机器学习 - LDA 主题模型简单实践
不讨论数学推导,只讨论调用一些封装好的类库,简单应用。
什么是主题
因为LDA是一种主题模型,那么首先必须明确知道LDA是怎么看待主题的。对于一篇新闻报道,我们看到里面讲了昨天NBA篮球比赛,那么用大腿想都知道它的主题是关于体育的。为什么我们大腿会那么聪明呢?这时大腿会回答因为里面出现了“科比”、“湖人”等等关键词。那么好了,我们可以定义主题是一种关键词集合,如果另外一篇文章出现这些关键词,我们可以直接判断他属于某种主题。但是,亲爱的读者请你想想,这样定义主题有什么弊端呢?按照这种定义,我们会很容易给出这样的条件:一旦文章出现了一个球星的名字,那么那篇文章的主题就是体育。可能你马上会骂我在瞎说,然后反驳说不一定,文章确实有球星的名字,但是里面全部在讲球星的性丑闻,和篮球没半毛钱关系,此时主题是娱乐还差不多。所以一个词不能硬性地扣一个主题的帽子,如果说一篇文章出现了某个球星的名字,我们只能说有很大概率他属于体育的主题,但也有小概率属于娱乐的主题。于是就会有这种现象:同一个词,在不同的主题背景下,它出现的概率是不同的。并且我们都可以基本确定,一个词不能代表一种主题,那么到底什么才是主题呢?耐不住性子的同学会说,既然一个词代表不了一种主题,那我就把所有词都用来代表一种主题,然后你自己去慢慢意会。没错,这样确实是一种完全的方式,主题本来就蕴含在所有词之中,这样确实是最保险的做法,但是你会发现这样等于什么都没做。老奸巨猾的LDA也是这么想的,但他狡猾之处在于它用非常圆滑手段地将主题用所有词汇表达出来。怎么个圆滑法呢?手段便是概率。LDA认为天下所有文章都是用基本的词汇组合而成,此时假设有词库V={v1,v2,....,vn}V={v1,v2,....,vn},那么如何表达主题kk呢?LDA说通过词汇的概率分布来反映主题!多么狡猾的家伙。我们举个例子来说明LDA的观点。假设有词库
文章在讲什么
给你一篇文章读,然后请你简要概括文章在讲什么,你可能会这样回答:80%在讲政治的话题,剩下15%在讲娱乐,其余都是废话。这里大概可以提炼出三种主题:政治,娱乐,废话。也就是说,对于某一篇文章,很有可能里面不止在讲一种主题,而是几种主题混在一起的。读者可能会问,LDA是一种可以从文档中提炼主题模型,那他在建模的时候有没有考虑这种情形啊,他会不会忘记考虑了。那您就大可放心了,深谋远虑的LDA早就注意到这些了。LDA认为,文章和主题之间并不一定是一一对应的,也就是说,文章可以有多个主题,一个主题可以在多篇文章之中。这种说法,相信读者只能点头称是。假设现在有KK个主题,有MM篇文章,那么每篇文章里面不同主题的组成比例应该是怎样的呢?由于上一小节我们知道不能硬性的将某个词套上某个主题,那么这里我们当然不能讲某个主题套在某个文章中,也就是有这样的现象:同一个主题,在不同的文章中,他出现的比例(概率)是不同的,看到这里,读者可能已经发现,文档和主题之间的关系和主题和词汇的关系是多么惊人的类似!LDA先人一步地将这一发现说出来,它说,上一节我们巧妙地用词汇的分布来表达主题,那么这一次也不例外,我们巧妙地用主题的分布来表达文章!同样,我们举个例子来说明一下,假设现在有两篇文章:
也就是说,一篇文章在讲什么,通过不同的主题比例就可以概括得出。
(以上两段注释源于博客)
我这里首先是要建立一个小小语料库,一共是六个文件,里面是我找的一些 各个主题类型的文章(文章量很小,只是简单应用) ,以及停用词表,主要是去除一些影响分析的停用词,如 :的 、 吗 、等等无意义的影响分析的文字符号和词语
# /usr/bin/env python
# -*- coding: utf-8 -*-
# @Time : 18-4-11 下午5:25
# @Author : 杨星星
# @Email : [email protected]
# @File : Lda_plt.py
# @Software: PyCharm
import numpy as np
import pandas as pd
import re
import os
import jieba
import matplotlib.pyplot as plt
import pprint
from gensim import corpora, models, similarities
# 取出停用词
def get_stop_words(file_name):
with open(file_name,'r') as file:
return set([line.strip() for line in file])
# 取出语料库
def readfile(path):
fp = open(path, "r")
content = fp.read()
fp.close()
return content
# 语料路径
corpus_path = r"/home/python/Spiderjs/Data_jieba/file_text" # 未分词分类语料
stop_file_path=r"/home/python/Spiderjs/Data_jieba/china_stop_word.txt" # 停用词的文件
#获取每个目录下的所有文件
catelist = os.listdir(corpus_path)
# print(catelist)
stop_words=get_stop_words(stop_file_path)
train_set=[]
for mydir in catelist:
class_path = corpus_path +'/'+ mydir # 拼出未分词的目录
# print(class_path)
content = readfile(class_path).strip()
content = content.replace("\n", '').replace("(", '').replace(")", '') # 删除掉换行和其他干扰因素
content_seg = list(jieba.cut(content, cut_all=True)) # jieba 分词
train_set.append([item for item in content_seg if str(item) not in stop_words]) # 剔除停用词
print('分词结束')
num_topics = 5 # 设置的主题数目
# 构建模型 用词袋的方法,把每个单词用一个数字index指代,并把我们的原文本变成一条长长的数组
dic = corpora.Dictionary(train_set)
# 根据字典,将每行文档都转换为索引的形式
corpus = [dic.doc2bow(text) for text in train_set]
# 现在对每篇文档中的每个词都计算tf-idf值
tfidf = models.TfidfModel(corpus)
corpus_tfidf = tfidf[corpus]
lda = models.LdaModel(corpus_tfidf, id2word = dic, num_topics = num_topics,alpha=1) #lda模型
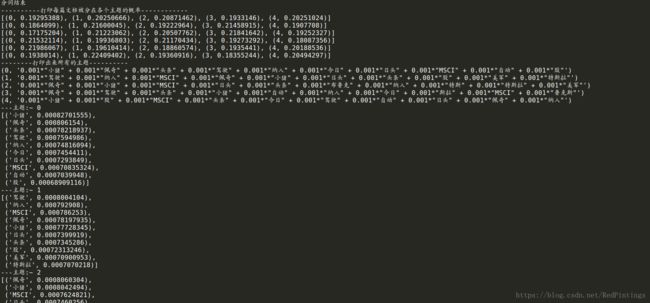
# 打印一下每篇文档被分在各个主题的概率:
print('----------打印每篇文档被分在各个主题的概率------------')
corpus_lda = lda[corpus_tfidf]
for corpus_lda_ in corpus_lda:
print(corpus_lda_)
# 打印出来所有的主题
print('--------打印出来所有的主题----------')
datas = lda.print_topics(num_topics=5, num_words=10)
for data in datas:
print(data)
# 打印每个主题中每个词出现的频率
for topic_id in range(num_topics):
print ('---主题:~', topic_id)
# 打印python 数据结构
pprint.pprint(lda.show_topic(topic_id))
# 画图
# thetas=[lda[c] for c in corpus_tfidf]
# plt.hist([len(t) for t in thetas], np.arange(10))
# plt.ylabel('Nr of documents')
# plt.xlabel('Nr of topics')
# plt.show()
# 给定一个新的文档
print('------------给定一个新的文档资料-----------')
new_doc_list = []
new_doc_path = "/home/python/Spiderjs/Data_jieba/news_doc/new_doc_001"
with open(new_doc_path,'r') as f:
content = f.read()
content = content.replace("\n", '').replace("(", '').replace(")", '').replace('', '') # 删除掉换行和其他干扰因素
test_doc = list(jieba.cut(content, cut_all=True)) #新文档进行分
new_doc_list.append([item for item in test_doc if str(item) not in stop_words]) # 剔除停用词
# print(test_doc) # 根据字典,将每行文档都转换为索引的形式
doc_bow = dic.doc2bow(new_doc_list[0]) # 文档转换成bow (词袋模型)
doc = lda.get_document_topics(doc_bow) # 分类成某个主题的概率
print(doc)
# 新文档的词的分布情况 向量
# doc_lda = lda[doc_bow]
# for doc_ in doc_bow:
# print(doc_)
我这里预料少,只是例子简单应用,结果也是辣眼睛,如果用大量的语料去训练 效果应该不错