4.3.1有监督学习(二) - 决策树(Decision Tree) - 构建树的核心指标
简介
决策树是与有监督学习中的常用方法。决策树的算法多见于分类问题中,即我们常说的分类树(Classification Tree);少数情况下,决策树也可以用于连续问题,即回归树(Regression Tree)。总体而言,决策树是基于树状结构来进行决策的,它模仿了人在面临决定时自然的处理方式,并将这种决策的过程用树的姿态展现出来。
一句话解释版本:
决策树是在模仿人的决策过程,构造树的指标有三个:信息增益、增益率、基尼系数与卡方值。
数据分析与挖掘体系位置
决策树是有监督学习中的一种模型。所以在数据分析与数据挖掘中的位置如下图所示。

决策树的理解
决策树(Decision Tree)是基于树状结构来模拟并完成决策问题。举一个最简单的二分类问题为例来理解:
假如,要决定“明天要不要出去玩?”这个问题时,通常我会进行一系列“子判断”:
- 首先,我要看“明天是不是双休日?”,如果“是”,则
- 第二,我要看“自己要不要加班?”,如果“是”,则
- 第三,我要看“女朋友愿不愿意跟我出去?”,如果是“OK。”,则
- 第三,我要看“明天天气怎么样?”,如果是“多云”,则
- 我得出最终决策:出去玩走起。
这个决策的过程可以这样显示:
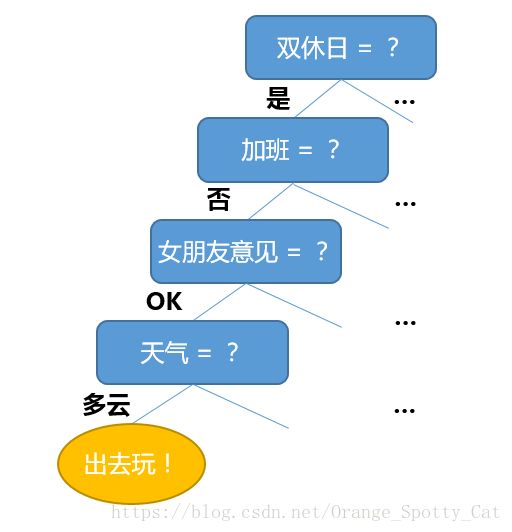
在上面的整个决策过程中,每一个提出的问题都是对属性(Features)的一次测试,测试的结果可能会是下一个问题,或者是最终的决策。每个问题都是有顺序的进行的,其考虑范围是在上个测试结果的限定范围之内。就是说,我只有在确定了“加班 = 否”之后,才会考虑“女朋友意见 = ?”
决策树其实就是在模仿上面的过程。在决策树模型中,Y就是决策结果:出去/不出去;X就是是否双休日、是否加班、女朋友意见、天气情况。最终模型会输出一个与上图类似的结果,告诉我们如何进行决策。
一般来说,一个决策树包括如下部分:
- 根结点(1个):包含样本全集。
- 内部结点(N个):对应属性测试。
- 叶结点(N个):对应决策结果。对应上面的“出去玩”/“不去玩”。
从根结点到叶结点的路径是一个判定测试序列。一个完整的决策树,能够呈现一个决策事件中的全部情况,因此泛化能力强,处理未见示例的能力强。
决策树的算法
决策树的算法参考周志华的《机器学习》一书。
决策树算法的核心是:如何最合适的划分属性(Features)。由于决策树的过程是一步一步不断细化的,因此从根到叶的过程中所包含的样本越来越小。到了决策树的末端时,我们肯定希望结点中包含的样本尽可能的属于同一个类别。
我们把每个节点中包含样本属于一个类别的比率叫做:“纯度”(Purity)。如果一个节点中的样本都属于同一个类别,纯度就是100%。所以我们希望纯度是越高越好的。
那么,如何衡量样本集合的纯度呢?我们要用一个指标:“信息熵”(Information Entropy)。
信息增益与信息熵
信息熵(Information Entropy)
信息熵的功能:衡量样本纯度。
信息熵的公式:
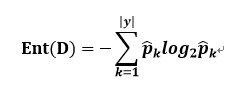
其中:
- D:样本集合
- k:第k个类别,k=1,2,……,|y|
- pk:D中第k个类别的所占比例
Ent(D)的值越小,则样本集合的纯度越高
信息熵是衡量样本与其所属类别的指标,因此与属性X的取值无关。如果要考虑属性对类别划分的影响,要用过另一个指标:“信息增益”(Information Gain)来实现。
信息增益(Information Gain)
信息增益的功能:衡量一个属性a对样本D进行划分后,纯度的提升有多大。
信息增益的公式:
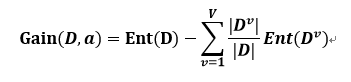
其中:
- D:样本集合
- a:离散属性a,等同于自变量
- V:属性a的V个可能的取值{a1, a2,……, aV},例如:天气可以取:“多云”,“晴天”,“下雨”
- Dv:D中所有在属性a上取值为aV的样本,例如:天气是“多云”的样本。
信息增益中通过计算分支节点的权重,来告诉我们:在属性a中,哪一个分支节点中包含的样本越多,哪一个分支节点的影响力越大。一般而言,信息增益越大,代表使用属性a划分样本所获得的“纯度”提升越大。
因此,可以用信息增益来进行各种属性的选择。我们希望选择的属性肯定是信息增益最大的,用公式表现出来就是:
![]()
实例解释
下面的数据是我过往的17次“明天要不要出去玩”的决定。
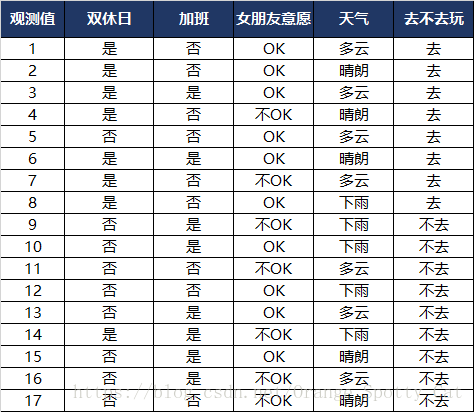
通过上面的例子,我们可以得到如下的结论:
- 观测值一共17个,样本量D=17
- 类别一共2类,所以|y|=2,k可以取“去”或者“不去”
所以,第一步,我们计算信息熵:

第二步,计算当前4个属性中每个属性的信息增益。以天气为例,它可以有三种取值可能:{晴朗,多云,下雨}。如果使用天气这个属性对D划分,可以得到三个子集:
- D1(天气=晴朗),包含5个样本,编号:2,4,6,15,17。其中,正例(去玩)占 3/5=0.60;反例(不去玩)占2/5=0.40。
- D2(天气=多云),包含7个样本,编号:1,3,5,7,11,13,16。其中,正例(去玩)占 4/7;反例(不去玩)占3/7。
- D3(天气=下雨),包含5个样本,编号为:8,9,10,12,14。其中,正例(去玩)占1/5=0.2;反例(不去玩)占4/5=0.8。
所以,我们又可以算出用“天气”属性划分样本后,3个分支节点的信息熵:
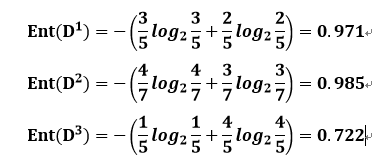
所以,我们进而能计算出“天气”的信息增益:
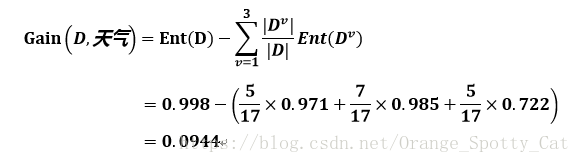
同理,我们能够对其他属性做出同样的计算:

通过比较,我们得出了结论:是否双休日对我是不是要出去玩的影响最大。我女朋友的意愿对我的是不是要出去玩最小。呵呵,你们是不是觉得我女朋友看到这篇文章会很生气。呵呵,骗你们的。其实,我并没有女朋友。。。
不管怎么样,模型告诉我们:是不是双休日这个因素最影响你最终会不会出去玩。所以,决策树的第一个分支就是:“是否双休日”。假如有属性计算出的增益值一样,那我们可以选择他们之间任意属性作为分支点。
所以,通过这种方法,再不断递归,我们就会得到一个最终的决策树。这种方法的优点在于理解简单,使用方便。但是,如果我们把上面的数据放到R里面跑一下,就会知道,结果认为只需要“双休日”一个属性就足够判断去不去玩了。更有甚者,如果我们把“序号”也当作一个属性放入模型,就会发现他的信息增益是0.998。这是因为序号对应的每一个子集数量都是1,纯度最高。所以,用信息增益得到的决策树泛化力非常弱,很难适应新的样本。
同时,信息增益也偏向那些可取值数目较多的属性,比如,我明明说的是女朋友更重要,但是模型却认为天气在我看来更重要。这与天气能够有3个可选样本是有关的。
为了减少信息增益的这些缺点,引出了另外一个构建决策树的方法:增益率,他就是C4.5决策树算法。
增益率
增益率的公式为:
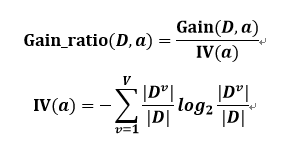
其中,IV(a)是属性的固有值(Intrinsic Value)。属性的取值可能越多,IV(a)越大。
我们增益率的方法计算了上面的例子后,就会发现:

Behold!女朋友的重要性在增益率判定指标时,完美超越了天气!这就是C4.5决策树强于之前的地方。
但是C4.5仍然无法处理数值型的变量。所以,在此基础上,又衍生出的C5.0算法。C5.0也是使用增益率在构建树,但是它更加适合大数据集,并且能同时处理离散属性与连续属性。
在对待离散属性时,C5.0与C4.5的方法是相同的;在处理连续属性时,C5.0的方法首先将数值型数据从小到大排序,再选取每相邻两个点的中间点,将数据自动离散化为两群。然后,分别计算每一次分割所得到的信息增益率,选取信息增益率最大的点作为切割点,此时的信息增益率为此数值属性的信息增益率。这样,C5.0就能处理数值型变量了。
那么,除了信息增益与增益率这两个指标,就没有其他的构建决策树的方法了吗?
其实还有一个就是被广范应用于各种面试题的CART决策树,它是用基尼指数作为评判标准构建决策树的。
基尼指数
CART决策树用基尼指数(Gini Index)作为评判标准构建决策树。而基尼系数是用来衡量纯度的。
对了,基尼指数与信息熵一样,都是衡量纯度的。只不过公式不一样。下面是基尼系数的公式:
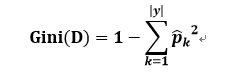
Gini(D)越小,数据的纯度越高。基尼系数反映了随机抽取两个样本,这两个样本所属的类别不一致的概率。
对单个属性a来说,它的基尼系数公式为:
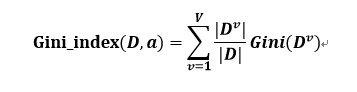
我们选择属性中基尼系数最小的属性作为最优的划分属性。
所以同样是上面的实例,以下是我计算的结果:

可见,是否双休日仍然是最关键的因素。
卡方值
上面的三种算法都与概率有关,但在构造决策树的过程中,还有一种方法是用相关度检验,即卡方检验来测试属性与决策之间的相关度来构建决策树。这种算法被称为CHAID(Chi-squared Automatic Interaction Detection)算法。
CHAID的步骤为:首先,选定分类的目标变量,然后用分类指标与目标变量进行交叉分类,产生一系列二维分类表,分别计算二维分类表里的卡方值,比较p值的大小,以p值最小的二维表作为最佳初始分类表,在最佳二维分类的基础上继续使用分类指标对目标变量进行分类,重复上述过程直到p大于设定的有统计意义的alpha值时则分类停止
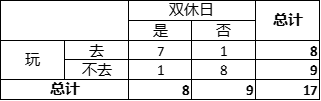
同样用上面的例子,以“是否双休日”为例,我们要确定其与“去不去玩”之间是否存在相关关系。
所以,我们要对这两个变量进行卡方检验:
H0:属性A(SXR)与属性B(Result)之间不相关
H1:属性A(SXR)与属性B(Result)之间相关
检验值:卡方值。其计算公式为:

我们会得到下面这张表格:
所以,
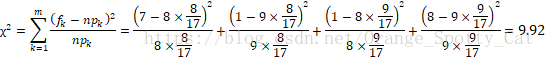
自由度为 (行数 - 1) * (列数 - 1) = (2-1)*(2-1)=1
当显著性为5%,即95%的可信度时,卡方值的临界值是3.84。
由于9.92 > 3.84,所以拒绝原假设,认为SXB与Result相关。
以此类推,我们能得到其他属性的卡方值。
最终,哪个属性的卡方值最大,认为哪个属性是树的第一个分支。该过程持续进行,直到卡方检验无法拒绝原假设,则停止继续构建树。
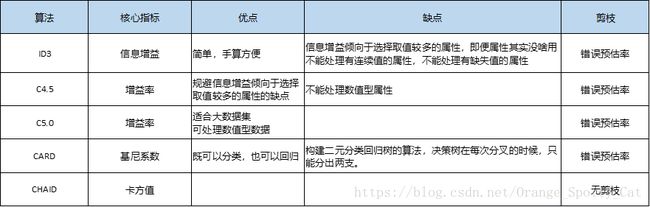
综上,我已经讲解了构造决策树的四种核心算法,大家可以针对数据的特点选择,但是需要注意的是,用什么样的算法构造树,确实可能对结果产生影响。所以选择时还需要结合现实。
决策树的不同算法整合
我将现有比较常见的决策树与其对应的核心指标展示在下表中:
决策树核心算法在R/Python中的实现
真正的算法因为代码好长,而且有R有Python的,不想放这里占地方,请去Github下载吧。
https://github.com/starsfell/decision_tree
下面这个木有啥用,是讲一下上文描述的例子中用到的各种指标的实现方法。上面的才是真正的算法。
rm(list = ls())
# 计算IV值的公式
IV_Dn <- function(a){
IV_D <- -a*log2(a)
return(IV_D)
}
# 计算ENT值的公式
Ent <- function(a, b){
Ent_ab <- -(a*log2(a) + b*log2(b))
return(Ent_ab)
}
# 计算Gini系数的公式
Gini_Dn <- function(a, b) {
Gini_ab = 1 - (a^2 + b^2)
}
# Ent值与Gain值
ENT_data = Ent(9/17, 8/17) # 总样本的Ent值
ENT_SXR_D1 = Ent(1/9, 8/9) # 双休日为“否”的Ent值
ENT_SXR_D2 = Ent(7/8, 1/8) # 双休日为“是”的Ent值
Gain_SXR = 0.998-((9/17)*ENT_SXR_D1+(8/17)*ENT_SXR_D2) # 双休日的gain值
ENT_JB_D1 = Ent(6/9, 3/9) # 加班为“否”的Ent值
ENT_JB_D2 = Ent(2/8, 6/8) # 加班为“是”的Ent值
Gain_JB = 0.998-((9/17)*ENT_JB_D1+(8/17)*ENT_JB_D2) # 加班的gain值
ENT_NPY_D1 = Ent(6/10,4/10) # 女朋友为“ok”的Ent值
ENT_NPY_D2 = Ent(2/7,5/7) # 女朋友为“不ok”的Ent值
Gain_NPY = 0.998-((10/17)*ENT_NPY_D1 +(7/17)*ENT_NPY_D2) # 女朋友的gain值
ENT_TQ_D1 = Ent(3/5,2/5) # 天气为“晴朗”的Ent值
ENT_TQ_D2 = Ent(4/7,3/7) # 天气为“多云”的Ent值
ENT_TQ_D3 = Ent(1/5,4/5) # 天气为“下雨”的Ent值
Gain_TQ = 0.998-((5/17)*ENT_TQ_D1 +(7/17)*ENT_TQ_D2+(5/17)*ENT_TQ_D3) # 天气的gain值
# IV值
IV_BH = IV_Dn(1/17)*17 # 编号的IV值
IV_SXR = IV_Dn(8/17)+ IV_Dn(9/17) # 双休日的IV值
IV_JB = IV_Dn(9/17)+ IV_Dn(8/17) # 加班的IV值
IV_NPY = IV_Dn(10/17)+ IV_Dn(7/17) # 女朋友的IV值
IV_TQ = IV_Dn(5/17)+ IV_Dn(5/17) + IV_Dn(7/17) # 天气的IV值
# 增益率
gain_ratio_SXR = Gain_SXR/IV_SXR
gain_ratio_JB = Gain_JB/IV_JB
gain_ratio_NPY = Gain_NPY/IV_NPY
gain_ratio_TQ = Gain_TQ/IV_TQ
# Gini系数
Gini_data = Gini_Dn(8/17,9/17) # 总样本的Gini系数
Gini_SXR_D1 = Gini_Dn(1/9, 8/9) # 双休日为“否”的Gini系数
Gini_SXR_D2 = Gini_Dn(7/8, 1/8) # 双休日为“是”的Gini系数
Gini_SXR = (9/17)*Gini_SXR_D1+(8/17)*Gini_SXR_D2 # 双休日的Gini系数
Gini_JB_D1 = Gini_Dn(6/9, 3/9) # 加班为“否”的Gini系数
Gini_JB_D2 = Gini_Dn(2/8, 6/8) # 加班为“是”的Gini系数
Gini_JB = (9/17)*Gini_JB_D1+(8/17)*Gini_JB_D2 # 加班的Gini系数
Gini_NPY_D1 = Gini_Dn(6/10,4/10) # 女朋友为“ok”的Gini系数
Gini_NPY_D2 = Gini_Dn(2/7,5/7) # 女朋友为“不ok”的Gini系数
Gini_NPY = (10/17)*Gini_NPY_D1 +(7/17)*Gini_NPY_D2 # 女朋友的Gini系数
Gini_TQ_D1 = Gini_Dn(3/5,2/5) # 天气为“晴朗”的Gini系数
Gini_TQ_D2 = Gini_Dn(4/7,3/7) # 天气为“多云”的Gini系数
Gini_TQ_D3 = Gini_Dn(1/5,4/5) # 天气为“下雨”的Gini系数
Gini_TQ = (5/17)*Gini_TQ_D1 +(7/17)*Gini_TQ_D2+(5/17)*Gini_TQ_D3 # 天气的Gini系数
参考资料:
【1】周志华:《机器学习》