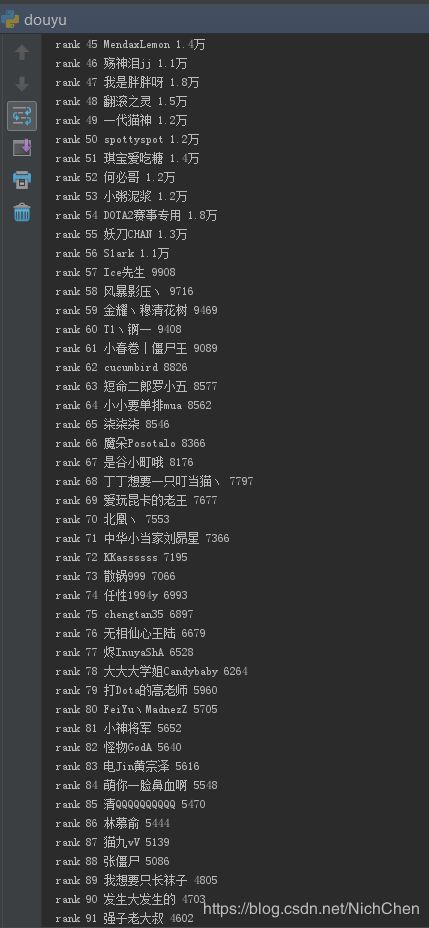
爬虫获取斗鱼主播人气
获取斗鱼页面中DOTA2游戏主播的人气值,并进行排序
代码:
import requests
import re
import random
class Spider():
# url = 'https://www.douyu.com/g_LOL'
url = 'https://www.douyu.com/g_DOTA2'
root_pattern = '([\d\D]*?)'
name_pattern = '([\d\D]{0,20}?)'
number_pattern = '([\d\D]*?)'
def __fetch_content(self):
r = requests.get(Spider.url)
htmls = r.text
return htmls
def __analysis(self, htmls):
root_html = re.findall(Spider.root_pattern, htmls)[1::2]
# print(root_html[0])
anchors = []
# str_max = ""
for html in root_html:
name = re.findall(Spider.name_pattern, html)
number = re.findall(Spider.number_pattern, html)
anchor = {'name': name, 'number': number}
# if len(anchor['name']) > len(str_max):
# str_max = anchor['name']
anchors.append(anchor)
# print(anchors[0], str_max, len(str_max))
return anchors
def __refine(self, anchors):
l = lambda anchor: {
'name': anchor['name'][0].strip(),
'number': anchor['number'][0].strip()}
anchors_refine = list(map(l, anchors))
return anchors_refine
def __sort(self, anchors):
shuffle_list = list(range(len(anchors)))
random.shuffle(shuffle_list)
anchors_shuffle = [anchors[i] for i in shuffle_list]
anchors = sorted(anchors_shuffle, key=self.__sort_seed, reverse=True)
return anchors
def __sort_seed(self, anchor):
r = re.findall('\d*', anchor['number'])
number = float(r[0])
if '万' in anchor['number']:
number *= 10000
return number
# return anchor['number'] # wrong
def __show(self, anchors):
for i, anchor in enumerate(anchors):
print('rank', i+1, anchor['name'], anchor['number'])
def go(self):
htmls = self.__fetch_content()
anchors = self.__analysis(htmls)
anchors = self.__refine(anchors)
anchors = self.__sort(anchors)
self.__show(anchors)
spider = Spider()
spider.go()
结果: