DT大数据梦工厂Spark定制班笔记(009)
Spark Streaming源码解读之Receiver在Driver的精妙实现全生命周期彻底研究和思考
在经过了一系列的有关Spark Streaming Job的考察之后,我们把目光转向Receiver。
Spark Streaming中ReceiverInputDStream都是现实一个Receiver,用来接收数据。而Receiver可以有很多个,并且运行在不同的worker节点上。这些Receiver都是由ReceiverTracker来管理的。
ReceiverTracker的start方法如下(ReceiverTracker.scala 152-164行)
def start(): Unit = synchronized { if (isTrackerStarted) { throw new SparkException("ReceiverTracker already started") } if (!receiverInputStreams.isEmpty) { endpoint = ssc.env.rpcEnv.setupEndpoint( "ReceiverTracker", new ReceiverTrackerEndpoint(ssc.env.rpcEnv)) if (!skipReceiverLaunch) launchReceivers() logInfo("ReceiverTracker started") trackerState = Started } }
它首先实例化一个消息通信体ReceiverTrackerEndpoint,然后调用launchReceivers(ReceiverTracker.scala 436-447行).
private def launchReceivers(): Unit = { val receivers = receiverInputStreams.map { nis => val rcvr = nis.getReceiver() rcvr.setReceiverId(nis.id) rcvr } runDummySparkJob() logInfo("Starting " + receivers.length + " receivers") endpoint.send(StartAllReceivers(receivers)) }它的巧妙之处在于会先运行 runDummySparkJob(),从而获得集群中Executor的情况。
然后向消息通信体发送StartAllReceivers消息。
消息通信体收到消息后的处理过程如下所示(ReceiverTracker.scala 468-475行)
case StartAllReceivers(receivers) => val scheduledLocations = schedulingPolicy.scheduleReceivers(receivers, getExecutors) for (receiver <- receivers) { val executors = scheduledLocations(receiver.streamId) updateReceiverScheduledExecutors(receiver.streamId, executors) receiverPreferredLocations(receiver.streamId) = receiver.preferredLocation startReceiver(receiver, executors) }
在这里我们需要展示一下函数startReceiver中一处精妙的实现 (ReceiverTracker.scala 605-611行)
val receiverRDD: RDD[Receiver[_]] = if (scheduledLocations.isEmpty) { ssc.sc.makeRDD(Seq(receiver), 1) } else { val preferredLocations = scheduledLocations.map(_.toString).distinct ssc.sc.makeRDD(Seq(receiver -> preferredLocations)) }
在这里Receiver被封装成了RDD!(所以Receiver必须是可以序列化的)
并被提交到集群中运行。(ReceiverTracker.scala 616行)
val future = ssc.sparkContext.submitJob[Receiver[_], Unit, Unit]( receiverRDD, startReceiverFunc, Seq(0), (_, _) => Unit, ())
在任务被提交到worker节点后,执行如下操作。(receiverTracker.scala 585-602行)
// Function to start the receiver on the worker node val startReceiverFunc: Iterator[Receiver[_]] => Unit = (iterator: Iterator[Receiver[_]]) => { if (!iterator.hasNext) { throw new SparkException( "Could not start receiver as object not found.") } if (TaskContext.get().attemptNumber() == 0) { val receiver = iterator.next() assert(iterator.hasNext == false) val supervisor = new ReceiverSupervisorImpl( receiver, SparkEnv.get, serializableHadoopConf.value, checkpointDirOption) supervisor.start() supervisor.awaitTermination() } else { // It's restarted by TaskScheduler, but we want to reschedule it again. So exit it. } }此处创建了一个ReceiverSupervisorImpl对象;用来管理具体的Receiver。
它首先会将Receiver注册到ReceiverTracker中 (ReceiverSupervisor.scala 182-186行)
override protected def onReceiverStart(): Boolean = { val msg = RegisterReceiver( streamId, receiver.getClass.getSimpleName, host, executorId, endpoint) trackerEndpoint.askWithRetry[Boolean](msg) }
注册成功后,启动receiver。(ReceiverSupervisor.scala 144-159行)
def startReceiver(): Unit = synchronized { try { if (onReceiverStart()) { logInfo(s"Starting receiver $streamId") receiverState = Started receiver.onStart() logInfo(s"Called receiver $streamId onStart") } else { // The driver refused us stop("Registered unsuccessfully because Driver refused to start receiver " + streamId, None) } } catch { case NonFatal(t) => stop("Error starting receiver " + streamId, Some(t)) } }
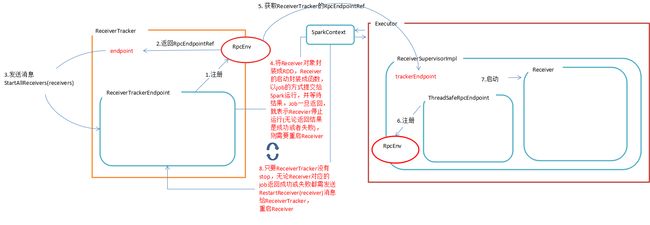
上述过程如下图所示 转自http://lqding.blog.51cto.com/9123978/1773912 感谢作者!