【机器学习】广义回归神经网络(GRNN)的python实现
【机器学习】广义回归神经网络(GRNN)的python实现
- 一、广义回归神经网络原理
- 1.1、GRNN与PNN的关系
- 2.2、GRNN的网络结构
- 二、广义回归神经网络的优点与不足
- 2.1、优点
- 2.2、不足
- 三、GRNN的python实现
- 参考资料
一、广义回归神经网络原理
1.1、GRNN与PNN的关系
广义回归神经网络(Generalized Regression Neural Network)的网络结构类似于RBF神经网络。与概率神经网络(PNN)相同,GRNN也是一个前向传播的网络,不需要反向传播求模型参数;不同的是GRNN用于求解回归问题,而PNN用于求解分类问题。关于GRNN的数学原理可以参考资料【1】。
2.2、GRNN的网络结构
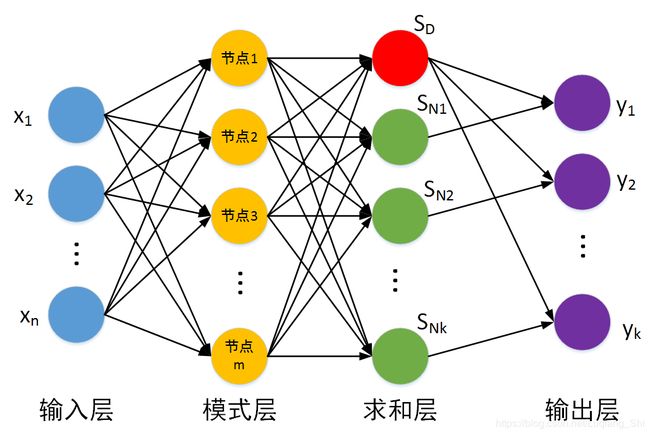
如下图所示,GRNN与PNN一样也是一个四层的网络结构。
对于回归问题训练数据集包括样本特征集与标签集,假设样本特征集为: { t r x 1 , t r x 2 , ⋯ , t r x m } \left\{ {tr{x_1},tr{x_2}, \cdots ,tr{x_m}} \right\} {trx1,trx2,⋯,trxm},每一个样本的维度为 n n n,即 t r x i = [ x 1 , x 2 , ⋯ , x n ] tr{x_i} = [{x_1},{x_2}, \cdots ,{x_n}] trxi=[x1,x2,⋯,xn]。标签集为: { t r y 1 , t r y 2 , ⋯ , t r y m } \left\{ {tr{y_1},tr{y_2}, \cdots ,tr{y_m}} \right\} {try1,try2,⋯,trym},每一个标签的维度为 k k k,即 t r y i = [ y 1 , y 2 , ⋯ , y k ] tr{y_i} = [{y_1},{y_2}, \cdots ,{y_k}] tryi=[y1,y2,⋯,yk]。
输入层:输入测试样本,节点个数等于样本的特征维度。
模式层:(与PNN的模式层相同)计算测试样本与训练样本中的每一个样本的Gauss函数的取值,节点个数等于训练样本的个数。
第 i i i个测试样本 t e x i te{x_i} texi与第 j j j个训练样本 t r x j trx_j trxj之间的Gauss函数取值(对于测试样本 x x x,从第 j j j个模式层节点输出的数值)为:
G a u s s ( t e x i − t r x j ) = e − ∥ t e x i − t r x j ∥ 2 δ 2 Gauss(te{x_i} - tr{x_j}) = {e^{ - \frac{{\left\| {te{x_i} - tr{x_j}} \right\|}}{{2{\delta ^2}}}}} Gauss(texi−trxj)=e−2δ2∥texi−trxj∥
其中 δ \delta δ是模型的超参数(机器学习模型中,超参数是在开始学习过程之前设置值的参数),需要提前设定,也可以通过寻优算法(GA,QGA,PSO,QPSO等)获得。
求和层:节点个数等于输出样本维度加1( k + 1 k+1 k+1),求和层的输出分为两部分,第一个节点输出为模式层输出的算术和,其余 k k k个节点的输出为模式层输出的加权和。
假设对于测试样本 t e x tex tex,模式层的输出为 { g 1 , g 2 , ⋯ , g m } \left\{ {{g_1},{g_2}, \cdots ,{g_m}} \right\} {g1,g2,⋯,gm}。
求和层第一个节点的输出为:
S D = ∑ i = 1 m g i {S_D} = \sum\limits_{i = 1}^m {{g_i}} SD=i=1∑mgi
其余 k k k个节点的输出为:
S N j = ∑ i = 1 m y i j g i , j = 1 , 2 , ⋯ , k {S_{Nj}} = \sum\limits_{i = 1}^m {{y_{ij}}{g_i},j = 1,2, \cdots ,k} SNj=i=1∑myijgi,j=1,2,⋯,k
其中加权系数 y i j y_{ij} yij为第 j j j个模式层节点对应的训练样本的标签的第 j j j个元素。
输出层:输出层节点个数等于标签向量的维度,每个节点的输出等于对应的求和层输出与求和层第一个节点输出相除。
二、广义回归神经网络的优点与不足
2.1、优点
收敛快:没有模型参数需要训练,收敛速度快。
非线性逼近:以径向基网络为基础,具有良好的非线性逼近性能。
2.2、不足
计算复杂度高:每个测试样本要与全部的训练样本进行计算。
空间复杂度高:因为没有模型参数,对于测试样本全部的训练样本都要参与计算,因此需要存储全部的训练样本。
三、GRNN的python实现
完整python代码与样本地址:https://github.com/shiluqiang/GRNN_python
本博文采用数据集为sine函数的数据集,将前190组数据作为训练集,后10组数据作为测试集。数据集中特征维度为1,标签维度也为1,因此GRNN的网络结构应该是(1:190:2:1)。
首先,计算模式层的输出。
def distance(X,Y):
'''计算两个样本之间的距离
'''
return np.sqrt(np.sum(np.square(X-Y),axis = 1))
def distance_mat(trainX,testX):
'''计算待测试样本与所有训练样本的欧式距离
input:trainX(mat):训练样本
testX(mat):测试样本
output:Euclidean_D(mat):测试样本与训练样本的距离矩阵
'''
m,n = np.shape(trainX)
p = np.shape(testX)[0]
Euclidean_D = np.mat(np.zeros((p,m)))
for i in range(p):
for j in range(m):
Euclidean_D[i,j] = distance(testX[i,:],trainX[j,:])[0,0]
return Euclidean_D
def Gauss(Euclidean_D,sigma):
'''测试样本与训练样本的距离矩阵对应的Gauss矩阵
input:Euclidean_D(mat):测试样本与训练样本的距离矩阵
sigma(float):Gauss函数的标准差
output:Gauss(mat):Gauss矩阵
'''
m,n = np.shape(Euclidean_D)
Gauss = np.mat(np.zeros((m,n)))
for i in range(m):
for j in range(n):
Gauss[i,j] = math.exp(- Euclidean_D[i,j] / (2 * (sigma ** 2)))
return Gauss
然后,计算求和层输出。
def sum_layer(Gauss,trY):
'''求和层矩阵,列数等于输出向量维度+1,其中0列为每个测试样本Gauss数值之和
'''
m,l = np.shape(Gauss)
n = np.shape(trY)[1]
sum_mat = np.mat(np.zeros((m,n+1)))
## 对所有模式层神经元输出进行算术求和
for i in range(m):
sum_mat[i,0] = np.sum(Gauss[i,:],axis = 1) ##sum_mat的第0列为每个测试样本Gauss数值之和
## 对所有模式层神经元进行加权求和
for i in range(m):
for j in range(n):
total = 0.0
for s in range(l):
total += Gauss[i,s] * trY[s,j]
sum_mat[i,j+1] = total ##sum_mat的后面的列为每个测试样本Gauss加权之和
return sum_mat
最后,计算输出层的输出。
def output_layer(sum_mat):
'''输出层输出
input:sum_mat(mat):求和层输出矩阵
output:output_mat(mat):输出层输出矩阵
'''
m,n = np.shape(sum_mat)
output_mat = np.mat(np.zeros((m,n-1)))
for i in range(n-1):
output_mat[:,i] = sum_mat[:,i+1] / sum_mat[:,0]
return output_mat
结果展示:
| 测试样本标签 | 回归结果 |
|---|---|
| 0.624676 | 0.557845 |
| 0.816921 | 0.881194 |
| 1.04449 | 0.916176 |
| -0.30906 | -0.293338 |
| 0.267336 | 0.126166 |
| 1.01882 | 0.815953 |
| 0.409871 | 0.296891 |
| 0.920009 | 0.912512 |
| -0.112378 | -0.0923096 |
| 0.768894 | 0.86055 |
参考资料
1、https://blog.csdn.net/guoyunlei/article/details/76101899?locationNum=4&fps=1