NLP中的词向量总结与实战:从one-hot到bert
写在前面
之前写的关于NLP基础词向量的笔记,这次更新一下。从最简单的one-hot到目前效果惊人的BERT进行整理对比,加深对基础的理解。词向量的表示方法由低级至高级可以分为以下几个部分:
- Bag of Words模型:one-hot, tfidf等离散表示
- 主题模型表示:LDA这一类
- 固定词向量模型:Word2vec,glove, fasttext
- 动态词向量模型(预训练方式):elmo、gpt、bert
一、离散表示
One-hot独热表示法
- NLP 中最常用、最传统的词特征表示方式是采用One-Hot 编码,即每一个词特征都被表示成一个很长的向量,其长度等于词表大小,当前词对应位置为1,其他位置为0。
- 但是这种表示方式存在显而易见的问题:
- 不同词之间总是正交的,无法衡量不同词之间的相似关系。
- 只能反映每个词是否出现,但无法突出词之间重要性的区别。
BOW词袋表示法
- 在One-Hot 表示法的基础上,对词表中的每一个词在该文本出现的频次进行记录,以表示当前词在该文本的重要程度。
- 但这种表示方式只能表达词在当前文本中的重要程度。很多停用词由于频次较高,权重很大。可用TF-IDF进行优化
- 存在的问题:
- 词之间是独立的,无法提供词序信息和上下文信息。
- 数据十分稀疏。
二、基于SVD
这是一种构造词嵌入的方法,首先遍历所有的文本数据,然后统计词出现的次数保存在矩阵X中,然后对X应用奇异值分解: X = U S V T X=U S V^{T} X=USVT。然后将U矩阵的行向量作为所有词表中词的词向量。对于矩阵X,有两种选择方式:
词-文档矩阵
这种情况下矩阵X中的每一个元素X[i][j]表示第i个词出现在第j个文本中的次数。最终得到一个庞大的 R ∣ V ∣ × M \mathbb{R}^{|V| \times M} R∣V∣×M矩阵,该方案显然不理想。
基于窗口的共现矩阵
这个方法不再考虑文档的数量,统计两个词在给定窗口中的共现次数。以CS224N课程中例子来说,对于下面三个句子:
- I enjoy flying.
- I like NLP.
- I like deep learning.
共现矩阵为:
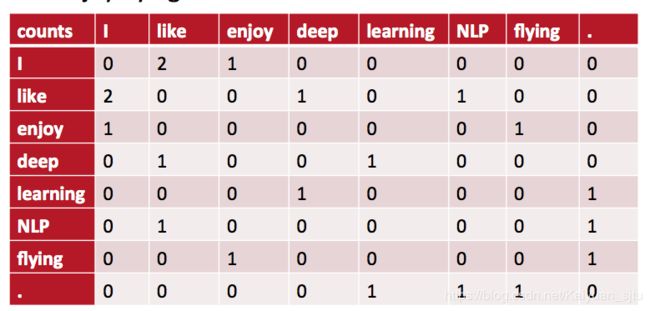
可以发现上述矩阵存在非常明显的高纬度和高稀疏性问题。于是首先想到的就是降维。
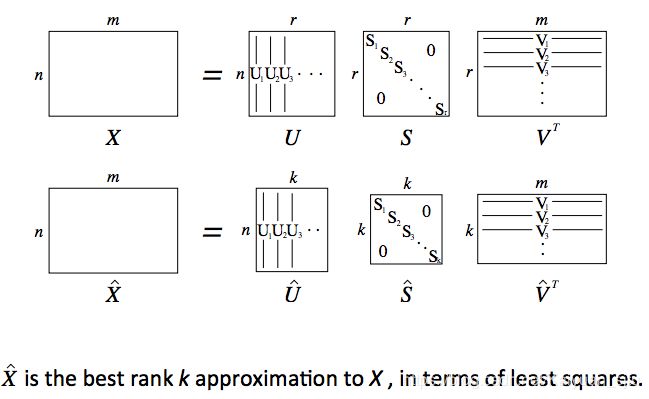
Python中简单的词向量SVD分解
三、固定词向量模型
3.1 NNLM
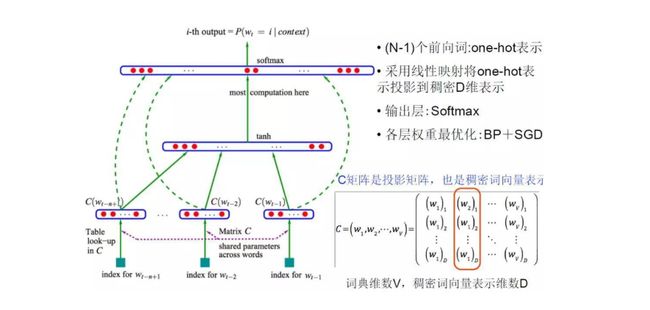
Distributed representation 被称为“Word Representation”或“Word Embedding”, 中文也叫“词向量”或“词嵌入”。首先引入词向量概念的是2003年Bengio等人用三层的神经网络构建了统计语言模型的框架,该框架的主要目标是训练语言模型,词向量只是它的副产品。模型的网络结构如下:
3.2 Word2vec
- 2013年Google 开源了一款直接计算低维词向量的工具 ——Word2Vec,不仅能够在百万级的词典亿级数据集上高效训练,而且能够很好的度量词与词之间的相似性。
- 对原始NNLM的改进:
- 移除前向反馈神经网络中的非线性hidden layer,直接将中间层的embedding layer 与 softmax layer 连接。
- 输入所有词向量到一个embedding layer 中 。
- 将特征词嵌入上下文环境
- 后续还在训练方法上进行了优化:层次softmax以及负采样技术
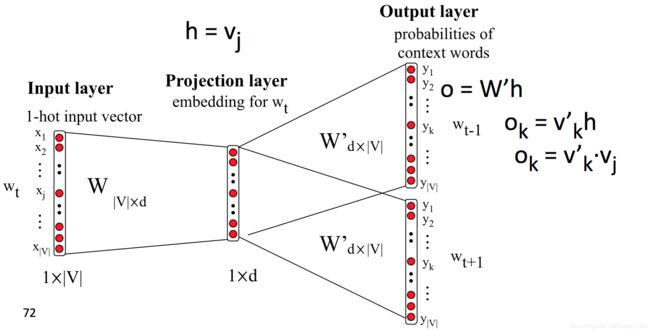
word2vec主要有两种训练方式:Continuous Bag of Words Model(CB)和Skip-Gram
有两种优化方式:hierarchical softmax 和negative sampling
所以说Word2vec一共可以有四种模型。
这里只做简略说明,具体推导可参考word2vec中的数学原理详解
CBOW模型:
- 损失函数:
L = ∑ w ∈ C log p ( w ∣ Context ( w ) ) \mathcal{L}=\sum_{w \in \mathcal{C}} \log p(w | \text {Context}(w)) L=w∈C∑logp(w∣Context(w))
- 模型框架
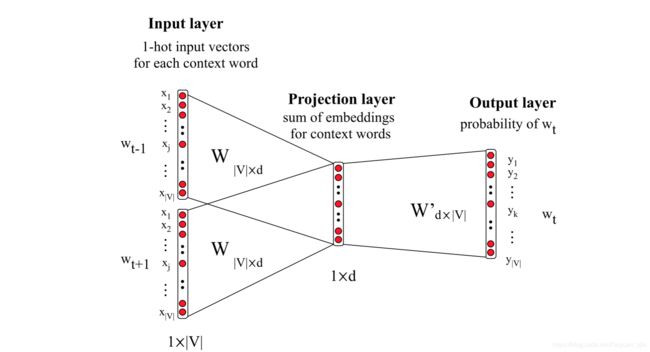
Skip-gram模型
- 损失函数:
L = ∑ w ∈ C log p ( Context ( w ) ∣ w ) \mathcal{L}=\sum_{w \in \mathcal{C}} \log p(\text {Context}(w) | w) L=w∈C∑logp(Context(w)∣w)
- 模型框架:
用gensim学习word2vec
对于word2vec来说,模型分为CBOW和SG两种,训练方法有Negative Sampling和Hierarchical Softmax两类,总的一共有四种解法。最方便的是选用开源库gensim来使用。
- 如果需要自己训练word2vec模型,伪代码如下
import gensim
text = 'your/path/to/training.txt'
model = gensim.models.Word2Vec(min_count=2)
model.build_vocab(text)
model.train(text, total_examples=model.corpus_count, epochs=model.iter)
- 如果直接调用以及训练好的模型
model = gensim.models.Word2Vec.load('your/path/to/model')
- 获取词向量
>>> model['computer'] # raw NumPy vector of a word
array([-0.00449447, -0.00310097, 0.02421786, ...], dtype=float32)
>>> model.wv['word']
- 获取词表
model.wv.vocab.keys()
- 求词与词之间的相似度
y2=model.similarity(u"好", u"还行") # 比较两个词的相似
print(y2)
for i in model.most_similar(u"滋润"): # 一个词相似词有哪些
print i[0],i[1]
更具体可以参考:【不可思议的Word2Vec】 2.训练好的模型
3.3 Glove
Glove认为Word2vec词向量的视野只有中心词周围的部分词语,缺少全局词语的信息;另外,w2v缺乏对高频词的处理。
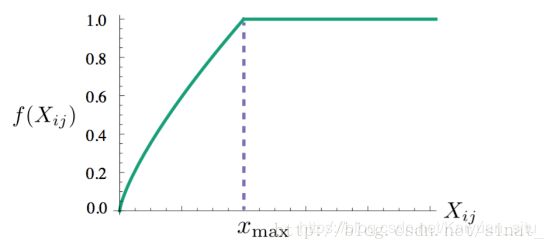
glove的思路是将全局词-词共现矩阵进行分解,训练得到词向量。目标函数为: J = ∑ i , j = 1 V f ( X i j ) ( w i T w ~ j + b i + b ~ j − log X i j ) 2 J =\sum_{i, j=1}^{V} f\left(X_{i j}\right)\left(w_{i}^{T} \tilde{w}_{j}+b_{i}+\tilde{b}_{j}-\log X_{i j}\right)^{2} J=i,j=1∑Vf(Xij)(wiTw~j+bi+b~j−logXij)2
其中 X i j X_{ij} Xij表示单词j出现在单词 i i i上下文中的次数, f ( x ) f(x) f(x)表达式为: f ( x ) = { ( x / x max ) α if x < x max 1 otherwise f(x)=\left\{\begin{array}{cl}{\left(x / x_{\max }\right)^{\alpha}} & {\text { if } x<x_{\max }} \\ {1} & {\text { otherwise }}\end{array}\right. f(x)={(x/xmax)α1 if x<xmax otherwise
glove实战
比较好的开源库有:maciejkula/glove-python
使用方式与gensim类似,具体可以参考:极简使用︱Glove-python词向量训练与使用
3.4 Fasttext
fasttext模型框架类似于CBOW但是也有区别:
- 输入:word2vec用的是上下文单词的one-hot编码;fasttext用的是一个sentence的单词向量同时包括subword, 字符级别n-gran向量
- 中间层:word2vec使用的是求和;fasttext使用的是平均;
- 输出:cbow输出目标词汇;fasttext输出文本分类标签
- 与以上两者相比,速度快,使用层次softmax,使用subword对oov友好
关于FastText的原理参考:【论文复现】使用fastText进行文本分类
四、动态词向量模型
虽然前面介绍的几款词向量生成模型可以很有效地应用于各种任务,但是由于其词向量的固定表示导致面对一词多义问题没有很好的效果。于是就出现了一下几款更高级的预训练词向量。
NLP大杀器BERT模型解读里对elmo、gpt、bert等进行了较为high-level的介绍。
建议一定要看原始论文然后对着源码去读!!
以上~