深入解析mapreduce中shuffle的工作原理

定义
shuffle:针对多个map任务的输出按照不同的分区(Partition)通过网络复制到不同的reduce任务节点上的过程。相应上图中红色框所圈的内容。
由图可见Shuffle过程横跨了map,reduce两端,所以为了方便讲解,我们在下面分为两个部分进行讲解:map端和reduce端
map端的shuffle:
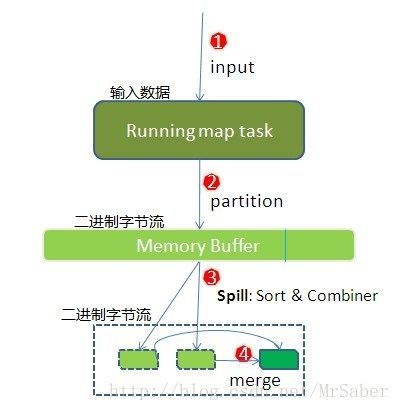
我们按照图中的1234步逐步进行说明:
①在map端首先接触的是InputSplit,在InputSplit中含有DataNode中的数据,每一个InputSplit都会分配一个Mapper任务。
②当key/value被写入缓冲区之前,都会被序列化为字节流。mapreduce提供Partitioner接口,它的作用就是根据key或value及reduce的数量来决定当前的这对输出数据最终应该交由哪个reduce task处理(分区)。默认对key hash后再以reduce task数量取模。默认的取模方式只是为了平均reduce的处理能力,如果用户自己对Partitioner有需求,可以订制并设置到job上。
注意:虽然Partitioner接口会计算出一个值来决定某个输出会交给哪个reduce去处理,但是在缓冲区中并不会实现物理上的分区,而是将结果加载key-value后面。物理上的分区实在磁盘上进行的。
每个map有一个环形内存缓冲区,用于存储任务的输出。默认大小100MB(io.sort.mb属性)。
③一旦达到阀值80%(io.sort.spil l.percent),一个后台线程就把内容写到(spill:溢写)Linux本地磁盘中的指定目录(mapred.local.dir)下的新建的一个溢出写文件。在这一步会执行两个操作排序和Combiner(前提是设置了Combiner)。
这里大家可能会出现疑问:是将哪部分溢写到磁盘上那?答案是,溢写线程启动时,会锁定这80M的内存,执行溢写过程。而剩余的那20M缓冲区会继续接收map的输出,直到缓冲区写满,Map 才会被阻塞直到spill 完成。spill操作和接收map输出的操作是两个独立的线程,故互不影响。
spill 线程在把缓冲区的数据写到磁盘前,会对它进行一个二次快速排序,首先根据数据所属的partition (分区)排序,然后每个partition 中再按Key 排序。输出包括一个索引文件和数据文件。如果设定了Combiner,将在排序输出的基础上运行。Combiner 就是一个简单Reducer操作,它在执行Map 任务的节点本身运行,先对Map 的输出做一次简单Reduce,使得Map 的输出更紧凑,更少的数据会被写入磁盘和传送到Reducer。spill 文件保存在由mapred.local.dir指定的目录中,map 任务结束后删除。
每次溢写会在磁盘上生成一个溢写文件,如果map的输出结果很大,有多次这样的溢写发生,磁盘上相应的就会有多个溢写文件存在。而如果map的输出很小以至于最终也没有到达阀值,那最后会将其缓冲区的内容写入磁盘。
④因为最终的文件只有一个,所以需要将这些溢写文件归并到一起,
这个过程就叫做Merge。因为merge是将多个溢写文件合并到一个文件,所以可能也有相同的key存在,在这个过程中如果client设置过Combiner,也会使用Combiner来合并相同的key。
从这里我们可以得出,溢写操作是写到了磁盘上,并不一定就是最终的结果,因为最终结果是要只有一个文件,除非其map的输出很小以至于没有没有发生过溢写(也就是说磁盘上只有一个文件)。
到这里,map端的shuffle就全部完成了。
reduce端的shuffle:

map完成后,会通过心跳将信息传给tasktracker,其进而通知jobtracker,reduce task不断地通过RPC从JobTracker那里获取map task是否完成的信息,当得知某个TaskTracker上的map task执行完成,Reduce端的shuffle就开始工作了。
注意:这里是reduce端的shuffle开始工作,而不是reduce操作开始执行,在shuffle阶段reduce不会运行。
同样我们按照图中的标号,分为三个阶段进行讲解。
**①**Copy阶段:reduce端默认有5个数据复制线程从map端复制数据,其通过Http方式得到Map对应分区的输出文件。reduce端并不是等map端执行完后将结果传来,而是直接去map端去Copy输出文件。
**②**Merge阶段:reduce端的shuffle也有一个环形缓冲区,它的大小要比map端的灵活(由JVM的heapsize设置),由Copy阶段获得的数据,会存放的这个缓冲区中,同样,当到达阀值时会发生溢写操作,这个过程中如果设置了Combiner也是会执行的,这个过程会一直执行直到所有的map输出都被复制过来,如果形成了多个磁盘文件还会进行合并,最后一次合并的结果作为reduce的输入而不是写入到磁盘中。
③当Reducer的输入文件确定后,整个Shuffle操作才最终结束。之后就是Reducer的执行了,最后Reducer会把结果存到HDFS上。
以上是我个人对mapredcue中shuffle一些理解,如果大家发现上面讲解中存在什么问题,或者是有想要补充的地方,欢迎评论,探讨。