利用Pyhthon实现语法分析器(实验报告)
1.概述
本次实验通过用python语言,设计,编制,调试一个词法分析子程序,识别单词,实现一个python语法分析器,经过此过程可以加深对编译器解释的过程。
1.1.实验目的
理解并掌握语法分析的原理与方法,能够使用某种语言实现语法分析程序。
1.2.实验描述
本实验中将C语言单词符号分为三类:关键字,运算符,界符,将关键字初始在KeyWord列表中,将界符初始在KeyAmbit列表中,将运算符初始在KeySimple列表中。因此,从原文件字符串中识别出关键字,界符,运算符只能从中选取,其他的可以归类为变量,数字,格式变量,格式符,存放到列表中,字典存放这些变量的位置,方便确认报错位置。
1.3.实验要求
1.输入词法分析输出的单词序列,判断单词序列构成的程序是否符合语法语法规则。
2.记录语法错误信息,统一输出错误信息。
2.实验内容
2.1.实验代码
__author__='PythonStriker'
KeySimple=['*','-','/','=','>','<','>=','==','<=','%','+','+=','-=','*=','/='] #词法分析器中分别运算符
KeyAmbit=['(',')',',',';','.','{','}','<','>','"','[',']',"'"] #词法分析器中分别界符
KeyWord=[ 'bool','char' ,'char[','class','define','double','false','float','getchar','include','int','iostream','long','main','null','open','printf',
'private','public','put','read','return','short','scanf','signed','static','stdio','string','struct','true',
'unsigned','void']
TypeKeyWord=['int','long','unsign','double','float','string','struct','char','void','bool','class','short'] #语法分析定义类型
FunctionKeyWord=['getchar','open','printf','put','read','return','scanf','main'] #语法分析功能类型
#------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
SourceProgram=[] #存放源程序代码
DeleteNote_SourceProgram=[] #存放去除注释源程序代码
Reader_SourceProgram=[] #存放类型判断后源程序
WordPositionList=[] #存放单词位置信息
#------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
ErrorList={} #语法分析器错误储存报表(存储报错位置和类型)
WordType={} #词法类型字典
WordPosition={} #定位关键字位置
#------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
Filepath='' #存放文件路径
#------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
LeftNoteFlag=0 #/*注释清除标记
RightNoteFlag=0 #*/注释清除标记
LeftBracketNumber=0 #成对界符的左标记
RighBracketNumber=0 #成对界符的右标记
NumberInString=0 #String中的下标
NumberinList=0 #List中的下标
#------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
class Assembly(): #封装成编译器
def IsLetter(self,Char):
if((Char<='z' and Char>='a') or( Char<='Z' and Char>='A') or Char=='_'):
return True
else:
return False
def IsNote(self,String): #判断注释类型
global LeftNoteFlag
global RightNoteFlag
NumberInString=0
for Char in String:
if(NumberInString='0'):
return True
else:
return False
def IsSpace(self,Char):
if(Char==' '):
return True
else:
return False
def PassSpace(self,List): #清除字符串中前后的空格
NumberinList=0
for String in List:
List[NumberinList]=String.strip()
NumberinList+=1
return List
def DeleteNote(self,List): #删除列表中的注释『'//'或者'/* */'』
global LeftNoteFlag
global RightNoteFlag
RemoveList=[]
ResultList=List
FirstLeftNoteNumber=0
NumberinList=0
LeftNoteNumber=0
for String in ResultList:
Flag=self.IsNote(String)
NumberInString=0
FirstLeftNoteNumber=0
if(Flag):
for Char in String:
if(NumberInString'):
if(List[NumberinList-3] in KeyAmbit or List[NumberinList-4] in KeyWord):
WordType.setdefault('分界符',[]).append(String)
elif(String=='.'):
if(List[NumberinList].isdigit() and List[NumberinList-2].isdigit()):
WordType.setdefault('运算符',[]).append(String)
else:
WordType.setdefault('分界符',[]).append(String)
elif(String in KeySimple):
if(String=='%'):
if(not(List[NumberinList].isdigit())):
WordType.setdefault('格式符',[]).append(String)
FormatFlag=1
continue
WordType.setdefault('运算符',[]).append(String)
else:
if(String.isdigit()):
WordType.setdefault('数字',[]).append(String)
elif(String.isalnum()):
if(FormatFlag==0):
WordType.setdefault('变量',[]).append(String)
else:
WordType.setdefault('格式变量',[]).append(String)
FormatFlag=0
else:
if(String in KeyWord):
WordType.setdefault('关键字',[]).append(String)
elif(String in KeySimple):
WordType.setdefault('运算符',[]).append(String)
else:
if(String.isdigit() or '.' in String):
WordType.setdefault('数字',[]).append(String)
elif(String.isalnum()):
if(FormatFlag==0):
WordType.setdefault('变量',[]).append(String)
else:
WordType.setdefault('格式变量',[]).append(String)
FormatFlag=0
def KeyWordPosition(self,HandleList,DivisionList): #参数为源程序列表和分割关键词后的列表,记录位置方便报错
global WordPosition
global WordPositionList
for ListIdex in range(len(HandleList)):
SameFlag=-1 #防止下标为0开始,匹配不上
Word=''
for StringIndex in range(len(HandleList[ListIdex])):
if(HandleList[ListIdex][StringIndex]==' '):
pass
else:
Word+=HandleList[ListIdex][StringIndex]
if(Word in DivisionList):
if(SameFlag!=StringIndex):
WordPosition.setdefault(Word,[]).append([ListIdex,StringIndex])
SameFlag=StringIndex
Word=''
else:
Word=''
continue
for key,value in WordPosition.items():
WordPositionList.append([key,value])
def BracketError(self,DivisionList): #括号匹配函数
global WordType
global WordPosition
lLeftBracketNumber=0
lRighBracketNumber=0
bLeftBracketNumber=0
bRighBracketNumber=0
sLeftBracketNumber=0
sRighBracketNumber=0
for String in DivisionList:
if(String=='('):
lLeftBracketNumber+=1
elif(String==')'):
lRighBracketNumber+=1
elif(String=='['):
bLeftBracketNumber+=1
elif(String==']'):
bRighBracketNumber+=1
elif(String=='{'):
sLeftBracketNumber+=1
elif(String=='}'):
sRighBracketNumber+=1
if(lLeftBracketNumber!=lRighBracketNumber):
if(lLeftBracketNumber>lRighBracketNumber):
print('括号不匹配,缺少右小括号,尝试匹配此处括号:'+str(WordPosition.get('(')[lLeftBracketNumber-1][0])+'行'+str(WordPosition.get('(')[lLeftBracketNumber-1][1])+'列')
else:
print('括号不匹配,缺少左小括号,尝试匹配此处括号或者删除:'+str(WordPosition.get(')')[lRighBracketNumber-1][0])+'行'+str(WordPosition.get('(')[lRighBracketNumber-1][1])+'列')
elif(bLeftBracketNumber!=bRighBracketNumber):
if(bLeftBracketNumber>bRighBracketNumber):
print('括号不匹配,缺少右中括号,尝试匹配此处括号:'+str(WordPosition.get('[')[bLeftBracketNumber-1][0])+'行'+str(WordPosition.get('[')[bLeftBracketNumber-1][1])+'列')
else:
print('括号不匹配,缺少左中括号,尝试匹配此处括号或者删除:'+str(WordPosition.get(']')[bRighBracketNumber-1][0])+'行'+str(WordPosition.get(']')[bRighBracketNumber-1][1])+'列')
elif(sLeftBracketNumber!=sRighBracketNumber):
if(sLeftBracketNumber>sRighBracketNumber):
print('括号不匹配,缺少右大括号,尝试匹配此处括号:'+str(WordPosition.get('{')[sLeftBracketNumber-1][0])+'行'+str(WordPosition.get('{')[sLeftBracketNumber-1][1])+'列')
else:
print('括号不匹配,缺少左大括号,尝试匹配此处括号或者删除:'+str(WordPosition.get('}')[sRighBracketNumber-1][0])+'行'+str(WordPosition.get('}')[sRighBracketNumber-1][1])+'列')
def AllKindOfError(self,DivisionList):
global WordPosition
global WordPositionList
global WordType
WordTypeList=[]
for value,key in WordType.items():
WordTypeList.append([value,key])
for Index in range(len(DivisionList)-1):
CountNumber=-1
if(DivisionList[Index]=='#'):
if(DivisionList[Index+1]!='define' and DivisionList[Index+1]!='include'):
for Word in DivisionList[0:Index+1]:
if(Word=='#'):
CountNumber+=1
print('宏定义错误,错误位置:'+str(WordPosition.get('#')[CountNumber][0]+1)+'行'+str(WordPosition.get(DivisionList[Index])[CountNumber][1])+'列')
elif(DivisionList[Index] in TypeKeyWord):
if((DivisionList[Index+1] not in WordType.get('变量') and (DivisionList[Index+1] not in KeyAmbit)) and (DivisionList[Index+1] not in FunctionKeyWord)):
for Word in DivisionList[0:Index+1]:
if(Word==DivisionList[Index]):
CountNumber+=1
print('定义错误,错误位置:'+str(WordPosition.get(DivisionList[Index])[CountNumber][0]+1)+'行'+str(WordPosition.get(DivisionList[Index])[CountNumber][1])+'列')
elif(DivisionList[Index] in WordType.get('变量')):
if(DivisionList[Index+1]!='=' and DivisionList[Index+1] not in KeyAmbit):
for Word in DivisionList[0:Index+1]:
if(Word==DivisionList[Index]):
CountNumber+=1
print('变量错误,错误位置:'+str(WordPosition.get(DivisionList[Index])[CountNumber][0]+1)+'行'+str(WordPosition.get(DivisionList[Index])[CountNumber][1])+'列')
elif(DivisionList[Index] in WordType.get('运算符')):
if((DivisionList[Index+1] not in WordType.get('数字')) and (DivisionList[Index+1] not in WordType.get('变量'))):
for Word in DivisionList[0:Index+1]:
if(Word==DivisionList[Index]):
CountNumber+=1
print('数据错误,错误位置:'+str(WordPosition.get(DivisionList[Index])[CountNumber][0]+1)+'行'+str(WordPosition.get(DivisionList[Index])[CountNumber][1])+'列')
elif(DivisionList[Index] in WordType.get('数字')):
if((DivisionList[Index+1] not in KeySimple) and (DivisionList[Index+1] not in KeyAmbit)):
for Word in DivisionList[0:Index+1]:
if(Word==DivisionList[Index]):
CountNumber+=1
print('数据错误,错误位置:'+str(WordPosition.get(DivisionList[Index])[CountNumber][0]+1)+'行'+str(WordPosition.get(DivisionList[Index])[CountNumber][1])+'列')
elif(DivisionList[Index] in WordType.get('格式符')):
if((DivisionList[Index+1] not in WordType.get('格式变量'))):
for Word in DivisionList[0:Index+1]:
if(Word==DivisionList[Index]):
CountNumber+=1
print('格式错误,错误位置:'+str(WordPosition.get(DivisionList[Index])[CountNumber][0]+1)+'行'+str(WordPosition.get(DivisionList[Index])[CountNumber][1])+'列')
elif(DivisionList[Index] in WordType.get('格式变量')):
if((DivisionList[Index+1] not in WordType.get('格式变量'))):
for Word in DivisionList[0:Index+1]:
if(Word==DivisionList[Index]):
CountNumber+=1
print('格式错误,错误位置:'+str(WordPosition.get(DivisionList[Index])[CountNumber][0]+1)+'行'+str(WordPosition.get(DivisionList[Index])[CountNumber][1])+'列')
elif(DivisionList[Index] in FunctionKeyWord):
if((DivisionList[Index+1] not in KeyAmbit) and (DivisionList[Index+1] not in WordType.get('数字'))):
for Word in DivisionList[0:Index+1]:
if(Word==DivisionList[Index]):
CountNumber+=1
print('方法错误,错误位置:'+str(WordPosition.get(DivisionList[Index])[CountNumber][0]+1)+'行'+str(WordPosition.get(DivisionList[Index])[CountNumber][1])+'列')
self.BracketError(DivisionList)
def main():
global Reader_SourceProgram
global DeleteNote_SourceProgram
global SourceProgram
global Filepath
global WordPosition
global WordType
AsseMbly=Assembly()
Filepath=input("请输入文件路径:")
for line in open(Filepath,'r',encoding='GB2312'):
line=line.replace('\n','')
SourceProgram.append(line)
print("源程序:")
for line in SourceProgram:
print(line)
DeleteNote_SourceProgram=AsseMbly.DeleteNote(SourceProgram)
DeleteNote_SourceProgram=AsseMbly.PassSpace(DeleteNote_SourceProgram)
Reader_SourceProgram=AsseMbly.Reader(DeleteNote_SourceProgram)
AsseMbly.JugeMent(Reader_SourceProgram)
AsseMbly.KeyWordPosition(DeleteNote_SourceProgram,Reader_SourceProgram)
print("\n处理后程序:")
for line in DeleteNote_SourceProgram:
print(line)
AsseMbly.AllKindOfError(Reader_SourceProgram)
if __name__ == "__main__":
main()
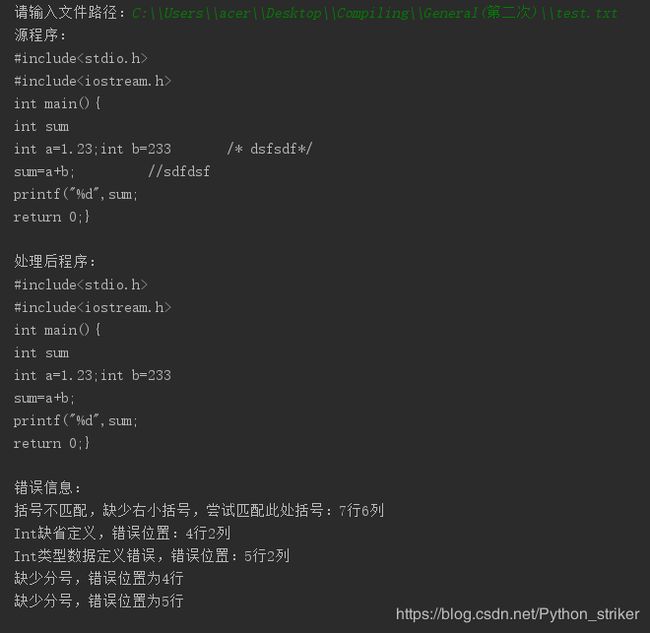
2.2.测试数据
nclude
#include
int main(){
int sum
int a=1.23;int b=233 /* dsfsdf*/
sum=a+b; //sdfdsf
printf("%d",sum;
return 0;} ps:该数据应放在txt文档中。
2.3测试结果