机器学习十大算法---8. 随机森林算法
在学习随机森林之前我们想你学习以下集成学习(ensemble)的内容。
随机森林简介
随机森林顾名思义,是用随机的方式建立一个森林,森林里面有很多的决策树组成,随机森林的每一棵决策树之间是没有关联的。在得到森林之后,当有一个新的输入样本进入的时候,就让森林中的每一棵决策树分别进行一下判断,看看这个样本应该属于哪一类(对于分类算法),然后看看哪一类被选择最多,就预测这个样本为那一类。
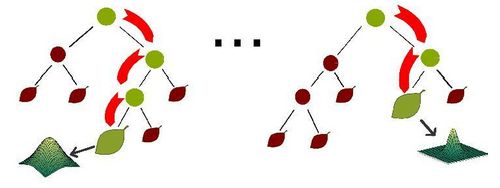
在建立每一棵决策树的过程中,有两点需要注意 - 采样与完全分裂。首先是两个随机采样的过程,random forest对输入的数据要进行行、列的采样。对于行采样,采用有放回的方式,也就是在采样得到的样本集合中,可能有重复的样本。假设输入样本为N个,那么采样的样本也为N个。这样使得在训练的时候,每一棵树的输入样本都不是全部的样本,使得相对不容易出现over-fitting。然后进行列采样,从M 个feature中,选择m个(m << M)。之后就是对采样之后的数据使用完全分裂的方式建立出决策树,这样决策树的某一个叶子节点要么是无法继续分裂的,要么里面的所有样本的都是指向的同一 个分类。一般很多的决策树算法都一个重要的步骤 - 剪枝,但是这里不这样干,由于之前的两个随机采样的过程保证了随机性,所以就算不剪枝,也不会出现over-fitting。
按这种算法得到的随机森林中的每一棵都是很弱的,但是大家组合起来就很厉害了。我觉得可以这样比喻随机森林算法:每一棵决策树就是一个精通于某一个窄领域 的专家(因为我们从M个feature中选择m让每一棵决策树进行学习),这样在随机森林中就有了很多个精通不同领域的专家,对一个新的问题(新的输入数 据),可以用不同的角度去看待它,最终由各个专家,投票得到结果。
随机森林基本原理
随机森林通过自助法(bootstrap)重采样技术,从原始训练样本集N中有放回地重复随机抽取k个样本生成新的训练样本集合,然后根据自助样本集生成k个分类树组成随机森林,新数据的分类结果按分类树投票多少形成的分数而定。其实质是对决策树算法的一种改进,将多个决策树合并在一起,每棵树的建立依赖于一个独立抽取的样品,森林中的每棵树具有相同的分布,分类误差取决于每一棵树的分类能力和它们之间的相关性。特征选择采用随机的方法去分裂每一个节点,然后比较不同情况下产生的误差。能够检测到的内在估计误差、分类能力和相关性决定选择特征的数目。单棵树的分类能力可能很小,但在随机产生大量的决策树后,一个测试样品可以通过每一棵树的分类结果经统计后选择最可能的分类。
随机森林有三个主要的超参数调整:
-
结点规模:随机森林不像决策树,每一棵树叶结点所包含的观察样本数量可能十分少。该超参数的目标是生成树的时候尽可能保持小偏差。
-
树的数量:在实践中选择数百棵树一般是比较好的选择。
-
预测器采样的数量:一般来说,如果我们一共有 D 个预测器,那么我们可以在回归任务中使用 D/3 个预测器数作为采样数,在分类任务中使用 D^(1/2) 个预测器作为抽样。
--随机森林的优点:
a. 在数据集上表现良好,两个随机性的引入,使得随机森林不容易陷入过拟合
b. 在当前的很多数据集上,相对其他算法有着很大的优势,两个随机性的引入,使得随机森林具有很好的抗噪声能力
c. 它能够处理很高维度(feature很多)的数据,并且不用做特征选择,对数据集的适应能力强:既能处理离散型数据,也能处理连续型数据,数据集无需规范化
d. 可生成一个Proximities=(pij)矩阵,用于度量样本之间的相似性: pij=aij/N, aij表示样本i和j出现在随机森林中同一个叶子结点的次数,N随机森林中树的颗数
e. 在创建随机森林的时候,对generlization error使用的是无偏估计
f. 训练速度快,可以得到变量重要性排序(两种:基于OOB误分率的增加量和基于分裂时的GINI下降量
g. 在训练过程中,能够检测到feature间的互相影响
h. 容易做成并行化方法
i. 实现比较简单
随机森林的局限性
-
当我们需要推断超出范围的独立变量或非独立变量,随机森林做得并不好,我们最好使用如 MARS 那样的算法。
-
随机森林算法在训练和预测时都比较慢。
-
如果需要区分的类别十分多,随机森林的表现并不会很好。
随机森林应用范围
随机森林主要应用于回归和分类。本文主要探讨基于随机森林的分类问题。随机森林和使用决策树作为基本分类器的(bagging)有些类似。以决策树为基本模型的bagging在每次bootstrap放回抽样之后,产生一棵决策树,抽多少样本就生成多少棵树,在生成这些树的时候没有进行更多的干预。而随机森林也是进行bootstrap抽样,但它与bagging的区别是:在生成每棵树的时候,每个节点变量都仅仅在随机选出的少数变量中产生。因此,不但样本是随机的,连每个节点变量(Features)的产生都是随机的。
许多研究表明, 组合分类器比单一分类器的分类效果好,随机森林(random forest)是一种利用多个分类树对数据进行判别与分类的方法,它在对数据进行分类的同时,还可以给出各个变量(基因)的重要性评分,评估各个变量在分类中所起的作用。
随机森林模型的注意点
设有N个样本,每个样本有M个features,决策树们其实都是随机地接受n个样本(对行随机取样)的m个feature(对列进行随机取样),每颗决策树的m个feature相同。每颗决策树其实都是对特定的数据进行学习归纳出分类方法,而随机取样可以保证有重复样本被不同决策树分类,这样就可以对不同决策树的分类能力做个评价。
随机森林实现过程
随机森林中的每一棵分类树为二叉树,其生成遵循自顶向下的递归分裂原则,即从根节点开始依次对训练集进行划分;在二叉树中,根节点包含全部训练数据, 按照节点纯度最小原则,分裂为左节点和右节点,它们分别包含训练数据的一个子集,按照同样的规则节点继续分裂,直到满足分支停止规则而停止生长。若节点n上的分类数据全部来自于同一类别,则此节点的纯度I(n)=0,
纯度度量方法是Gini准则,即假设P(Xj)是节点n上属于Xj 类样本个数占训练。
具体实现过程如下:
(1)原始训练集为N,应用bootstrap法有放回地随机抽取k个新的自助样本集,并由此构建k棵分类树,每次未被抽到的样本组成了k个袋外数据;
(2)设有mall个变量,则在每一棵树的每个节点处随机抽取mtry个变量(mtry n mall),然后在mtry中选择一个最具有分类能力的变量,变量分类的阈值通过检查每一个分类点确定;
(3)每棵树最大限度地生长, 不做任何修剪;
(4)将生成的多棵分类树组成随机森林,用随机森林分类器对新的数据进行判别与分类,分类结果按树分类器的投票多少而定。
代码练习:
from sklearn.datasets import load_iris
from sklearn.ensemble import RandomForestClassifier
import pandas as pd
import numpy as np
iris = load_iris()
df = pd.DataFrame(iris.data, columns=iris.feature_names)
df['is_train'] = np.random.uniform(0, 1, len(df)) <= .75
df['species'] = pd.Categorical(iris.target, iris.target_names)
df.head()
train, test = df[df['is_train']==True], df[df['is_train']==False]
features = df.columns[:4]
clf = RandomForestClassifier(n_jobs=2)
y, _ = pd.factorize(train['species'])
clf.fit(train[features], y)
preds = iris.target_names[clf.predict(test[features])]
pd.crosstab(test['species'], preds, rownames=['actual'], colnames=['preds'])参考资料:
随机森林案例实现:
http://www.cnblogs.com/zdz8207/p/DeepLearning-rfa-python.html
随机森林原理:
https://www.cnblogs.com/maybe2030/p/4585705.html#_label6
http://blog.csdn.net/a819825294/article/details/51177435
http://backnode.github.io/pages/2015/04/23/random-forest.html