Hadoop — 分布式文件系统HDFS(初识 )
一、HDFS设计基础和目标
# 硬件错误是常态,以此要有冗余。
# 流式数据访问。数据批量读取(而不是随机读取)、Hadoop擅长数据分析(而不是事务处理)。
# 大规模数据集
# 简单一致模型。为降低系统复杂性,对文件采用一次写入多次读取的方式(文件写入之后就不能修改了)
# 程序采用“数据就近”原则分配节点执行
二、HDFS体系框架
# NameNode
# DataNode
# 事物日志
# 映像文件
# SecondaryNameNode

1、NameNode
# 管理文件系统的命名空间
# 记录文件数据块所属的DataNode,和副本信息
# 协调客户端对文件的访问
# 记录命名空间内的改动和空间本身属性的改动
# 适用事物日志记录HDFS元数据的变化,适用映像文件存储文件系统的命名空间,包括映射和文件属性
2、DataNode
# 物理节点上的储存管理
# 一次写入多次读取(不能修改)
# 数据块(block)组成->块大小 64M
# 数据块尽可能分散到各个节点(实现冗余的效果)
3、数据读取流程
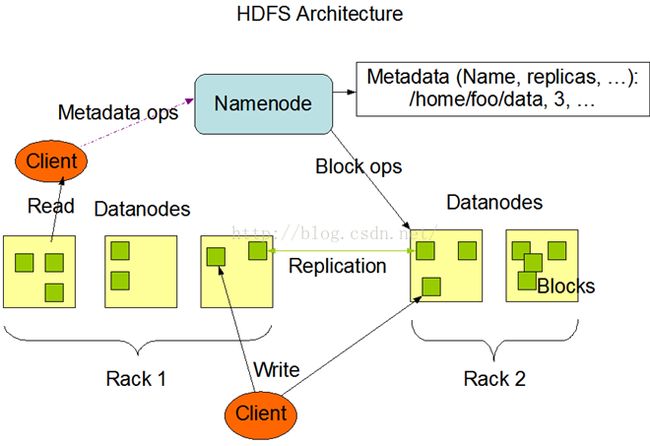
当客户端(Client)希望访问HDFS中的一个文件,首先从NodeNode中获取这个数据块的位置列表,然后读取到数据块所属的DataNode节点,在访问该DataNode,NameNode不参与实际的数据传输,其属于查询工具。
4、HDFS的可靠性

# 冗余副本策略:
在hdfs-site.xml中设置复制因子指定副本数量
所有数据块都有副本
DataNode启动时,遍历文件系统,产生一份hdfs数据块和本地文件的对应关系列表(blockreport)汇报给NameNode
# 机架策略:
集群一般放在不同机架中,机架间的带宽小于机架内的带宽
HDFS“机架感知”(通过节点之间的信息包感知是否在一个机架)
一般要在机架存放一个副本,在其他的机架存放剩下的副本,防止机架失效时的数据丢失,并且提高带宽利用率
# 心跳机制
NameNode周期性从DataNode接收心跳信号和块报告
NameNode根据块报告验证元数据
没有按时发送心跳的DataNode视为宕机,不再发送任何I/O请求
DataNode失效引起副本数量降低,低于预先设置的阀值,NameNode会检测出这些数据块,在适合时机重新设置
引发复制数据块的原因还有,数据块本身的损坏、磁盘错误、复制因子增大
# 安全模式
NameNode启动时,会经历一个“安全模式”
安全模式阶段不会产生数据的写入
此阶段NameNode收集各个DataNode的报告,当数据块达到最小副本数以上时,被认为安全
在一定比例的数据块被确定为”安全”后,再过若干时间,安全模式结束
当检测到副本数不足的数据块时,会执行复制行为(到副本数量达到最小副本数为止)
# 校验和
每个数据块都拥有一个校验和
校验和会作为一个单独的隐藏文件保存在命名空间
客户端获取数据时会检查校验和,从而判断数据块的完整性
若正在读取的数据块遭到损坏,则读取其他数据块
# 回收站
删除文件将放在trash
trash里的文件可以快速恢复
可以设置阀值,当文件存放时间超过阀值将被彻底删除,释放所占用的数据块
# 元数据保护
映像文件和事物日志是NameNode的核心数据,可配置多个副本
副本降低NameNode的处理速度,但增加安全性
NameNode是单点,发生故障要手工接换到SecondaryNameNode
# 快照(某些低版本不支持)
存储某个时间的映像,可以使数据快速重返那个时间点
三、HDFS基础命令
#将文件上传到HDFS下,并列出HDFS下的文件
将文件拷贝到HDFS -> [ hadoop fs -put "被复制文件在linux下的目录" “HDFS下的目标目录”]
补:[hadoop fs -get "path_HDFS" "path_linux"]与上传相反。
查询HDFS的文件 -> [hadoop fs -ls]

查询指定目录 -> [ hadoop fs -ls "HDFS下的目录"]

递归查询 -> [ hadoop fs -ls -R ]

注意:Hadoop 没有当前目录的概念,即无 “cd” 命令。
#查看文件内容命令
查看 -> [ hadoop fs -cat "path_HDFS" ]

#改变文件属性(linux下改变用户组、拥有者、权限属性详细说明)
改变档案用户组 -> [ hadoop fs -chgrp "path_name_HDFS" ]
改变档案拥有者-> [ hadoop fs -chown "path_name_HDFS" ]
改变档案 权 限 -> [ hadoop fs -chmod "path_name_HDFS" ]


#删除HDFS中的文件
删除 -> [ hadoop fs -rm "path_HDFS" ]

查询

递归删除 -> [ hadoop fs -rm -R "path_HDFS" ]

#查看HDFS基本统计信息
查看 -> [ hadoop dfsadmin -report ]

#进入和退出安全模式
进入 -> [ hadoop dfsadmin -safemode enter ]
退出 -> [ hadoop dfsadmin -safemode leave ]

注意:以上所有的HDFS命令 第一个 “hadoop" 在 高版本的 Hadoop 中 应该将其换成 “hdfs”,例如进入和退出安全模式
退出 -> [ hdfs dfsadmin -safemode leave ]
将不会出现 ->

四、添加节点
1.在新节点安装好hadoop
2.把namenode的有关配置文件复制到该节点
3.修改masters和slaves文件,增加该节点
4.设置ssh免密码进出该节点
5.单独启动该节点上的datanode和tasktracker(hadoop-daemon.sh start datanode/tasktracker)
6.运行start-balancer.sh进行数据负载均衡
五、了解 HDFS Java API
![]()
据说这本书挺好(捂脸)