机器学习笔记——梯度下降(Gradient Descent)
梯度下降算法(Gradient Descent)
在所有的机器学习算法中,并不是每一个算法都能像之前的线性回归算法一样直接通过数学推导就可以得到一个具体的计算公式,而再更多的时候我们是通过基于搜索的方式来求得最优解的,这也是梯度下降法所存在的意义。
- 不是一个机器学习算法
- 是一种基于搜索的最优化方法
- 作用:最小化一个损失函数
- 梯度上升法:最大化一个效用函数
1 梯度下降法
1.1 什么梯度下降法?
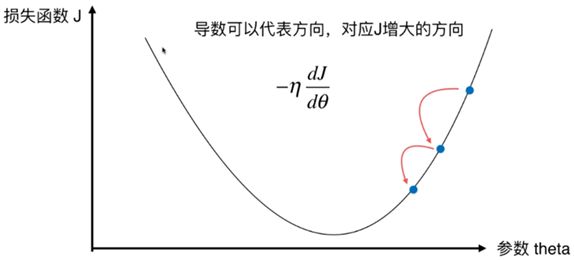
图中任意一点的斜率我们可以用 d J d θ \frac{dJ}{d\theta} dθdJ来表示,而斜率的正负更可以表示增大或减小的放下,若斜率为正则沿 x x x 正方向增大,若斜率为负则沿 x x x 正方向减小,当我们设置一个步长 η \eta η ,以及一个起始点 ( J , θ ) (J,\theta) (J,θ) ,每次向 J J J 减小的方向移动一个步长,则有:
J ( θ − η ) ≈ J ( θ ) − η d J d θ J(\theta-\eta) \approx J(\theta) -\eta\frac{dJ}{d\theta} J(θ−η)≈J(θ)−ηdθdJ
这样通过搜索的方法就可以找到一个最小的 J J J ,而对于某些函数来说并不是都存在一个唯一的极值点,例如下图中的情况:
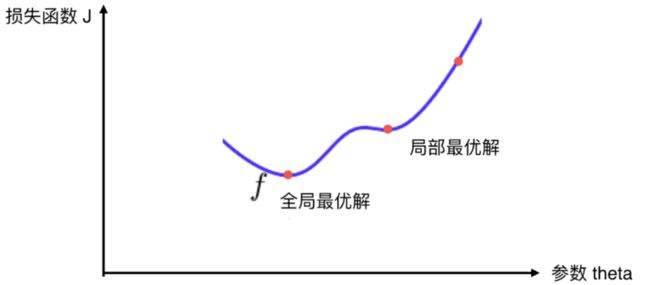
函数 f f f 存在一个局部最优解和一个全局最优解,按照梯度下降算法,如果我们的起始点选在了最右边的红点处的话那么这样寻找到得只是一个局部最优解。为了解决这个问题,我们通常的做法是多次运行,随机化初始点。因此我们可以知道梯度下降算法中的初始点也是一个超参数。
1.2 关于参数 η \eta η
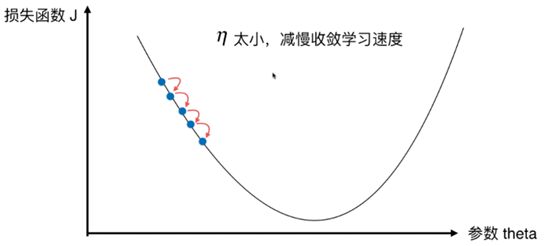
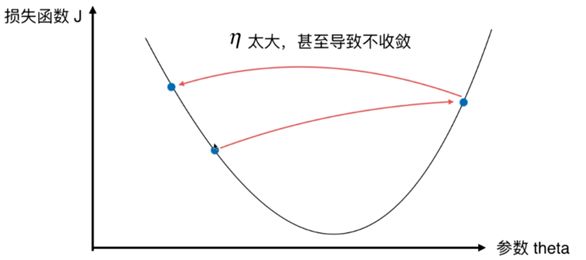
- η \eta η 称为学习率(Learning Rate)
- η \eta η 的取值影响获得最优解的速度
- η \eta η 取值不合适甚至得不到最优解
- η \eta η 是梯度下降算法的一个超参数
1.3 代码实现梯度下降算法
import numpy as np
import matplotlib.pyplot as plt
plot_x = np.linspace(-1,6,141)
# print(plot_x)
plot_y = (plot_x - 2.5) ** 2 -1
plt.plot(plot_x,plot_y)
# plt.show()
def dJ(theta):
return 2 * (theta - 2.5)
def J(theta):
return (theta - 2.5) ** 2 -1
theta = 0.0
eta = 0.1
epsilon = 1e-8
theta_history = [theta]
while True:
gradieent = dJ(theta)
last_theta = theta
theta = theta - eta * gradieent
theta_history.append(theta)
if(abs(J(theta) -J(last_theta)) < epsilon):
break
plt.plot(np.array(theta_history), J(np.array(theta_history)), color = 'r', marker = '+')
plt.show()
print(theta)
print(J(theta))
#**************************运行结果***************************************
# 2.499891109642585
# -0.99999998814289
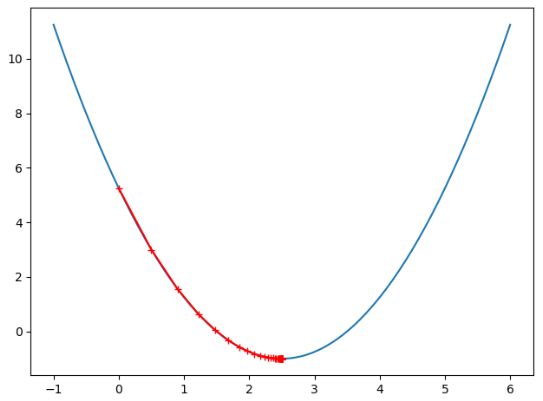
显然我们实现的梯度下降算法已经达到了我们想要的效果,下面我们对上面的代码进行封装,再看看不同的 θ \theta θ 取值对算法效果的影响:
import numpy as np
import matplotlib.pyplot as plt
plot_x = np.linspace(-1,6,141)
def dJ(theta):
return 2 * (theta - 2.5)
def J(theta):
return (theta - 2.5) ** 2 -1
def gradient_descent(initial_theta, eta, epsilon=1e-8):
theta = initial_theta
theta_history.append(initial_theta)
while True:
gradieent = dJ(theta)
last_theta = theta
theta = theta - eta * gradieent
theta_history.append(theta)
if (abs(J(theta) - J(last_theta)) < epsilon):
break
def plot_theta_history():
plt.plot(plot_x, J(plot_x))
plt.plot(np.array(theta_history), J(np.array(theta_history)), color='r', marker='+')
plt.show()
eta = 0.01
theta_history = []
gradient_descent(0.0, eta)
plot_theta_history()
#***************************************运行结果************************
# 如下图
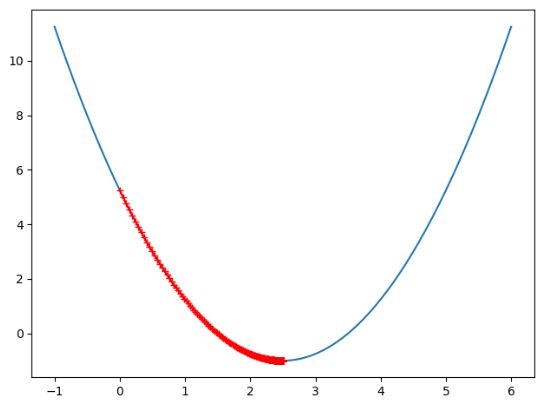
相比我们将 θ \theta θ 设置为0.1,此时的 θ = 0.01 \theta = 0.01 θ=0.01 显然此时已经近乎拟合了曲线。如果我们把 θ \theta θ 的取值设置的更大一点呢?
eta = 0.8
theta_history = []
gradient_descent(0.0, eta)
plot_theta_history()
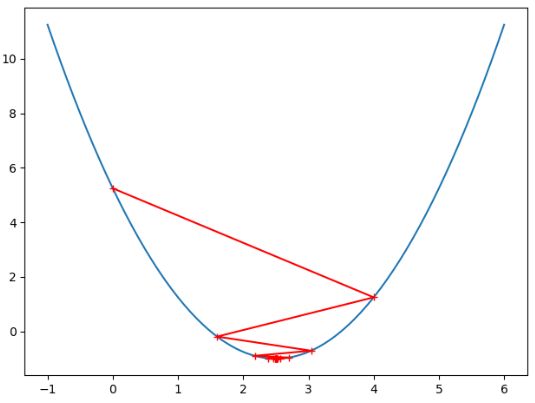
虽然此时我们的梯度下降算法并没有很好的拟合我们的曲线,但是依然有效,依旧找到了最优解,因此我们知道, θ \theta θ 的值只要不超过某个限定的值就是有效的。
下面我们试着将 θ \theta θ 的值设置为1.1
此时编译器直接报错
OverflowError: (34, 'Result too large')
此时因为我们选取的 η \eta η 值过大,是的我们无法求得最优解,我我们修改一下代码,用matplot画出直观的图示来看看究竟发生了什么。
首先我们将gradient_descent函数中添加一个n_iterations变量来控制循环次数,再改变while循环的条件
ef gradient_descent(initial_theta,eta, n_iterations = 1e4, epsilon=1e-8):
theta = initial_theta
theta_history.append(initial_theta)
i_iter = 0
while i_iter < n_iterations:
gradieent = dJ(theta)
last_theta = theta
theta = theta - eta * gradieent
theta_history.append(theta)
if (abs(J(theta) - J(last_theta)) < epsilon):
break
i_iter += 1
我们让while循环执行10次查看结果
eta = 1.1
theta_history = []
gradient_descent(0.0, eta,n_iterations=10)
plot_theta_history()
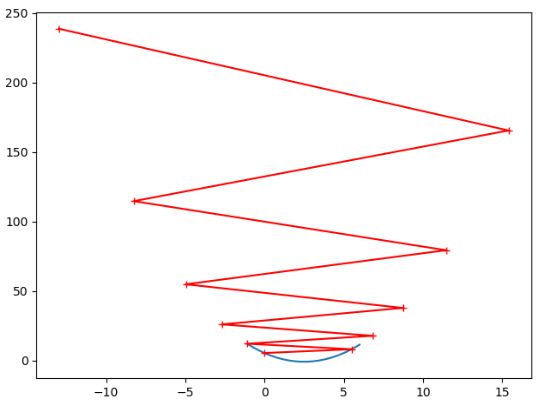
从结果中我们可以明显看到, θ \theta θ 取值过大, J ( θ ) J(\theta) J(θ) 的值也随之越来越大,而且我们这里只循环了10次,在之前我们的while循环直接等于true,一直在死循环,所以才会报OverflowError: (34, 'Result too large')的错误!
2 多元线性回归中的梯度下降算法
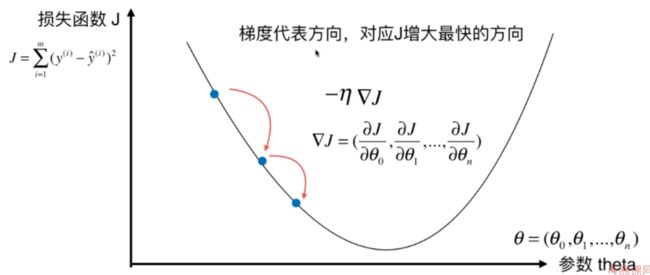
在参数只有一个的情况下,我们知道斜率对应于 J J J 增大的方向,而在多个参数的情况下梯度 ∇ J \nabla J ∇J 表示 J J J增大最快的方向
在之前的多元线性回归算法中我们的目标函数为
∑ i = 1 m ( y ( i ) − y ^ ( i ) ) 2 \sum_{i=1}^m{(y^{(i)}-\hat{y}^{(i)})^2} i=1∑m(y(i)−y^(i))2
y ^ ( i ) = θ 0 + θ 0 x 1 ( i ) + θ 0 x 2 ( i ) + ⋯ + θ 0 x n ( i ) \hat{y}^{(i)}=\theta_0+\theta_0x_1^{(i)}+\theta_0x_2^{(i)}+\cdots+\theta_0x_n^{(i)} y^(i)=θ0+θ0x1(i)+θ0x2(i)+⋯+θ0xn(i)
所以也就是求
∑ i = 1 m ( y ( i ) − θ 0 − θ 0 x 1 ( i ) − θ 0 x 2 ( i ) − ⋯ − θ 0 x n ( i ) ) 2 \sum_{i=1}^m{(y^{(i)}-\theta_0-\theta_0x_1^{(i)}-\theta_0x_2^{(i)}-\cdots-\theta_0x_n^{(i)})^2} i=1∑m(y(i)−θ0−θ0x1(i)−θ0x2(i)−⋯−θ0xn(i))2
尽可能小。
下面我们来求这一函数的梯度:
∇ J = ( ∂ J ∂ θ 0 ∂ J ∂ θ 1 ∂ J ∂ θ 2 ⋮ ∂ J ∂ θ n ) = ( ∑ i = 1 m 2 ( y ( i ) − X b ( i ) θ ) ⋅ ( − 1 ) ∑ i = 1 m 2 ( y ( i ) − X b ( i ) θ ) ⋅ ( − X 1 ( i ) ) ∑ i = 1 m 2 ( y ( i ) − X b ( i ) θ ) ⋅ ( − X 2 ( i ) ) ⋮ ∑ i = 1 m 2 ( y ( i ) − X b ( i ) θ ) ⋅ ( − X n ( i ) ) ) \nabla J= \begin{pmatrix} \frac{\partial J}{\partial \theta_0} \\ \frac{\partial J}{\partial \theta_1} \\ \frac{\partial J}{\partial \theta_2} \\ \vdots \\ \frac{\partial J}{\partial \theta_n} \end{pmatrix}= \begin{pmatrix} \sum_{i=1}^m2(y^{(i)}-X_b^{(i)}\theta)·(-1) \\ \sum_{i=1}^m2(y^{(i)}-X_b^{(i)}\theta)·(-X_1^{(i)}) \\ \sum_{i=1}^m2(y^{(i)}-X_b^{(i)}\theta)·(-X_2^{(i)}) \\ \vdots \\ \sum_{i=1}^m2(y^{(i)}-X_b^{(i)}\theta)·(-X_n^{(i)}) \end{pmatrix} ∇J=⎝⎜⎜⎜⎜⎜⎜⎛∂θ0∂J∂θ1∂J∂θ2∂J⋮∂θn∂J⎠⎟⎟⎟⎟⎟⎟⎞=⎝⎜⎜⎜⎜⎜⎜⎛∑i=1m2(y(i)−Xb(i)θ)⋅(−1)∑i=1m2(y(i)−Xb(i)θ)⋅(−X1(i))∑i=1m2(y(i)−Xb(i)θ)⋅(−X2(i))⋮∑i=1m2(y(i)−Xb(i)θ)⋅(−Xn(i))⎠⎟⎟⎟⎟⎟⎟⎞
= 2 ( ∑ i = 1 m ( X b ( i ) θ − y ( i ) ) ⋅ ∑ i = 1 m ( X b ( i ) θ − y ( i ) ) ⋅ X 1 ( i ) ∑ i = 1 m ( X b ( i ) θ − y ( i ) ) ⋅ X 2 ( i ) ⋮ ∑ i = 1 m ( X b ( i ) θ − y ( i ) ) ⋅ X n ( i ) ) =2 \begin{pmatrix} \sum_{i=1}^m(X_b^{(i)}\theta-y^{(i)})· \\ \sum_{i=1}^m(X_b^{(i)}\theta-y^{(i)})·X_1^{(i)} \\ \sum_{i=1}^m(X_b^{(i)}\theta-y^{(i)})·X_2^{(i)} \\ \vdots \\ \sum_{i=1}^m(X_b^{(i)}\theta-y^{(i)})·X_n^{(i)} \end{pmatrix} =2⎝⎜⎜⎜⎜⎜⎜⎛∑i=1m(Xb(i)θ−y(i))⋅∑i=1m(Xb(i)θ−y(i))⋅X1(i)∑i=1m(Xb(i)θ−y(i))⋅X2(i)⋮∑i=1m(Xb(i)θ−y(i))⋅Xn(i)⎠⎟⎟⎟⎟⎟⎟⎞
观察发现这个式子于 m m m 相关,也就是说于样本的数量相关,如果样本数量越大,那么梯度中的元素值越大,显然这并不是我们想要的结果,为了消去 m m m 的影响,我们把结果除以 m m m 即:
2 m ( ∑ i = 1 m ( X b ( i ) θ − y ( i ) ) ⋅ ∑ i = 1 m ( X b ( i ) θ − y ( i ) ) ⋅ X 1 ( i ) ∑ i = 1 m ( X b ( i ) θ − y ( i ) ) ⋅ X 2 ( i ) ⋮ ∑ i = 1 m ( X b ( i ) θ − y ( i ) ) ⋅ X n ( i ) ) \frac{2}{m} \begin{pmatrix} \sum_{i=1}^m(X_b^{(i)}\theta-y^{(i)})· \\ \sum_{i=1}^m(X_b^{(i)}\theta-y^{(i)})·X_1^{(i)} \\ \sum_{i=1}^m(X_b^{(i)}\theta-y^{(i)})·X_2^{(i)} \\ \vdots \\ \sum_{i=1}^m(X_b^{(i)}\theta-y^{(i)})·X_n^{(i)} \end{pmatrix} m2⎝⎜⎜⎜⎜⎜⎜⎛∑i=1m(Xb(i)θ−y(i))⋅∑i=1m(Xb(i)θ−y(i))⋅X1(i)∑i=1m(Xb(i)θ−y(i))⋅X2(i)⋮∑i=1m(Xb(i)θ−y(i))⋅Xn(i)⎠⎟⎟⎟⎟⎟⎟⎞
此时的目标函数也相应得改为:
1 m ∑ i = 1 m ( y ( i ) − y ^ ( i ) ) 2 \frac{1}{m}\sum_{i=1}^m{(y^{(i)}-\hat{y}^{(i)})^2} m1i=1∑m(y(i)−y^(i))2
这个式子我们应该很熟悉就是前面所学的 M S E MSE MSE 也即
J ( θ ) = M S E ( y , y ^ ) J(\theta) = MSE(y,\hat{y}) J(θ)=MSE(y,y^)
有时我们也取
J ( θ ) = 1 2 m ∑ i = 1 m ( y ( i ) − y ^ ( i ) ) 2 J(\theta) =\frac{1}{2m}\sum_{i=1}^m{(y^{(i)}-\hat{y}^{(i)})^2} J(θ)=2m1i=1∑m(y(i)−y^(i))2
来消去梯度中计算结果中的2,但是两者一般情况下并没有什么显著的差距。
2.1 实现多元线性回归中的梯度下降算法
我们在之前的多元线性回归算法中封装了一个fit_nomal的方法,现在我们使用同样的方法封装一个fit_gd的方法,以后使用时直接调用这个方法即可
def fit_gd(self,X_train,y_train,eta=0.01,n_iterations=1e4):
"""根据训练数据集X_train训练 Linear Regression模型"""
assert X_train.shape[0] == y_train.shape[0], \
"the size of X_train must be equal to the size of y_train"
def J(theta, x_b, y):
try:
return np.sum((y - x_b.dot(theta)) ** 2) / len(x_b)
except:
return float('inf')
def dJ(theta, x_b, y):
res = np.empty(len(theta))
res[0] = np.sum(x_b.dot(theta) - y)
for i in range(1, len(theta)):
res[i] = (x_b.dot(theta) - y).dot(x_b[:, i])
return res * 2 / len(x_b)
def gradient_descent(x_b, y, initial_theta, eta, n_iterations=1e4, epsilon=1e-8):
theta = initial_theta
i_iter = 0
while i_iter < n_iterations:
gradient = dJ(theta, x_b, y)
last_theta = theta
theta = theta - eta * gradient
if (abs(J(theta, x_b, y) - J(last_theta, x_b, y)) < epsilon):
break
i_iter += 1
return theta
x_b = np.hstack([np.ones((len(X_train), 1)), X_train])
initial_theta = np.zeros(x_b.shape[1])
self._theta=gradient_descent(x_b,y_train,initial_theta,eta,n_iterations)
self.interception_=self._theta[0]
self.coef_ = self._theta[1:]
这样就将这个fit_gd方法封装进了LinearRegression这个类当中了,我们看一下具体怎么使用
import numpy as np
import matplotlib.pyplot as plt
from LinearRegression import LinearRegression
lin_reg = LinearRegression()
np.random.seed(666)
x = np.random.random(size=100)
y = x * 3. + 4. + np.random.normal(size=100)
X = x.reshape(-1,1)
lin_reg.fit_gd(X,y)
print(lin_reg.coef_)
print(lin_reg.interception_)
#***************运行结果********************
# [3.0043078]
# 4.0269033037832385
可以看到运行的结果符合我们模拟的直线 y = 3 x + 4 y=3x+4 y=3x+4
2.2 梯度下降法的向量化处理
在上一节中我们知道了梯度的求法:
∇ J ( θ ) = 2 m ( ∑ i = 1 m ( X b ( i ) θ − y ( i ) ) ∑ i = 1 m ( X b ( i ) θ − y ( i ) ) ⋅ X 1 ( i ) ∑ i = 1 m ( X b ( i ) θ − y ( i ) ) ⋅ X 2 ( i ) ⋮ ∑ i = 1 m ( X b ( i ) θ − y ( i ) ) ⋅ X n ( i ) ) \nabla J(\theta)=\frac{2}{m} \begin{pmatrix} \sum_{i=1}^m(X_b^{(i)}\theta-y^{(i)}) \\ \sum_{i=1}^m(X_b^{(i)}\theta-y^{(i)})·X_1^{(i)} \\ \sum_{i=1}^m(X_b^{(i)}\theta-y^{(i)})·X_2^{(i)} \\ \vdots \\ \sum_{i=1}^m(X_b^{(i)}\theta-y^{(i)})·X_n^{(i)} \end{pmatrix} ∇J(θ)=m2⎝⎜⎜⎜⎜⎜⎜⎛∑i=1m(Xb(i)θ−y(i))∑i=1m(Xb(i)θ−y(i))⋅X1(i)∑i=1m(Xb(i)θ−y(i))⋅X2(i)⋮∑i=1m(Xb(i)θ−y(i))⋅Xn(i)⎠⎟⎟⎟⎟⎟⎟⎞
对于这样一个式子我们可否再进行简化呢?
∇ J ( θ ) = 2 m ( ∑ i = 1 m ( X b ( i ) θ − y ( i ) ) ∑ i = 1 m ( X b ( i ) θ − y ( i ) ) ⋅ X 1 ( i ) ∑ i = 1 m ( X b ( i ) θ − y ( i ) ) ⋅ X 2 ( i ) ⋮ ∑ i = 1 m ( X b ( i ) θ − y ( i ) ) ⋅ X n ( i ) ) = 2 m ( ∑ i = 1 m ( X b ( i ) θ − y ( i ) ) ⋅ X 0 ( i ) ∑ i = 1 m ( X b ( i ) θ − y ( i ) ) ⋅ X 1 ( i ) ∑ i = 1 m ( X b ( i ) θ − y ( i ) ) ⋅ X 2 ( i ) ⋮ ∑ i = 1 m ( X b ( i ) θ − y ( i ) ) ⋅ X n ( i ) ) \nabla J(\theta)=\frac{2}{m} \begin{pmatrix} \sum_{i=1}^m(X_b^{(i)}\theta-y^{(i)}) \\ \sum_{i=1}^m(X_b^{(i)}\theta-y^{(i)})·X_1^{(i)} \\ \sum_{i=1}^m(X_b^{(i)}\theta-y^{(i)})·X_2^{(i)} \\ \vdots \\ \sum_{i=1}^m(X_b^{(i)}\theta-y^{(i)})·X_n^{(i)} \end{pmatrix} =\frac{2}{m} \begin{pmatrix} \sum_{i=1}^m(X_b^{(i)}\theta-y^{(i)})·X_0^{(i)} \\ \sum_{i=1}^m(X_b^{(i)}\theta-y^{(i)})·X_1^{(i)} \\ \sum_{i=1}^m(X_b^{(i)}\theta-y^{(i)})·X_2^{(i)} \\ \vdots \\ \sum_{i=1}^m(X_b^{(i)}\theta-y^{(i)})·X_n^{(i)} \end{pmatrix} ∇J(θ)=m2⎝⎜⎜⎜⎜⎜⎜⎛∑i=1m(Xb(i)θ−y(i))∑i=1m(Xb(i)θ−y(i))⋅X1(i)∑i=1m(Xb(i)θ−y(i))⋅X2(i)⋮∑i=1m(Xb(i)θ−y(i))⋅Xn(i)⎠⎟⎟⎟⎟⎟⎟⎞=m2⎝⎜⎜⎜⎜⎜⎜⎛∑i=1m(Xb(i)θ−y(i))⋅X0(i)∑i=1m(Xb(i)θ−y(i))⋅X1(i)∑i=1m(Xb(i)θ−y(i))⋅X2(i)⋮∑i=1m(Xb(i)θ−y(i))⋅Xn(i)⎠⎟⎟⎟⎟⎟⎟⎞
= 2 m ⋅ ( X b ( 1 ) θ − y ( 1 ) , X b ( 2 ) θ − y ( 2 ) , X b ( 3 ) θ − y ( 3 ) , ⋯ , X b ( m ) θ − y ( m ) ) ⋅ ( X 0 ( 1 ) X 1 ( 1 ) X 2 ( 1 ) ⋯ X n ( 1 ) X 0 ( 2 ) X 1 ( 2 ) X 2 ( 2 ) ⋯ X n ( 2 ) X 0 ( 3 ) X 1 ( 3 ) X 2 ( 3 ) ⋯ X n ( 3 ) ⋮ ⋮ ⋮ ⋮ ⋮ X 0 ( m ) X 1 ( m ) X 2 ( m ) ⋯ X n ( m ) ) =\frac{2}{m}·\begin{pmatrix} X_b^{(1)}\theta-y^{(1)}, & X_b^{(2)}\theta-y^{(2)}, & X_b^{(3)}\theta-y^{(3)}, \cdots, X_b^{(m)}\theta-y^{(m)} \end{pmatrix}· \begin{pmatrix} X_0^{(1)} & X_1^{(1)} & X_2^{(1)} & \cdots & X_n^{(1)} \\ X_0^{(2)} & X_1^{(2)} & X_2^{(2)} & \cdots & X_n^{(2)} \\ X_0^{(3)} & X_1^{(3)} & X_2^{(3)} & \cdots & X_n^{(3)} \\ \vdots & \vdots & \vdots & \vdots & \vdots \\ X_0^{(m)} & X_1^{(m)} & X_2^{(m)} & \cdots & X_n^{(m)} \end{pmatrix} =m2⋅(Xb(1)θ−y(1),Xb(2)θ−y(2),Xb(3)θ−y(3),⋯,Xb(m)θ−y(m))⋅⎝⎜⎜⎜⎜⎜⎜⎛X0(1)X0(2)X0(3)⋮X0(m)X1(1)X1(2)X1(3)⋮X1(m)X2(1)X2(2)X2(3)⋮X2(m)⋯⋯⋯⋮⋯Xn(1)Xn(2)Xn(3)⋮Xn(m)⎠⎟⎟⎟⎟⎟⎟⎞
= 2 m ⋅ ( X b θ − y ) T ⋅ X b =\frac{2}{m}·(X_b\theta-y)^T·X_b =m2⋅(Xbθ−y)T⋅Xb
这样就将原来的表达是转换成了一个 1 × m 1\times m 1×m 的矩阵乘以一个 m × ( n + 1 ) m \times (n+1) m×(n+1) 的矩阵,得到的是一个 1 × ( n + 1 ) 1 \times (n+1) 1×(n+1) 的向量,而这个矩阵就是我们所求的梯度。
而这个式子最终的结果是
2 m ⋅ ( X b θ − y ) T ⋅ X b \frac{2}{m}·(X_b\theta-y)^T·X_b m2⋅(Xbθ−y)T⋅Xb
这样得到的结果是一个行向量,为了后面方便计算,我们将其转化为一个列向量
( 2 m ⋅ ( X b θ − y ) T ⋅ X b ) T = 2 m ⋅ X b T ⋅ ( X b θ − y ) \bigl({\frac{2}{m}·(X_b\theta-y)^T·X_b}\bigr)^T=\frac{2}{m}·X_b^T·(X_b\theta-y) (m2⋅(Xbθ−y)T⋅Xb)T=m2⋅XbT⋅(Xbθ−y)
如此我们就可以将前面封装的d(theta, X_b, y)方法进行重新实现
def dJ(theta, x_b, y):
return x_b.T.dot(x_b.dot(theta) - y) * 2 / len(x_b)
相比之前的代码简化了许多,原来的for循环计算方式也改为了向量点乘运算,在性能上也得到了提升
2.3 波士顿房价预测(梯度下降法实现)
import numpy as np
from sklearn import datasets
boston = datasets.load_boston()
x = boston.data
y = boston.target
x = x[y < 50.0]
y = y[y < 50.0]
from model_selection import train_test_split
X_train, X_test, y_train, y_test= train_test_split(x,y,seed=666)
from LinearRegression import LinearRegression
lin_reg1 = LinearRegression()
lin_reg1.fit_nomal(X_train,y_train)
print(lin_reg1.score(X_test,y_test))
#********************运行结果****************************************
# 0.8129802602658653
当我们以多元线性回归法来做预测是,得分为0.8129802602658653,如果们以梯度下降算法来运行准确度是否回有所提升呢?
lin_reg2 = LinearRegression()
lin_reg2.fit_gd(X_train,y_train)
print(lin_reg2.score(X_test,y_test))
当我们满怀期待的去运行时,结果发现编译器报错,overflow encountered
打印theta值看一下结果
print(lin_reg2._theta)
#**************运行结果*****************
# [nan nan nan nan nan nan nan nan nan nan nan nan nan nan]
我们知道当学习的步长 η \eta η 取值过大时就会出现这种情况,默认情况下我们的eta值取值为0.01,那么我们将其设置为0.000001再看看结果:
lin_reg2 = LinearRegression()
lin_reg2.fit_gd(X_train,y_train,eta=0.000001)
print(lin_reg2.score(X_test,y_test))
#***********************运行结果***********************
# 0.27556634853389206
可以看到计算后的准确度才0.27,这显然是无法接受的,那我们在修改n_iterations这个参数,让其多计算几次,在查看下训练后的精度如何
lin_reg2 = LinearRegression()
lin_reg2.fit_gd(X_train,y_train,eta=0.000001,n_iterations=1e6)
print(lin_reg2.score(X_test,y_test))
#**********************运行结果**************************
# 0.7541852353980765
经过了漫长的等待我们终于得到了现在的精度0.754,相对于我们之前所使用的线性回归算法,其准确度依然不佳,那么我们如果再减小步长或者增加计算次数n_iterations,这样确实可以提高一定的准确度,可是相比较来说,计算的时间就显得漫长,那么问题到底处在哪里呢?
我们仔细来看一下这组数据
print(X_train[:10,:])
#***************************运行结果***********
#[[1.42362e+01 0.00000e+00 1.81000e+01 0.00000e+00 6.93000e-01 6.34300e+00
1.00000e+02 1.57410e+00 2.40000e+01 6.66000e+02 2.02000e+01 3.96900e+02
2.03200e+01]
[3.67822e+00 0.00000e+00 1.81000e+01 0.00000e+00 7.70000e-01 5.36200e+00
9.62000e+01 2.10360e+00 2.40000e+01 6.66000e+02 2.02000e+01 3.80790e+02
1.01900e+01]
[1.04690e-01 4.00000e+01 6.41000e+00 1.00000e+00 4.47000e-01 7.26700e+00
4.90000e+01 4.78720e+00 4.00000e+00 2.54000e+02 1.76000e+01 3.89250e+02
6.05000e+00]
[1.15172e+00 0.00000e+00 8.14000e+00 0.00000e+00 5.38000e-01 5.70100e+00
9.50000e+01 3.78720e+00 4.00000e+00 3.07000e+02 2.10000e+01 3.58770e+02
1.83500e+01]
[6.58800e-02 0.00000e+00 2.46000e+00 0.00000e+00 4.88000e-01 7.76500e+00
8.33000e+01 2.74100e+00 3.00000e+00 1.93000e+02 1.78000e+01 3.95560e+02
7.56000e+00]
[2.49800e-02 0.00000e+00 1.89000e+00 0.00000e+00 5.18000e-01 6.54000e+00
5.97000e+01 6.26690e+00 1.00000e+00 4.22000e+02 1.59000e+01 3.89960e+02
8.65000e+00]
[7.75223e+00 0.00000e+00 1.81000e+01 0.00000e+00 7.13000e-01 6.30100e+00
8.37000e+01 2.78310e+00 2.40000e+01 6.66000e+02 2.02000e+01 2.72210e+02
1.62300e+01]
[9.88430e-01 0.00000e+00 8.14000e+00 0.00000e+00 5.38000e-01 5.81300e+00
1.00000e+02 4.09520e+00 4.00000e+00 3.07000e+02 2.10000e+01 3.94540e+02
1.98800e+01]
[1.14320e-01 0.00000e+00 8.56000e+00 0.00000e+00 5.20000e-01 6.78100e+00
7.13000e+01 2.85610e+00 5.00000e+00 3.84000e+02 2.09000e+01 3.95580e+02
7.67000e+00]
[5.69175e+00 0.00000e+00 1.81000e+01 0.00000e+00 5.83000e-01 6.11400e+00
7.98000e+01 3.54590e+00 2.40000e+01 6.66000e+02 2.02000e+01 3.92680e+02
1.49800e+01]]
我们观察可以发现这组数据的范围跨度很大,从 1 0 − 2 到 1 0 2 10^{-2}到10^2 10−2到102,联系到我们之前所学习的数据归一化的知识我们知道,这样的未经过归一化的数据应该就是导致算法准确度不佳的原因了。
2.4 梯度下降算法与数据归一化
这里我们用Sklearn.preprocessing中的StandardScaler来对数据进行归一化处理:
from sklearn.preprocessing import StandardScaler
standard_scaler = StandardScaler()
standard_scaler.fit(X_train)
X_train_standard = standard_scaler.transform(X_train)
lin_reg3 = LinearRegression()
lin_reg3.fit_gd(X_train_standard,y_train)
# standard_scaler.fit(X_test)
X_test_standard = standard_scaler.transform(X_test)
res = lin_reg3.score(X_test_standard,y_test)
print(res)
#********************运行结果***************
# 0.8129880620122235
此时得到的结果与我们使用多元线性回归算法所得到的结果无异,显然已经符合我们的要求。
梯度下降相比多元线性回归的优势
import numpy as np
from timeit import timeit
m = 1000
n = 5000
big_X = np.random.normal(size=(m,n))
true_theta = np.random.uniform(0.0,100.0,size=n+1)
big_y = big_X.dot(true_theta[1:]) + true_theta[0] + np.random.normal(0.0,10.0,size=m)
from LinearRegression import LinearRegression
big_reg1 = LinearRegression()
def timereg1():
big_reg1.fit_nomal(big_X,big_y)
big_reg2 = LinearRegression()
def timereg2():
big_reg2.fit_gd(big_X,big_y)
t1 = timeit('timereg1()', 'from __main__ import timereg1',number=1)
t2 = timeit('timereg2()', 'from __main__ import timereg2',number=1)
print("使用正规方程解运行时间为",t1)
print("使用梯度下降算法运行时间为",t2)
#****************运行结果**********************
# 使用正规方程解运行时间为 11.050684344
# 使用梯度下降算法运行时间为 6.554695461
我们使用了一个有5000个特征的1000行数据比较两个算法的运行效率,结果发现,在样本特征较大的情况下,使用梯度下降算法更为有效
2.5 随机梯度下降
批量梯度下降的求解思路:
(1)将损失函数 J ( θ ) = 1 2 m ∑ i = 1 m ( y ( i ) − y ^ ( i ) ) 2 J(\theta) =\frac{1}{2m}\sum_{i=1}^m{(y^{(i)}-\hat{y}^{(i)})^2} J(θ)=2m1∑i=1m(y(i)−y^(i))2 对 θ \theta θ 求偏导,得到每个 θ \theta θ 对应的梯度。
(2)按 θ \theta θ 的负方向来更新 θ \theta θ
(3)迭代直至找到最优解
当我们每一次求解梯度时,我们用到了所有的训练数据,每迭代一次,在求解梯度就会耗费很多时间,当样本巨大时,这种时间成本显然是无法忍受的。
随机梯度下降算法的求解思路
在批量梯度下降算法中我们在计算梯度时使用的方法是
∇ J ( θ ) = 2 m ( ∑ i = 1 m ( X b ( i ) θ − y ( i ) ) ∑ i = 1 m ( X b ( i ) θ − y ( i ) ) ⋅ X 1 ( i ) ∑ i = 1 m ( X b ( i ) θ − y ( i ) ) ⋅ X 2 ( i ) ⋮ ∑ i = 1 m ( X b ( i ) θ − y ( i ) ) ⋅ X n ( i ) ) \nabla J(\theta)=\frac{2}{m} \begin{pmatrix} \sum_{i=1}^m(X_b^{(i)}\theta-y^{(i)}) \\ \sum_{i=1}^m(X_b^{(i)}\theta-y^{(i)})·X_1^{(i)} \\ \sum_{i=1}^m(X_b^{(i)}\theta-y^{(i)})·X_2^{(i)} \\ \vdots \\ \sum_{i=1}^m(X_b^{(i)}\theta-y^{(i)})·X_n^{(i)} \end{pmatrix} ∇J(θ)=m2⎝⎜⎜⎜⎜⎜⎜⎛∑i=1m(Xb(i)θ−y(i))∑i=1m(Xb(i)θ−y(i))⋅X1(i)∑i=1m(Xb(i)θ−y(i))⋅X2(i)⋮∑i=1m(Xb(i)θ−y(i))⋅Xn(i)⎠⎟⎟⎟⎟⎟⎟⎞
现在我们将其改为:
2 ( ( X b ( i ) θ − y ( i ) ) ( X b ( i ) θ − y ( i ) ) ⋅ X 1 ( i ) ( X b ( i ) θ − y ( i ) ) ⋅ X 2 ( i ) ⋮ ( X b ( i ) θ − y ( i ) ) ⋅ X n ( i ) ) 2 \begin{pmatrix} (X_b^{(i)}\theta-y^{(i)}) \\ (X_b^{(i)}\theta-y^{(i)})·X_1^{(i)} \\ (X_b^{(i)}\theta-y^{(i)})·X_2^{(i)} \\ \vdots \\ (X_b^{(i)}\theta-y^{(i)})·X_n^{(i)} \end{pmatrix} 2⎝⎜⎜⎜⎜⎜⎜⎛(Xb(i)θ−y(i))(Xb(i)θ−y(i))⋅X1(i)(Xb(i)θ−y(i))⋅X2(i)⋮(Xb(i)θ−y(i))⋅Xn(i)⎠⎟⎟⎟⎟⎟⎟⎞
为什么这样计算?直观的解释就是我们在m行数据中随机的取一个第i行数据,把它此时的梯度我们认为就是我们之前全局求解的那个梯度。这样做虽然不是每次迭代得到的损失函数都向着全局最优方向, 但是大的整体的方向是向全局最优解的,最终的结果往往是在全局最优解附近。
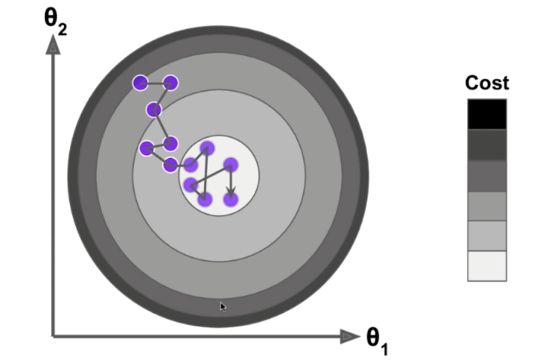
我们同样可以对上面的结果进行向量化:
2 ⋅ ( X b ( i ) ) T ⋅ ( X b ( i ) θ − y ( i ) ) 2·{(X_b^{(i)})}^T·(X_b^{(i)}\theta-y^{(i)}) 2⋅(Xb(i))T⋅(Xb(i)θ−y(i))
在随机梯度下降算法中我们需要特别注意的就是 η \eta η 的取值,如果 η \eta η 的取值一直是一个固定的值,那么如果当我们的算法已经迭代到最优解附近时,由于我们并不是按照下降最快的那条路径去寻找最优解,所以就会存在因为 η \eta η 值过大而又避开了最优解这样的情况出现,如何解决这样的问题,依照退火原理我们的一种做法就是随着迭代次数的增加, η \eta η 值不断减小,我们将其定义为:
η = b n _ i t e r a t i o n s + b \eta = \frac{b}{n\_iterations + b} η=n_iterations+bb
其中 a 、 b a、b a、b 也是两个超参数。
2.6 随机梯度下降法的实现
import numpy as np
from timeit import timeit
import matplotlib.pyplot as plt
m = 100000
x = np.random.normal(size=m)
X = x.reshape(-1,1)
y = 4. * x + 3. + np.random.normal(0,3,size=m)
def dJ_sgd(theta,x_b_i,y_i):
return x_b_i.T.dot(x_b_i.dot(theta) - y_i) * 2.
def sgd(X_b, y, initial_theta, n_iterations):
a = 5
b = 50
def learning_rate(t):
return a / (b + t)
theta = initial_theta
for cur_iterations in range(n_iterations):
rand_i = np.random.randint(len(x_b))
gradient = dJ_sgd(theta, x_b[rand_i], y[rand_i])
theta = theta - learning_rate(cur_iterations) * gradient
return theta
x_b = np.hstack([np.ones((len(X),1)),X])
initial_theta = np.zeros(x_b.shape[1])
def time_it():
theta = sgd(x_b, y, initial_theta, n_iterations=len(x_b)//3)
print(theta)
t1 = timeit('time_it()', 'from __main__ import time_it',number=1)
print(t1)
#**************************运行结果***********************
# [2.99397702 4.00149466]
# 0.4551753490000001
从结果我们可以看到,精度理想,而且运行效率也得到了显著提升。
2.7 波士顿房价预测(随机梯度下降法实现)
我们首先将2.6中的随机梯度下降算法进行封装
def fit_sgd(self,X_train,y_train,n_iterations=1e4,a=5,b=50):
"""根据训练数据集X_train训练 Linear Regression模型"""
assert X_train.shape[0] == y_train.shape[0], \
"the size of X_train must be equal to the size of y_train"
assert n_iterations >= 1
def dJ_sgd(theta, X_b_i, y_i):
return X_b_i.T.dot(X_b_i.dot(theta) - y_i) * 2.
def sgd(X_b, y, initial_theta, n_iterations,a=5,b=50):
def learning_rate(t):
return a / (b + t)
theta = initial_theta
m = len(X_b)
for cur_iterations in range(n_iterations):
indexes = np.random.permutation(m)
X_b_new = X_b[indexes]
y_new = y[indexes]
for i in range(m):
gradient = dJ_sgd(theta, X_b_new[i], y_new[i])
theta = theta - learning_rate(cur_iterations * m + i) * gradient
return theta
X_b = np.hstack([np.ones((len(X_train), 1)), X_train])
initial_theta = np.random.randn(X_b.shape[1])
self._theta = sgd(X_b, y_train,initial_theta,n_iterations,a,b)
self.interception_ = self._theta[0]
self.coef_ = self._theta[1:]
值得注意的是在封装fit_sgd这个方法的时候所传入的n_iterations的含义发生了改变,现在这个参数以为着我们对所有的数据整体遍历了几遍,所以我们添加了一个断言它必须大于1。为了确保每一个数据样本都能被模型所考虑到,所以我们进行了两层嵌套循环。
验证一下封装之后代码的正确性
import numpy as np
from LinearRegression import LinearRegression
m = 100000
x = np.random.normal(size=m)
X = x.reshape(-1,1)
y = 4. * x + 3. + np.random.normal(0,3,size=m)
reg = LinearRegression()
reg.fit_sgd(X,y,n_iterations=2)
print(reg.coef_)
print(reg.interception_)
#*******************运行结果***********************
# [4.00204626]
# 2.9768871417215963
下面我们使用波士顿房产数据运用随机梯度下降算法来验证我们算法的效果
from timeit import timeit
from sklearn import datasets
boston = datasets.load_boston()
x = boston.data
y = boston.target
x = x[y < 50.0]
y = y[y < 50.0]
from model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(x,y,seed=666)
from sklearn.preprocessing import StandardScaler
standardScaler = StandardScaler()
standardScaler.fit(X_train)
X_train_standard = standardScaler.transform(X_train)
X_test_standard = standardScaler.transform(X_test)
from LinearRegression import LinearRegression
lin_reg = LinearRegression()
def time_it():
lin_reg.fit_sgd(X_train_standard,y_train,n_iterations=2)
t = timeit('time_it()', 'from __main__ import time_it', number=1)
r_score = lin_reg.score(X_test_standard,y_test)
print(r_score)
print(t)
#***************运行结果**************
# 0.7865171620468298
# 0.0073522989999998956
之前我们使用正规方程解和批量梯度下降算法得到的R方值为0.81,然而我们现在得到的值为0.78,那么我们是不是可以通过增大n_iterations的值来提高R方值呢?
from timeit import timeit
from sklearn import datasets
boston = datasets.load_boston()
x = boston.data
y = boston.target
x = x[y < 50.0]
y = y[y < 50.0]
from model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(x,y,seed=666)
from sklearn.preprocessing import StandardScaler
standardScaler = StandardScaler()
standardScaler.fit(X_train)
X_train_standard = standardScaler.transform(X_train)
X_test_standard = standardScaler.transform(X_test)
from LinearRegression import LinearRegression
lin_reg = LinearRegression()
def time_it():
lin_reg.fit_sgd(X_train_standard,y_train,n_iterations=5)
t = timeit('time_it()', 'from __main__ import time_it', number=1)
r_score = lin_reg.score(X_test_standard,y_test)
print(r_score)
print(t)
#**************************运行结果*******************
# 0.8102377181989601
# 0.01804809599999979
正如我们所猜测的,确实可以通过提高遍历次数从而提高精确度。