4.4.2分类模型评判指标(三) - KS曲线与KS值
简介
KS曲线是用来衡量分类型模型准确度的工具。KS曲线与ROC曲线非常的类似。其指标的计算方法与混淆矩阵、ROC基本一致。它只是用另一种方式呈现分类模型的准确性。KS值是KS图中两条线之间最大的距离,其能反映出分类器的划分能力。
一句话概括版本:
KS曲线是两条线,其横轴是阈值,纵轴是TPR与FPR。两条曲线之间之间相距最远的地方对应的阈值,就是最能划分模型的阈值。
KS值是MAX(TPR - FPR),即两曲线相距最远的距离。
数据分析与挖掘体系位置
KS曲线也是评判模型结果的指标,因此属于模型评估的一部分。此方法在整个数据分析与挖掘体系中的位置如下图所示。

KS曲线的定义
KS曲线与ROC曲线非常相像,如果不了解ROC曲线的请参阅我写的这篇文章:4.4.2分类模型评判指标(二) - ROC曲线与AUC面积。
了解ROC曲线的人会知道其横轴与纵轴分别是混淆矩阵中的FPR与TPR。而线上的每一个点,都是在不同阈值在得到的FPR与TPR的集合。
如果知道这一事实,那么理解KS就会十分简单。因为KS曲线就是把ROC曲线由原先的一条曲线拆解成了两条曲线。原先ROC的横轴与纵轴都在KS中变成了纵轴,而横轴变成了不同的阈值。
所以总结一下就是:
横轴的计算:
横轴的指标,是阈值(Threshold)。
分类器的输出一般都为[0,1]之间的概率(Possibilities),那么多少几率我们认为会发生事件,多少几率我们认为不会发生时间。界定“发生”与“不发生”的临界值,就叫做阈值。
比如,我们认为下雨几率高于(含等于)0.7时,天气预报就会显示有雨;而下雨几率低于0.7时,天气预报就不会显示有雨。那么这个0.7,就是阈值。他也是KS曲线的横轴。
纵轴的计算:
KS曲线中有两条线,这两条线有共同的横轴,但是纵轴分别有两个指标:FPR与TPR。
由于在之前章节讲过这两个指标,这里就不再赘述。不清楚的请查这篇文章。4.4.2分类模型评判指标(一) - 混淆矩阵(Confusion Matrix)。
KS曲线的解读
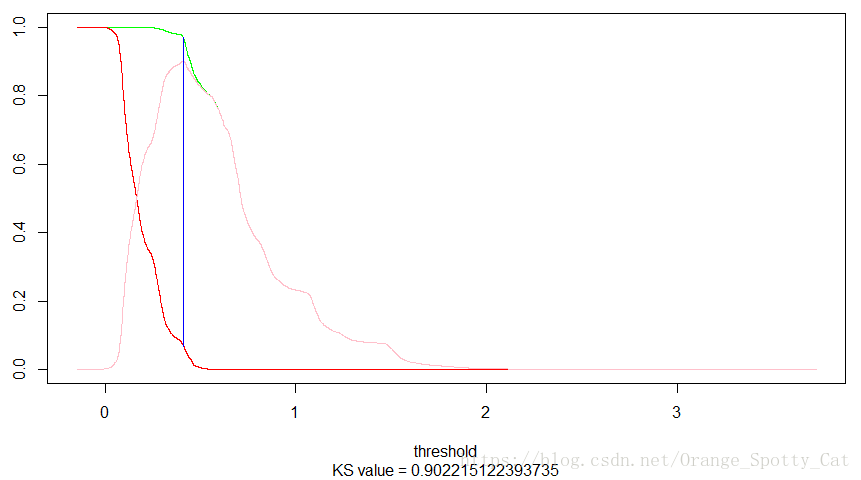
如下图所示,这就是一个典型的KS曲线。
纵轴分别是TPR(绿色线),FPR(红色线)与TPR与FPR的距离(粉色的线)。
横轴我们并未选择传统的阈值(即0-1),我们将横轴变为逻辑回归中预测值Y的概率结果,所以横轴突破了1。在阈值为0.4117361的时候,TPR-FPR的差距是最大的,为0.902215。
因此,我们认为逻辑回归的模型应该将阈值定为41.17%。在这个时候,TPR很高,FPR很低。是最好的输出结果。
KS曲线的在R中的实现
rm(list=ls())
# 引入library
library(reshape2)
library(ROCR)
library(stringr)
# 引入样本,划分Train与Test
diamonds$is_expensive <- diamonds$price > 2400
is_test <- runif(nrow(diamonds)) > 0.75
train <- diamonds[is_test==FALSE,]
test <- diamonds[is_test==TRUE,]
# 拟合模型
fit_A <- glm(is_expensive ~ carat + cut + clarity, data=train)
# 预测模型
prob_A <- predict(fit_A, newdata=test, type="response")
pred_A <- prediction(prob_A, test$is_expensive)
perf_A <- performance(pred_A, measure = "tpr", x.measure = "fpr")
# 预测值以概率的形式保存在“pred_B@predictions”中
# 真实值以“TRUE”/“FALSE”的形式保存在“pred_B@labels”中
unlist(pred_A@predictions)
unlist(pred_A@labels)
# 首先,我们需要将TRUE/FALSE转化为0/1
df <- data.frame(rep = unlist(pred_A@labels))
# 替换
df$rep=str_replace(df$rep,'TRUE',"1")
df$rep=str_replace(df$rep,'FALSE',"0")
# 之后,需要再将数据转化为integer
# 所以,as.integer(unlist(df$rep))是真实的Y值
# 定义公式
myKS <- function(pre,label){
true <- sum(label)
false <- length(label)-true
tpr <- NULL
fpr <- NULL
o_pre <- pre[order(pre)] # let the threshold in an order from small to large
for (i in o_pre){
tp <- sum((pre >= i) & label)
tpr <- c(tpr,tp/true)
fp <- sum((pre >= i) & (1-label))
fpr <- c(fpr,fp/false)
}
plot(o_pre,tpr,type = "l",col= "green",xlab="threshold",ylab="tpr,fpr")
lines(o_pre,fpr,type="l", col = "red")
KSvalue <- max(tpr-fpr)
sub = paste("KS value =",KSvalue)
title(sub=sub)
cutpoint <- which(tpr-fpr==KSvalue)
thre <- o_pre[cutpoint]
lines(c(thre,thre),c(fpr[cutpoint],tpr[cutpoint]),col = "blue")
cat("KS-value:",KSvalue,mean(thre))
}
# 输出结果
myKS(unlist(pred_A@predictions),as.integer(unlist(df$rep)) )