识别图中模糊的手写数字-导入图片数据集
MNIST是一个入门级的计算机视觉数据集。当我们开始学习编程时,第一件事往往是学习打印Hello World。在机器学习入门的领域里,我们会用MNIST数据集来实验各种模型。
1. MNIST数据集介绍
MNIST包含各种手写数字图片。

它也包含每一张图片对应的标签,告诉我们这个数字是几。上面图片的标签分别是5、0、4、1。
MNIST数据集的官网是http://yann.lecun.com/exdb/mnist/ ,可以在这里面手动下载数据集。
2. 下载并安装MNIST数据集
1. 利用TensorFlow代码下载MNIST
TensorFlow提供了一个库,可以直接用来自动下载与安装MNIST。
from tensorflow.examples.tutorials.mnist import input_data
mnist = input_data.read_data_sets("MNIST_data/", one_hot=True)运行上面的代码,会自动下载数据集并将文件解压到当前代码所在的同级目录下的MNIST_data文件夹下。
代码中的one_hot=True,表示将样本标签转化为one_hot编码。
举例来解释one_hot编码:假如一共10类。0的one_hot为1000000000,1的one_hot为0100000000,2的one_hot为0010000000,3的one_hot为0001000000。以此类推。只有一个位为1,1所在的位置就代表着第几类。
MNIST数据集中的图片是28×28 Pixel,所以,每一幅画就是一行784(28×28)列的数据,括号中的每一个值代表一个像素。
- 如果是黑白的图片,图片中黑色的地方数值为0;有图案的地方,数值为0~255之间的数字,代表其颜色的深度。
- 如果是彩色的图片,一个像素会由3个值来表示RGB(红、黄、蓝)。
将MNIST里面的信息打印出来,看看它的具体内容。
print('输入数据', mnist.train.images)
print('输入数据的shape', mnist.train.images.shape)
import pylab
im = mnist.train.images[1]
im = im.reshape(-1, 28)
pylab.imshow(im)
pylab.show()运行代码可得出结果:
Extracting MNIST_data/train-images-idx3-ubyte.gz
Extracting MNIST_data/train-labels-idx1-ubyte.gz
Extracting MNIST_data/t10k-images-idx3-ubyte.gz
Extracting MNIST_data/t10k-labels-idx1-ubyte.gz
输入数据 [[0. 0. 0. ... 0. 0. 0.]
[0. 0. 0. ... 0. 0. 0.]
[0. 0. 0. ... 0. 0. 0.]
...
[0. 0. 0. ... 0. 0. 0.]
[0. 0. 0. ... 0. 0. 0.]
[0. 0. 0. ... 0. 0. 0.]]
输入数据的shape (55000, 784)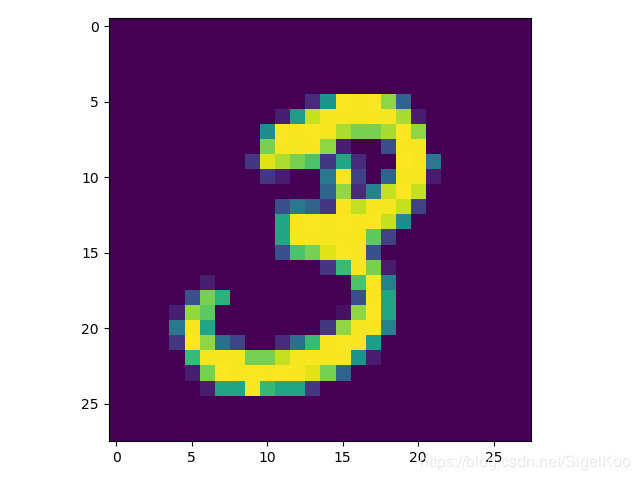
刚开始的打印信息是解压数据集的意思。如果是第一次运行,还会显示下载数据的相关信息。
接着打印出来的是训练集的图片信息,是一个55000行、784列的矩阵。即,训练集中有55000张图片。
2. MNIST数据集组成
在MNIST训练数据集中,mnist.train.images是一个形状为[55000, 784]的张量。其中,第1个维度数字用来索引图片,第2个维度数字用来索引每张图片中的像素点。此张量里的每一个元素,都表示某张图片里的某个像素的强度值,值介于0~255之间。
MNIST里包含3个数据集:第一个是训练数据集,另外两个分别是测试数据集(mnist.test)和验证数据集(mnist.validation)。
print('测试集数据的shape', mnist.test.images.shape)
print('验证集数据的shape', mnist.validation.images.shape)得到结果
测试集数据的shape (10000, 784)
验证集数据的shape (5000, 784)运行后可以发现在数据测试集里有10000条样本图片,验证数据集有5000个图片。
在实际的机器学习模型设计时,样本一般分为3部分:
- 一部分用于训练
- 一部分用于评估训练过程中的准确度(测试数据集)
- 一部分用于评估最终模型的准确度(验证数据集)
训练过程中,模型并没有遇到过验证数据集中的数据,所以利用验证数据集可以评估出模型的准确度。这个准确度越高,代表模型的泛化能力越强。
另外,这3个数据集还有分别对应的3个文件(标签文件),用来标注每个图片上的数字是几。把图片和标签放在一起,称为“样本”。通过样本来就可以实现一个有监督信号的深度学习模型。
相对用的,MNIST数据集的标签是介于0~9之间的数字,用来描述给定图片里表示的数字。标签数据是“one-hot vectors”:一个one-hot向量,除了某一位的数字是1外,其余各维度数字都是0。例如,标签0将表示为([1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0])。因此,mnist.train.labels是一个[55000, 10]的数字矩阵。
其余文章:
- 导入MNIST数据集。
- 分析MNIST样本特点定义变量。
- 构建模型。
- 训练模型并输出中间状态参数。
- 测试模型。
- 保存模型。
- 读取模型。