MobileNetV2 :Inverted Residuals and Linear Bottlenecks
论文源码 | https://github.com/Randl/MobileNet2-pytorch/
摘要:
介绍了一种新的移动端架构——MobileNetV2,其在多任务和基准以及不同模型大小的范围上进一步刷新了移动端模型的当前最佳性能。介绍了如何通过全新框架 SSDLite 将这些模型高效应用于目标检测。展示了通过简化版 DeepLabv3( Mobile DeepLabv3)构建移动端的语义分割方法。
MobileNetV2 架构基于反向残差结构,其中短连接处于thin瓶颈层,这与在输入中使用扩展表征的传统残差模型正相反。MobileNetV2 使用轻量级深度卷积过滤中间扩展层的特征。此外,发现为了保持表征能力,移除短层中的非线性很重要,这提升了性能,并带来了催生该设计的直观想法。最后,我们的方法允许将输入/输出域与转换的表现性分开,从而为未来的分析提供一个简便的框架。我们在 ImageNet 分类、COCO 目标检测、VOC 图像分割上测试了 MobileNetV2 的性能,同时也评估了精度、operations 数量(通过 MAdd 测量)以及参数量之间的权衡。
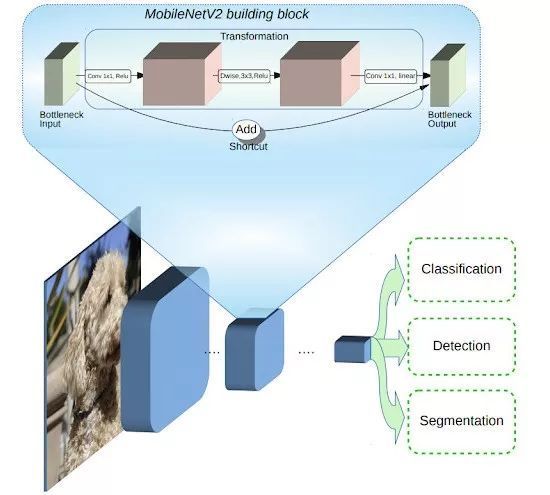
MobileNetV2的架构:蓝色模块代表深度可分离卷积层
Block 基本结构
输入:一个低维 k(通道)的、经压缩的数据
经过:
step 1, point wise卷积扩展维度(通道),扩展因子为t;
step 2, depthwise separable 卷积,stride为 s;
step 3, linear conv把特征再映射的低维,输出维度为 k’;
输出作为下一个block的输入,堆叠block。
具体结构如表:

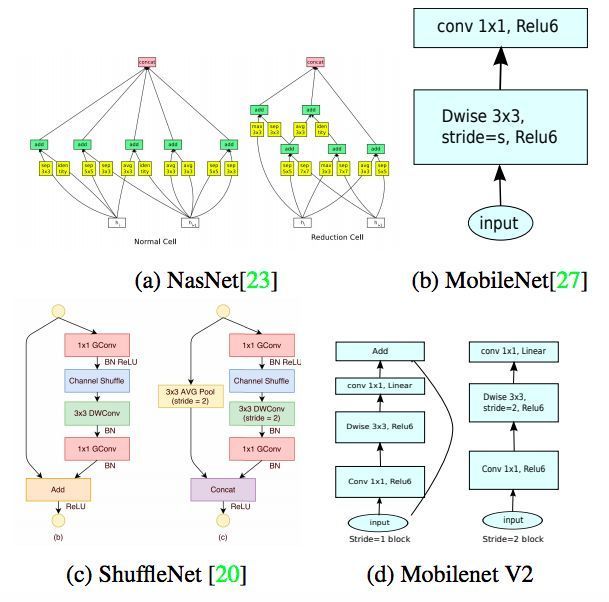
不同架构的卷积block:NasNet是谷歌使用神经网络自动搜索得到的,ShuffleNet则是去年孙剑团队提出的,基于分组逐点卷积和通道重排操作,优于谷歌MobileNet
简介
深度学习在图像分类,目标检测和图像分割等任务表现出了巨大的优越性。但是伴随着模型精度的提升是计算量,存储空间以及能耗方面的巨大开销,对于移动或车载应用都是难以接受的。之前的一些模型小型化工作是将焦点放在模型的尺寸上。
因此,在小型化方面常用的手段有:
(1)卷积核分解,使用1×N和N×1的卷积核代替N×N的卷积核;
(2)使用bottleneck结构,以SqueezeNet为代表;
(3)以低精度浮点数保存,例如Deep Compression;
(4)冗余卷积核剪枝及哈弗曼编码;
MobileNet进一步深入的研究了depthwise separable convolutions使用方法后设计出MobileNet,depthwiseseparable convolutions的本质是冗余信息更少的稀疏化表达。在此基础上给出了高效模型设计的两个选择:宽度因子(width multiplier)和分辨率因子(resolutionmultiplier);通过权衡大小、延迟时间以及精度,来构建规模更小、速度更快的MobileNet。Google团队也通过了多样性的实验证明了MobileNet作为高效基础网络的有效性。
网络结构
Deep-wise卷积
MobileNet使用了一种称之为deep-wise的卷积方式来替代原有的传统3D卷积,减少了卷积核的冗余表达。在计算量和参数数量明显下降之后,卷积网络可以应用在更多的移动端平台。

传统的3D卷积使用一个和输入数据通道数相同的卷积核在逐个通道卷积后求和最后得出一个数值作为结果,计算量为

其中M为输入的通道数,Dk为卷积核的宽和高;
一个卷积核处理输入数据时的计算量为(有Padding):
![]()
其中DF为输入的宽和高;
在某一层如果使用N个卷积核,这一个卷积层的计算量为:
![]()
如果使用deep-wise方式的卷积核,首先使用一组二维的卷积核,也就是卷积核的通道数为1,每次只处理一个输入通道的,这一组二维卷积核的数量是和输入通道数相同的。在使用逐个通道卷积处理之后,再使用3D的1*1卷积核来处理之前输出的特征图,将最终输出通道数变为一个指定的数量

图a中的卷积核就是最常见的3D卷积,替换为deep-wise方式:一个逐个通道处理的2D卷积(图b)结合3D的1*1卷积(图c)
从理论上来看,一组和输入通道数相同的2D卷积核的运算量为:
![]()
3D的1*1卷积核的计算量为:
![]()
因此这种组合方式的计算量为:

deep-wise方式的卷积相比于传统3D卷积计算量为:
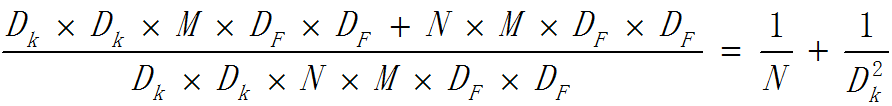
举一个具体的例子,给定输入图像的为3通道的224x224的图像,VGG16网络的第3个卷积层conv2_1输入的是尺寸为112的特征图,通道数为64,卷积核尺寸为3,卷积核个数为128,传统卷积运算量就是
![]()
如果将传统3D卷积替换为deep-wise结合1x1方式的卷积,计算量为:
![]()
可见在这一层里,MobileNet所采用卷积方式的计算量与传统卷积计算量的比例为:

网络结构
传统的3D卷积常见的使用方式如下图1左侧所示,deep-wise卷积的使用方式如下图1右边所示。
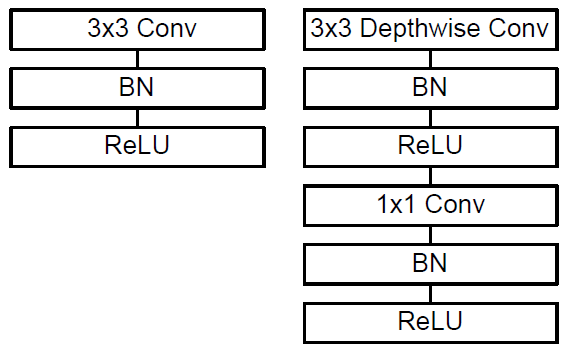
从图中可以看出,deep-wise的卷积和后面的1x1卷积被当成了两个独立的模块,都在输出结果的部分加入了Batch Normalization和非线性激活单元。Deep-wise结合1x1的卷积方式代替传统卷积不仅在理论上会更高效,而且由于大量使用1x1的卷积,可以直接使用高度优化的数学库来完成这个操作。以Caffe为例,如果要使用这些数学库,要首先使用im2col的方式来对数据进行重新排布,从而确保满足此类数学库的输入形式;但是1x1方式的卷积不需要这种预处理。
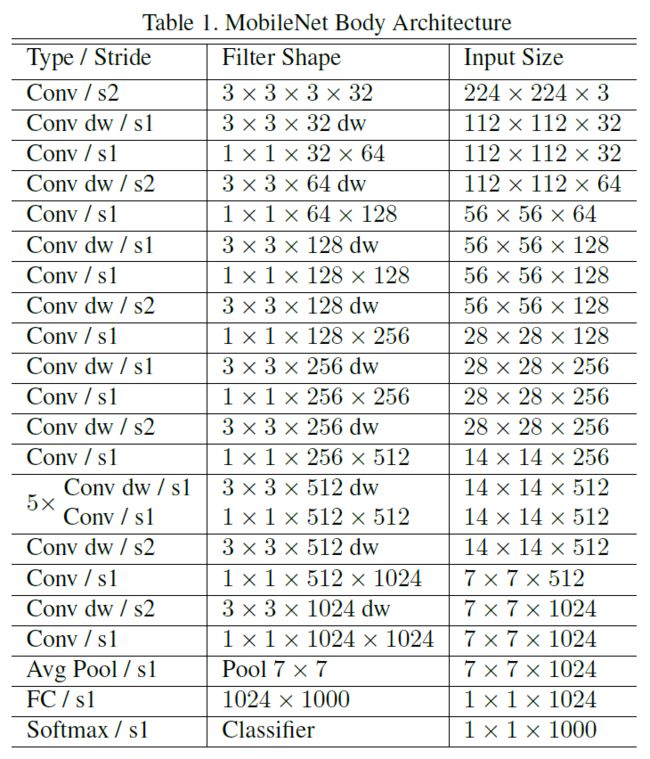
在MobileNet中,有95%的计算量和75%的参数属于1x1卷积。下图为MobileNet在ImageNet上训练时使用的网络架构(表格中含有dw的就表示这一层采用了deep-wise结合1x1的方式)
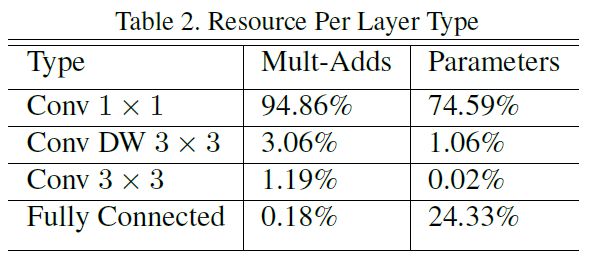
下图为MobileNet对于不同结构单元在计算量和参数数量方面的统计。
训练细节
作者基于TensorFlow训练MobileNet,使用RMSprop算法优化网络参数。考虑到较小的网络不会有严重的过拟合问题,因此没有做大量的数据增强工作。在训练过程中也没有采用训练大网络时的一些常用手段,例如:辅助损失函数,随机图像裁剪输入等。
deep-wise卷积核含有的参数较少,作者发现这部分最好使用较小的weight decay或者不使用weight decay。
宽度因子和分辨率因子
尽管标准的MobileNet在计算量和模型尺寸方面具备了很明显的优势,但是,在一些对运行速度或内存有极端要求的场合,还需要更小更快的模型,如何能够在不重新设计模型的情况下,以最小的改动就可以获得更小更快的模型呢?本文中提出的宽度因子(width multiplier)和分辨率因子(resolutionmultiplier)就是解决这些问题的配置参数。
宽度因子α是一个属于(0,1]之间的数,附加于网络的通道数。简单来说就是新网络中每一个模块要使用的卷积核数量相较于标准的MobileNet比例。对于deep-wise结合1x1方式的卷积核,计算量为:
![]()
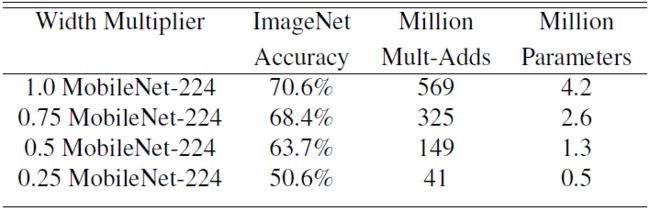
α常用的配置为1,0.75,0.5,0.25;当α等于1时就是标准的MobileNet。通过参数α可以非常有效的将计算量和参数数量约减到α的平方倍。通过下图可以看出使用α系数进行网络参数的约减时,在ImageNet上的准确率,为准确率,参数数量和计算量之间的权衡提供了参考(每一个项中最前面的数字表示α的取值)。
分辨率因子β的取值范围在(0,1]之间,是作用于每一个模块输入尺寸的约减因子,简单来说就是将输入数据以及由此在每一个模块产生的特征图都变小了,结合宽度因子α,deep-wise结合1x1方式的卷积核计算量为:
![]()
下图为使用不同的β系数作用于标准MobileNet时,对精度和计算量以的影响(α固定)

要注意在使用宽度和分辨率参数调整网络结构之后,都要从随机初始化重新训练才能得到新网络。
实验
为了验证MobileNet作为基础网络的有效性,Google团队使用MobileNet在不同的视觉识别任务上组为基础网络都表现出了优异的性能。
任务1:基础网络
MobileNet极大地降低了网络参数数量和计算量,但是相比起经典的基础网络,其精度并未明显的降低,如下图所示,与VGG相比,在ImageNet分类任务上的精度差距较小

如下图所示,与经典的小型网络SqueezeNet相比,在精度和计算量方面都有明显提升

任务2:精细分类
在 Stanford Dogs 数据集上训练MobileNet 进行精细分类。结果下图所示,MobileNet 在大大减少计算量和减小模型大小的情况下分类精度接近于InceptionV3。
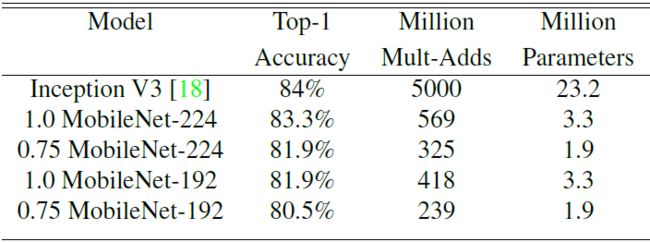
任务3:大规模地理定位
PlaNet 用于分辨一张照片拍摄于哪个地理位置的分类问题任务。基本思想是将地球划分为成网格,用数量巨大的有地理标记的照片训练网络。PlaNet 可以较为准确的将各种各样的照片标记地理位置,代表了这个领域的顶级水平。使用 MobileNet 作为基础网络在相同的数据上重新训练 PlaNet。如下图所示,MobileNet作为基础网络的PlaNet与经典 PlaNet 相比,规模小了很多,性能稍有降低,但比 Im2GPS 各方面更佳。
任务4:人脸属性提取
MobileNet 的一个使用情景是压缩具有未知或复杂训练程序的大型系统。在人脸属性分类任务中,本文证明了 MobileNet 与 distillation间的协同关系,这是网络的一种知识迁移技术。本文在 YFCC100M 多属性数据集上训练。
使用 MobileNet 架构提取一个人脸属性分类器。distillation是通过训练分类器模拟一个更大的模型的输出,而非人工标注标签工作,因此能够从大型(可能是无限大)未标记数据集训练。结合 distillation 的可扩展性和MobileNet 的简约参数化,相比于一个具有7500万超参数和16亿 Mult-Adds 的大型人脸属性分类器,终端系统不仅不需要正则化,而且表现出更好的性能。结果如下图所示

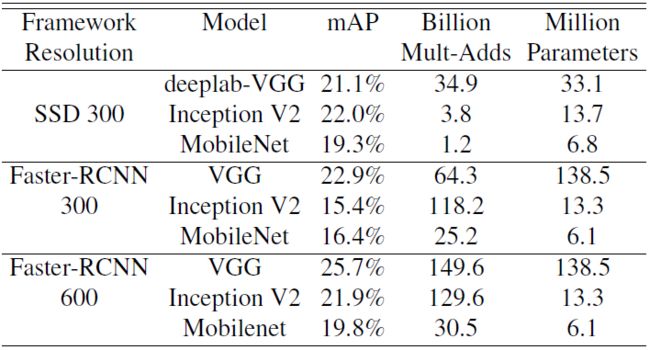
任务5:目标检测
MobileNet 可以作为一个有效的基础网络部署在目标检测系统上。基于2016 COCO 数据集,比较了在 COCO 数据上训练的 MobileNet 进行目标检测的结果。下图列出了在 Faster-RCNN 和 SSD 框架下,MobileNet,VGG 以及 Inception V2 作为基础网络的对比结果。在不同而检测框架和输入尺寸设定下,以MobileNet为基础网络的检测框架表现出了不明显逊色于两个基础网络的性能,而且在计算量和模型尺寸方面有较大优势。
任务6:人脸识别
FaceNet 模型是目前顶级水平的人脸识别模型,它基于 triplet loss 构建faceEmbedding。为了能够在移动设备上运行 FaceNet 模型,使用 distillation来最小化训练数据上 FaceNet和 MobileNet 输出的方差。下图列出了输入尺寸较小的MobileNet在此任务上的性能表现,可以看出主要还是在没有过分损失精度的情况下,运算量大大减少。

总结
MobileNet在计算量,存储空间和准确率方面取得了非常不错的平衡。与VGG16相比,在很小的精度损失情况下,将运算量减小了30倍。通过实验结果,我们认为MobileNet的设计思想会在自动驾驶汽车,机器人和无人机等对实时性、存储空间、能耗有严格要求的终端智能应用中发挥显著作用。
补充知识
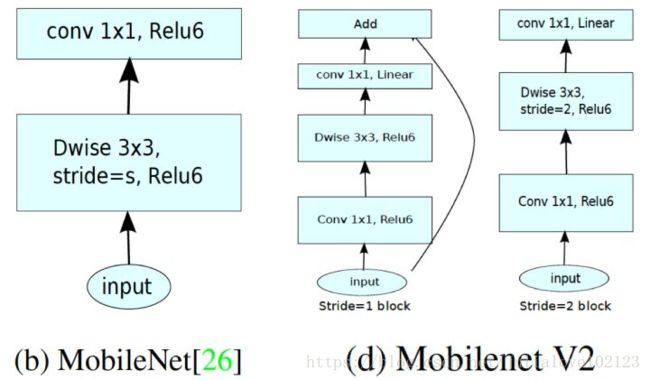
1. MobileNet v1 与 v2 微结构的区别
可以看到有两个区别。 2. MobileNet v2 与 ResNet 微结构的区别
可以看到基本结构很相似。不过ResNet是先降维(0.25倍)、提特征、再升维。而v2则是先升维(6倍)、提特征、再降维。另外v2也用DW代替了标准卷积来做特征提取。 链接:https://www.zhihu.com/question/265709710/answer/297996096 来源:知乎 著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。 |
知乎讨论:
https://www.zhihu.com/question/265709710
一个很不错的博客总结:
https://blog.ddlee.cn/posts/c9816b0a/