基于深度学习的细粒度图像分类综述
SIGAI特约作者
卢宪凯
上海交通大学在读博士
1.简介
细粒度图像分类 (Fine-grained image categorization), 又被称作子类别图像分类 (Sub-category recognition),是近年来计算机视觉、 模式识别等领域一个非常热门的研究课题。 其目的是对属于同一基础类别的图像(汽车、狗、花、鸟等)进行更加细致的子类划分, 但由于子类别间细微的类间差异以及较大的类内差异, 较之普通的图像分类任务, 细粒度图像分类难度更大。 图1所示为细粒度图像分类数据集CUB-200[1]中的两个物种,加州鸥和北极鸥,从竖直方向的图片对比可以看出,两个不同物种长相非常相似,而从对比水平方向可知,同一物种由于姿态,背景以及拍摄角度的不同,存在较大的类内差异。 因此,要想顺利的对两个极为相似的物种进行细粒度分类,最重要的是在图像中找到能够区分这两个物种的区分性的区域块(discriminative part),并能够对这些有区分性的区域块的特征进行较好的表示。

由于深度卷积网络能够学习到非常鲁棒的图像特征表示,对图像进行细粒度分类的方法,大多都是以深度卷积网络为基础的,这些方法大致可以分为以下四个方向:
- 基于常规图像分类网络的微调方法
- 基于细粒度特征学习(fine-grained feature learning)的方法
- 基于目标块的检测(part detection)和对齐(alignment)的方法
- 基于视觉注意机制(visualattention)的方法
2.基于常规图像分类网络的方法
这一类方法大多直接采用常见的深度卷积网络来直接进行图像细粒度分类,比如AlexNet[3]、VGG[4]、GoogleNet[5]、ResNet[6]以及DenseNet[7]和 SENet[8] 等。
由于这些分类网络具有较强的特征表示能力,因此在常规图像分类中能取得较好的效果。然而在细粒度分类中,不同物种之间的差异其实十分细微,因此,直接将常规的图像分类网络用于对细粒度图像的分类,效果并不理想。受迁移学习理论启发,一种方法是将大规模数据上训练好的网络迁移到细粒度分类识别任务中来。常用的解决方法是采用在ImageNet上预训练过的网络权值作为初始权值,然后再通过在细粒度分类数据集上对网络的权值进行微调(finetune),得到最终的分类网络。
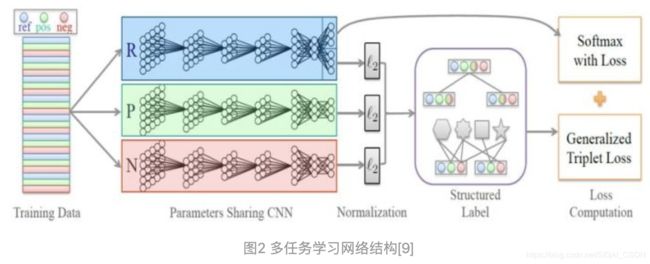
在[9]中,Zhang等人进一步将度量损失函数引入到精细分类网络的微调中来。具体而言,每次输入三个样本(Postive,Reference以及Negative)到三个共享权值的网络中,然后利用三个网络的特征输出用来计算损失函数,除了传统的softmax 损失函数,三个特征输出还构成了广义的triplet 损失。最后两个损失函数联合用来微调网络:
![]()
其中, 是softmax获取的分类误差,E_{s}(r)是通过图2中三个共享参数的子网络 ,f_{r}(s)和f_{r}(s)获取到的triplet误差,两种误差实现对网络不同层次的约束。E_{s}(r)通过图像的类别信息,约束网络参数的优化方向是在图像真实类别上获取最大的响应,这其中并没有关注不同类别之间的度量关系。而E_{t}(r,p,n)则通过计算类内距离与类间距离,增大网络对不同类别的相似样本的识别能力。
3. 基于细粒度特征学习的方法
Lin等人在2015年发表于ICCV的论文[9]中提出双线性卷积神经网络模型(Bilinear CNN,网络结构如图3所示)实现对深度卷积特征更好的表示。该方法使用VGG-D和VGG-M两个网络作为基准网络,在不使用Bounding Box (边框)标注信息的情况下,在CUB200-2011数据集上到达了84.1%的分类精度;而使用Bounding Box时,其分类精度高达85.1%。
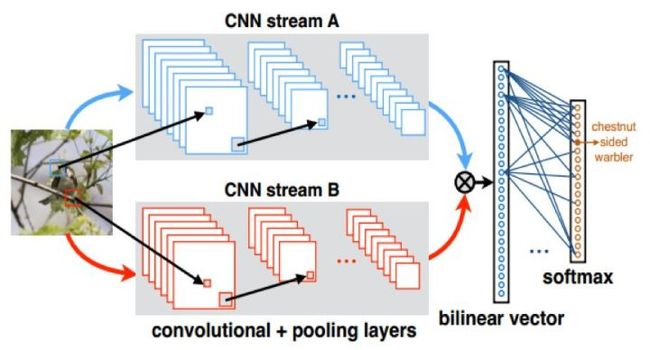
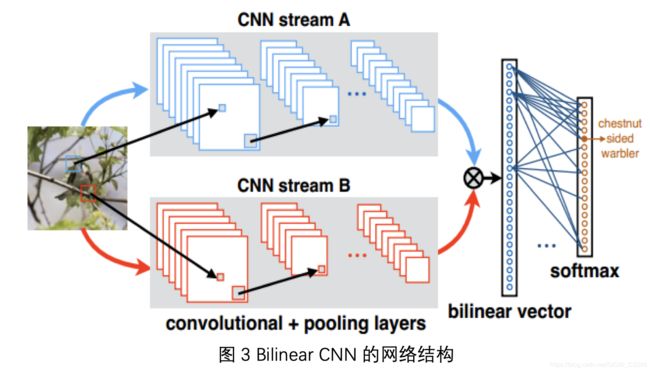
一个双线性模型 M 由一个四元组组成: M = ( ; P; C)。其中,fA和fB代表特征提取函数, 即图 3 中的卷积网络 A和卷积网络 B, P 是一个池化函数 (Pooling function),C 则是分类函数。
特征提取函数 f(·) (CNN stream)由卷积层,池化层和激活函数组成。这一部分网络结构可以看作一个函数映射f:L x I →RK×D, 将输入图像与位置区域 映射为一个维的特征,其中K为卷积网络输出特征图的通道数,D为每个通道中的二维特征图展开成的一维特征向量的大小。而两个特征提取函数输出的卷积特征, 可以通过一个双线性操作进行汇聚, 得到一个双线性特征:bilinear(l;T;f_{A};f_{B}) = (L;T (L;T)。而池化函数 P 的作用则是将所有位置的双线性特征汇聚成一个特征。文章所采用的池化函数是将所有位置的双线性特征累加起来,得到图像的全局特征表示Φ'(I)。
![]()
如果两个特征函数fA,fB 提取的特征维度分别是 K × M 与K ×N 的话,则池化函数 P 的输出将是一个 M×N的矩阵,而在对其进行分类之前需要先把特征矩阵拉伸成一列MN大小的特征向量。最后, 分类函数的作用是对提取的特征进行分类, 可以采用逻辑回归或者 SVM 分类器实现。
总体来说,双线性CNN模型能够基于简洁的网络模型,实现对细粒度图像的有效识别。一方面,CNN网络能实现对细粒度图像进行高层语义特征获取,通过迭代训练网络模型中的卷积参数,过滤图像中不相关的背景信息。更重要的是另一方面,网络A 和网络B在图像识别任务中扮演着互补的角色,即网络A能够对图像中的物体进行定位,, 而网络B 则是完成对网络A 定位到的物体位置进行特征提取。通过这种方式,两个网络能够配合完成对输入细粒度图像的类检测和目标特征去的过程,较好地完成细粒度图像识别任务。关于双线性网络更加的介绍可以参考SIGAI的另外一篇文章:
https://mp.weixin.qq.com/s/slmod5rW4qRhxGnbNN2J8g。
4.基于目标块检测的方法
基于目标块(object part)检测的方法思路是:先在图像中检测出目标所在的位置,然后再检测出目标中有区分性区域的位置,然后将目标图像(即前景)以及具有区分性的目标区域块同时送入深度卷积网络进行分类。但是,基于目标块检测的方法,往往在训练过程中需要用到目标的Bounding box标注信息,甚至是目标图像中的关键特征点信息,而在实际应用中,要想获取到这些标注信息是非常困难的。比较有代表性的是2014年ECCV中提出来的Part-RCNN方法[11]:
Part-RCNN算法的流程图如图4所示。它的主要思想是借助目标检测中的经典方法R-CNN[12]来检测图中鸟的位置和鸟头部以及鸟身体的位置,然后将这三部分的信息同时输入深度卷积网络进行训练。
首先, 同 R-CNN 一样, Part RCNN 也使用自底向上的区域算法 Selective Search[13] 来产生区域候选, 如图4左上角所示。之后, 利用 R-CNN 算法来对这些区域候选进行检测, 给出评分分值。在这里, Part R-CNN 只检测前景对象 (鸟) 和两个局部区域 (头、 身体)。 根据评分分值 (图4中间) 挑选出区域检测结果 (见图4上方中间)。作者认为, R-CNN 给出的评分分值并不能准确地反映出每个区域的好坏。例如, 对于头部检测给出的标注框可能会在对象检测的标注框外面, 身体检测的结果与头部检测的结果可能会有重叠等。 这些现象都会影响最终的分类性能。 因此, 需要对检测区域进行修正,主要考虑利用区域的边框约束和几何约束进行:
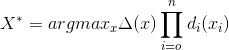 (2)
(2)
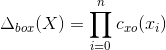 (3)
(3)
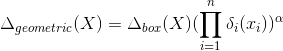 (4)
(4)
其中,公式2为改进后的评分函数,公式3和公式4分别为边框约束和几何约束条。利用如上所述的约束条件对 R-CNN 检测的位置信息进行修正之后,再分别对每一块区域提取卷积特征,将不同区域的特征相互连接起来, 构成最后的特征表示来训练 SVM 分类器。在CUB200-2011数据集中,该算法使用AlexNet作为骨干网络,在测试时如果不使用目标标注框,其识别准确率为73.89%,若测试阶段使用目标位置标注框,识别准确率为76.37%。
5.基于视觉注意机制的方法
视觉注意机制(Vision Attention Mechanism)是人类视觉所特有的信号处理机制。具体表现为视觉系统在看东西的时候,先通过快速扫描全局图像获得需要关注的目标区域,而后抑制其他无用信息以获取感兴趣的目标。目前,基于CNN网络的视觉注意方法被广泛应用到计算机视觉中,包括目标检测、识别等任务。在深度卷积网络中,同样能够利用注意模型来寻找图像中的感兴趣区域或区分性区域,并且对于不同的任务,卷积网络关注的感兴趣区域是不同的。比如图5中的亮点即为卷积网络感兴趣的区域,且越亮的区域对于精细分类任务越重要。

由于基于视觉注意模型(Vision Attention Model)的方法可以在不需要额外标注信息(比如目标位置标注框和重要部件的位置标注信息)的情况下,定位出图像中有区分性的区域,近年来被广泛应用于图像的细粒度分类领域。代表性的工作是17年CVPR中提出的循环注意卷积神经网络(Recurrent Attention Convolutional Neural Network, RA-CNN)[14]。该模型模仿faster-RCNN[15]中的RPN (Region Proposal Network) 网络,提出使用APN (Attention Proposal Network) 网络来定位出图像中的区分性区域,并通过在训练过程中使用排序损失函数 (Rank Loss),来保证每次利用注意模型定位的区域都更加有效。
![]()
如图6所示,整个模型由三个VGG19网络组成,第一个VGG网络卷积层输出的特征图送入到APN网络中进行学习,得到关于整幅图像的区分性区域的坐标以及Bounding Box的半径。假设当前VGG网络输入图像为X,VGG卷积层的所有参数为 ,则卷积特征F=W_{c}*x,其中*表示在前向传递求取卷积特征过程中网络中所有的卷积,池化和激活函数操作。而APN网络可以表示为[ ]=g(W_{c}*X),其中t_{x},t_{y},t_{l}分别为输入图像X中区分性区域中心的横纵坐标,以及该区域的半径(文章中默认该区域为正方形)。APN网络由两层全连接网络构成。
在获得了有辨识性区域的坐标和半径以后,作者利用该坐标从上一层VGG输入图像中将该区域进行裁剪,然后在将其放大以后输入到下一个VGG网络中进一步学习,依次迭代。
文中除了使用交叉熵损失函数(Cross Entropy Loss)保证每一个VGG网络对图像分类的准确性以外,还使用一个排序损失函数(如公式5所示)来对由APN网络得到的不同的区分性区域进行分类,在分类结果中正确类别的置信概率,要高于用生成该区域的原图直接进行分类的正确置信概率(见图6中绿色条纹处的 )。排序损失函数如下:
![]()
在迭代过程中,排序损失函数驱动卷积网络寻找输入图像中最有区分性的区域,作者通过对区分性区域层层放大的方法,将其细节不断放大,有利于卷积网络对该区域特征的学习。同时模型中的第一层和第二层网络可以分别认为是目标级别的注意模型(Object level attention model)和目标块级别的注意模型(Part level attention model)。
最后作者将原图以及通过APN网络迭代得到的两个不同尺度的区域图像同时送入深度卷积网络进行训练,并将这三个尺度图像的特征进行融合,进行分类,在CUB-200数据集中达到了85.3%的准确率。
6.总结
本文简要介绍了基于深度学习的精细分类的代表方法,目前精细分类领域发展出了包括基于多网络学习、目标块和视觉注意等多种方法,每一种方法都是为了获取到图像中具有区分性的区域,从而帮助网络学习到更加有效的特征,用来完成对细粒度图像的分类与识别。特别是通过使用视觉注意机制,能够在不依赖人工标注框信息的情况下,自动学习出图像中细微的区分性区域,达到非常高的分类精度。
参考文献
[1] Wah C, Branson S, Welinder P, et al. The Caltech-UCSD Birds-200-2011 Dataset[J]. Advances in Water Resources, 2011.
[2].Bo, et al. "A survey on deep learning-based fine-grained object classification and semantic segmentation." International Journal of Automation and Computing (2017): 1-17.
[3].Krizhevsky A, Sutskever I, Hinton G E, et al. ImageNet Classification with Deep Convolutional Neural Networks[C]. Neural Information Processing Systems(NIPS), 2012: 1097-1105.
[4].Simonyan K, Zisserman A. Very Deep Convolutional Networks for Large-Scale Image Recognition[C]. International Conference on Learning Representations(ICLR), 2015.
[5].Szegedy C, Liu W, Jia Y, et al. Going deeper with convolutions[C]. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2015: 1-9.
[6].He K, Zhang X, Ren S, et al. Deep Residual Learning for Image Recognition[C]. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR),2016: 770-778.
[7]Huang G, Liu Z, Van Der Maaten L, et al. Densely connected convolutional networks[C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR). 2017, 1(2): 3.
[8] Hu J, Shen L, Sun G. Squeeze-and-Excitation Networks[C]. // Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR). 2018
[9]. ZHANG, Xiaofan, et al. Embedding label structures for fine-grained feature representation. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2016. p. 1114-1123.
[10] Lin T Y, Roychowdhury A, Maji S. Bilinear Convolutional Neural Networks for Fine-grained Visual Recognition[J]. IEEE Transactions on Pattern Analysis & Machine Intelligence, 2017, PP(99):1-1.
[11] Zhang N, Donahue J, Girshick R B, et al. Part-Based R-CNNs for Fine-Grained Category Detection[J]. European Conference on Computer Vision (ECCV), 2014: 834-849.
[12] Girshick R, Donahue J, Darrell T, et al. Rich feature hierarchies for accurate object detection and semantic segmentation[C]//Proceedings of the IEEE conference on computer vision and pattern recognition (CVPR). 2014: 580-587.
[13].Uijlings J R, De Sande K E, Gevers T, et al. Selective Search for Object Recognition[J]. International Journal of Computer, 2013, 104(2): 154-171.
[14] Ren S, He K, Girshick R, et al. Faster r-cnn: Towards real-time object detection with region proposal networks[C]//Advances in neural information processing systems (NIPS). 2015: 91-99.
[15] Jianlong Fu, Heliang Zheng, Tao Mei. Look Closer to See Better: Recurrent Attention Convolutional Neural Network for Fine-Grained Image Recognition[C]// IEEE Conference on Computer Vision and Pattern Recognition. 2017,4476-4484.
[16] Lin T, Roychowdhury A, Maji S, et al. Bilinear CNN Models for Fine-Grained Visual Recognition[C]. International Conference on Computer Vision, 2015: 1449-1457.