Darknet YOLO 训练问题集锦
该文章记录了YOLOv1-YOLOv3训练过程中可能出现的问题,没有特别标明的,在不同版本YOLO训练中都可能存在的问题。
如果大家有问题/不同的解决办法,欢迎留言。更新于6/28/2018
1. CUDA Error: out of memory
配置Makefile,使用GPU,CUDN以及Opencv
GPU=1
CUDNN=1
OPENCV=1
OPENMP=0
DEBUG=0出现报错:
darknet: ./src/cuda.c:36: check_error: Assertion `0' failed.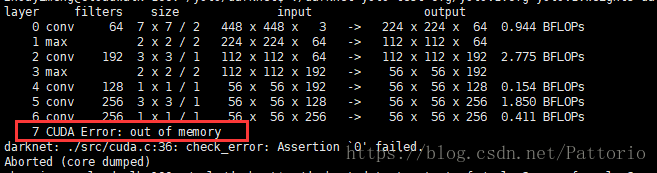
原因是GPU内存不够了
1. 可能是有人占用资源,查查后台进程
2. batch size过大,超出了显卡能够承受的范围。可以适当改小cfg文件中的batch,同时让batch和subdivisions保持在一个比较合适的比例,每次传入的图片数量=进行forward propagation的图片数量=batch/subdivisions,进行backward propagation的图片数量=batch (我的理解是这样,如果不对欢迎指正)
2. loss不收敛,到处都是nan
使用官网教程里的数据出现loss不收敛(nan),IOU很低,辨别不出来class情况,以YOLOv3为例:

原因及解决方法:
1. 如果训练YOLOv3,且一个iter后得到的log是上述图片这样作,那是cfg文件中batch设置问题。
直接从作者github上载下来的 .cfg 文件里,默认是针对test的:
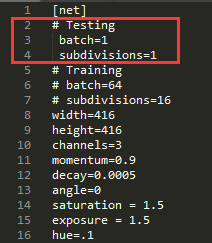
如果要训练的话,要把Testing状态的相关参数注释掉,改用Training状态的参数(batch=64, subdicisions=16),否则会出现loss不收敛,一直nan的状态(这个傻逼问题困扰了我好久,直到我去比较GitHub里对yolov1的修改历史,里面有一个对cfg/yolov1/yolo.train.cfg 的删改,逐行对比过去发现了问题OTL)
改成Training状态之后,就可以看到比较正常的训练log了(训练YOLOv1的结果):

需要测试的时候,也要记得把yolov1.cfg里的参数(batch, subdivisions)改回去。
至于batch和subdivisions两个参数:
batch:批尺寸,每一次迭代送到网络的图片数量。batch * iteration得到的就是一个epoch内训练的样本数。增大这个可以让网络在较少的迭代次数内完成一个epoch。在固定最大迭代次数的前提下,增加batch会延长训练时间,但会更好的寻找到梯度下降的方向。如果你显存够大,可以适当增大这个值来提高内存利用率。这个值是需要大家不断尝试选取的,过小的话会让训练不够收敛,过大会陷入局部最优。
参考:https://blog.csdn.net/dearwind153/article/details/69483190
subdivisions:如果内存不够大,会将batch分割为subdivisions个子batch,每个子batch大小为batch/subdivisions。子batch一份一份的跑完后,在一起打包算作完成一次iteration。这样会降低对显存的占用情况。如果设置这个参数为1的话就是一次性把所有batch的图片都丢到网络里,如果为2的话就是一次丢一半。
参考:https://blog.csdn.net/u012554092/article/details/78263456 (包括其他参数的意义)
关于YOLO的cfg配置文件理解,这个博主说的很全了,参考:https://blog.csdn.net/hrsstudy/article/details/65447947
3. Cannot load image "image_path/image.jpg",类似这样的,明明图片存在却无法读取问题

据我所知的80%都是因为train.txt文件编码问题:你在windows下编写的脚本文件,放到Linux中无法识别格式。
vi ./train.txt //进入文件
:set ff=unix //配置成需要的unix,在window下默认为dos
4. Segmentation fault (core dumped)

刚开始训练没多久,或者跑了不到几百个itertation就出现了这个错误,原因有两个:
1. 检查一下cfg文件的配置,有可能是因为在开了多尺度学习(random=1)的情况下,out of memory,这种情况下,适当调小batch,或者random=0,或者调小输入图片大小
2. 如果不论怎么改小batch都没有用,那么可能是数据集出了问题。检查一下label中是否存在框的x,y坐标为0.0, 0.0的情况,如果有,就适当的使x,y为一个极小值>0
Github:#356
5. YOLOv3训练时,出现大量nan
如果全部都是nan,参考问题2,如果是大量nan,在显存允许的范围内,适当调大batch。
可能调大batch还存在部分region是nan情况,这很正常,因为YOLOv3从三个尺度上提取了特征,且不同尺度选取了不同尺度的的检测框,某尺度下检测框检测不到东西并不奇怪(如,目标过小)
6. YOLOv1检测recall时,出现IOU=0%,Recall=0%
参考我的另一篇博文:https://blog.csdn.net/Pattorio/article/details/80223573
7. First section must be [net] or [network]: No such file or directory

同问题3,也是文件编码问题。这次是cfg文件,请打开cfg文件然后set ff=unix,参考问题3
8. Can't open label file. (This can be normal only if you use MSCOCO)
如果你用的是AlexeyAB的repo,可能会出现这个报错。原因是少了对应的label文件。
9. 使用demo检测视频,出现Cannot allocate memory错误,如下:
Loading weights from yolo.weights...Done!
video file: ../Videos/outside-0001.mov
Couldn't connect to webcam.
: Cannot allocate memory
darknet: ./src/utils.c:193: error: Assertion `0' failed.原因是:cfg文件里batch和subdivisions参数不等于1. 将cfg文件里参数配置为batch=1,subdivisions=1后再检测。