tensorflow —— 基本的LSTM循环网络的实现
利用基本的LSTM循环网络实现对 “international-airline-passengers.csv“ 的预测 ,该数据是 1949到1960共12年,每年12个月的数据,一共 144 个数据。在 SeriesPredictor 类中定义了模型构建、模型训练、模型测试的方法来实现预测,plot_result 方法实现了预测结果的折线图绘制。
import numpy as np
import tensorflow as tf
from tensorflow.contrib import rnn
import matplotlib.pyplot as plt
class SeriesPredictor:
def __init__(self, input_dim, seq_size, hidden_dim):
# Hyperparameters
self.input_dim = input_dim
self.seq_size = seq_size
self.hidden_dim = hidden_dim
# Weight variables and input placeholders
self.W_out = tf.Variable(tf.random_normal([hidden_dim, 1]), name='W_out')
self.b_out = tf.Variable(tf.random_normal([1]), name='b_out')
self.x = tf.placeholder(tf.float32, [None, seq_size, input_dim])
self.y = tf.placeholder(tf.float32, [None, seq_size])
# Cost optimizer
self.cost = tf.reduce_mean(tf.square(self.model() - self.y))
self.train_op = tf.train.AdamOptimizer(learning_rate=0.01).minimize(self.cost)
# Auxiliary ops
self.saver = tf.train.Saver()
def model(self):
"""
:param x: inputs of size [T, batch_size, input_size]
:param W: matrix of fully-connected output layer weights
:param b: vector of fully-connected output layer biases
"""
cell = rnn.BasicLSTMCell(self.hidden_dim)
outputs, states = tf.nn.dynamic_rnn(cell, self.x, dtype=tf.float32)
num_examples = tf.shape(self.x)[0]
W_repeated = tf.tile(tf.expand_dims(self.W_out, 0), [num_examples, 1, 1])
out = tf.matmul(outputs, W_repeated) + self.b_out
out = tf.squeeze(out)
return out
def train(self, train_x, train_y, test_x, test_y):
with tf.Session() as sess:
tf.get_variable_scope().reuse_variables()
sess.run(tf.global_variables_initializer())
max_patience = 3 # 停止训练的参数:连续3次误差增大则停止训练
patience = max_patience
min_test_err = float('inf')
step = 0
while patience > 0:
_, train_err = sess.run([self.train_op, self.cost], feed_dict={self.x: train_x, self.y: train_y})
if step % 100 == 0:
test_err = sess.run(self.cost, feed_dict={self.x: test_x, self.y: test_y})
print('step: {}\t\ttrain err: {}\t\ttest err: {}'.format(step, train_err, test_err))
if test_err < min_test_err:
min_test_err = test_err
patience = max_patience
else:
patience -= 1
step += 1
save_path = self.saver.save(sess, './rnn_ts/model')
print('Model saved to {}'.format(save_path))
def test(self, sess, test_x):
tf.get_variable_scope().reuse_variables()
self.saver.restore(sess, tf.train.latest_checkpoint('./rnn_ts/'))
output = sess.run(self.model(), feed_dict={self.x: test_x})
return output
def plot_results(train_x, predictions, actual, filename):
plt.figure()
num_train = len(train_x)
plt.plot(list(range(num_train)), train_x, color='b', label='training data')
plt.plot(list(range(num_train, num_train + len(predictions))), predictions, color='r', label='predicted')
plt.plot(list(range(num_train, num_train + len(predictions))), actual[:len(predictions)], color='g', label='test data')
plt.legend()
if filename is not None:
plt.savefig(filename)
else:
plt.show()在数据导入之前,需要对数据进行归一化,本次将数据划分为80% 的训练集和20%的测试集。由 data_loader 模块实现。
import numpy as np
import tensorflow as tf
from tensorflow.contrib import rnn
import data_loader
import matplotlib.pyplot as plt
seq_size = 5 # 设置滑动窗口的大小
predictor = SeriesPredictor(input_dim=1, seq_size=seq_size, hidden_dim=100)
data, data_mean, data_std = data_loader.load_series('international-airline-passengers.csv')
train_data, actual_vals = data_loader.split_data(data)
train_x, train_y = [], []
for i in range(len(train_data) - seq_size - 1):
train_x.append(np.expand_dims(train_data[i:i+seq_size], axis=1).tolist())
train_y.append(train_data[i+1:i+seq_size+1])
test_x, test_y = [], []
for i in range(len(actual_vals) - seq_size - 1):
test_x.append(np.expand_dims(actual_vals[i:i+seq_size], axis=1).tolist())
test_y.append(actual_vals[i+1:i+seq_size+1])
predictor.train(train_x, train_y, test_x, test_y)
with tf.Session() as sess:
# method one
predicted_vals = predictor.test(sess, test_x)[:,0]
print('predicted_vals', np.shape(predicted_vals))
plot_results(train_data, predicted_vals, actual_vals, 'predictions1.png')
inversed_predata = np.array(predicted_vals) * data_std + data_mean
inversed_trudata = np.array(actual_vals)[:len(predicted_vals)] * data_std + data_mean
print(inversed_predata)
print(inversed_trudata)
# method two
prev_seq = train_x[-1]
predicted_vals = []
predicted_num = 12
for i in range(predicted_num):
next_seq = predictor.test(sess, [prev_seq])
predicted_vals.append(next_seq[-1])
prev_seq = np.vstack((prev_seq[1:], next_seq[-1]))
plot_results(train_data, predicted_vals, actual_vals, 'predictions2.png')
# 反归一化
inversed_predata = np.array(predicted_vals) * data_std + data_mean
inversed_trudata = np.array(actual_vals)[-predicted_num:] * data_std + data_mean
print(inversed_predata)
print(inversed_trudata)方法一是用原始数据当作测试数据进行测试,共测试了22个样本
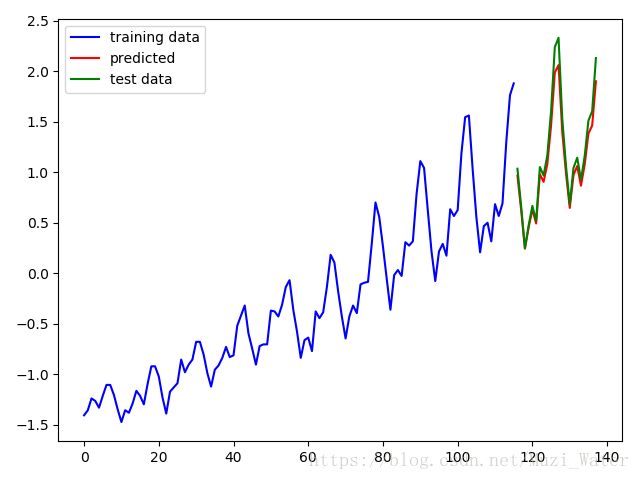
预测数据:[ 395.60186768 354.80560303 309.34631348 334.51806641 355.72271729 339.14706421 397.39108276 388.42373657 409.85327148 455.11221313 517.96313477 526.71069336 447.40203857 398.28482056 357.55560303
396.49676514 407.19207764 383.92028809 408.96676636 445.68139648 455.11221313 507.50881958]
真实数据:[ 404. 359. 310. 337. 360. 342. 406. 396. 420. 472. 548. 559. 463. 407. 362. 405. 417. 391. 419. 461. 472. 535.]
方法二是用预测出的数据作为测试数据进行预测,该方法的精度不如方法一,但扔可看出数据走势,适用于没有真实数据的情况,本次预测了未来12天的数据。
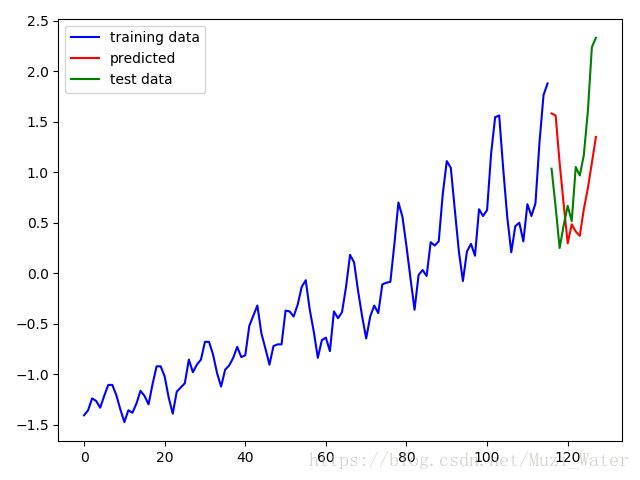
预测数据 [ 469.43139648 467.07409668 410.91229248 362.13061523 315.65072632 338.21929932 329.56622314 324.51544189 356.00354004 380.85159302 410.90618896 441.54260254]
真实数据 [ 417. 391. 419. 461. 472. 535. 622. 606. 508. 461. 390. 432.]