机器学习中的文本处理
为了在文本文档中执行机器学习,我们首先需要将文本内容转换为数字特征向量。
词袋模型
简单有效,通过以下步骤将文本转化为数值向量 -> (分词,计数,规范化和加权)
局限性:
- 不能涵盖词语间的关联关系
- 不能正确捕捉否定关系
- 不能捕捉短语和多词表达
- 忽略了词序
- 不能解释潜在的拼写错误或单词派生
N-grams
代替构建简单的unigrams集合(n=1),可以使用bigrams(n=2),这样就考虑了连续单词的出现次数。词序
character n-grams
能够表示拼写错误和派生词的情况
from sklearn.feature_extraction.text import CountVectorizer
ngram_vectorizer = CountVectorizer(analyzer='char_wb', ngram_range=(2, 2))
counts = ngram_vectorizer.fit_transform(['words', 'wprds'])
ngram_vectorizer.get_feature_names()
Out: [' w', 'ds', 'or', 'pr', 'rd', 's ', 'wo', 'wp']分词、去停用词
from sklearn.feature_extraction.text import CountVectorizer
count_vect = CountVectorizer(min_df=1, stop_words='english')
X_train_counts = count_vect.fit_transform(twenty_train.data)tfidf
![]()
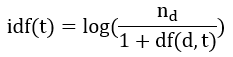
applying the Euclidean (L2) norm:
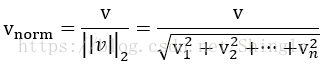
# without normalization
import numpy as np
import scipy as sp
def tfidf(term, doc, docset):
tf = float(doc.count(term)) / sum(doc.count(term) for doc in docset)
idf = np.log(float(len(docset)) / (1 + len([doc for doc in docset if term in doc])))
return tf * idf# Term Frequency times Inverse Document Frequency
from sklearn.feature_extraction.text import TfidfTransformer
tfidf_transformer = TfidfTransformer()
X_train_tfidf = tfidf_transformer.fit_transform(X_train_counts)词干化
import nltk.stem
english_stemmer = nltk.stem.SnowballStemmer('english')
class StemmedTfidfVectorizer(TfidfVectorizer):
def build_analyzer(self):
analyzer = super(TfidfVectorizer, self).build_analyzer()
return lambda doc: (english_stemmer.stem(w) for w in analyzer(doc))
tfidf_vectorizer = StemmedTfidfVectorizer(min_df=1, stop_words='english')
X_train_stemmed_tfidf = tfidf_vectorizer.fit_transform(twenty_train.data)数字处理
from sklearn.feature_extraction.text import TfidfVectorizer
def number_normalizer(tokens):
""" Map all numeric tokens to a placeholder.
For many applications, tokens that begin with a number are not directly
useful, but the fact that such a token exists can be relevant. By applying
this form of dimensionality reduction, some methods may perform better.
"""
return ("#NUMBER" if token[0].isdigit() else token for token in tokens)
class NumberNormalizingVectorizer(TfidfVectorizer):
def build_tokenizer(self):
tokenize = super(NumberNormalizingVectorizer, self).build_tokenizer()
return lambda doc: list(number_normalizer(tokenize(doc)))
vectorizer = NumberNormalizingVectorizer(stop_words='english', min_df=5)中文
from sklearn.feature_extraction.text import TfidfVectorizer
import jieba
class Tokenizer(object):
def __init__(self):
self.n = 0
def __call__(self, line):
tokens = []
for query in line.split('\t'):
words = [word for word in jieba.cut(query)]
for gram in [1, 2]:
for i in range(len(words) - gram + 1):
tokens += ["_*_".join(words[i:i+gram])]
if np.random.rand() < 0.00001:
print(line)
print('='*20)
print(tokens)
self.n += 1
if self.n % 10000 == 0:
print(self.n, end=' ')
return tokens
tfv = TfidfVectorizer(tokenizer=Tokenizer(), min_df=3, max_df=0.95, sublinear_tf=True)
X_sp = tfv.fit_transform(df_all['query'])词性标注(Part Of Speech tagging, POS标注)
词性标注器会对整句进行解析,目标是把它重新排列成一个依存关系树的形式。树中的灭个节点对应一个词语,而父子关系确定了这个词是依赖谁的。有了这个树就可以做成更好的判断,如”book”是名词(”This is a good book.”)还是动词(”Could you please book the flight?”)。
import nltk
nltk.pos_tag(nltk.word_tokenize("This is a good book."))
nltk.pos_tag(nltk.word_tokenize("Could you please book the flight?"))引入外部知识,如SentiWordNet
SentiWordNet(http://sentiwordnet.isti.cnr.it),一个13MB的文件。赋予了大部分英文单词一个正向分值和一个负向分值。
文本预处理:
- 切分文本
- 扔掉出现过分频繁,对测试集预测无帮助的词语
- 扔掉出现出现频率很低,只有很小可能出现在测试集的词语
- 统计剩余词语
- 考虑整个语料集合,从词频统计中计算TF-IDF值
拓展——定制化
Customizing the vectorizer classes
- preprocessor: a callable that takes an entire document as input (as a single string), and returns a possibly transformed version of the document, still as an entire string. This can be used to remove HTML tags, lowercase the entire document, etc.
- tokenizer: a callable that takes the output from the preprocessor and splits it into tokens, then returns a list of these.
- analyzer: a callable that replaces the preprocessor and tokenizer. The default analyzers all call the preprocessor and tokenizer, but custom analyzers will skip this. N-gram extraction and stop word filtering take place at the analyzer level, so a custom analyzer may have to reproduce these steps.
To make the preprocessor, tokenizer and analyzers aware of the model parameters it is possible to derive from the class and override the build_preprocessor, build_tokenizer` and build_analyzer factory methods instead of passing custom functions.
1.
>>> def my_tokenizer(s):
... return s.split()
...
>>> vectorizer = CountVectorizer(tokenizer=my_tokenizer)
>>> vectorizer.build_analyzer()(u"Some... punctuation!") == (
... ['some...', 'punctuation!'])
Out[17]: True2.
>>> from nltk import word_tokenize
>>> from nltk.stem import WordNetLemmatizer
>>> class LemmaTokenizer(object):
... def __init__(self):
... self.wnl = WordNetLemmatizer()
... def __call__(self, doc):
... return [self.wnl.lemmatize(t) for t in word_tokenize(doc)]
...
>>> vect = CountVectorizer(tokenizer=LemmaTokenizer()) 3.
>>> import re
>>> def to_british(tokens):
... for t in tokens:
... t = re.sub(r"(...)our$", r"\1or", t)
... t = re.sub(r"([bt])re$", r"\1er", t)
... t = re.sub(r"([iy])s(e$|ing|ation)", r"\1z\2", t)
... t = re.sub(r"ogue$", "og", t)
... yield t
...
>>> class CustomVectorizer(CountVectorizer):
... def build_tokenizer(self):
... tokenize = super(CustomVectorizer, self).build_tokenizer()
... return lambda doc: list(to_british(tokenize(doc)))
...
>>> print(CustomVectorizer().build_analyzer()(u"color colour"))
['color', 'color']主题模型
单独讨论,见Blog
主题模型
词向量
单独讨论,见Blog
词向量
《Building Machine Learning Systems with Python》 P37 P106
http://scikit-learn.org/stable/modules/feature_extraction.html
https://github.com/scikit-learn/scikit-learn/blob/a24c8b46/sklearn/feature_extraction/text.py#L541
https://en.wikipedia.org/wiki/Vector_space_model
https://en.wikipedia.org/wiki/Bag-of-words_model
https://en.wikipedia.org/wiki/Tf–idf
https://en.wikipedia.org/wiki/N-gram