DT大数据梦工厂Spark定制班笔记(008)
Spark Streaming源码解读之RDD生成全生命周期彻底研究和思考
DStream是RDD的模板,每隔一个batchInterval会根据DStream模板生成一个对应的RDD。然后将RDD存储到DStream中的generatedRDDs数据结构中。
DStream.scala(86行)
private[streaming]vargeneratedRDDs =newHashMap[Time, RDD[T]]()
用于分析RDD生成的示例代码
val
lines
=
ssc.socketTextStream(
"localhost"
,
9999
)
val
words
=
lines.flatMap(
_
.split(
" "
))
val
pairs
=
words.map(word
=
> (word,
1
))
val
wordCounts
=
pairs.reduceByKey(
_
+
_
)
wordCounts.print()
DStream中Print的实现如下(DStream.scala 731-746行)
def print(num: Int): Unit = ssc.withScope { def foreachFunc: (RDD[T], Time) => Unit = { (rdd: RDD[T], time: Time) => { val firstNum = rdd.take(num + 1) // scalastyle:off println println("-------------------------------------------") println(s"Time: $time") println("-------------------------------------------") firstNum.take(num).foreach(println) if (firstNum.length > num) println("...") println() // scalastyle:on println } } foreachRDD(context.sparkContext.clean(foreachFunc), displayInnerRDDOps = false) }其中foreachRDD的实现如下(DStream.scala 650-655行)
private def foreachRDD( foreachFunc: (RDD[T], Time) => Unit, displayInnerRDDOps: Boolean): Unit = { new ForEachDStream(this, context.sparkContext.clean(foreachFunc, false), displayInnerRDDOps).register() }核心部分是实例化ForEachDStream并将其注册(register)到DStreamGraph中。
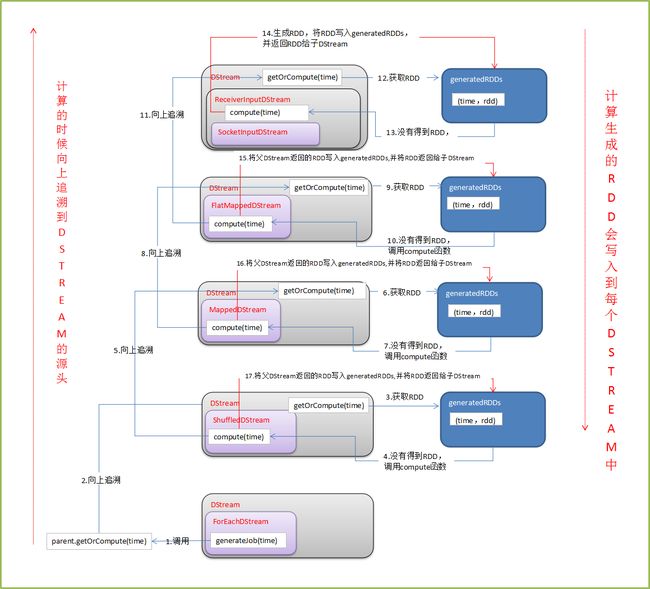
ForEachDStream是DStream的子类,并且实现了generateJob函数(ForEachStream.scala 47-56行)。
override def generateJob(time: Time): Option[Job] = { parent.getOrCompute(time) match { case Some(rdd) => val jobFunc = () => createRDDWithLocalProperties(time, displayInnerRDDOps) { foreachFunc(rdd, time) } Some(new Job(time, jobFunc)) case None => None } }回顾第5讲的内容,generateJob会在DStreamGraph启动是被调用,从而触发一系列追溯DStream,生成RDD的操作。
详情如下图所示 (图来自http://lqding.blog.51cto.com/9123978/1773398 感谢作者!)