自然语言处理中的Attention机制
Attention in NLP
Advantage:
- integrate information over time
- handle variable-length sequences
- could be parallelized
Seq2seq
Encoder–Decoder framework:
Encoder:
h t = f ( x t , h t − 1 ) h_t = f(x_t, h_{t-1}) ht=f(xt,ht−1)
c = q ( h 1 , . . . , h T x ) c = q({h_1,...,h_{T_x}}) c=q(h1,...,hTx)
Sutskeveretal.(2014) used an LSTM as f and q ( h 1 , ⋅ ⋅ ⋅ , h T ) = h T q ({h_1,··· ,h_T}) = h_T q(h1,⋅⋅⋅,hT)=hT
Decoder:
p ( y ) = ∑ t = 1 T p ( y t ∣ y 1 , . . . , y t − 1 , c ) p(y) = \sum_{t=1}^T p(y_t | {y_1,...,y_{t-1}}, c) p(y)=t=1∑Tp(yt∣y1,...,yt−1,c)
p ( y t ∣ y 1 , . . . , y t − 1 , c ) = g ( y t − 1 , s t , c ) p(y_t | {y_1,...,y_{t-1}}, c) = g(y_{t-1}, s_t, c) p(yt∣y1,...,yt−1,c)=g(yt−1,st,c)
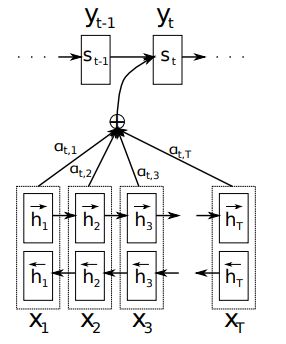
LEARNING TO ALIGN AND TRANSLATE
Decoder:
each conditional probability:
p ( y i ∣ y 1 , . . . , y i − 1 , x ) = g ( y i − 1 , s i , c i ) p(y_i | {y_1,...,y_{i-1}}, x) = g(y_{i-1}, s_i, c_i) p(yi∣y1,...,yi−1,x)=g(yi−1,si,ci)
s i = f ( s i − 1 , y i − 1 , c i ) s_i = f(s_{i-1}, y_{i-1}, c_i) si=f(si−1,yi−1,ci)
context vector c i c_i ci:
c i = ∑ j = 1 T x α i j h j c_i = \sum_{j=1}^{T_x} \alpha_{ij} h_j ci=j=1∑Txαijhj
α i j = e x p ( e i j ) ∑ k = 1 T x e x p ( e i k ) \alpha_{ij} = \frac{exp(e_{ij})}{\sum_{k=1}^{T_x}exp(e_{ik})} αij=∑k=1Txexp(eik)exp(eij)
e i j = a ( s i − 1 , h j ) e_{ij} = a(s_{i-1}, h_j) eij=a(si−1,hj)
in [1], a a a is computed by:
a ( s i − 1 , h j ) = v T t a n h ( W a s i − 1 + U a h j ) a(s_{i-1}, h_j) = v^T tanh(W_a s_{i-1} + U_a h_j) a(si−1,hj)=vTtanh(Wasi−1+Uahj)
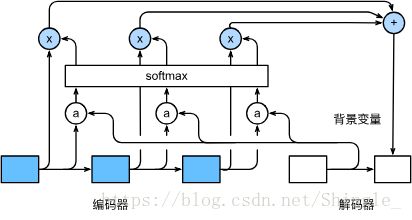
https://zh.gluon.ai/chapter_natural-language-processing/attention.html
Kinds of attention
Hard and soft attention
hard attention 会专注于很小的区域,而 soft attention 的注意力相对发散
Global and local attention

四种alignment function计算方法:
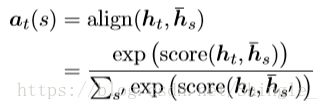

a n o t h e r , a t = s o f t m a x ( W a h t ) l o c a t i o n another, \qquad \qquad a_t = softmax(W_ah_t) \qquad \qquad location another,at=softmax(Waht)location
小结:

attention in feed-forword NN

simplified version of attention:
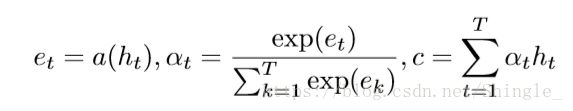
h e r e , a ( h t ) = t a n h ( W h c h t + b h c ) here, \qquad \qquad a(h_t) = tanh(W_{hc}h_t + b_{hc}) here,a(ht)=tanh(Whcht+bhc)
Hierarchical Attention

word level attention:
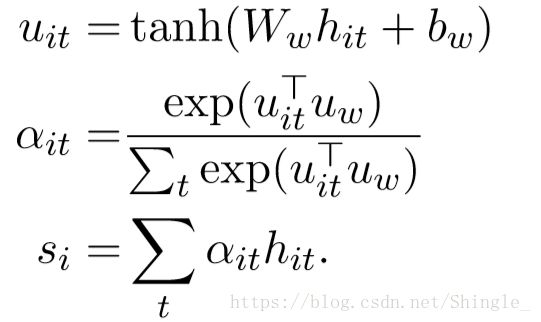
sentence level attention:
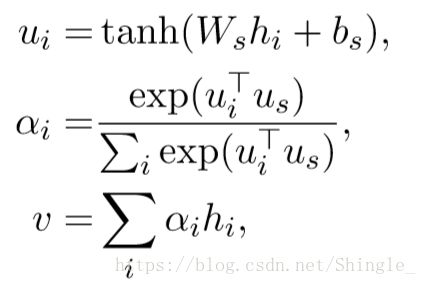
inner attention mechanism:

annotation h t h_t ht is first passed to a dense layer. An alignment coefficient α t α_t αt is then derived by comparing the output u t u_t ut of the dense layer with a trainable context vector u u u (initialized randomly) and normalizing with a softmax. The attentional vector s s s is finally obtained as a weighted sum of the annotations.
score can in theory be any alignment function. A straightforward approach is to use dot. The context vector can be interpreted as a representation of the optimal word, on average. When faced with a new example, the model uses this knowledge to decide which word it should pay attention to. During training, through backpropagation, the model updates the context vector, i.e., it adjusts its internal representation of what the optimal word is.
Note: The context vector in the definition of inner-attention above has nothing to do with the context vector used in seq2seq attention!
self-attention

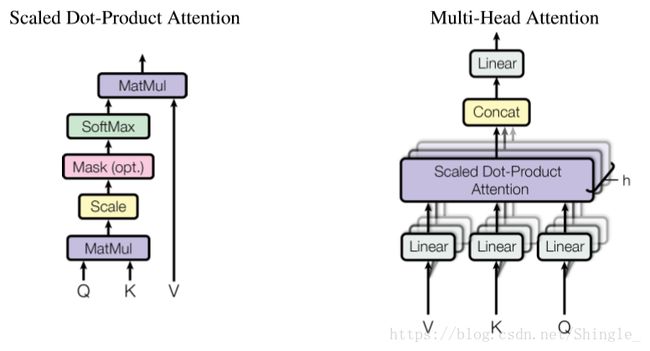
Self-Attention 即 K=V=Q,例如输入一个句子,那么里面的每个词都要和该句子中的所有词进行 Attention 计算。目的是学习句子内部的词依赖关系,捕获句子的内部结构。
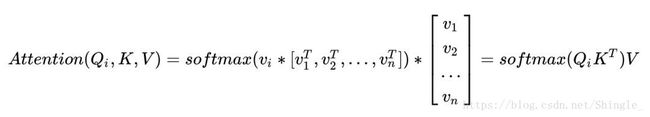


Conclusion
Attention 函数的本质可以被描述为一个查询(query)到一系列(键key-值value)对的映射。

将Source中的构成元素想象成是由一系列的
![]()
Attention机制的具体计算过程,如果对目前大多数方法进行抽象的话,可以将其归纳为三个阶段:第一个阶段根据Query和Key计算两者的相似性或者相关性;第二个阶段对第一阶段的原始分值进行归一化处理;第三个阶段根据权重系数对Value进行加权求和。

- 在一般任务的Encoder-Decoder框架中,输入Source和输出Target内容是不一样的,比如对于英-中机器翻译来说,Source是英文句子,Target是对应的翻译出的中文句子,Attention机制发生在Target的元素Query和Source中的所有元素之间。K=V
- Self Attention是Source内部元素之间或者Target内部元素之间发生的Attention机制,也可以理解为Target=Source这种特殊情况下的注意力计算机制。Q=K=V
Paper:
[1] 《NEURAL MACHINE TRANSLATION BY JOINTLY LEARNING TO ALIGN AND TRANSLATE》 https://arxiv.org/pdf/1409.0473v7.pdf
[2] 《Show, Attend and Tell: Neural Image Caption Generation with Visual Attention》 http://cn.arxiv.org/pdf/1502.03044v3.pdf
[2] 《Effective Approaches to Attention-based Neural Machine Translation》 http://cn.arxiv.org/pdf/1508.04025v5.pdf
[3] 《FEED-FORWARD NETWORKS WITH ATTENTION CAN SOLVE SOME LONG-TERM MEMORY PROBLEMS》 https://colinraffel.com/publications/iclr2016feed.pdf
[4] 《Hierarchical Attention Networks for Document Classification》 https://www.cs.cmu.edu/~diyiy/docs/naacl16.pdf
[5] 《Notes on Deep Learning for NLP》 https://arxiv.org/abs/1808.09772
[6] 《Attention Is All You Need》 https://arxiv.org/pdf/1706.03762.pdf
Blog:
https://richliao.github.io/supervised/classification/2016/12/26/textclassifier-HATN/
https://yq.aliyun.com/articles/342508?utm_content=m_39938
https://zh.gluon.ai/chapter_natural-language-processing/attention.html
https://www.cnblogs.com/robert-dlut/p/8638283.html
https://blog.csdn.net/malefactor/article/details/78767781
Implement:
https://keras.io/layers/writing-your-own-keras-layers/ (The existing Keras layers provide examples of how to implement almost anything. Never hesitate to read the source code!)
https://github.com/richliao/textClassifier/blob/master/textClassifierRNN.py
https://github.com/bojone/attention/blob/master/attention_keras.py