大白话5分钟带你走进人工智能-第十七节逻辑回归之交叉熵损失函数概念(2)
第十七节逻辑回归之交叉熵损失函数概念(2)
上一节中我们讲解了逻辑回归是做分类的原因,本节的话我们讲解逻辑回归的损失函数-交叉熵损失函数。逻辑回归,是要做分类的,最重要的是要去分界,这个逻辑回归它是怎么找分界?首先它有回归两个字,我们可以转成另外两个字,拟合。所以逻辑回归找分界,它首先干的事情是拟合原有的数据,然后再来找分界,怎么找?
如果知道已知的数据点,用曲线来进行拟合,之后找到某一个位置可以对原有的0和1类别,两类数据进行一个很好的分开。当然线性回归也可以来分类,通过回归找到一个分界点X,小于分界点的X属于某个类别,大于分界点的X属于另一个类别。为什么分类一定要找这个点?因为做分类的目标是要训练出一个模型,然后根据这个模型,我们把未来新的数据xnew带进来,它可以给我们一个预算结果ŷ,一个分类号,对于二分类来说,它必须得给一个0类别号或者1类别号。所以要根据分界点把每个数据区分开。我们怎么找到一个很好的分界点?因为y= θ^T*X,它的结果是负无穷到正无穷之间,因此Y=0零是比较合适的一个分界点。假如我们让y= θ^T*X的负无穷到正无穷之间的值缩放到0到1之间,让每个值都具有一个概率的含义,越接近零就说这件事情发生的概率越低越小,越接近1就说明这件事情发生的概率就越大。这时候再找一个分界点区分开之前的数据,可以自然而然的想到 是0.5,0.5是50%,就是说它属于负例的概率是50%,它属于正例的概率也是50%。所以我们就可以找0到1之间的0.5来作为分界点。 实际上这就是逻辑回归的设想。
逻辑回归它给出这样一个缩放的函数,满足最后缩放的区间是0到1之间,并且在我们原本y= θ^T*X的这个位置,满足缩放后的位置刚好是对应0.5才合适。所以sigmoid函数,本身是一个S曲线的意思,S型的曲线有无穷无尽种,你可以找很多S曲线,这里选用的S曲线特点是:
![]()
你会发现,如果θ^T*X=0的话,f(x)的值刚好等于1/(1+1)=1/2=0.5。所以对f(x)来说就以0.5作为一个分界。也就是说如果我们要去做分类的话,所计算出来的θ^T*X>0是正例,θ^T*X<0是负例。带到sigmoid函数里面去,f(x)就是y轴,算出的y轴,所对应的值就是大于0.5是正例,小于0.5是负例。因此我们的目标是找到y是0.5的情况下所对应的x是多少,这样我们就可以用x或者用缩放完之后的y=0.5来作为分界点,对未来数据进行分类,一个是X轴上的维度,一个是y轴上的维度。
我们再结合图形来看下对应的函数:

S曲线实际上是y=1/(1+e-θTx),x,y,e,1都是已知的,唯独只有θ需要去计算,所以算出来的θ参数就是我们的模型,所以这个模型就是去找一组θ,使得θ^T*X缩放之后对应的S曲线尽可能通过我们已有的所有的点。尽可能是人类语言的描述,我们就要把尽可能的给它变成公式,变成数字的表达,然后让计算机去算,让它尽可能的误差最小的时候。
总结下我们的目标就是:构造一个函数更好地解决二分类问题,并且使得这个函数输出一个 (0,1) 的实数代表概率。通过上面的结论,我们知道这个函数比较好的是sigmoid函数,即:
![]()
这里面的Z=w^T*X。如果我们把w^Tx看成一个整体Z ,f(x)就是关于Z的函数,我们定义为g(z),它给出的结果是0到1之间的一个值,我们说如果它小于0.5代表负例,如果大于0.5,它代表正例。即 g(z) <0.5 时, 判断y=0。g(z)>=0.5时, 判断y=1。比如某条数据带到这个公式里,然后它给出一个ŷ值,这条ŷ数据具体值含义是,它是1类别的概率有多大。比如最后算出来的值是0.85,0.85是大于0.5,那就意味着这条数据它是1这个类别是正例的概率是85%。如果另外一个x new传进来得到的结果是0.05,首先0.05小于0.5,所以肯定给它分到0这个类别,它就意味着它是1这个类别的概率是0.05,相反它是0类别的概率就是1-0.05,就是0.95。所以实际上得出的ŷ值它代表是该条数据是1这个位置的概率是多少,这是它的实质。
我们再来解剖下z的图像的含义:g(z) = 0.5 时 ,W^T*X = 0 在二维平面下是一条直线。如果是一维的情况下,只有一个轴,找到一个点将数据分开,如果有两个维度,x1,x2,对应一个平面,我们要找到一条直线把它分开。比如下图:

红色和绿色是已知的数据点,是不同的类别,当wTx=0的话,就意味着w1*x1+w2*x2+b=0,正好是图中的分界线,将数据分割了两个类别。因为这个地方带有截距,所以没有穿过原心点。直线左侧的x通过计算会让g(z)<5,也就是说这里面红颜色的就是小于0.5的负例,绿颜色就是大于0.5的正例。这个东西很简单,之前说的一维情况下,就把小于0的设为负例。
所以看起来我们找到了分类的方法,那么如何确定g(z)?实际上确定了一组w, 就确定了 z,因为Z=w^T*X,确定了z 就确定了 g(z) 的输出。这里的g(z) 也可以写成 g(w,x),代表每条样本所对应的输出。它应该有以下特点,首先值是0到1之间,有概率含义;其次这个概率的含义就是在已知w和x的情况下,它是1类别的概率是多少。我们转化成数学形式的表达就是:以w.x为条件,它的y是1的概率。即:
P(y=1|w,x),自然而然以w.x为条件,它的y是0的概率,即P(y=0|w,x)=1- g(z),是相反的。
所以我们的期望是找到一组w使得已有的数据x为已知的条件下,你预测出来的ŷ发生的概率最大,也就是希望预测出来的ŷ和手头上已经拿到的y一致。什么是不一致,什么是误差?ŷ-y是偏差,误差。对于分类来说,真实的y要么是0,要么就是1。对于ŷ来说,它是一个0到1之间的一个值。如果它真实是1类别,我们的ŷ计算出来结果又正好是1.0,百分之一百准确。如果我们真实类别是1,计算出来是个0.2,这个误差就是0.8。如果你真实的类别是0,你计算出来是0.2,那这个偏差就是0.2。因为它最完美的情况就是0这个类别概率就是0,1这个类别概率就是1.因此我们期望就是只要让我们的g(w,x)函数在训练集上预测正确的概率最大,我的g(w,x)就是好的g(w,x)。
举个例子,比如下面的数据集:
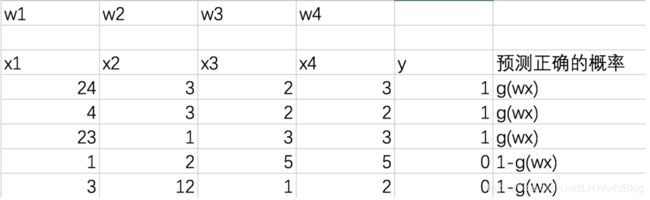
x1,x2,x3,x4分别代表不同的维度,y就是真实的y类别号。我们要求的结果是每个维度所对应的模型w。而我们预测正确的概率,就是ŷ=1/(1+e-θ^T*x),即g(w,x)。它是1类别的概率是g(w,x),它是0类别的概率就是1- g(w,x)。我们结合最大似然的思想。回顾前面我们所学的知识最大似然的总似然是怎么求的?就是要得到每条样本的概率相乘。而当我们求出一组模型来的话,此时的总似然就是我们对应这个模型下每一个样本的概率相乘,而每一个样本此时的概率就是我们预测正确的概率值。我们最大似然的前提是假设这里面的每条样本它是随机并且独立的从所有的样本里面采样的这一部分,所以假如我们的训练集里面就这五条数据,并且每条样本之间相对独立。对于我们这五条样本来说,这里面总的MLE(最大似然)就是第一条样本乘以这组w,然后再带到Sigmoid函数里面去得到g(w*x1),这个X1,代表第一条样本,第二个就是g(w*x2),X2代表第二条样本,第三个就是g(w*x3),第四条是1-g(w*x4),第五条样本是1-g(w*x5),连续相乘,得到总似然。即:MLE=g(w*x1)*g(w*x2)*g(w*x3)*1-g(w*x4)*1-g(w*x5)。这里面的x1,x2,x3,x3,x5分别代表每一行样本。简化一下就是:
![]()
我们只所以将样本预测出来的概率写成g(w,xi)或者是1-g(w,xi),是因为我们看了一眼真实的y=1,才把它写成g(w,xi),看了一眼真实的 y=0给它写成1-g(w,xi)。即:

如果要没看y是1还是0,来表达一个形式的话,那就是下面泛化的形式,它都可以来表达这两种情况。对于每一条数据预测正确的概率即:

假设这条样本,它的lable标签y是1,放到公式中,1-yi=0,后面一部分是1,剩下就是g(w,xi)。如果yi=0的话,前面这部分就是1,后面这部分是1-g(w,xi)。所以说这种形式是不看yi是1,0的情况下,就可以知道概率如何来通过公式来描述和表达。 如果我们有n条样本,要做一个总似然,要把所有条样本的概率相乘.即:

因为假设独立了。所以用一个连乘符号∏,从第1条样本一直乘到n条样本。pi就是上面的单个预测正确的式子。我们得到了一个总似然的式子,记P(全部正确) 为 L(θ),这里的θ为之前的w,记g(w,xi)为h(θ),即:
![]()
它的连乘可以通过log,ln变一下。实际上就是L(θ),大写的L,然后取个对数,把它变成l(θ),小写的l。即:
解释下上面公式:因为log(a*b)=log a+log b,所以从第一个公式化简到第二个公式,所以L(θ),把它变成对数形式l(θ),连乘就变成连加,从第1条加到第m条。又log x^2=2log x,所以从第二条化简为第3条公式,即化简为上面公式。
我们要使得整体似然函数最大,而此时这样一个公式,就成为我们的目标函数。但是搞机器学习的人喜欢去把它换个名称叫损失函数,一般提到损失函数我们都是要找最小。这件事情很简单,如果要找它的最大,就相当于在前面添个-,找添上-之后的整体最小。 所以逻辑回归的损失函数就推导出来了。
所以简单归纳起来就是首先要根据y的真实情况的概率表达,推导出比较泛化的对每条样本的概率表达,然后我们再来一个总似然的概率表达,然后把这些东西带进来,就得到L(θ),然后接着取对数,得到l(θ),最后人为的加一个负号,这就是损失函数。逻辑回归比mse要简单的多。
它有什么含义呢?它是从最大似然理论推出来的,通常前面加一个负号。即:

我们会称为交叉熵。所以很多时候一提到分类,就会提到交叉熵损失函数。这个就是逻辑回归里面的损失函数,它前面是一个负号,所以我们一定要找到交叉熵最小的情况。
熵是什么意思? 高压锅在熵特别大的时候它会爆炸,因为熵从物理上来说,它代表分子的不确定性。分子越不确定,它就乱撞,在高压锅里面乱碰乱撞,总之它代表是不确定性。不确定性越大,就代表熵越大。这个含义也被引入到了信息论里面去,熵越大,就代表了所包含的信息量越大。
熵越大是件好事还是件坏事?要是研究原子弹,肯定越大越好。放到机器学习里面,熵越小越好,因为咱们希望它是有规律的,是确定性的。所以概率越大,熵就越小。比如说这个人它注定是你一身的伴侣,注定的情况下,就意味着这件事情概率特别大,不确定性相反就会变小,不确定性变小就是熵变小。所以概率越大,不确定性越小,熵越小。概率越小,不确定性越大,熵越大。
我们现在找的就是熵越小的情况下,概率越大,概率越大就越能说明已知的x根据我们的某组w,它就越确定最后的结果是真实y,我们要使得这个概率最大。这个是它的本质。我们看下熵和概率的图示关系:
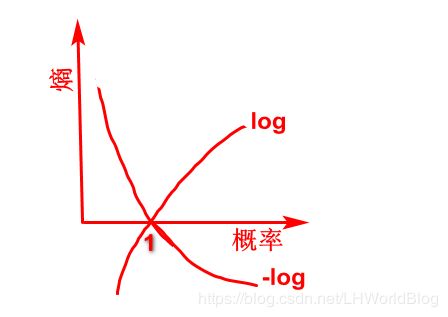
横轴是概率probability,纵轴是熵 entropy。概率最大是1.0,熵没有尽头,概率越大,熵就越小,比如说概率达到1.0的时候,熵就是0。概率越小,熵就越大,越趋于正无穷。它是一个带拐弯的曲线。对比log函数单调递增,如果我们反方向画出log函数,熵的图像类似反方向的log函数。
再来看下我们的损失函数:
左边一部分是yi=1的情况,右边一部分是yi=0的情况,其中log hθ(xi)是我们预测的ŷ,前面y^(i)是我们真实的样本类别,所以yi*log pi,它是交叉熵的公式核心的一部分。如果类比多个分类(k个分类,m个样本),可以自然而然推导出目标函数l(θ)公式应该是,0到k个类别各自的yi*log pi累加,然后再从样本1到m加和,实际上这个就是softmax回归的损失函数,即交叉熵,Cross Entropy,公式是:
![]()
事实上所有的分类,它的损失函数都是交叉熵。只不过逻辑回归里面的pi是根据Sigmoid函数1/(1+e-z)算出来的。如果有人发明了另外一种算法,算出来之后概率不是用这样的公式,无非用交叉熵的时候,hθ(x)的形式变了而已。其实前面推出交叉熵公式的时候,也并没有涉及到前面说的Sigmoid函数,所以它的推导跟Sigmoid函数没有关系。只不过逻辑回归的损失函数在算hθ(x)的时候用了Sigmoid函数。如果是其它算法,那就得用其它算法的公式来算概率。
总结下定义损失函数的步骤:因为要使得l(θ ) 最大的θ 生产出来的 g(θ,x) 全预测对的概率最大,但损失函数是要求某个函数结果越小 生成的模型越好,所以我们定义 - l(θ )为逻辑回归的损失函数,即:
![]()
问题转化为 找到一组使损失函数最小的w,下一步就可以用前面讲过的梯度下降最小化这样一个公式,然后找到w在什么情况下,使得损失函数最小。下一节中我们对具体交叉熵损失函数怎么求解进行展开。