Python爬虫之爬取动态页面数据
很多网站通常会用到Ajax和动态HTML技术,因而只是使用基于静态页面爬取的方法是行不通的。对于动态网站信息的爬取需要使用另外的一些方法。
先看看如何分辨网站时静态的还是动态的,正常而言含有“查看更多”字样或者打开网站时下拉才会加载内容出来的进本都是动态的,简便的方法就是在浏览器中查看页面相应的内容、当在查看页面源代码时找不到该内容时就可以确定该页面使用了动态技术。
对于动态页面信息的爬取,一般分为两种方法,一种是直接从JavaScript中采集加载的数据、需要自己去手动分析Ajax请求来进行信息的采集,另一种是直接从浏览器中采集已经加载好的数据、即可以使用无界面的浏览器如PhantomJS来解析JavaScript。
1、直接从JavaScript中采集加载的数据
示例1——爬取MTime影评信息:
随便打开一个电影的URL:http://movie.mtime.com/99547/

一开始出现转圈的加载,即可判断是动态加载的。
关注到“票房”这里:

查看源代码并找不到票房的字样:
因此可断定该内容是使用Ajax异步加载生成的。
打开FireBug,在“网络”>“JavaScript”中查看含有敏感字符的接口链接,因为是和电影相关的,就先查看含有“Movie.api?Ajax_Callback=......”字样的链接,可以查看到其中一个含有影评和票房等信息:

为了进行确认哪些参数是会变化的,再打开一个新的电影的URL并进行相同的操作进行查看:

为了方便,直接上BurpSuite的Compare模块进行比较:
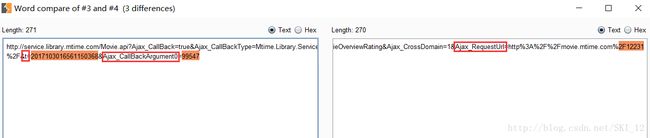
可以直接看到,只有以上三个参数的值是不一样的,其余的都是相同的。其中Ajax_RequestUrl参数值为当前movie的URL,t的值为当前时间,Ajax_CallBackArgument0的值为当前电影的序号、即其URL中后面的数字。
因此就可以构造Ajax请求的URL来爬取数据,回到top 100的主页http://www.mtime.com/top/movie/top100/,分析其中的标签等然后编写代码遍历top 100所有的电影相关票房和影评信息,注意的是并不是所有的电影都有票房信息,这里需要判断即可。
代码如下:
#coding=utf-8
import requests
import re
import time
import json
from bs4 import BeautifulSoup as BS
import sys
reload(sys)
sys.setdefaultencoding('utf8')
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/60.0.3112.113 Safari/537.36',
}
def Get_Movie_URL():
urls = []
for i in range(1,11):
# 第一页的URL是不一样的,需要另外进行处理
if i != 1:
url = "http://www.mtime.com/top/movie/top100/index-%d.html" % i
else:
url = "http://www.mtime.com/top/movie/top100/"
r = requests.get(url=url,headers=headers)
soup = BS(r.text,'lxml')
movies = soup.find_all(name='a',attrs={'target':'_blank','href':re.compile('http://movie.mtime.com/(\d+)/'),'class':not None})
for m in movies:
urls.append(m.get('href'))
return urls
def Create_Ajax_URL(url):
movie_id = url.split('/')[-2]
t = time.strftime("%Y%m%d%H%M%S0368", time.localtime())
ajax_url = "http://service.library.mtime.com/Movie.api?Ajax_CallBack=true&Ajax_CallBackType=Mtime.Library.Services&Ajax_CallBackMethod=GetMovieOverviewRating&Ajax_CrossDomain=1&Ajax_RequestUrl=%s&t=%s&Ajax_CallBackArgument0=%s" % (url,t,movie_id)
return ajax_url
def Crawl(ajax_url):
r = requests.get(url=ajax_url,headers=headers)
if r.status_code == 200:
r.encoding = 'utf-8'
result = re.findall(r'=(.*?);',r.text)[0]
if result is not None:
value = json.loads(result)
movieTitle = value.get('value').get('movieTitle')
TopListName = value.get('value').get('topList').get('TopListName')
Ranking = value.get('value').get('topList').get('Ranking')
movieRating = value.get('value').get('movieRating')
RatingFinal = movieRating.get('RatingFinal')
RDirectorFinal = movieRating.get('RDirectorFinal')
ROtherFinal = movieRating.get('ROtherFinal')
RPictureFinal = movieRating.get('RPictureFinal')
RStoryFinal = movieRating.get('RStoryFinal')
print movieTitle
if value.get('value').get('boxOffice'):
TotalBoxOffice = value.get('value').get('boxOffice').get('TotalBoxOffice')
TotalBoxOfficeUnit = value.get('value').get('boxOffice').get('TotalBoxOfficeUnit')
print '票房:%s%s' % (TotalBoxOffice,TotalBoxOfficeUnit)
print '%s——No.%s' % (TopListName,Ranking)
print '综合评分:%s 导演评分:%s 画面评分:%s 故事评分:%s 音乐评分:%s' %(RatingFinal,RDirectorFinal,RPictureFinal,RStoryFinal,ROtherFinal)
print '****' * 20
def main():
urls = Get_Movie_URL()
for u in urls:
Crawl(Create_Ajax_URL(u))
# 问题所在,请求如下单个电影链接时时不时会爬取不到数据
# Crawl(Create_Ajax_URL('http://movie.mtime.com/98604/'))
if __name__ == '__main__':
main()运行结果为:
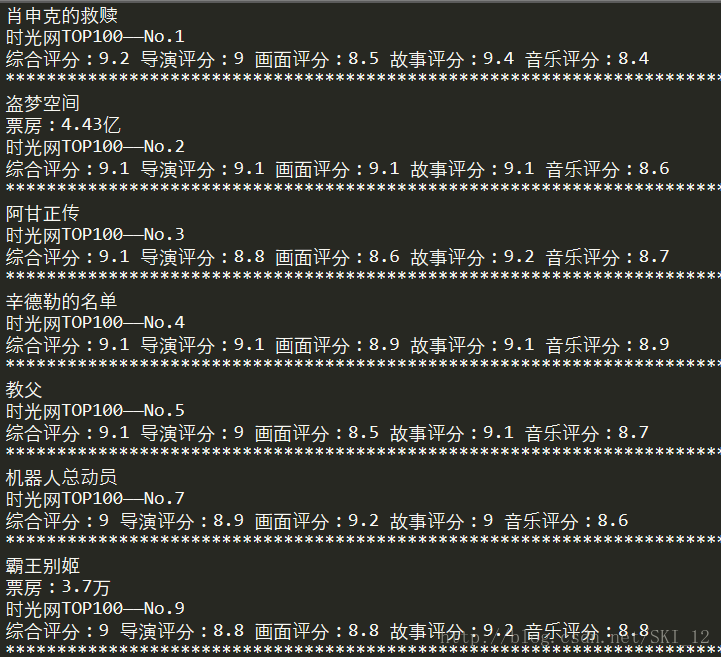
注意到其中一些电影如No.6的是时不时才会爬取得到的,具体Json数据也是loads下来了,就是不能够每次都可以解析出来,具体的原因还没分析出来。
示例2——爬取肯德基门店信息:
以肯德基的餐厅地址为例:http://www.kfc.com.cn/kfccda/storelist/index.aspx

可以看到当前城市显示的是广州。
查看页面源代码:


发现在“当前城市”之后只有“上海”的字样而没有广州,而且城市是通过JS加载进来的,即该页面使用了动态加载技术。
到FireBug中查看JS相应的请求内容:
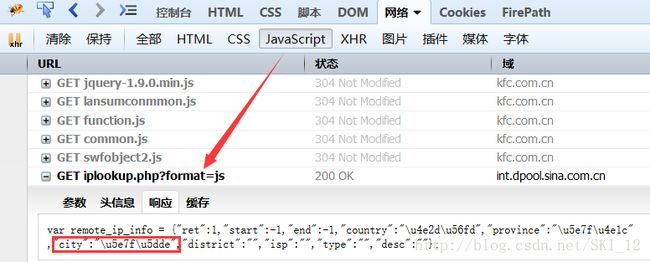
可以看到其中一个JS请求是用于获取城市地址的,将该URL记下用于后面的地址的自动获取然后再解析Json格式的数据即可。
获取了city信息,就应该是获取所在city的门店信息了,到XHR中查看到如下请求:

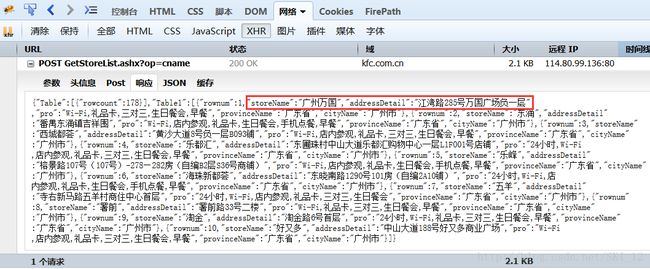
其为POST请求,提交的内容为city信息等,且返回的响应内容就是含有门店信息的Json格式的内容。
因此记录下该POST请求的URL和参数名,其中cname参数为city的值、直接从上一个Ajax请求中获取即可,pageIndex参数是指定第几页(注意门店的换页操作也是使用Ajax加载的),pageSize参数指定每页显示几家店铺、这里为默认的10。
代码如下:
#coding=utf-8
import requests
import re
import json
url = 'http://www.kfc.com.cn/kfccda/storelist/index.aspx'
ajax_url = 'http://int.dpool.sina.com.cn/iplookup/iplookup.php?format=js'
store_url = 'http://www.kfc.com.cn/kfccda/ashx/GetStoreList.ashx?op=cname'
r = requests.get(ajax_url)
result = re.findall(r'=(.*?);',r.text)[0]
value = json.loads(result)
city = value.get('city')
for i in range(1,11):
data = {
'cname':city,
'pageIndex':str(i),
'pageSize':'10',
'pid':''
}
r2 = requests.post(url=store_url,data=data)
result2 = json.loads(r2.text)
tables = result2.get('Table1')
for t in tables:
print t.get('storeName')
print t.get('addressDetail')
print '**' * 20运行结果:

注意,直接在命令行输出结果才会完整,不要直接在Sublime中输出否则结果会出现漏掉的:-)
2、直接从浏览器中采集已经加载好的数据
这里用到一个组合,即:PhantomJS+Selenium+Python,都需要一个个去安装,PhantomJS负责渲染解析JavaScript,Selenium负责驱动浏览器以及和Python交互,Python负责后期处理。
安装selenium:pip install selenium,另外在调用浏览器驱动时可能会报错,这时就需要下载相应的补丁,地址为:http://www.seleniumhq.org/download/
下载phantomjs解压然后在调用时执行路径executable_path上写上phantomjs.exe所在的路径即可。
Selenium练习例子:
使用Firefox浏览器的驱动来打开百度,查看输入框的标签:
![]()
可知可以通过webdriver的find_element_by_name()方法来获取标签元素进行操作。
在代码中判断是否包含“百度”字样,然后输入“Kali Linux”进行搜索,查看页面是否含有“Kali”字符,最后退出:
#coding=utf-8
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
import time
url = 'https://www.baidu.com/'
driver = webdriver.Firefox()
driver.implicitly_wait(3) # 隐式等待
driver.get(url)
assert u"百度" in driver.title
elem = driver.find_element_by_name("wd") # 找到输入框的元素
elem.clear() # 清空输入框里的内容
elem.send_keys(u"Kali Linux") # 在输入框中输入'Kali Linux'
elem.send_keys(Keys.RETURN) # 在输入框中输入回车键
time.sleep(3)
assert u"Kali" in driver.page_source
driver.close()期间会出现报错信息:selenium.common.exceptions.WebDriverException: Message: 'geckodriver' executable needs to be in PATH.
这是因为没有geckodriver.exe文件或者没有将其配置到环境变量中。
先去下载,个人下载的是win64版的:https://github.com/mozilla/geckodriver/releases
接着解压,将geckodriver.exe放在一个已经设置了环境变量的目录或者直接再设置新的环境变量的目录都可以,这里是直接放在Python目录中的Scripts目录中。
接着运行就没有问题了:
示例1——爬取肯德基门店信息:
这里还是使用肯德基门店的例子,直接调用webdriver的find_element_by_xpath()方法,对于餐厅名称及其地址的xpath的获取,可以直接使用FireBug中的FirePath来获取:

接着可以使用PhantomJS或者Firefox驱动都可以。
代码如下:
#coding=utf-8
from selenium import webdriver
import time
url = 'http://www.kfc.com.cn/kfccda/storelist/index.aspx'
driver = webdriver.PhantomJS(executable_path='E:\Python27\Scripts\phantomjs-2.1.1-windows\\bin\phantomjs.exe')
# 也可以使用Firefox驱动,区别在于有无界面的显示
# driver = webdriver.Firefox()
# driver.implicitly_wait(10) # 隐式等待
driver.get(url)
# 线程休眠,和隐式等待的区别在于前者执行每条命令的超时时间是一样的而sleep()只会在调用时wait指定的时间
time.sleep(3)
for i in range(1,11):
shopName_xpath = ".//*[@id='listhtml']/tr[" + str(i+1) + "]/td[1]"
shopAddress_xpath = ".//*[@id='listhtml']/tr[" + str(i+1) + "]/td[2]"
shopName = driver.find_element_by_xpath(shopName_xpath).text
shopAddress = driver.find_element_by_xpath(shopAddress_xpath).text
print shopName
print shopAddress
print '**' * 20
driver.close()运行结果:

想换页的话直接获取该下一页的标签然后再模拟点击即可。
这里还是要注意,直接在命令行输出结果才会完整,不要直接在Sublime中输出否则结果会出现漏掉的:-)
示例2——爬取去哪儿网酒店信息:
网页为:http://hotel.qunar.com/

查看源代码中表单部分内容:

可以根据图中框出的属性来进行元素的提取,然后通过webdriver进行相应的操作。
接着对酒店信息的标签进行特征提取,这里城市选的是深圳:

根据框中的特征使用BeautifulSoup来进行提取即可。
酒店名所在标签:
![]()
酒店地址所在标签:

酒店评分所在标签:

酒店价格所在标签:

接着进行自动点击下一页操作,查看源代码:

可以看到li标签的class值为“item next ”,即中间有空格隔着,也就是其class值有多个而不是一个的意思,这样就不能使用find_element_by_class_name()而是使用find_element_by_css_selector()来获取元素,当然也可以使用find_element_by_xpath()和FirePath结合使用、但是xpath解析出来的参数会随着页面而改变,为了方便就直接使用find_element_by_css_selector(),如上述情况,多个class值的写法为find_element_by_css_selector(".item.next")
代码如下:
#coding=utf-8
import requests
import re
import time
import datetime
from selenium import webdriver
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from bs4 import BeautifulSoup as BS
def Crawl_For_Hotel(driver, to_city, from_date, to_date):
ele_tocity = driver.find_element_by_id('toCity')
ele_fromdate = driver.find_element_by_id('fromDate')
ele_todate = driver.find_element_by_id('toDate')
ele_search = driver.find_element_by_class_name('search-btn')
ele_tocity.clear()
ele_tocity.send_keys(to_city)
ele_tocity.click()
ele_fromdate.clear()
ele_fromdate.send_keys(from_date)
ele_todate.clear()
ele_todate.send_keys(to_date)
ele_search.click()
page_num = 0
while True:
try:
WebDriverWait(driver, 10).until(
EC.title_contains(unicode(to_city))
)
except Exception, e:
print e
break
time.sleep(5)
# 让driver执行JS脚本,将页面拉到底部
js = "window.scrollTo(0, document.body.scrollHeight);"
driver.execute_script(js)
time.sleep(5)
htm_const = driver.page_source
soup = BS(htm_const,'lxml')
names = soup.find_all(name='a',attrs={'class':'e_title js_list_name', 'href':not None, 'title':not None, 'target':'_blank'})
addrs = soup.find_all(name='span',attrs={'class':'area_contair'})
scores = soup.find_all(name='p',attrs={'class':'score'})
prices = soup.find_all(name='div',attrs={'class':'hotel_price'})
for name,addr,score,price in zip(names,addrs,scores,prices):
# 处理地址标签及其拼接问题
ads = re.findall(r'(.*?)',str(addr))
addr_new = ''
for a in ads:
addr_new = a if addr_new == '' else addr_new + ',' + a
score_new = re.findall(r'(.*?)',str(score))[0]
price_new = re.findall(r'(.*?)',str(price))[0]
print name.string
print '价格:%s元起' % price_new
print '评分:%s / 5分' % score_new
print '地址:' + addr_new
print '**' * 20
try:
next_page = WebDriverWait(driver, 10).until(
# EC.visibility_of(driver.find_element_by_xpath(".//*[@id='searchHotelPanel']/div[6]/div[1]/div/ul/li[10]/a/span[1]"))
EC.visibility_of(driver.find_element_by_css_selector(".item.next"))
)
next_page.click()
page_num += 1
time.sleep(10)
except Exception, e:
print e
break
def main():
url = 'http://hotel.qunar.com/'
today = datetime.date.today().strftime('%Y-%m-%d')
tomorrow = datetime.datetime.today() + datetime.timedelta(days=1)
tomorrow = tomorrow.strftime('%Y-%m-%d')
driver = webdriver.Firefox()
# driver = webdriver.PhantomJS(executable_path='E:\Python27\Scripts\phantomjs-2.1.1-windows\\bin\phantomjs.exe')
driver.set_page_load_timeout(50)
driver.get(url)
driver.maximize_window() # 将浏览器最大化显示
driver.implicitly_wait(10) # 控制间隔时间,等待浏览器反应
Crawl_For_Hotel(driver,u'深圳',today,tomorrow)
if __name__ == '__main__':
main()运行结果:

示例3——爬取酷狗页面实现下载歌曲
参考的文章:http://www.freebuf.com/sectool/151282.html
大致过程为,当点击播放某一首歌时,页面会请求一个MP3文件所在的URL来进行播放,这个URL可以使用BurpSuite截断或者浏览器的开发者工具看到,然后直接访问也可以进行歌曲的下载。在这里就只看如何通过webdriver来获取该URL然后实现下载。
打开酷狗主页面:http://www.kugou.com/
查看其输入框以及搜索按钮的元素标签,同样是使用FirePath来查看其xpath:


随意搜索一首歌,这里搜的是“smileyface”,然后查看第一行的歌曲的元素标签信息:

打开FireBug的网络,然后点击该链接进行播放操作:

查看Network的内容,发现其中一条请求的是一个乱取名字的URL文件,即mp3文件,可以看到它请求包的一些特征:


直接复制该URL进行访问,可以直接下载歌曲,即是我们需要查找的URL。
接着点击页面的下载按钮看看,会提示需要在客户端才能进行下载操作:

可以看到,是可以直接绕过这个限制直接下载歌曲的。
接着查看页面源代码,看到audio标签的属性src的值是不会显示出来的:
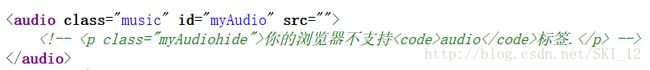
只有查看元素时才可以看到链接,即需要动态加载:
![]()
接着,直接对该URL使用urllib库的urlretrieve()方法下载即可。
但是,有一些付费歌曲在在线页面上是找不到其相应播放的URL的,需要下载客户端才可以播放:

所以要在下载时进行判断以免下载了不是MP3的文件。
代码如下:
#coding=utf-8
import requests
import re
import time
import urllib
import sys
from selenium import webdriver
from selenium.common.exceptions import NoSuchElementException
def Download_The_Song(url):
try:
print "[*]Start to download the song..."
path = "%s.mp3" % name
urllib.urlretrieve(url, path, Schedule)
print '\n[+]Download successfully!'
except Exception, e:
print '[-]Failed to download.'
print e
def Crawl_For_The_URL():
print
song_name = raw_input("[*]Please input the name of song for search: ")
global name
url = 'http://www.kugou.com/'
driver = webdriver.Chrome()
driver.maximize_window()
driver.get(url)
# time.sleep(3)
# 输入歌曲名并进行搜索操作
ele_input = driver.find_element_by_xpath('html/body/div[1]/div[1]/div[1]/div[1]/input')
ele_input.clear()
ele_input.send_keys(song_name.decode('gbk'))
ele_search = driver.find_element_by_xpath('html/body/div[1]/div[1]/div[1]/div[1]/div/i')
ele_search.click()
songs_list_url = driver.current_url
# 获取歌曲列表的名称
driver.get(songs_list_url)
# time.sleep(3)
i = 1
while True:
try:
ele_song = driver.find_element_by_xpath(".//*[@id='search_song']/div[2]/ul[2]/li[%d]/div[1]/a"%i)
print "%d." % i + ele_song.get_attribute('title')
i += 1
except NoSuchElementException as msg:
break
# 获取用户输入的数字进行相应歌曲下载URL的提取
print
num_input = raw_input("[*]Please choose the number of the song to download: ")
num = int(num_input)
driver.get(songs_list_url)
# time.sleep(3)
ele_choosed_song = driver.find_element_by_xpath(".//*[@id='search_song']/div[2]/ul[2]/li[%d]/div[1]/a"%num)
name = ele_choosed_song.get_attribute('title')
ele_choosed_song.click()
driver.switch_to_window(driver.window_handles[1])
download_url = driver.find_element_by_xpath(".//*[@id='myAudio']").get_attribute('src')
driver.close()
return download_url
# 用于显示下载进度
def Schedule(a, b, c):
per = 100 * a * b / c
if per > 100:
per = 100
percentage = "Downloading...... %.2f %%" % per
sys.stdout.write('\r'+'[*]'+percentage)
def main():
url = Crawl_For_The_URL()
# 若返回的URL请求的文件名后缀不是MP3格式,则可能是webdriver的问题,或者是该歌曲是付费歌曲、需要在客户端才能播放
if url.split('.')[-1] == "mp3":
Download_The_Song(url)
else:
print "[-]Can't download the song .Maybe the type of webdriver is incorrect ,or the song needs to be paid for play."
if __name__ == '__main__':
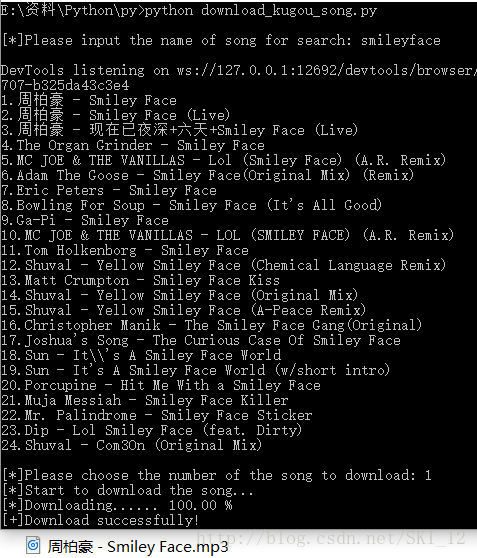
main()运行结果:
大多数歌曲都是可以直接下载的:
接着看下Eason大佬的新歌,一般都是需要付费的:

这里奇怪的一点是使用Firefox驱动或者PhantomJS是有问题的而使用Chrome的就没有问题,Firefox说的是找不到该元素:

具体的不同浏览器驱动的问题后面再分析看看。
参考来源:《Python爬虫开发与项目实战》