【AAAI2019】【CVPR2018】最新 Video-based ReID 论文核心解读---附代码
SIGAI推荐
SIGAI资源汇总
SIGAI人工智能平台全场六折
SIGAI特约作者
Fisher Yu@Oulu
CV在读博士
研究方向:情感计算
最近看了两篇 Video-based 的 ReID 文章,做下笔记简单对比下:
第一篇CVPR2018 [1]:先对每帧的深度特征进行空间Attention,让网络自主发现对分类任务更有帮助的人体parts;然后对每Part各自进行多帧时间Attention,让网络自动评价每帧中的parts特征的质量好坏(如下图最后一行 SK,网络关注的part=黑色小包包区域,对于第1帧,全被遮挡,质量权值为0)

第二篇AAAI2019 [2]:Refining Recurrent Unit (RRU) 对多帧的历史特征,进行时空交互提炼更新,输出更新后的多帧特征; Spatial-Temporal clues Integration Module (STIM) 对多帧特征进行时空卷积整合。
不得不说,继17年18年单帧ReID后,现在基于视频的ReID陆陆续续火起来。什么叫火?就是算法不需要特别大的创新,针对视频特性来解决单帧中难以解决的问题,最后性能超SOTA,就可以发顶会了~~哈哈,纯属娱乐,火应该定义为当下对学术界有研究意义,而对工业界产品预研方向起到作用的topic。
Diversity Regularized Spatiotemporal Attention[1],CVPR2018
算法流程:
1.首先类似TSN对视频进行下采样,得到 N 帧。
2. 对每帧进行 Multiple Spatial Attention , 得到 K 个attention于不同parts 且 part间重叠尽量少的特征图。
3.对每个part类别中的N个特征图进行 temporal attention,权值叠加。
4.最后把K个part特征 Concat 起来,进行分类。
那么问题来了,怎么才能让网络自主去关注 multiple spatial attention parts?当然可以使用辅助监督的方法,比如给定人体某些 keypoint 对应的热图,来让网络刻意学对应的区域特征。文中作者使用的是无监督的方法,训练 multiple attention model 去关注 multiple parts,具体的网络模块如下:
既然每个Spatial Attention Model都是相同的架构
(Conv+ReLU+Conv+Softmax),怎么才能保证每个model训练出来关注不同的 parts?这就是本文的 main contribution:使用 Diversity Regularization 来约束不同model出来的Attention map感受野重叠的部分尽量小,即IoU尽量小。作者发现使用 Kullback-Leibler divergence 训练起来可能不稳定,因为有 log()项 会使Softmax出来的大部分小值更小;故最后使用 Hellinger distance 作为度量来约束,即最大化model出来的Attention maps的 Hellinger distance。
假定models个数=6,即希望关注6个不同parts (knee, hip, foot, arm, neck, waist),加上Diversity Regularization后效果如下:
对于 Temporal Attention 也是简单的 softmax of a linear response function 即可。
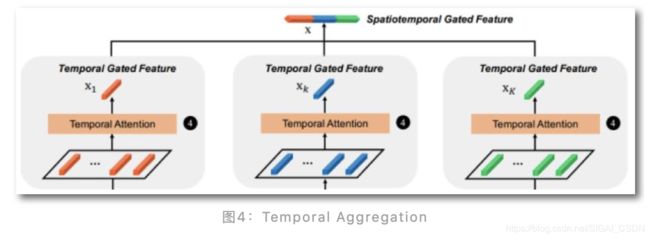
总结:
最后再反观来看,文中的主思路更像是在 tracking 特定 parts 的时空特征,而由于每帧中人的姿态不同,受遮挡程度不同,如何给时空中元素打分,就纯靠网络学习得来。更进一步来说,multiple attention model+diversity regularization思想跟清华那篇PCB-RPP[3]也类似,只不过后者的 RPP 是建立在 PCB part-based预训练的模型基础上微调,其实就是一个6 parts 的 diversity regularization。
不足之处:
1.基本上没有使用全局特征(person-based的),也没有建立起parts间的关系,等于丢失了大部分有用的空间信息。
2.Temporal信息的利用只放在最后评价每帧中parts的质量,也是可惜。
RRU+STIM[2],AAAI2019
先来一览总框架图:
看图说话,main contribution就是 RRU 和 STIM 模块,不过后者简直是醉了:STIM = 1x1x1卷积+3x3x3卷积+AVGpooling,等于把每帧时空refined好的特征再进行时空聚合。
来看看RRU做了什么:
1.由于是想设计类似RNN的 recurrent unit的结构,利用上一个时刻的输出很有必要,故RRU的输入为当前帧,上一帧的 raw feature xi,k,t,xi,k,t-1和上一帧的 refined feature Si,k,t-1
2.使用(Xi,k,t---Si,k,t-1)来模拟外观差异,使用(Xi,k,t---Xi,k,t-1)来捕捉动作上下文信息,将这两项concat一起作为 Update gate g 的输入。
3.gate g首先对输入特征进行聚合降维(过渡层),接着分别进行 channel attention 和 Spatial attention,然后将两个attention结果进行 element-wise 相乘,过Sigmoid函数,得到对当前帧 raw feature xi,k,t的更新权重 Z,以及上一帧refined feature1 Si,k,t-1的更新权值1-Z
4.最后更新得到当前帧的refined feature:
![]()
循环计算clip中每一帧的refined feature,最后把T帧特征stack起来。
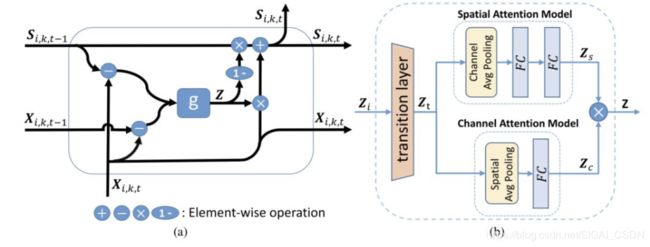
图6:(a) RRU, (b) update gate g
文中的story讲得非常细腻有趣,生动地描述了RRU设计的初衷以及与普通RNN的本质区别:
1.不同帧间的部分人体区域会遭受 遮挡/不同姿态/抖动 影响,为了更好地恢复帧内区域的丢失的信息,设计了RRU(通过参考过去帧的外观和动作信息,来去掉噪声和恢复丢失信息)
2.RRU通过参考过去帧时空信息来更新 frame-level feature,而传统的RNN模块是从temporal features来提取新特征;即前者输入与输出共享同样feature space,而后者的hidden state已经是不同的feature space。这可以应用到每个time step,来减少空间噪声,改善特征质量?

图7:X为raw feature,S为RRU后refined feature
Loss function由三部分组成:
STIM后的softmax CE loss + STIM后的video-level的 triplet loss + RRU后的part-based triplet loss
实验结果:
文中设置 T=8,即每次对8帧进行操作;有点失望,文中没有给出超参T的对比实验,还想看看RRU的 short-term 和 Long-term 特性如何。
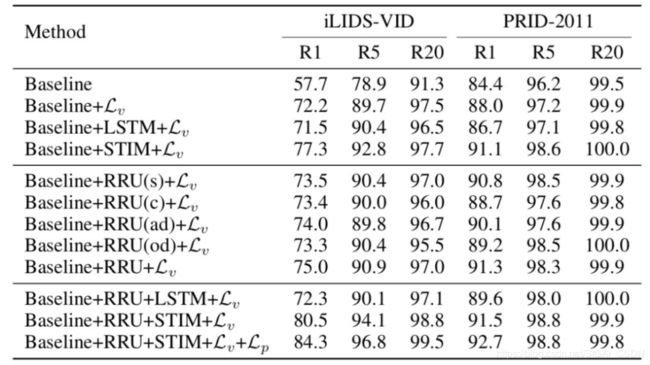
图8:RRU+STIM的ablation study
从上图可以看到两个有趣的点:
1.从第一个block结果可见,使用temporal信息未必能带来性能提升,比如使用LSTM,反而性能下降了;而STIM,用3D卷积的形式,能提升性能。这跟 @高继扬 BMVC[4]文章得出的结论神同步。
2.从第二个block结果可见,RRU中每个小模块都对feature起着不同程度的改善作用。但是最终只加复杂RRU的性能还不如简单STIM,可见在 top 层使用 temporal 卷积的强大威力。
图9:与SOTA性能对比
倒数第三行的 DRSTA 就是第一篇文章[1]的结果。
可见在大规模数据集MARS下,本文的方法性能比DRSTA高了足足7个点(mAP)。无力吐槽的是,这文用的backbone是Inception-v3,每帧resize到299 × 299,这不好比。
总结与展望
文中通过RRU和STIM来整合时空信息,虽然创新性不是很强,但简洁有效,也方便大家复现。其中RRU使用历史帧特征来更新当前帧特征的模块构造,非常有启发性,大家可以思考:如何构造对特定的任务的 'RNN'模块才是最有效的?而不是想都不想直接用 LSTM, GRU,convLSTM, convGRU来序列建模~~
RRU的论文代码链接如下:
https://github.com/yolomax/rru-reid
Reference:
[1]Shuang Li et al., Diversity Regularized Spatiotemporal Attention for Video-based Person Re-identification, CVPR2018
[2]Yiheng Liu et al., Spatial and Temporal Mutual Promotion for Video-based Person Re-identification, AAAI2019
[3]Yifan Sun et al., Beyond Part Models: Person Retrieval with Refined Part Pooling, ECCV2018
[4]Jiyang Gao and Ram Nevatia, Revisiting Temporal Modeling for Video-based Person ReID,BMVC2018