Alextnet网络
Alextnet网络结构图
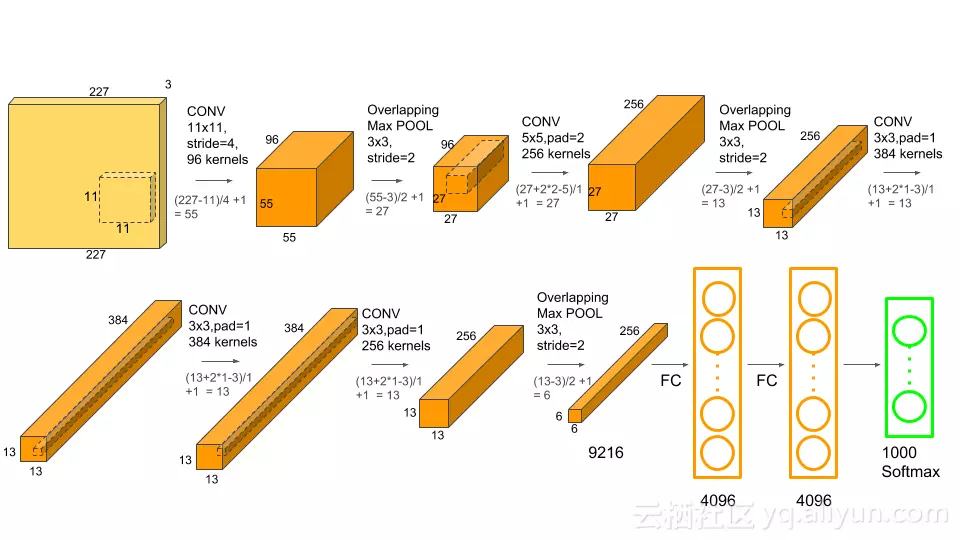
从这个图我们可以很清楚地看到Alexnet的整个网络结构是由5个卷积层和3个全连接层组成的,深度总共8层。
图片上已经有一个较清楚的层与层直接转换的过程,那么接下来就对各层做个简单的解读。
Process
--cov1
1.输入Input的图像规格: 224X224X3(RGB图像),实际上会经过预处理变为227X227X3
2.使用的96个大小规格为11X11X3的过滤器filter,或者称为卷积核(步长为4),进行特征提取,卷积后的数据:
55X55X96 [(227-11)/4+1=55]
(注意,内核的宽度和高度通常是相同的,深度与通道的数量是相同的。)
3.使用relu作为激励函数,来确保特征图的值范围在合理范围之内。
relu1后的数据:55X55X96
4.降采样操作pool1
pool1的核:3X3 步长:2,降采样之后的数据为27X27X96 [(55-3)/2+1=27]
[注意:Alexnet中采用的是最大池化,是为了避免平均池化的模糊化效果,从而保留最显著的特征,并且AlexNet中提出让步长比池化核的尺寸小,这样池化层的输出之间会有重叠和覆盖,提升了特征的丰富性,减少了信息的丢失。]
--cov2
1.输入数据 27X27X96
2.conv2中使用256个5X5大小的过滤器filter(步长1)对27X27X96个特征图,进行进一步提取特征,但是处理的方式和conv1不同,过滤器是对96个特征图中的某几个特征图中相应的区域乘以相应的权重,然后加上偏置之后所得到区域进行卷积。经过这样卷积之后,然后在在加上宽度高度两边都填充2像素,会的到一个新的256个特征图.特征图的大小为:
(【27+2X2 - 5】/1 +1) = 27 ,也就是会有256个27X27大小的特征图.
3.然后进行relu操作,relu之后的数据27X27X96
4.降采样操作pool2
pool1的核:3X3 步长:2,pool2(池化层)降采样之后的数据为13X13X96 [(27-3)/2+1=13]
--cov3
1.没有降采样层
2.得到【13+2X1 -3】/1 +1 = 13 , 384个13X13的新特征图(核3X3,步长为1)
--cov4
1.没有降采样层
2.得到【13+2X1 -3】/1 +1 = 13 , 384个13X13的新特征图(核3X3,步长为1)
--cov5
1.输出数据为13X13X256的特征图
2.降采样操作pool3**
pool3的核:3X3 步长:2,pool3(池化层)降采样之后的数据为6X6X256 [(13-3)/2+1=6]
--fc6
全连接层,这里使用4096个神经元,对256个大小为6X6特征图,进行一个全连接,也就是将6X6大小的特征图,进行卷积变为一个特征点,然后对于4096个神经元中的一个点,是由256个特征图中某些个特征图卷积之后得到的特征点乘以相应的权重之后,再加上一个偏置得到,之后再进行一个dropout,也就是随机从4096个节点中丢掉一些节点信息(值清0),然后就得到新的4096个神经元。
(dropout的使用可以减少过度拟合,丢弃并不影响正向和反向传播。)
[注意:在经过交叉验证,隐含节点dropout率等于0.5的时候效果最好,原因是0.5的时候dropout随机生成的网络结构最多。]
--fc7
和fc6类似
--fc8
采用的是1000个神经元,然后对fc7中4096个神经元进行全链接,然后会通过高斯过滤器,得到1000个float型的值,也就是我们所看到的预测的可能性。
[此process可参考(https://www.cnblogs.com/gongxijun/p/6027747.html)]
接下来补充介绍:在Alexnet中使用relu作为激活函数优势
Relu激活函数
Relu函数为f(x)= max(0,x)
1.sigmoid与tanh有饱和区,Relu函数在x>0时导数一直是1,因为梯度的连乘表达式包括各层激活函数的导数以及各层的权重,reLU解决了激活函数的导数问题,所以有助于缓解梯度消失,也能在一定程度上解决梯度爆炸,从而加快训练速度。
2.无论是正向传播还是反向传播,计算量显著小于sigmoid和tanh。
利用keras实现Alexnet
from keras.models import Sequential
from keras.layers import Dense, Flatten, Dropout
from keras.layers.convolutional import Conv2D, MaxPooling2D
from keras.utils.np_utils import to_categorical
import numpy as np
seed = 7
np.random.seed(seed)
# 创建模型序列
model = Sequential()
#第一层卷积网络,使用96个卷积核,大小为11x11步长为4, 要求输入的图片为227x227, 3个通道,不加边,激活函数使用relu
model.add(Conv2D(96, (11, 11), strides=(1, 1), input_shape=(28, 28, 1), padding='same', activation='relu',
kernel_initializer='uniform'))
# 池化层
model.add(MaxPooling2D(pool_size=(3, 3), strides=(2, 2)))
# 第二层加边使用256个5x5的卷积核,加边,激活函数为relu
model.add(Conv2D(256, (5, 5), strides=(1, 1), padding='same', activation='relu', kernel_initializer='uniform'))
#使用池化层,步长为2
model.add(MaxPooling2D(pool_size=(3, 3), strides=(2, 2)))
# 第三层卷积,大小为3x3的卷积核使用384个
model.add(Conv2D(384, (3, 3), strides=(1, 1), padding='same', activation='relu', kernel_initializer='uniform'))
# 第四层卷积,同第三层
model.add(Conv2D(384, (3, 3), strides=(1, 1), padding='same', activation='relu', kernel_initializer='uniform'))
# 第五层卷积使用的卷积核为256个,其他同上
model.add(Conv2D(256, (3, 3), strides=(1, 1), padding='same', activation='relu', kernel_initializer='uniform'))
model.add(MaxPooling2D(pool_size=(3, 3), strides=(2, 2)))
model.add(Flatten())
model.add(Dense(4096, activation='relu'))
model.add(Dropout(0.5))
model.add(Dense(4096, activation='relu'))
model.add(Dropout(0.5))
model.add(Dense(10, activation='softmax'))
model.compile(loss='categorical_crossentropy', optimizer='sgd', metrics=['accuracy'])
model.summary()
参考来源:(https://blog.csdn.net/qq_41559533/article/details/83718778 )
其余参考资料:(https://www.imooc.com/article/34702)
作者:李_颖Biscuit
链接:https://www.jianshu.com/p/00a53eb5f4b3
来源:简书
简书著作权归作者所有,任何形式的转载都请联系作者获得授权并注明出处。