【PyTorch学习笔记】13:使用Visdom可视化训练-测试过程
在PyTorch的可视化中,相比tensorboardX,Visdom更简洁方便一些(例如对image数据的可视化可以直接使用Tensor,而不必转到cpu上再转为numpy数据),刷新率也更快。
安装Visdom
直接用pip安装的话在windows上面可能出现问题,先从Github上下载Visdom的源码,进入解压后的目录,执行:
pip install -e .
即从当前目录下的setup.py安装了Visdom。
测试一下Visdom能不能正常使用,另开一个CMD,运行:
python -m visdom.server
除了可能看到一些warning信息之外,正常运行时是这样的:
It's Alive!
INFO:root:Application Started
You can navigate to http://localhost:8097
访问http://localhost:8097:

可视化训练-测试过程
步骤简述
先开启上面的Visdom服务器。在上节学习的自定义网络实现MNIST分类的代码基础上,添加一些Visdom可视化的内容。
在最前面导入Visdom:
from visdom import Visdom
这一步因为是从外部安装的Visdom,可能PyCharm里会出红线,但是不影响导入和使用的。
在训练-测试的迭代过程之前,定义两条曲线,这里相当于是占位,在训练-测试的过程中再不断填充点以实现曲线随着训练动态增长:
viz = Visdom()
viz.line([0.], [0.], win='train_loss', opts=dict(title='train loss'))
viz.line([[0.0, 0.0]], [0.], win='test', opts=dict(title='test loss&acc.',
legend=['loss', 'acc.']))
这里第一步可以提供参数env='xxx'来设置环境窗口的名称,这里什么都没传,所以是在默认的main窗口下。
第二第三步的viz.line的前两个参数是曲线的Y和X的坐标(前面是纵轴后面才是横轴),这里为了占位所以都设置了0(实际上为Loss初始Y值设置为0的话,在图中刚开始的地方会有个大跳跃有点难看,因为Loss肯定是从大往小了走的)。为它们设置了不同的win参数,它们就会在不同的窗口中展示,因为第三步定义的是测试集的loss和acc两条曲线,所以在X等于0时Y给了两个初始值。
为了知道训练了多少个batch了,紧接着设置一个全局的计数器:
global_step = 0
在每个batch训练完后,为训练曲线添加点,来让曲线实时增长:
global_step += 1
viz.line([loss.item()], [global_step], win='train_loss', update='append')
注意这里用win参数来选择是哪条曲线,用update='append'的方式添加曲线的增长点,前面是Y坐标,后面是X坐标。
在每次测试结束后,并在另外两个窗口(用win参数设置)中展示图像(.images)和真实值(文本用.text):
viz.line([[test_loss, correct / len(test_loader.dataset)]],
[global_step], win='test', update='append')
viz.images(data.view(-1, 1, 28, 28), win='x')
viz.text(str(pred.detach().cpu().numpy()), win='pred',
opts=dict(title='pred'))
代码
这里直接贴课程老师提供的代码了,不在自己跟着写的代码上面改了:
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
from torchvision import datasets, transforms
from visdom import Visdom
batch_size = 200
learning_rate = 0.01
epochs = 10
train_loader = torch.utils.data.DataLoader(
datasets.MNIST('../data', train=True, download=True,
transform=transforms.Compose([
transforms.ToTensor(),
# transforms.Normalize((0.1307,), (0.3081,))
])),
batch_size=batch_size, shuffle=True)
test_loader = torch.utils.data.DataLoader(
datasets.MNIST('../data', train=False, transform=transforms.Compose([
transforms.ToTensor(),
# transforms.Normalize((0.1307,), (0.3081,))
])),
batch_size=batch_size, shuffle=True)
class MLP(nn.Module):
def __init__(self):
super(MLP, self).__init__()
self.model = nn.Sequential(
nn.Linear(784, 200),
nn.LeakyReLU(inplace=True),
nn.Linear(200, 200),
nn.LeakyReLU(inplace=True),
nn.Linear(200, 10),
nn.LeakyReLU(inplace=True),
)
def forward(self, x):
x = self.model(x)
return x
device = torch.device('cuda:0')
net = MLP().to(device)
optimizer = optim.SGD(net.parameters(), lr=learning_rate)
criteon = nn.CrossEntropyLoss().to(device)
viz = Visdom()
viz.line([0.], [0.], win='train_loss', opts=dict(title='train loss'))
viz.line([[0.0, 0.0]], [0.], win='test', opts=dict(title='test loss&acc.',
legend=['loss', 'acc.']))
global_step = 0
for epoch in range(epochs):
for batch_idx, (data, target) in enumerate(train_loader):
data = data.view(-1, 28 * 28)
data, target = data.to(device), target.cuda()
logits = net(data)
loss = criteon(logits, target)
optimizer.zero_grad()
loss.backward()
# print(w1.grad.norm(), w2.grad.norm())
optimizer.step()
global_step += 1
viz.line([loss.item()], [global_step], win='train_loss', update='append')
if batch_idx % 100 == 0:
print('Train Epoch: {} [{}/{} ({:.0f}%)]\tLoss: {:.6f}'.format(
epoch, batch_idx * len(data), len(train_loader.dataset),
100. * batch_idx / len(train_loader), loss.item()))
test_loss = 0
correct = 0
for data, target in test_loader:
data = data.view(-1, 28 * 28)
data, target = data.to(device), target.cuda()
logits = net(data)
test_loss += criteon(logits, target).item()
pred = logits.argmax(dim=1)
correct += pred.eq(target).float().sum().item()
viz.line([[test_loss, correct / len(test_loader.dataset)]],
[global_step], win='test', update='append')
viz.images(data.view(-1, 1, 28, 28), win='x')
viz.text(str(pred.detach().cpu().numpy()), win='pred',
opts=dict(title='pred'))
test_loss /= len(test_loader.dataset)
print('\nTest set: Average loss: {:.4f}, Accuracy: {}/{} ({:.0f}%)\n'.format(
test_loss, correct, len(test_loader.dataset),
100. * correct / len(test_loader.dataset)))
运行结果:
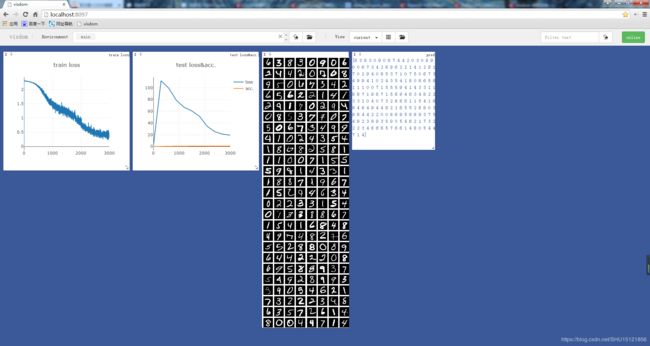
参考阅读
老师的代码里用到了.detach(),并把数据搬到了CPU上,这样才能展示出来。
PyTorch中 tensor.detach() 和 tensor.data 的区别
Pytorch 中的detach 和detach_