Hadoop开发入门与实践(一)
Hadoop开发入门与实践(一)
一、Hadoop简介
Hadoop是一个由Apache基金会所开发的分布式系统基础架构。
Hadoop由 Apache Software Foundation 公司于 2005 年秋天作为Lucene的子项目Nutch的一部分正式引入。它受到最先由 Google Lab 开发的 Map/Reduce 和 Google File System(GFS) 的启发。
用户可以在不了解分布式底层细节的情况下,开发分布式程序。充分利用集群的威力进行高速运算和存储。
Hadoop实现了一个分布式文件系统(Hadoop Distributed File System),简称HDFS。HDFS有高容错性的特点,并且设计用来部署在低廉的(low-cost)硬件上;而且它提供高吞吐量(high throughput)来访问应用程序的数据,适合那些有着超大数据集(large data set)的应用程序。HDFS放宽了(relax)POSIX的要求,可以以流的形式访问(streaming access)文件系统中的数据。 Hadoop的框架最核心的设计就是:HDFS和MapReduce。HDFS为海量的数据提供了存储,则MapReduce为海量的数据提供了计算。
网址:http://hadoop.apache.org/
中文文档:https://hadoop.apache.org/docs/r1.0.4/cn/hdfs_design.html
二、Hadoop的特点
Hadoop运用于海量数据处理,主要特点有:
1. 方便:可以运行在一般商业机器构成的大型集群上,或乾是亚马逊弹性计算云等云计算服务上。
2. 弹性:通过增加集群节点,可以线性地扩展以处理更大数据集。同时,在集群负载下降时,也可以减少节点,以高效使用计资源。
3. 健壮:可以从容处理通用计逄平台上出现的硬件失效的并行分布代码。
4. 简单:允许用户快速编写出高效的并行分布代码。
三、Hadoop版本
| 版本 | 日期 |
|---|---|
| 2.8.2 | 24 Oct, 2017 |
| 2.7.4 | 04 August, 2017 |
| 2.6.5 | 08 October, 2016 |
四、Hadoop生态系统
狭义的Hadoop核心只包括Hadoop Common、Hadoop HDFS和Hadoop MapReduce三个子项目,但是和Hadoop核心密切相关的,还包括:Avro、ZooKeeper、Hive、Pig和HBase等项目。
五、Windows Hadoop环境开发
(一)安装JDK
1、JDK下载
http://download.oracle.com/otn-pub/java/jdk/8u151-b12/e758a0de34e24606bca991d704f6dcbf/jdk-8u151-windows-x64.exe
2、配置环境变量
JAVA_HOME=C:\Program Files\Java\jdk1.8.0_111
path=%JAVA_HOME%\bin;
注意:因路径中有空格,需改为:==”C:\Program Files”\Java\jdk1.8.0_111==
3、JDK环境检测
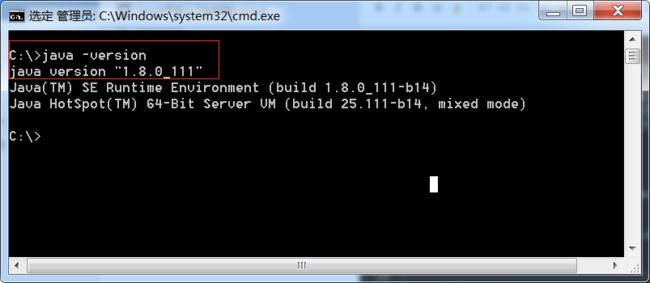
(二)Hadoop安装配置
1、下载Hadoop
下载地址:
http://mirrors.tuna.tsinghua.edu.cn/apache/hadoop/common/hadoop-2.8.2/hadoop-2.8.2.tar.gz
2、解压Hadoop到指定目录
解压文件到: C:\hadoop-2.8.1
3、Hadoop依赖库安装配置
(1)下载Hadoop依赖库
下载地址:https://github.com/steveloughran/winutils
在C盘新建目录:C:\hadoop-2.8.1\bin
解压文件到目录:

依赖库放在Hadoop的bin目录中。
(2)配置环境变量
HADOOP_HOME=C:\hadoop-2.8.1
path=%HADOOP_HOME%\bin;%HADOOP_HOME%\sbin;
==注意==:hadoop.dll等文件不要与hadoop冲突。为了不出现依赖性错误可以将hadoop.dll放到c:/windows/System32下一份。
(3)Hadoop环境测试
C:\hadoop-2.8.1\bin>hadoop version

3、Hadoop配置
配置文件目录:C:\hadoop-2.8.1\etc\hadoop
(1)core-site.xml
<configuration>
<property>
<name>fs.defaultFSname>
<value>hdfs://localhost:9000value>
property>
configuration>(2)hdfs-site.xml
<configuration>
<property>
<name>dfs.replicationname>
<value>1value>
property>
<property>
<name>dfs.namenode.name.dirname>
<value>file:/hadoop/hadoop282/data/dfs/namenodevalue>
property>
<property>
<name>dfs.datanode.data.dirname>
<value>file:/hadoop/hadoop282/data/dfs/datanodevalue>
property>
configuration>(3)mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.namename>
<value>yarnvalue>
property>
configuration>(4)yarn-site.xml
<configuration>
<property>
<name>yarn.nodemanager.aux-servicesname>
<value>mapreduce_shufflevalue>
property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce.shuffle.classname>
<value>org.apache.hadoop.mapred.ShuffleHandlervalue>
property>
configuration>(5)格式化系统文件
C:\hadoop-2.8.1\bin>hdfs namenode -format

待执行完毕即可,不要重复format.
(6)启动hadoop
格式化完成后到hadoop/sbin下执行 start-dfs启动hadoop
C:\hadoop-2.8.1\sbin>start-dfs
回车执行后,将会弹出两个新窗口:
(7)浏览器测试

(8)创建目录:用于输入和输出
C:\hadoop-2.8.1\sbin>hdfs dfs -mkdir /input
C:\hadoop-2.8.1\sbin>hdfs dfs -mkdir /output

创建完成可以通过hdfs dfs-ls 目录名称查看,也可以在浏览器中查看创建的目录或文件
C:\hadoop-2.8.1\bin>hdfs dfs -ls /

(9)创建输入输出文件
input输入文件到目录:study_hadoop是我自己创建的文本文件,位于hadoop一个盘的。此处是C:/study_hadoop
C:\hadoop-2.8.1\bin>hdfs dfs -put /study_hadoop /input
查看input输入的文件内容:
C:\hadoop-2.8.1\bin>hdfs dfs -cat /input/study_hadoop

(10)运行Hadoop的examples
hadoop jar jar文件位置
/input 输入目录(包含被处理文件的目录)
/outputword输出目录(运行结果输出目录)
首先上传输入文件:
C:\hadoop-2.8.1\bin>hdfs dfs -put /input.txt /input
进行计算分析:
C:\hadoop-2.8.1\bin>hadoop jar /hadoop-2.8.1/share/hadoop/mapreduce/hadoop-mapre
duce-examples-2.8.2.jar wordcount /input /outputword

(11)查看结果
C:\hadoop-2.8.1\bin>hadoop fs -ls /outputword
C:\hadoop-2.8.1\bin>hadoop fs -cat /outputword/part-r-00000

(12)启动Yarn
http://localhost:8088
