PLA算法的理解(perceptron learning algorithm)
最近在学习台大林轩田教授的课程,一开始就讲到了perceptron learning algorithm,这个算法是用来对线性可分数据进行分类的。要注意这里是线性可分的数据,这个也是PLA算法的局限的地方,如果PLA算法运用在线性不可分的数据中的时候,算法将会无限循环下去,还有就是即使我们的数据是线性可分的,我们也不知道PLA算法什么时候才能找到一个最优的解,可能循环操作几次就可以得到,也有可能需要很多次才能找到最优解,其实在不知道的情况下,我们无法预计算法需要计算多久,这样其实是开销很大的,后续我们基于贪心算法(greedy algorithm)对PLA算法进行了改进,我们每一次的计算都保留当前的最优解,意思就是找到一个相对最优解,然后我们不断去更新优化这个最优解。
首先我们PLA算法是用来求解分类的那条分界线的,也就是求解我们 W = { w 1 , w 2 , . . . , w n } W{\text{ = \{ }}{{\text{w}}_1}{\text{,}}{{\text{w}}_2}{\text{,}}...{\text{,}}{{\text{w}}_n}{\text{\} }} W = { w1,w2,...,wn} 向量,假设我们的数据集为 X = { x 1 , x 2 , . . . , x n } X{\text{ = \{ }}{{\text{x}}_1}{\text{,}}{{\text{x}}_2}{\text{,}}...{\text{,}}{{\text{x}}_n}{\text{\} }} X = { x1,x2,...,xn} ,我们可以用这条线将我们的数据X分成正负两个部分,用数学表达式可以将假设函数h(x)表示成:
h ( x ) = s i g n ( ∑ i = 1 n w i x i − t h r e s h o l d ) h(x) = sign(\sum\limits_{i = 1}^n {{w_i}{x_i} - threshold} ) h(x)=sign(i=1∑nwixi−threshold)
我们将分界线的向量和数据集进行内积运算,然后减去一个阈值,最后加上一个sign函数将数据进行分类操作,结果1表示正类,-1表示负类。在这个公式里这个阈值看着比较碍眼,我们可以将阈值项threshold看作是w0和x0相乘,w0看做是-threshold,x0看做是1,那么整个公式可以表示成:
h ( x ) = s i g n ( ∑ i = 1 n w i x n − t h r e s h o l d ) = s i g n ( ∑ i = 1 n w i x n + ( − t h r e s h o l d ) ( + 1 ) ) = s i g n ( ∑ i = 1 n w i x i + w 0 x 0 ) = s i g n ( ∑ i = 0 n w i x i ) = s i g n ( W T X ) h(x) = sign(\sum\limits_{i = 1}^n {{w_i}{x_n} - threshold} )= sign(\sum\limits_{i = 1}^n {{w_i}{x_n} + ( - threshold} )( + 1)) \\= sign(\sum\limits_{i = 1}^n {{w_i}{x_i} + {w_0}{x_0}} ) = sign(\sum\limits_{i = 0}^n {{w_i}{x_i}} ) = sign({W^T}X) h(x)=sign(i=1∑nwixn−threshold)=sign(i=1∑nwixn+(−threshold)(+1))=sign(i=1∑nwixi+w0x0)=sign(i=0∑nwixi)=sign(WTX)
由上述数学公式我们可以得到 h ( x ) = s i g n ( W T X ) h(x) = sign({W^T}X) h(x)=sign(WTX),在假设函数h(x)中,X是已知的数据集,要求W的向量, W T X {W^T}X WTX的值会把我们数据集分成正负两个类,PLA的算法就是在不断地纠正我们的分类错误,纠正的方法如下所示:
- 正类+1被预测到了负类-1
这个时候,x的实际指向是正方向,也就是说y=+1,但是预测到了-1,也就是说 W T X = − 1 {W^T}X=-1 WTX=−1,这里x的指向表示y的布尔值,我们可以用向量图来表示:
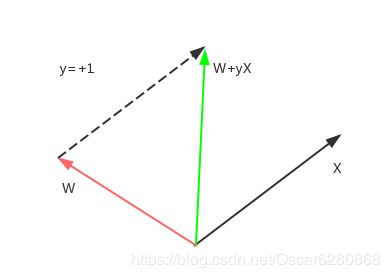
在上图中X是正类,但是与预测的W向量夹角大于90度,所以 W T X = − 1 {W^T}X=-1 WTX=−1,我们如何来纠正这个向量呢?我们可以将W和X向量相加,这里需要注意的是X还需要乘以一个y,来表示向量的方向,同时也表示W分割线调整的方向。这个时候y=+1,所以我们新调整的W是W+X,如图所示,红色的向量表示预测错误的向量,我们加上实际的X向量,就可以得到调整之后的绿色的向量,可以看到绿色的向量相比红色的向量更加靠近X向量了,夹角也小于90度,这样就可以纠正原来的错误预测了。 - 负类-1被预测到了正类+1
同样的道理,X的向量指向负的情况下,但是由于预测错误,W向量和X向量夹角小于90度,所以 W T X = 1 {W^T}X=1 WTX=1,我们同样需要y*X来调整新的预测,我们可以得到下图:
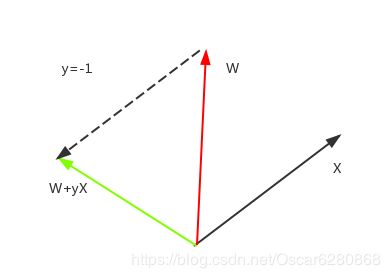
由上图可以看出,黑色的向量X和红色的向量W,由于夹角小于90度,所以 W T X = 1 {W^T}X=1 WTX=1,这个时候需要调整新的W向量,这个时候y=-1,所以W+yX=W-X,就相当于是两个向量相减,得到新的调整之后的绿色的向量,这样新调整的向量与原有的X向量的夹角大于90度,那么 W T X = − 1 {W^T}X=-1 WTX=−1,这样错误就纠正了。
有了上面就正错误点的方法,我们可以不断地更新W,直到找到最优解,用伪代码可以表示成:
init w(0)=0
for t = 0,1,2,3,...:
for i = 1,2,3,4,...,n:
w(t+1) = w(t) + y(i) * x(i)
end
//直到所有的点都被正确分类,我们就停止更新W
有的朋友就会有疑问了,会不会有这个循环停不下来的情况,答案是不会的,这个算法到最后一定是会停下来的。下面我们就来证明一下。首先我们假设有一条理想的分割线 W f {W_f} Wf,因为 y n {y_n} yn和 W f T X n W_f^T{X_n} WfTXn一定是同号的,那么 y n W f T X n {y_n}W_f^T{X_n} ynWfTXn一定是大于0的,所以可以得到:
y n ( t ) W f T X n ( t ) ⩾ min n y n W f T X n > 0 {y_{n(t)}}W_f^T{X_{n(t)}} \geqslant \mathop {\min }\limits_n {y_n}W_f^T{X_n} > 0 yn(t)WfTXn(t)⩾nminynWfTXn>0
我们再来看看理想分割线和我们预测的分割线的内积:
W f T W t + 1 = W f T ( W t + y n ( t ) X n ( t ) ) ⩾ W f T W t + min n y n W f T X n > W f T W t + 0 = W f T W t W_f^T{W_{t + 1}} = W_f^T({W_t} + {y_{n(t)}}{X_{n(t)}}) \geqslant W_f^T{W_t} + \mathop {\min }\limits_n {y_n}W_f^T{X_n} > W_f^T{W_t} + 0 = W_f^T{W_t} WfTWt+1=WfT(Wt+yn(t)Xn(t))⩾WfTWt+nminynWfTXn>WfTWt+0=WfTWt
由上述式子是可以得到 W f T W t W_f^T{W_{t }} WfTWt随着t的增加是递增的,所以说每一次的纠正错误,我们预测的 W t W_{t } Wt与理想的分割线 W f W_f Wf越来越接近,但是也有可能是两个向量的夹角在减小,也有可能是调整的向量在增大,所以我们还需要确定是哪一种情况,我们再来看看下面的推导:
∥ W t + 1 ∥ 2 = ∥ W t + y n ( t ) X n ( t ) ∥ 2 = ∥ W t ∥ 2 + 2 y n ( t ) W t T X n ( t ) + ∥ y n ( t ) X n ( t ) ∥ 2 ⩽ ∥ W t ∥ 2 + 0 + ∥ y n ( t ) X n ( t ) ∥ 2 ⩽ ∥ W t ∥ 2 + max n ∥ y n X n ∥ 2 {\left\| {{W_{t + 1}}} \right\|^2} = {\left\| {{W_t} + {y_{n(t)}}{X_{n(t)}}} \right\|^2} = {\left\| {{W_t}} \right\|^2} + 2{y_{n(t)}}W_t^T{X_{n(t)}} + {\left\| {{y_{n(t)}}{X_{n(t)}}} \right\|^2} \\\leqslant {\left\| {{W_t}} \right\|^2} + 0 + {\left\| {{y_{n(t)}}{X_{n(t)}}} \right\|^2} \leqslant {\left\| {{W_t}} \right\|^2} + \mathop {\max }\limits_n {\left\| {{y_n}{X_n}} \right\|^2} ∥Wt+1∥2=∥∥Wt+yn(t)Xn(t)∥∥2=∥Wt∥2+2yn(t)WtTXn(t)+∥∥yn(t)Xn(t)∥∥2⩽∥Wt∥2+0+∥∥yn(t)Xn(t)∥∥2⩽∥Wt∥2+nmax∥ynXn∥2
由上述的数学公式我们可以得到 ∥ W t + 1 ∥ 2 ⩽ ∥ W t ∥ 2 + max n ∥ y n X n ∥ 2 {\left\| {{W_{t + 1}}} \right\|^2} \leqslant {\left\| {{W_t}} \right\|^2} + \mathop {\max }\limits_n {\left\| {{y_n}{X_n}} \right\|^2} ∥Wt+1∥2⩽∥Wt∥2+nmax∥ynXn∥2,可以看出虽然每次更新的分割线向量长度都在递增,但是每次递增都是受限制的,所以综上我们可以得到,PLA算法到最后一定是会停止的,但是要多久会停下来呢,我们再来证明:
W f T W t = W f T ( W t − 1 + y n ( t − 1 ) X n ( t − 1 ) ) ⩾ W f T W t − 1 + min n y n W f T X n W_f^T{W_t} = W_f^T({W_{t - 1}} + {y_{n(t - 1)}}{X_{n(t - 1)}}) \geqslant W_f^T{W_{t - 1}} + \mathop {\min }\limits_n {y_n}W_f^T{X_n} WfTWt=WfT(Wt−1+yn(t−1)Xn(t−1))⩾WfTWt−1+nminynWfTXn
我们可以将T次调整更新的结果进行叠加,就可以得到:
W f T W t ⩾ W 0 + T ⋅ min n y n W f T X n W_f^T{W_t} \geqslant {W_0} + T \cdot \mathop {\min }\limits_n {y_n}W_f^T{X_n} WfTWt⩾W0+T⋅nminynWfTXn
因为在初始化的时候 W 0 W_0 W0=0,所以 W f T W t ⩾ T ⋅ min n y n W f T X n W_f^T{W_t} \geqslant T \cdot \mathop {\min }\limits_n {y_n}W_f^T{X_n} WfTWt⩾T⋅nminynWfTXn,在上述数学公式中我们就可以推导出:
∥ W t ∥ 2 ⩽ ∥ W t − 1 ∥ 2 + ∥ y n ( t − 1 ) X n ( t − 1 ) ∥ 2 ⩽ ∥ W t − 1 ∥ 2 + max n ∥ X n ∥ 2 ⩽ ∥ W 0 ∥ + T ⋅ max n ∥ X n ∥ 2 {\left\| {{W_t}} \right\|^2} \leqslant {\left\| {{W_{t - 1}}} \right\|^2} + {\left\| {{y_{n(t - 1)}}{X_{n(t - 1)}}} \right\|^2} \leqslant {\left\| {{W_{t - 1}}} \right\|^2} + \mathop {\max }\limits_n {\left\| {{X_n}} \right\|^2} \leqslant \left\| {{W_0}} \right\| + T \cdot \mathop {\max }\limits_n {\left\| {{X_n}} \right\|^2} ∥Wt∥2⩽∥Wt−1∥2+∥∥yn(t−1)Xn(t−1)∥∥2⩽∥Wt−1∥2+nmax∥Xn∥2⩽∥W0∥+T⋅nmax∥Xn∥2
因为初始化 W 0 W_0 W0=0,所以可以得到 ∥ W t ∥ 2 ⩽ T ⋅ max n ∥ X n ∥ 2 {\left\| {{W_t}} \right\|^2} \leqslant T \cdot \mathop {\max }\limits_n {\left\| {{X_n}} \right\|^2} ∥Wt∥2⩽T⋅nmax∥Xn∥2,由上述的推论我们最终可以得到如下的推论:
W f T ∥ W f ∥ W T ∥ W T ∥ = T ⋅ min n y n W f T X n ∥ W f T ∥ ∥ W t ∥ ⩾ T ⋅ min n y n W f T X n ∥ W f T ∥ ⋅ T ⋅ max ∥ X n ∥ n ⩾ T ⋅ min n y n W f T X n ∥ W f T ∥ ⋅ max ∥ X n ∥ n = T ⋅ c o n s t a n t \frac{{W_f^T}}{{\left\| {{W_f}} \right\|}}\frac{{{W_T}}}{{\left\| {{W_T}} \right\|}} = \frac{{T \cdot \mathop {\min }\limits_n {y_n}W_f^T{X_n}}}{{\left\| {W_f^T} \right\|\left\| {{W_t}} \right\|}} \geqslant \frac{{T \cdot \mathop {\min }\limits_n {y_n}W_f^T{X_n}}}{{\left\| {W_f^T} \right\| \cdot \sqrt T \cdot \mathop {\max \left\| {{X_n}} \right\|}\limits_n }} \\\geqslant \frac{{\sqrt T \cdot \mathop {\min }\limits_n {y_n}W_f^T{X_n}}}{{\left\| {W_f^T} \right\| \cdot \mathop {\max \left\| {{X_n}} \right\|}\limits_n }} = \sqrt T \cdot constant ∥Wf∥WfT∥WT∥WT=∥∥∥WfT∥∥∥∥Wt∥T⋅nminynWfTXn⩾∥∥∥WfT∥∥∥⋅T⋅nmax∥Xn∥T⋅nminynWfTXn⩾∥∥∥WfT∥∥∥⋅nmax∥Xn∥T⋅nminynWfTXn=T⋅constant
因为 W f T ∥ W f ∥ W T ∥ W T ∥ = cos θ ⩽ 1 \frac{{W_f^T}}{{\left\| {{W_f}} \right\|}}\frac{{{W_T}}}{{\left\| {{W_T}} \right\|}} = \cos \theta \leqslant 1 ∥Wf∥WfT∥WT∥WT=cosθ⩽1,所以我们可以推导出 T ⋅ min n y n W f T X n ∥ W f T ∥ ⋅ max ∥ X n ∥ n ⩽ 1 \frac{{\sqrt T \cdot \mathop {\min }\limits_n {y_n}W_f^T{X_n}}}{{\left\| {W_f^T} \right\| \cdot \mathop {\max \left\| {{X_n}} \right\|}\limits_n }} \leqslant 1 ∥WfT∥⋅nmax∥Xn∥T⋅nminynWfTXn⩽1,这时候我们来定义一下: R 2 = max n ∥ X n ∥ 2 {R^2} = \mathop {\max }\limits_n {\left\| {{X_n}} \right\|^2} R2=nmax∥Xn∥2, ρ = min n y n W f T ∥ W f ∥ X n \rho = \mathop {\min }\limits_n {y_n}\frac{{W_f^T}}{{\left\| {{W_f}} \right\|}}{X_n} ρ=nminyn∥Wf∥WfTXn,这时候我们可以得到最终的推论:
T ⋅ min n y n W f T X n ∥ W f T ∥ ⋅ max ∥ X n ∥ n ⩽ 1 ⇔ T ⋅ min n y n W f T X n ⩽ ∥ W f T ∥ ⋅ max n ∥ X n ∥ ⇔ T ⩽ ∥ W f T ∥ ⋅ max ∥ X n ∥ n min n y n W f T X n = R ρ ⇔ T ⩽ R 2 ρ 2 \frac{{\sqrt T \cdot \mathop {\min }\limits_n {y_n}W_f^T{X_n}}}{{\left\| {W_f^T} \right\| \cdot \mathop {\max \left\| {{X_n}} \right\|}\limits_n }} \leqslant 1 \Leftrightarrow \sqrt T \cdot \mathop {\min }\limits_n {y_n}W_f^T{X_n} \leqslant \left\| {W_f^T} \right\| \cdot \mathop {\max }\limits_n \left\| {{X_n}} \right\| \\\Leftrightarrow \sqrt T \leqslant \frac{{\left\| {W_f^T} \right\| \cdot \mathop {\max \left\| {{X_n}} \right\|}\limits_n }}{{\mathop {\min }\limits_n {y_n}W_f^T{X_n}}} = \frac{R}{\rho } \Leftrightarrow T \leqslant \frac{{{R^2}}}{{{\rho ^2}}} ∥∥∥WfT∥∥∥⋅nmax∥Xn∥T⋅nminynWfTXn⩽1⇔T⋅nminynWfTXn⩽∥∥WfT∥∥⋅nmax∥Xn∥⇔T⩽nminynWfTXn∥∥∥WfT∥∥∥⋅nmax∥Xn∥=ρR⇔T⩽ρ2R2
所以综上所述,我们纠正迭代的次数T是有上界的,所以说只要数据是线性可分的,那么通过有限次的更新纠正,我们一定可以通过PLA算法找一条分割线来分割我们的数据集。
希望这篇博文能给大家在PLA算法的理解上有所帮助,文中如有疑问或纰漏之处,也望各位朋友批评指正,如有转载,也请标明文章的出处,蟹蟹。