统计学习方法概述
文章目录
- 统计学习方法:
- 变量与空间
- 机器学习算法分类
- 模型分类:
- 统计学习方法三要素
- 过拟合与应对方案
- 训练集、验证集和测试集
统计学习方法:
统计学习是概率论、统计论、信息论、计算理论、最优化理论及计算机科学等多个领域的交叉学科,其基本假设是同类数据具有一定的统计规律性,这是统计学习的前提,其在计算机科学中所处位置如下:

计算机科学由三维组成,即系统、计算和信息,统计学习属于信息这一维,向下又可以分为统计学习方法,统计学习理论和统计学习应用;统计学习方法由模型、策略和算法这三要素构成。
变量与空间
在机器学习模型中涉及的空间包括输入空间、特征空间、输出空间、参数空间。将输入所有可能取值的集合称为输入空间,将输出所有可能取值的集合称为输出空间,每一个输入实例由特征向量表示,所有特征向量所在空间是特征空间,有时假设输入空间与特征空间为相同空间,对他们不予区分(我本人到目前为止不区分这两个空间);有时假设输入空间与特征空间为不同空间,将实例从输入空间映射到特征空间,模型实际上都是定义在特征空间上的。
在监督学习过程中,将输入与输出定义在输入空间与输出空间上的随机变量(大写)的取值,即输入变量X,输出变量Y,变量的具体取值称为实例(小写),输入实例 x x x,输出实例 y y y,第i个实例 x i = ( x i ( 1 ) , x i ( 2 ) , x i ( 3 ) … x i ( n ) ) T x_{i}=(x_{i}^{(1)},x_{i}^{(2)},x_{i}^{(3)} \dots x_{i}^{(n)})^{T} xi=(xi(1),xi(2),xi(3)…xi(n))T,其中 x i ( 3 ) x_{i}^{(3)} xi(3)表示第 i i i个实例的第3个特征,其输出实例为 y i y_{i} yi,定义 ( x i , y i ) (x_{i},y_{i}) (xi,yi)为样本点,这样我们就可以表示数据集为 T = { ( x 1 , y 1 ) , ( x 1 , y 1 ) , ( x 1 , y 1 ) … ( x N , y N ) } T=\{(x_{1},y_{1}),(x_{1},y_{1}),(x_{1},y_{1}) \dots (x_{N},y_{N})\} T={(x1,y1),(x1,y1),(x1,y1)…(xN,yN)},参数空间即参数向量 θ \theta θ的所有可能取值构成的空间。
机器学习算法分类
一般我们所说的机器学习,主要是指统计机器学习,机器学习算法可以分为监督学习、非监督学习、半监督学习和强化学习。监督学习简单理解为有类标签,非监督学习理解为没有类标签,《统计学习方法》以监督学习为主,同时监督学习的模型也是统计学习中内容最丰富、应用最广泛的部分,监督学习的基本假设是输入变量X与输出变量Y具有联合概率分布 P ( X , Y ) P(X,Y) P(X,Y),上面提到的数据集 T = { ( x 1 , y 1 ) , ( x 1 , y 1 ) , ( x 1 , y 1 ) … ( x N , y N ) } T=\{(x_{1},y_{1}),(x_{1},y_{1}),(x_{1},y_{1}) \dots (x_{N},y_{N})\} T={(x1,y1),(x1,y1),(x1,y1)…(xN,yN)}就可以理解为从联合概率分布 P ( X , Y ) P(X,Y) P(X,Y)独立同分布产生的。;非监督学习主要指聚类问题。
{这里留空将来总结半监督学习和强化学习}
监督学习问题可以分为回归问题、分类问题、标注问题,输入变量和输出变量均是连续变量的预测问题称为回归问题,回归问题的学习等价于函数拟合;输入变量可以是离散也可以是连续的但输出变量为有限个离散变量的预测问题称为分类问题,许多统计学习方法可以用于分类,包括k近邻法、感知机、朴素贝叶斯法、决策树、决策列表、logistic回归、SVM、提升方法、贝叶斯网络、神经网络、Winnow等;输入变量与输出变量均为变量序列的预测问题称为标注问题,标注问题是分类问题的推广,也是更复杂结构预测的简单形式,分类问题输出一个类标签,而标记问题输出多个标签(和输入变量长度n一样),对第i个输入 x i = ( x i ( 1 ) , x i ( 2 ) , x i ( 3 ) … x i ( n ) ) T x_{i}=(x_{i}^{(1)},x_{i}^{(2)},x_{i}^{(3)} \dots x_{i}^{(n)})^{T} xi=(xi(1),xi(2),xi(3)…xi(n))T,第i个预测输出为 y i = ( y i ( 1 ) , y i ( 2 ) , y i ( 3 ) … y i ( n ) ) T y_{i}=(y_{i}^{(1)},y_{i}^{(2)},y_{i}^{(3)} \dots y_{i}^{(n)})^{T} yi=(yi(1),yi(2),yi(3)…yi(n))T,假设输出空间包含m个标记,则所有可能的输出结果 y i y_{i} yi有 n m n^{m} nm个,标注常用的统计学习方法有:隐马尔可夫模型、条件随机场。
模型分类:
模型可以分为参数模型和非参数模型,参数模型的参数个数已知,非参数模型的参数个数未知。
监督学习生成模型可以分为概率模型与非概率模型,其中概率模型学习的是条件概率分布 P ( X ∣ Y ) P(X|Y) P(X∣Y),例如朴素贝叶斯分类器,非概率模型学习的是一个决策函数 Y = f ( X ) Y=f(X) Y=f(X),以SVM为例为 y = s i g n ( w T φ ( x i ) + b ) y=sign(w^{T}\varphi(x_{i})+b) y=sign(wTφ(xi)+b)。
监督学习生成的模型还可以分为生成模型和判别模型,生成模型学习联合概率分布 P ( X , Y ) P(X,Y) P(X,Y),得到模型 P ( Y ∣ X ) = P ( X , Y ) P ( X ) P(Y|X)=\frac{P(X,Y)}{P(X)} P(Y∣X)=P(X)P(X,Y),例如朴素贝叶斯法和隐马尔可夫模型;而判别模型直接学习决策函数 Y = f ( X ) Y=f(X) Y=f(X)或者条件概率分布 P ( Y ∣ X ) P(Y|X) P(Y∣X),如k近邻法、感知机、决策树、logistic回归、最大熵模型、SVM、提升方法和条件随机场等。生成模型学习收敛速度快,可以还原出联合概率分布 P ( X , Y ) P(X,Y) P(X,Y),当存在隐变量时仍可使用;判别模型准确率更高,但在隐变量情况不能使用。
统计学习方法三要素
统计学习方法=模型+策略+算法,构建一种统计学习方法就是确定具体的统计学习三要素,统计学习方法之间的不同,就是三要素的不同。对于监督学习,如果用一个词概括这模型、策略、算法具体在干嘛,就是分别确定决策函数/条件概率函数、损失函数、优化方法。
- 模型
这一步主要确定假设空间。假设空间 F F F包含所有可能的模型,一般含有无穷多个模型,例如模型为线性决策函数,假设空间就是所有线性函数的集合。
F = { f ∣ Y = f θ ( X ) } F=\{f|Y=f_{\theta}(X)\} F={f∣Y=fθ(X)}
或 F = { P ∣ P θ ( Y ∣ X ) } F=\{P|P_{\theta}(Y|X)\} F={P∣Pθ(Y∣X)}
θ \theta θ为参数空间中的参数向量 - 策略
指定从假设空间选出最优模型的策略,包含期望损失最小化、经验风险最小化和结构风险最小化三个策略。
期望损失(expected loss)最小化:
min f ∈ F R e x p ( f ) = E p [ L ( Y , f ( X ) ) ] = ∫ L ( y , f ( x ) ) P ( x , y ) d x d y \min \limits_{f \in F} R_{exp}(f)=E_{p}[L(Y,f(X))]=\int L(y,f(x))P(x,y)dxdy f∈FminRexp(f)=Ep[L(Y,f(X))]=∫L(y,f(x))P(x,y)dxdy
L ( y , f ( x ) ) L(y,f(x)) L(y,f(x))为损失函数,为预测值 f ( x ) f(x) f(x)与真实输出 Y Y Y的偏差,常见的损失函数有0-1损失函数 L ( Y , f ( X ) ) = { 1 Y!=f(X) 0 Y=f(X) L(Y,f(X))= \begin{cases} 1& \text{Y!=f(X)}\\ 0& \text{Y=f(X)} \end{cases} L(Y,f(X))={10Y!=f(X)Y=f(X)、平方损失函数 L ( Y , f ( X ) ) = ( Y − f ( X ) ) 2 L(Y,f(X))=(Y-f(X))^{2} L(Y,f(X))=(Y−f(X))2、绝对损失函数 L ( Y , f ( X ) ) = ∣ Y − f ( X ) ∣ L(Y,f(X))=|Y-f(X)| L(Y,f(X))=∣Y−f(X)∣、对数损失函数 L ( Y , P ( Y ∣ X ) ) = − l o g P ( Y ∣ X ) L(Y,P(Y|X))=-logP(Y|X) L(Y,P(Y∣X))=−logP(Y∣X)等。
P ( x , y ) P(x,y) P(x,y)为输入与输出的联合分布,我们一般不知道 P ( x , y ) P(x,y) P(x,y)具体是什么(如果你知道具体是什么,就可以直接求 P ( Y ∣ X ) P(Y|X) P(Y∣X),不需要学习了),所以期望风险最小化不好使用,一般用于理论分析,因而提出了下面的经验风险最小化。
我个人这样理解期望损失最小化的公式,从 P ( x , y ) P(x,y) P(x,y)与 L ( y , f ( x ) ) L(y,f(x)) L(y,f(x))两个维度考虑, P ( x , y ) P(x,y) P(x,y)有大值(x,y同时出现可能性大)和小值(x,y同时出现可能性小), L ( y , f ( x ) ) L(y,f(x)) L(y,f(x))也有大值( y y y与 f ( x ) f(x) f(x)偏差较大)和小值( y y y与 f ( x ) f(x) f(x)偏差较小),当 P ( x , y ) P(x,y) P(x,y)大值与 L ( y , f ( x ) ) L(y,f(x)) L(y,f(x))的大值碰到,其乘积会很大,期望风险就会变大,我们的目的就是找到这样的模型 f f f,使得 f ( x ) f(x) f(x)在 P ( x , y ) P(x,y) P(x,y)取大值时, L ( y , f ( x ) ) L(y,f(x)) L(y,f(x))取小值,即预测值 f ( x ) f(x) f(x)与真实输出 y y y最接近。当然也可以从不等式角度考虑,令a= P ( x , y ) P(x,y) P(x,y),b= L ( y , f ( x ) ) L(y,f(x)) L(y,f(x)),根据不等式 a b ≤ ( a + b 2 ) 2 ab \leq (\frac{a+b}{2})^2 ab≤(2a+b)2,且当a=b时等号成立,即a,b都取大值或小值时, a b ab ab趋向 ( a + b 2 ) 2 (\frac{a+b}{2})^2 (2a+b)2,期望损失增大。
经验风险(empirical risk)最小化:
min f ∈ F R e m p ( f ) = 1 N ∑ i N L ( y i , f ( x i ) ) \min \limits_{f \in F} R_{emp}(f)=\frac{1}{N}\sum_{i}^{N}L(y_{i},f(x_{i})) f∈FminRemp(f)=N1i∑NL(yi,f(xi))
当样本容量很大,经验风险最小化趋于期望损失最小化,当样本容量较小,就容易产生过拟合,为了防止过拟合,提出结构风险最小化。
结构风险最小化(structural risk minimization):
min f ∈ F R s r m ( f ) = 1 N ∑ i N L ( y i , f ( x i ) ) + λ J ( f ) \min \limits_{f \in F} R_{srm}(f)=\frac{1}{N}\sum_{i}^{N}L(y_{i},f(x_{i}))+\lambda J(f) f∈FminRsrm(f)=N1i∑NL(yi,f(xi))+λJ(f)
和经验风险最小化相比,多了一个正则化项(regularizer)或者叫罚项(penalty item), J ( f ) J(f) J(f)为模型的复杂度,一般用模型参数向量的范数, λ \lambda λ为权衡经验风险和模型复杂度的系数,属于超参数,在机器学习的上下文中,超参数是在开始学习过程之前设置值的参数,而不是通过训练得到的参数数据。。 - 算法
把统计学习问题归结为最优化问题,统计学习的算法称为求解最优化问题的算法,其实就是考虑用什么方法计算求解最优模型。
过拟合与应对方案
当模型的复杂度增大时,训练误差会逐渐减小并趋向与0,;而测试误差会先减小,后增大。一旦测试误差开始增大,往往意味着进入过拟合。
我们可以通过正则化与交叉验证方法应对过拟合。
- 正则化:
正则化是结构风险最小化策略(上面有讲到)的实现,正则化符合奥卡姆剃刀原理:在所有可能选择的模型中,能够很好地解释已知数据并且十分简单的才是最好的模型。 - 交叉验证:
这篇blog总结的很好 https://blog.csdn.net/aliceyangxi1987/article/details/73532651
总结一下就是,当数据量非常充足,可以利用留出法(holdout cross validation),将数据切分成训练集、验证集和测试集;当数据量不够充分,可以使用K折交叉验证,最后选出K次评测中平均测试误差最小的模型;数据缺乏时,使用留一法。
多数blog会说k折交叉验证确定一个模型的性能指标,这里的模型应该是包含超参数的。我们定义这样的三元组 ( m , λ , θ ) (m,\lambda,\theta) (m,λ,θ),其中 m m m表示模型model,可以是SVM,logistic回归,神经网络等等; λ \lambda λ表示该模型的超参数; θ \theta θ表示该模型的模型参数;不难看出,这三者有任何一个不同,都可以说是不同的三元组,也就是不同的模型。k折交叉验证固定的就是 ( m , λ ) (m,\lambda) (m,λ),当 m m m或者 λ \lambda λ发生变化,都需要重新使用k折交叉验证。如果模型m确定,例如就是logistic回归,那么k折交叉验证就是确定最优的 λ \lambda λ,对不同的 λ \lambda λ,我们执行多次k折交叉验证,比较平均误差,选出最优的 λ \lambda λ。所以k折交叉验证给我的感觉就是同时完成了训练集和验证集的功能,可以结合下面训练集、验证集和测试集的板块的图进行理解。
当然,有时候编写了一个demo想简单看看结果如何,可以利用简单验证,把数据集按7:3分成训练集和测试集,训练集训练模型,测试集看模型效果。
训练集、验证集和测试集
验证集和测试集的区别之前一直不太懂,下面的blog说的不错 https://blog.csdn.net/jmh1996/article/details/79838917 ,这里简单总结一下,我们知道训练模型需要得到模型参数和超参数的值,而训练集就是训练模型的模型参数,而验证集就是确定模型的最优超参数,测试集用于估计模型对样本的泛化误差。以多项式回归为例,我们想要确定这样的回归函数 f M ( x , ω ) = ω 0 + ω 1 x + ω 1 x + ω 2 x 2 + ⋯ + ω M x M f_{M}(x,\omega)=\omega_{0}+\omega_{1}x+\omega_{1}x+\omega_{2}x^{2}+ \dots +\omega_{M}x^{M} fM(x,ω)=ω0+ω1x+ω1x+ω2x2+⋯+ωMxM,我们就需要知道模型参数向量 ω \omega ω和模型超参数 M M M,在执行机器学习算法之前,我们有很多超参数不同的多项式模型,例如 M = 5 , 10 , 15 , 20 , 25 M=5,10,15,20,25 M=5,10,15,20,25,经过训练集,我们知道了在不同的 M M M时,模型参数向量 ω \omega ω的最优解,经过验证集,我们发现 M = 10 M=10 M=10时候多项式模型最好,在测试集,我们就可以评估最优 ω \omega ω和最优 M M M的多项式模型的泛化能力。
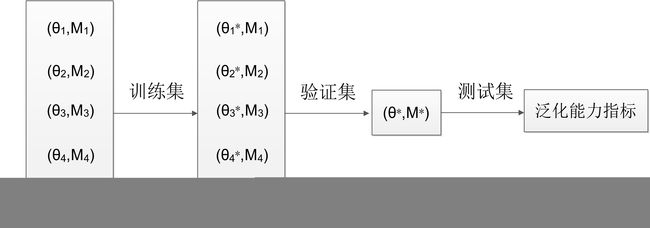
右上角带*表示最优,最左边5个模型其超参数和模型参数都没确定,经过训练集,我们知道了每个 M M M下 θ \theta θ的最优解,经过验证集,我们知道了 M M M和 θ \theta θ都最优的解,经过测试集我们得到了最优的 M M M和 θ \theta θ的模型的泛化能力评估指标。很多人会把验证集和测试集混淆,其实验证集和测试集功能完全不一样,真要说的话,验证集和训练集功能有一点相似,验证集用于确定最优超参数,训练集用于确定最优模型参数。
在深度学习中,验证集还有一个作用,对训练集得到的模型进行一个粗略的评价,一般可以用在early stop,例如模型进入过拟合状态,我们通过训练集看,误差其实还是在不断下降,但是测试集误差已经上升,在这种情况下,我们可以利用验证集做一个粗劣的评价,我们通过观察模型在验证集的表现是可以看出来模型是否已经进入过拟合,从而实现early stop,或者当我们观察模型在训练集表现已经达到我们的一个预期值,也可以进行early stop。值得注意的是,验证集和训练集不能混,训练集会反向传播更新参数,验证集不会,验证集仅做前向传播计算误差,其作用可以说是介于训练集和测试集之间。
总的来说,验证集有两个作用,确定模型超参数,或者防止模型过拟合。
主要参考书籍:《统计学习方法》