集成学习综述-从决策树到XGBoost
本文及其它机器学习、深度学习算法的全面系统讲解可以阅读《机器学习与应用》,清华大学出版社,雷明著,由SIGAI公众号作者倾力打造,自2019年1月出版以来已重印3次。
- 书的购买链接
- 书的勘误,优化,源代码资源
在之前缅怀金大侠的文章“永远的金大侠-人工智能的江湖”中提到:集成学习是机器学习中一种特殊的存在,自有其深厚而朴实的武功哲学,能化腐朽为神奇,变弱学习为强学习,虽不及武当和少林那样内力与功底深厚。其门下两个主要分支-Bagging和Boosting,各有成就,前者有随机森林支撑门面,后者有AdaBoost,GBDT,XGBoost一脉传承。门下弟子近年来在Kaggle大赛中获奖无数,体现了实用主义的风格,为众多习武之人所喜爱,趋之若鹜。
集成学习(ensemble learning)是机器学习里一个重要、庞大的分支,它体现了一种朴素的哲学思想:
将一些简单的机器学习模型组合起来使用,可以得到一个强大的模型
即使每个简单的模型能力很弱,预测精度非常低,但组合起来之后,精度得到了显著的提升,可以和其他类型的强模型相媲美。在这里,我们称简单的模型为弱学习器(weak learner),组合起来后形成的模型为强学习器(strong learner)。
这种做法在我们的日常生活中随处可见,比如集体投票决策,这种手段可以让我们做出更准确的决策。在机器学习领域,这种做法也获得了成功,理论分析和实验结果、实践经验证明,集成学习是有效的。
决策树很多情况下,集成学习的若学习器使用决策树(但也不是绝对的)。因为决策树实现简单,计算效率高。在SIGAI之前的公众号文章“理解决策树”中已经介绍了决策树的原理。决策树是一种基于规则的方法,它用一组嵌套的规则进行预测。在树的每个决策节点处,根据判断结果进入一个分支,反复执行这种操作直到到达叶子节点,得到预测结果。这些规则通过训练得到,而不是人工制定的。在各种机器学习算法中,决策树是非常贴近人的思维的方法,具有很强的可解释性。
决策树的预测算法很简单,从根节点开始,在树的每个节点处,用特征向量中的一个分量与决策树节点的判定阈值进行比较,然后决定进入左子节点还是右子节点。反复执行这种操作,直到到达叶子节点处,叶子节点中存储着类别值(对分类问题)或者回归值(对回归问题),作为预测结果。
训练时,递归的建立树,从根节点开始。用每个节点的训练样本集进行分裂,寻找一个最佳分裂,作为节点的判定规则。同时把训练样本集一分为二,用两个子集分别训练左子树和右子树。
目前已经有多种决策树的实现,包括ID3[1,2],C4.5[3],CART(Classification and Regression Tree,分类与回归树)[4]等,它们的区别主要在于树的结构与构造算法。其中分类与回归树既支持分类问题,也可用于回归问题,在集成学习中使用的最广。
分类树的映射函数是对多维空间的分段线性划分,即用平行于各坐标轴的超平面对空间进行切分;回归树的映射函数是分段常数函数。只要划分的足够细,分段常数函数可以逼近闭区间上任意函数到任意指定精度,因此决策树在理论上可以对任意复杂度的数据进行拟合。关于决策树的详细原理可以阅读SIGAI之前的公众号文章《理解决策树》。
集成学习前面已经说过,集成学习(ensemble learning)通过多个机器学习模型的组合形成一个精度更高的模型,参与组合的模型称为弱学习器(weak learner)。在预测时使用这些弱学习器模型联合进行预测,训练时需要用训练样本集依次训练出这些弱学习器。
根据训练各个弱学习器的不同思路,目前广为使用的有两种方案:
Bagging和Boosting(Stacking在这里不做介绍)
前者通过对原始训练样本集进行随机抽样,形成不同的训练样本集来训练每个弱学习器,各个弱学习器之间可以认为近似是独立的,典型代表是随机森林;后者为训练样本增加权重(AdaBoost),或者构造标签值(GBDT)来依次训练每个弱学习器,各个弱学习器之间相关,后面的弱学习器利用了前面的弱学习器的信息。下面分别对这两类算法进行介绍。
Bagging-随机抽样训练每个弱学习器Bagging的核心思想是对训练样本集进行抽样,形成新的训练样本集,以此训练各个弱学习器。由于每个弱学习器使用了不同的样本集,因此各不相同。预测时,用每个弱学习器分别进行预测,然后投票。在这里,每个弱学习器的地位是相等的。
随机森林-独立学习,平等投票Bagging的典型代表是随机森林,由Breiman等人提出[5],它由多棵决策树组成。预测时,对于分类问题,一个测试样本会送到每一棵决策树中进行预测,然后投票,得票最多的类为最终分类结果。对于回归问题随机森林的预测输出是所有决策树输出的均值。
训练时,使用bootstrap抽样来构造每个弱学习器的训练样本集。这种抽样的做法是在n个样本的集合中有放回的抽取n个样本形成一个数据集。在新的数据集中原始样本集中的一个样本可能会出现多次,也可能不出现。随机森林在训练时依次训练每一棵决策树,每棵树的训练样本都是从原始训练集中进行随机抽样得到。在训练决策树的每个节点时所用的特征也是随机抽样得到的,即从特征向量中随机抽出部分特征参与训练。即随机森林对训练样本和特征向量的分量都进行了随机采样。
正是因为有了这些随机性,随机森林可以在一定程度上消除过拟合。对样本进行采样是必须的,如果不进行采样,每次都用完整的训练样本集训练出来的多棵树是相同的。随机森林使用多棵决策树联合进行预测可以降低模型的方差。随机深林的介绍请阅读SIGAI之前的文章《随机森林概述》
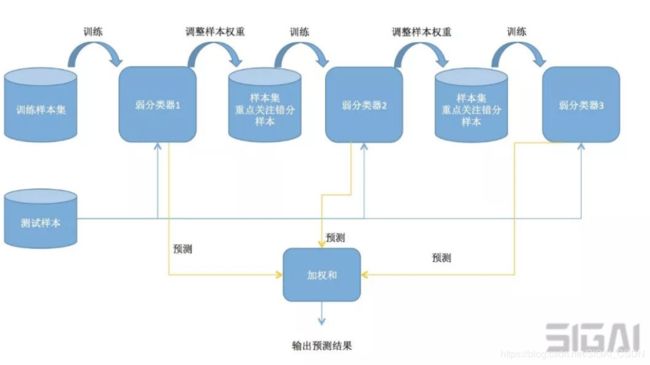
Boosting-串行训练每个弱学习器Boosting算法(提升)采用了另外一种思路。预测时用每个弱学习器分别进行预测,然后投票得到结果;训练时依次训练每个弱学习器,但不是对样本进行独立的随机抽样构造训练集,而是重点关注被前面的弱学习器错分的样本。
AdaBoost-吸取前人的教训,能者多“劳”Boosting作为一种抽象框架很早就被提出[6],但一直没有很好的具体实现。AdaBoost算法(Adaptive Boosting,自适应Boosting)由Freund等人提出[7-11],是Boosting算法的一种实现版本。在最早的版本中,这种方法的弱分类器带有权重,分类器的预测结果为弱分类器预测结果的加权和。训练时训练样本具有权重,并且会在训练过程中动态调整,被前面的弱分类器错分的样本会加大权重,因此算法会更关注难分的样本。2001年级联的AdaBoost分类器被成功用于人脸检测问题,此后它在很多模式识别问题上得到了应用。
基本的AdaBoost算法是一种二分类算法,用弱分类器的线性组合构造强分类器。弱分类器的性能不用太好,仅比随机猜测强,依靠它们可以构造出一个非常准确的强分类器。强分类器的计算公式为:
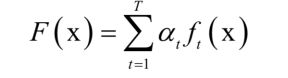
其中x是输入向量,F(x)是强分类器, 是弱分类器, 是弱分类器的权重,T为弱分类器的数量,弱分类器的输出值为+1或-1,分别对应正样本和负样本。分类时的判定规则为:
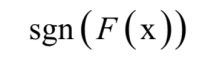
强分类器的输出值也为+1或-1。弱分类器、重通过训练算法得到。
训练时,依次训练每一个弱分类器,并得到它们的权重值。训练样本也带有权重值,初始时所有样本的权重相等,在训练过程中,被前面的弱分类器错分的样本会加大权重,反之会减小权重,这样接下来的弱分类器会更加关注这些难分的样本。弱分类器的权重值根据它的准确率构造,精度越高的弱分类器权重越大。
给定l个训练样本( , ),其中是特征向量,为类别标签,其值为+1或-1。训练算法的流程为:
初始化样本权重值,所有样本的初始权重相等:
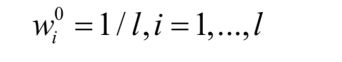
循环,对t=1,...,T依次训练每个弱分类器:
训练一个弱分类器 ,并计算它对训练样本集的错误率
计算弱分类器的权重:
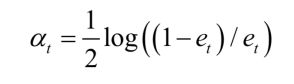
更新所有样本的权重:
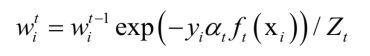
其中 为归一化因子,它是所有样本的权重之和:
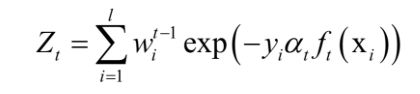
结束循环
最后得到强分类器:
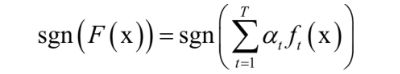
根据计算公式,错误率低的弱分类器权重大,它是准确率的增函数。AdaBoost训练和预测算法的原理可以阅读SIGAI之前的公众号文章“大话AdaBoost算法”,“理解AdaBoost算法”。AdaBoost算法的核心思想是:
关注之前被错分的样本,准确率高的弱分类器有更大的权重
文献[12]用广义加法模型[6]和指数损失函数解释了AdaBoost算法的优化目标,并推导出其训练算法。广义加法模型用多个基函数的加权组合来表示要拟合的目标函数。
AdaBoost算法采用了指数损失函数,强分类器对单个训练样本的损失函数为:
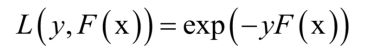
将广义加法模型的预测函数代入上面的损失函数中,得到算法训练时要优化的目标函数为:
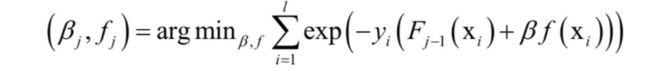
这里将指数函数拆成了两部分,已有的强分类器 ,以及当前弱分类器f对训练样本的损失函数,前者在之前的迭代中已经求出,因此可以看成常数。这样目标函数可以简化为:
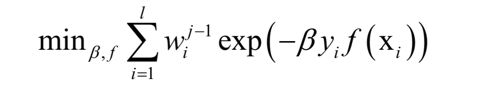
其中:
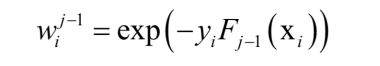
它只和前面的迭代得到的强分类器有关,与当前的弱分类器、弱分类器权重无关,这就是样本权重。这个问题可以分两步求解,首先将β看成常数,优化弱分类器。得到弱分类器f()之后,优化目标可以表示成β的函数,然后优化β。
文献[12]还介绍了四种类型的AdaBoost算法[7],它们的弱分类器不同,训练时优化的目标函数也不同。
离散型AdaBoost算法就是之前介绍的AdaBoost算法,从广义加法模型推导出了它的训练算法。它用牛顿法求解加法logistic回归模型。
实数型AdaBoost算法弱分类器的输出值是实数值,它是向量到实数的映射。这个实数的绝对值可以看作是置信度,它的值越大,样本被判定为正样本的可信度越高。
广义加性模型没有限定损失函数的具体类型,离散型和实数型AdaBoost采用的是指数损失函数。如果把logistic回归的损失函数应用于此模型,可以得到LogitBoost的损失函数:
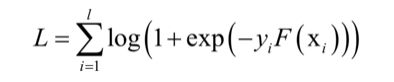
LogitBoost用牛顿法优化logistic回归的对数似然函数。
Gentle型AdaBoost的弱分类器是回归函数,和实数型AdaBoost类似。
标准的AdaBoost算法只能用于二分类问题,它的改进型可以用于多类分类问题[8],典型的实现有AdaBoost.MH算法,多类Logit型AdaBoost。AdaBoost.MH通过二分类器的组合形成多分类模型,采用了一对多的方案。多类Logit型AdaBoost采用了类似于softmax回归的方案。另外,AdaBoost还可以用于回归问题,即AdaBoost.R算法。
与随机森林不同,AdaBoost算法的目标主要是降低模型的偏差。文献[14]从分类间隔的角度对AdaBoost优良的泛化性能进行了解释。已经证明,AdaBoost算法在训练样本集上的误差随着弱分类器的增加呈指数级下降。
AdaBoost算法在模式识别中最成功的应用之一是机器视觉里的目标检测问题,如人脸检测和行人检测。在2001年Viola和Jones设计了一种人脸检测算法[13]。它使用简单的Haar特征和级联AdaBoost分类器构造检测器,检测速度较之前的方法有2个数量级的提高,并且有很高的精度。VJ框架是人脸检测历史上有里程碑意义的一个成果,奠定了AdaBoost目标检测框架的基础。
GBDT-接力合作,每一杆都更靠近球洞和AdaBoost算法类似,GBDT(Gradient Boosting Decision Tree,梯度提升树)[15]也是提升算法的一种实现,将决策树用于梯度提升框架,依次训练每一棵决策树。GBDT同样用加法模型表示预测函数,求解时采用了前向拟合。强学习器的预测函数为

其中l为训练样本数。这里采样了逐步求精的思想,类似于打高尔夫球,先粗略的打一杆,然后在之前的基础上逐步靠近球洞。具体的思路类似于梯度下降法,将强学习器的输出值看做一个变量,损失函数L对其求导,将已经求得的强学习器的输出值 带入导数计算公式,得到在这一点的导数值,然后取反,得到负梯度方向,当前要求的弱学习器的输入值如果为这个值,则损失函数的值是下降的。
由此得到训练当前弱学习器时样本的标签值为。
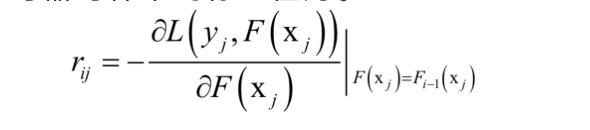
用样本集(, )训练当前的弱学习器,注意,样本标签值由已经求得的强学习器决定。
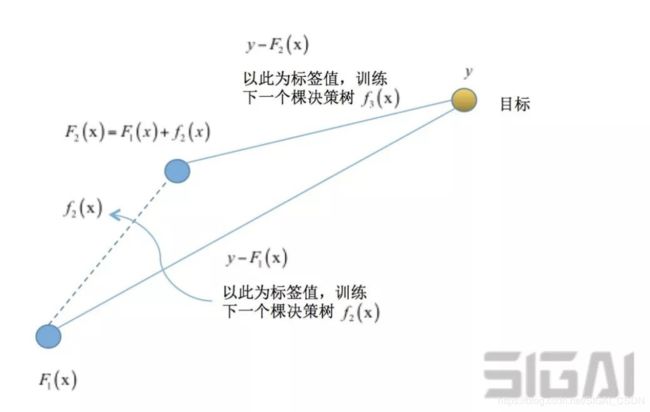
如果损失函数使用均方误差,则负梯度即为残差,这一般用于回归问题。
对于二分类问题,如果用logistic回归的对数似然函数做损失函数

对于多分类问题,使用交叉熵损失函数,可以得到类似的结果。
得到样本的标签值之后,就可以训练当前的决策树(弱学习器)。GBDT用损失函数对预测函数的负梯度值作为训练样本的标签值(目标值),训练当前的决策树,然后更新强学习器。
XGBoost-显式正则化,泰勒展开到二阶XGBoost[16]是对梯度提升算法的改进。XGBoost对损失函数进行了改进,由两部分构成,第一部分为梯度提升算法的损失函数,第二部分为正则化项

参考文献
[1] J. Ross Quinlan. Induction of decision trees. Machine Learning, 1986, 1(1): 81-106.
[2] J. Ross Quinlan. Learning efficient classification procedures and their application to chess end games. 1993.
[3] J. Ross Quinlan. C4.5: Programs for Machine Learning. Morgan Kaufmann, San Francisco, CA, 1993.
[4] Breiman, L., Friedman, J. Olshen, R. and Stone C. Classification and Regression Trees, Wadsworth, 1984.
[5] Breiman, Leo. Random Forests. Machine Learning 45 (1), 5-32, 2001.
[6] Robert E Schapire. The Strength of Weak Learnability. Machine Learning, 1990.
[7] Freund, Y. Boosting a weak learning algorithm by majority. Information and Computation, 1995.
[8] Yoav Freund, Robert E Schapire. A decision-theoretic generalization of on-line learning and an application to boosting. computational learning theory. 1995.
[9] Freund, Y. An adaptive version of the boost by majority algorithm. In Proceedings of the Twelfth Annual Conference on Computational Learning Theory, 1999.
[10] R.Schapire. The boosting approach to machine learning: An overview. In MSRI Workshop on Nonlinear Estimation and Classification, Berkeley, CA, 2001.
[11] Freund Y, Schapire RE. A short introduction to boosting. Journal of Japanese Society for Artificial Intelligence, 14(5):771-780. 1999.
[12] Jerome Friedman, Trevor Hastie and Robert Tibshirani. Additive logistic regression: a statistical view of boosting. Annals of Statistics 28(2), 337–407. 2000.
[13] P.Viola and M.Jones. Rapid object detection using a boosted cascade of simple features. In Proceedings IEEE Conf. on Computer Vision and Pattern Recognition, 2001.
[14] Robert E Schapire, Yoav Freund, Peter L Bartlett, Wee Sun Lee. Boosting the margin: a new explanation for the effectiveness of voting methods. Annals of Statistics, 1998.
[15] Jerome H Friedman. Greedy function approximation: A gradient boosting machine. Annals of Statistics, 2001.
[16] Tianqi Chen, Carlos Guestrin. XGBoost: A Scalable Tree Boosting System. knowledge discovery and data mining, 2016.
[17] Guolin Ke, Qi Meng, Thomas Finley, Taifeng Wang, Wei Chen, Weidong Ma, Qiwei Ye, Tieyan Liu. LightGBM: A Highly Efficient Gradient Boosting Decision Tree. neural information processing systems, 2017.