集成学习(Bagging、Boosting、Stacking)
组合多个学习器:集成方法(ensemble method) 或 元算法(meta-algorithm)。
- 不同算法的集成(集成个体应“好而不同”)
- 同一算法在不同设置的集成
- 数据集不同部分分配给不同分类器之后的集成
集成学习中需要有效地生成多样性大的个体学习器,需要多样性增强:
- 对 数据样本 进行扰动(敏感:决策树、神经网络; 不敏感:线性学习器、支持向量机、朴素贝叶斯、k近邻)
- 对 输入属性 进行扰动
- 对 输出表示 进行扰动
- 对 算法参数 进行扰动
目前的集成学习方法大致可分为两大类:
- 个体学习器之间存在强依赖关系,必须串行生成的序列化方法
- 个体学习器不存在强依赖关系,可以同时生成的并行化方法
Bagging
也称自举汇聚法(bootstrap aggregating),是在原始数据集选择T次后得到T个新数据集。通过放回取样得到(比如要得到一个大小为n的新数据集,该数据集中的每个样本都是在原始数据集中随机取样,即抽样之后又放回)得到。基于每个采样集训练出一个基学习器,再将这些基学习器结合,在对预测输出进行结合时,Bagging通常对分类任务使用简单投票法,对回归任务采用简单平均法。Bagging主要关注降低方差。
为啥有放回取样?:训练数据不同,我们获得的基学习器可望具有比较大的差异。然而,如果采样出的子集都完全不同,则每个基学习器只用到了一小部分训练数据,甚至不足以进行有效学习,显然无法产生比较好的基学习器。所以,采取相互有交叠的采样子集。
对于一个样本,它在某一次含m个样本的训练集的随机采样中,每次被采集到的概率是1/m。不被采集到的概率为1-1/m。如果m次采样都没有被采集中的概率是(1-1/m)^m, 当m→∞时,(1-1/m)^m→1/e≃0.368。也就是说,在bagging的每轮随机采样中,训练集中大约有36.8%的数据没有被采样集采集中。
随机森林(Random Forest, RF)
2001年由Breiman提出。是Bagging的一个扩展变体。
优点:可用于回归任务和分类任务,并且很容易查看它分配给输入特征的相对重要性。易于使用,超参数数量少。不易过拟合
缺点:大量的树会使算法变慢。
RF在以决策树为基学习器构建Bagging集成的基础上,进一步在决策树的训练过程中引入了随机属性选择。随机森林中基学习器的多样性不仅来自样本扰动,还来自属性扰动,使得最终集成的泛化性能可通过个体学习器之间差异度的增加而进一步提升。
传统决策树在选择划分属性时是在当前结点的属性集合中选择一个最优属性;而在RF中,对基决策树的每个结点,是从该结点的属性集合中随机选择一个包含k个属性的子集,然后再从这个子集中选择一个最优属性进行划分。参数k控制了随机性的引入程度,推荐值k=log2d。
超参数:
- n_estimators:控制随机森林中树的数量
- max_features:随机森林在单个树中尝试的最大特征数量。
- min_sample_leaf: 叶子的数量
Boosting
分类器通过串行训练获得,通过集中关注已有分类器错分的那些数据来获得新的分类器。Boosting主要关注降低偏差。
AdaBoost(Adaptive Boosting)
1995年由Freund和Schapire提出。
训练算法:
- 训练数据中的每个样本,并赋予其一个权重,这些权重构成了向量D。一开始,这些权重都初始化成相等值
- 首先在训练数据上训练出一个弱分类器并计算该分类器的错误率
- 然后在同一数据集上再次训练弱分类器。在分类器的第二次训练当中,将会重新调整每个样本的权重,其中第一次分对的样本的权重会降低,而第一次分错的样本的权重将会提高
- 为了从所有弱分类器中得到最终的分类结果,Adaboost为每个分类器都分配了一个权重值alpha,这些alpha值是基于每个弱分类器的错误率进行计算的。
alpha表示弱分类器在最终分类器中的重要性,由上式可知,当误差小于0.5时,alpha大于等于0,并且alpha随着误差的减小而增大,所以分类误差率越小的基本分类器在最终分类器中的作用越大。
如果某个样本被正确分类,那么该样本的权重更改为:
如果某个样本被错分,那么该样本的权重更改为:
AdaBoost算法会不断地重复训练和调整权重,直到训练错误率为0或者弱分类器的数目达到指定值。
AdaBoost模型是弱分类器的线性组合,系数alpha表示了基本分类器的重要性:
加法模型(additive model):
前向分步算法(forward stagewise algorithm):学习的是加法模型,能够从前往后,每一步只学习一个基函数及其系数,逐步逼近优化目标函数式,那么就可以简化优化的复杂度。具体地,每步只需优化如下损失函数:
AdaBoost算法的一个解释是该算法实际是前向分布算法的一个实现。 模型是加法模型、损失函数是指数损失、算法是前向分布算法。 每一步中极小化损失函数,得到参数beta、gamma.
梯度提升树(Gradient Boosting Decision Tree, GBDT)
提升方法实际采用的加法模型(即基函数的线性组合)与前向分布算法。以决策树为基函数的提升方法称为提升树(boosting tree)。
从统计视角来看,AdaBoost实质上是基于加法模型以类似牛顿迭代来优化指数损失函数。受此启发,通过将迭代优化过程替换为其他优化方法,产生了GradientBoosting等变体算法。
梯度提升于2000年由Friedman等人提出,利用了最速下降法,关键是利用损失函数的负梯度在当前模型的值
XGBoost
- 支持并行化:同层级节点可并行。具体的对于某个节点,节点内选择最佳分裂点,候选分裂点计算增益用多线程并行。
Xgboost和深度学习的关系,陈天奇在Quora上的解答如下: 不同的机器学习模型适用于不同类型的任务。深度神经网络通过对时空位置建模,能够很好地捕获图像、语音、文本等高维数据。而基于树模型的XGBoost则能很好地处理表格数据,同时还拥有一些深度神经网络所没有的特性(如:模型的可解释性、输入数据的不变性、更易于调参等)
Xgboost的调参。通常认为对它性能影响较大的参数有:
- eta:每次迭代完成后更新权重时的步长。越小训练越慢。
- num_round:总共迭代的次数。
- subsample:训练每棵树时用来训练的数据占全部的比例。用于防止Overfitting。
- colsample_bytree:训练每棵树时用来训练的特征的比例,类似RandomForestClassifier的max_features。
- max_depth:每棵树的最大深度限制。与Random Forest不同,Gradient Boosting如果不对深度加以限制,最终是会Overfit的。
- early_stopping_rounds:用于控制在Out Of Sample的验证集上连续多少个迭代的分数都没有提高后就提前终止训练。用于防止 Overfitting。
一般的调参步骤是:
- 将训练数据的一部分划出来作为验证集。
- 先将 eta 设得比较高(比如 0.1),num_round 设为 300 ~ 500。
- 用 Grid Search 对其他参数进行搜索
- 逐步将 eta 降低,找到最佳值。
- 以验证集为watchlist,用找到的最佳参数组合重新在训练集上训练。注意观察算法的输出,看每次迭代后在验证集上分数的变化情况,从而得到最佳的early_stopping_rounds。
结合方法
平均法
- 简单平均法
- 加权平均法
投票法
- 绝对多数投票法:得票过半数的标记,否则拒绝预测(可靠性要求较高的学习任务)
- 相对多数投票法:得票最多的标记(学习任务要求必须提供预测结果)
- 加权投票法
基于类概率进行结合往往比基于类标记进行结合性能更好。
Blending
用不相交的数据训练不同的Base Model,将它们的输出取(加权)平均。
Stacking
Stacking先从初始数据集训练出初级学习器(个体学习器),然后“生成”一个新数据集用于训练次级学习器(用于结合的学习器,也称元学习器meta-learner)。新的数据集中,初级学习器的输出被当作样例输入特征。
注:训练阶段,次级训练集是通过初级学习器产生的,若直接使用初级学习器的训练集来产生次级训练集,则过拟合风险会比较大;因此,一般是通过使用交叉验证这样的方式。
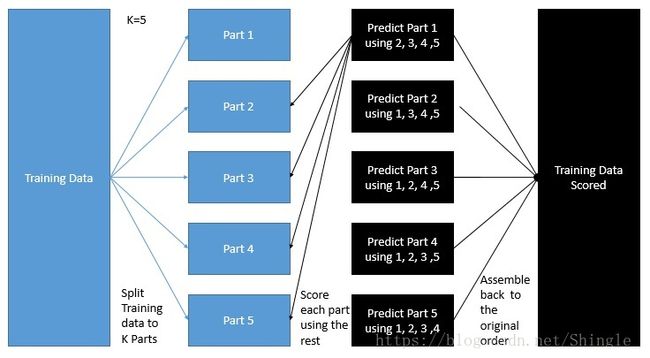

次级学习器的输入属性表示和次级学习算法对Stacking集成的泛化性能有很大影响。
《机器学习实战》 7
《统计学习方法》 8
《机器学习》 8
《XGBoost: A Scalable Tree Boosting System》 https://arxiv.org/pdf/1603.02754v1.pdf
http://www.flickering.cn/machine_learning/2016/08/gbdt%E8%AF%A6%E8%A7%A3%E4%B8%8A-%E7%90%86%E8%AE%BA/
http://matafight.github.io/2017/03/14/XGBoost-%E7%AE%80%E4%BB%8B/
http://blog.kaggle.com/2017/06/15/stacking-made-easy-an-introduction-to-stacknet-by-competitions-grandmaster-marios-michailidis-kazanova/