tasks)接受一个列表
sys.stdout.flush()
time.sleep(5)
except Exception as e:
logger.exception('测试发生错误 %s'%e)第四:web接口
1、利用Flask框架搭建一个简陋的接口

2、代码
from flask import Flask,g
from .db import RedisClient
__all__ =['app']
app = Flask(__name__)
def get_conn():
if not hasattr(g,'redis'):
g.redis=RedisClient()
return g.redis
@app.route('/')
def index():
return ' welcome to proxy pool sysytem
'
@app.route('/random')
def get_proxy():
"""
随机获取代理
:return: 随机代理
"""
conn=get_conn()
return conn.random()
@app.route('/count')
def get_count():
"""
代理池代理总数
:return:
"""
conn=get_conn()
return str(conn.count())
if __name__=='__main__':
app.run()
第五:调度模块
1、目的:定义scheduler()类。实现多进程运行以上三个模块:获取、检测、web api的方法
并且也是三个进程各有if条件判断。方便启用或者不起用

2、代码
import time
from .api import app
from .tester import tester
from .getter import getter
from multiprocessing import Process
from .logger_proxy import mylogger
from .settings import *
logger=mylogger.get_logger('scheduler')
class sheduler(object):
def sheduler_test(self,cycle=Tester_cycle):
test=tester()
while True:
logger.info('测试器开始运行')
test.run()
time.sleep(cycle)
def sheduler_get(self,cycle=Getter_cycle):
get = getter()
while True:
logger.info('开始抓取代理')
get.run()
time.sleep(cycle)
def sheduler_api(self):
app.run(host=Api_host,port=Api_port)
def run(self):
logger.info('代理池开始工作')
if Tester_enabled:
tester_process = Process(target=self.sheduler_test)
tester_process.start()
if Getter_enabled:
getter_process = Process(target=self.sheduler_get)
getter_process.start()
if Api_enabled:
api_process = Process(target=self.sheduler_api)
api_process.start()
第六:日志设置
1、利用系统自带的logger模块
2、yaml配置日志
3、因为涉及到多进程,多线程,系统自带的logging.handlers.RotatingFileHandler无法处理,安装了个第三次封装的日志处理器,实现日志保存。
4、把日志模块封装成一个类mylogger()
import logging.config
import os
import datetime
import logging.handlers
import yaml
import logging
import concurrent_log_handler
"""
class mylogger(object):
log_path = os.path.join(os.curdir,'logs')
if not os.path.exists(log_path):
os.mkdir(log_path)
log_name = datetime.datetime.now().strftime('%y-%m-%d') + '.log'
logger_conf_path =os.path.join(os.curdir,'logging.conf')
@staticmethod
def init_log_conf():
logging.config.fileConfig(mylogger.logger_conf_path)
@staticmethod
def get_logger(name=''):
mylogger.init_log_conf()
return logging.getLogger(name)
"""
log_name = datetime.datetime.now().strftime('%y-%m-%d') + '.log'
class mylogger(object):
log_path = os.path.join(os.curdir,'logs')
if not os.path.exists(log_path):
os.mkdir(log_path)
logger_conf_path =os.path.join(os.curdir,'logging.yaml')
with open(logger_conf_path,'r') as log_conf:
dict_yaml=yaml.load(log_conf)
@staticmethod
def init_log():
logging.config.dictConfig(mylogger.dict_yaml)
@staticmethod
def get_logger(name=''):
mylogger.init_log()
return logging.getLogger(name)第七:配置文档
A:setting.py设置参数
- 1、redis数据库的地址,端口,密码等
- 2、设置代理评分的最大值,最小值,初始值等
- 3、数据库连接的host,password等等
- 4、测试,调度器等等有关的配置
B:error.py设置
设置一个代理池已经枯竭的错误
class PoolEmptyerror(Exception):
def __init__(self):
Exception.__init__(self)
def __str__(self):
return repr('代理池已经枯竭')repr() 函数将对象转化为供解释器读取的形式。
返回一个对象的 string 格式