利用Rstudio对考试成绩进行数据分析
首先导入数据到Rstudio中
使用read.csv()函数
scores
nrow(scores)[1] 599
ncol(scores)[1] 12
在scores的所有列中,num和class两列与成绩没有太大的关系,我们可以将其去掉,也可以保留
如果要去掉的话:
生成一个新的数据框,把num和class去掉:
scores1<-as.data.frame(scores[,c('chn','math','eng','phy','chem','politics','bio','history','geo','pe')])或:
scores1<-as.data.frame(scores[,3:12])然后分别给scores和scores1两个数据框各添加一列,总分sum:
scores$sum<-apply(scores[,3:12],1,sum)scores1$sum<-apply(scores1,1,sum)其中apply()函数中的1代表对行,2代表对列
结果:
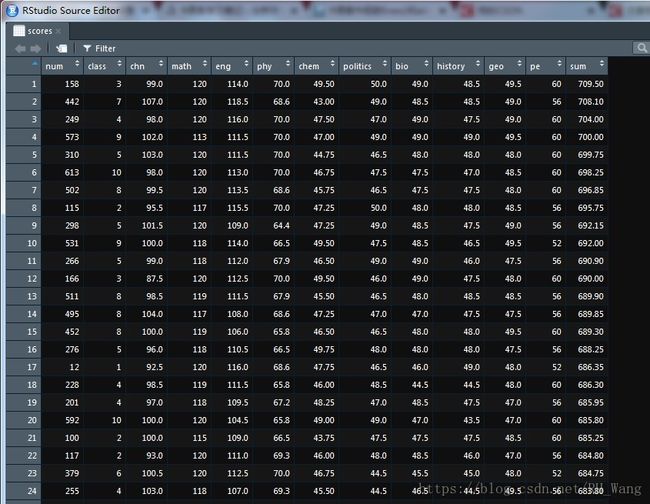
可以发现原始数据其实是根据其中没有的总分来排列的
看一下描述性统计量数据:
summary(scores[,3:13])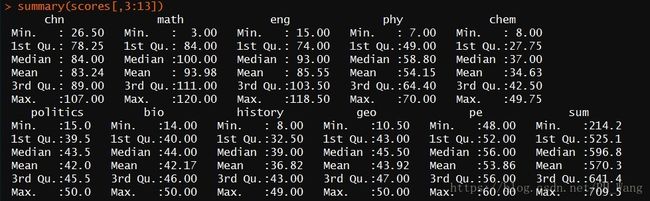
对于sum这个变量,可以看到极差为:
attach(scores)
max(sum)-min(sum)[1] 495.3
看一看sum值的分布情况:
hist(scores$sum,freq=F,breaks=50)
lines(density(scores$sum),col='red',lwd=2)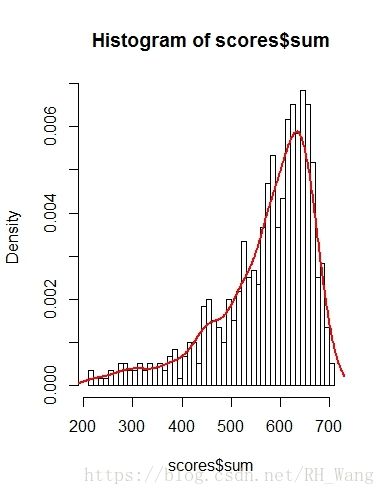
上图在sum分布直方图上添加了其核密度曲线,可以看到sum的分布情况
使用ggplot2实现:
library(ggplot2)
ggplot(scores,aes(sum,..density..))+geom_histogram(fill='darkgray')+geom_density(color='red')+ggtitle('Histogram with Density of SUM')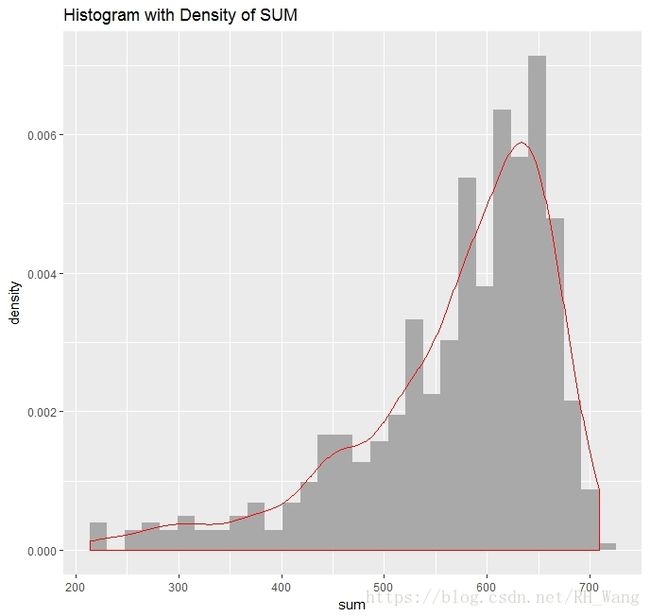
接下来考察一下各科目间的相关性,以数学为例,在使用cor()函数计算相关系数之前,我先来猜测一下,数学与物理、化学和生物的相关性比较大
cor(scores[,3:12])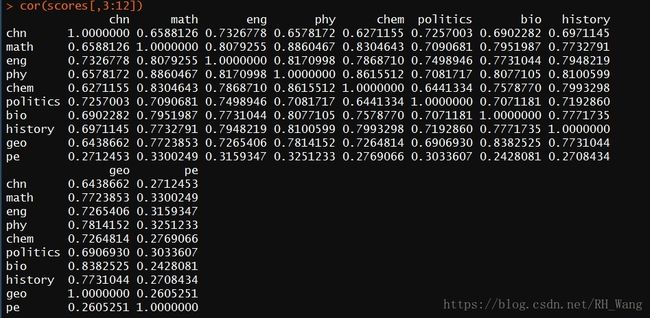
观察math的一列可以发现,相关系数超过0.8的科目有三个,分别是英语,物理和化学,和我的猜测有些出入。
接下来使用lm()函数拟合线性回归模型
mathfit<-lm(math~.,data=scores[,3:12])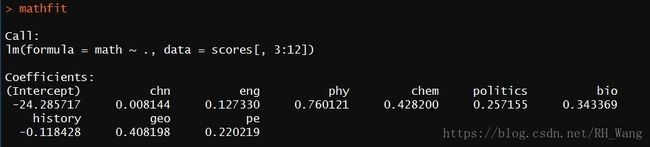
在拟合的模型中可以看到系数最大的是phy(0.760),其次是chem(0.428),第三是geo(0.408)
所以可以从对这个样本的分析中得出一个初步的结论:在多元线性回归模型中,数学成绩与物理成绩的相关程度最高,也就是说对于多数学生而言,数学成绩高则物理成绩高,反之亦然。这与我们日常的认识是一致的。
而对于其他科目,与数学成绩的相关性就没有那么高,尽管可能有联系,但是相比于物理成绩而言要稍微弱一些。
有了一个回归模型之后,就需要对回归模型进行评价
首先使用confint()函数查看置信区间
confint(mathfit,level=0.95)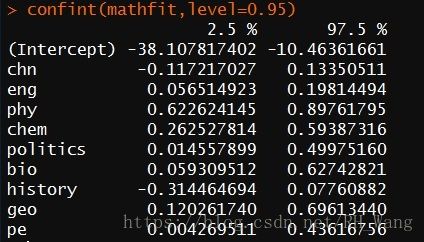
在结论中可以看到:
1、chn和history成绩的置信区间包含0,则可以得出结论:当其他变量不变时,chn和history成绩的改变与math成绩无关
2、其余变量每改变1%,math成绩就在95%的置信区间里变化
例:eng成绩每改变1%,math成绩就在95%的置信区间[0.057,0.198]中变化
回归诊断的一个标准方法是使用基本包中的plot()函数生成评价模型拟合情况的四幅图形
plot(mathfit)就得到了以下的四幅图:
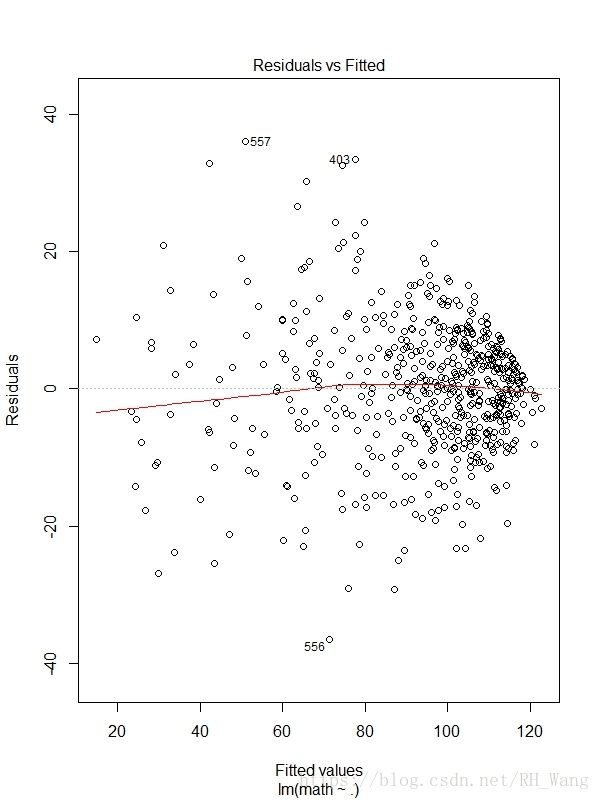
1,Residuals & Fitted(残差与拟合图):若变量与自变量线性相关,那么残差值与预测值就没有任何系统关联
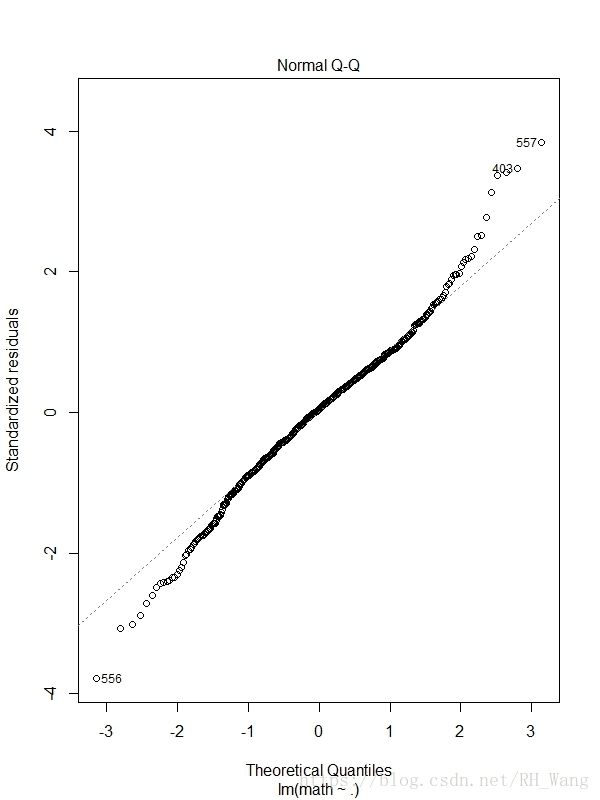
2,Normal Q-Q(正态Q-Q图):在正态分布对应的值下,标准化残差的概率图。若满足正态假设,那么图上的点应落在呈45°角的直线上,否则不满足正态假设。(正态假设:当预测变量固定式,因变量成正态分布,则残差值也应该是一个均值为零的正态分布)
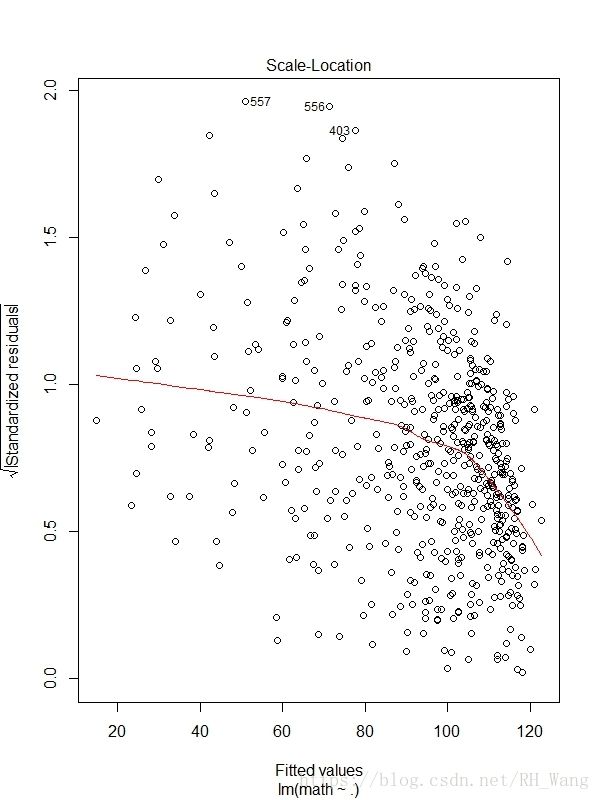
3, Scale-Location Graph(位置尺度图):表示标准化残差的开方与拟合值的残差图。若满足不变方差假设,则在该图中,曲线周围的点应该随机分布
4, Residuals vs Leverage(残差与杠杆图):从图形可以鉴别出离群点、高杠杆值点和强影响点
