【机器学习】Tensorflow神经网络分析Kaggle的Titanic数据集
Titanic这也算是一个很经典的案例了,详情见【官网详情】(博主提交了一次,很菜七千多名,正确率:0.76555,排名有点渣,日后再优化,优化后,到两千多哈哈,0.79....左右,,还有很大的上升空间)
分析一个案例我主要是一下几步:
【1】导入依赖,加载数据
【2】分析数据,了解数据
【3】格式化数据,预处理数据
【4】建立模型,训练模型
【5】使用模型,测试模型
基本就这五大步骤,
【1】导入依赖,加载数据
import pandas as pd
from pandas import Series,DataFrame
import numpy as np
import matplotlib.pyplot as plt
# 设置图表中字体
import matplotlib as mpl
mpl.rcParams['font.sans-serif'] = ['SimHei']
data_train = pd.read_csv('../data/train.csv')
data_train.head()
data_train.head()主要是看看,数据是否加载上,是否家在正确。
【2】分析数据,了解数据
data_train.info()
RangeIndex: 891 entries, 0 to 890
Data columns (total 12 columns):
PassengerId 891 non-null int64
Survived 891 non-null int64
Pclass 891 non-null int64
Name 891 non-null object
Sex 891 non-null object
Age 714 non-null float64
SibSp 891 non-null int64
Parch 891 non-null int64
Ticket 891 non-null object
Fare 891 non-null float64
Cabin 189 non-null object
Embarked 891 non-null object
dtypes: float64(2), int64(5), object(5)
memory usage: 83.6+ KB • PassengerId => 乘客ID
• Survived => 获救情况(1为获救,0为未获救)
• Pclass => 乘客等级(1/2/3等舱位)
• Name => 乘客姓名
• Sex => 性别
• Age => 年龄
• SibSp => 堂兄弟/妹个数
• Parch => 父母与小孩个数
• Ticket => 船票信息
• Fare => 票价
• Cabin => 客舱
• Embarked => 登船港口data_train.describe()
PassengerId Survived Pclass Age SibSp Parch Fare
count 891.000000 891.000000 891.000000 714.000000 891.000000 891.000000 891.000000
mean 446.000000 0.383838 2.308642 29.699118 0.523008 0.381594 32.204208
std 257.353842 0.486592 0.836071 14.526497 1.102743 0.806057 49.693429
min 1.000000 0.000000 1.000000 0.420000 0.000000 0.000000 0.000000
25% 223.500000 0.000000 2.000000 20.125000 0.000000 0.000000 7.910400
50% 446.000000 0.000000 3.000000 28.000000 0.000000 0.000000 14.454200
75% 668.500000 1.000000 3.000000 38.000000 1.000000 0.000000 31.000000
max 891.000000 1.000000 3.000000 80.000000 8.000000 6.000000 512.329200fig = plt.figure(figsize=(15,10))
fig.set(alpha=0.2) # 设定图表颜色alpha参数
plt.subplot2grid((2,3),(0,0)) # 在一张大图里分列几个小图
data_train.Survived.value_counts().plot(kind='bar')# 柱状图
plt.title(u"获救情况 (1为获救)") # 标题
plt.ylabel(u"人数")
plt.subplot2grid((2,3),(0,1))
data_train.Pclass.value_counts().plot(kind="bar")
plt.ylabel(u"人数")
plt.title(u"乘客等级分布")
plt.subplot2grid((2,3),(0,2))
plt.scatter(data_train.Survived, data_train.Age)
plt.ylabel(u"年龄") # 设定纵坐标名称
plt.grid(b=True, which='major', axis='y')
plt.title(u"按年龄看获救分布 (1为获救)")
plt.subplot2grid((2,3),(1,0), colspan=2)
data_train.Age[data_train.Pclass == 1].plot(kind='kde')
data_train.Age[data_train.Pclass == 2].plot(kind='kde')
data_train.Age[data_train.Pclass == 3].plot(kind='kde')
plt.xlabel(u"年龄")# plots an axis lable
plt.ylabel(u"密度")
plt.title(u"各等级的乘客年龄分布")
plt.legend((u'头等舱', u'2等舱',u'3等舱'),loc='best') # sets our legend for our graph.
plt.subplot2grid((2,3),(1,2))
data_train.Embarked.value_counts().plot(kind='bar')
plt.title(u"各登船口岸上船人数")
plt.ylabel(u"人数")
plt.show()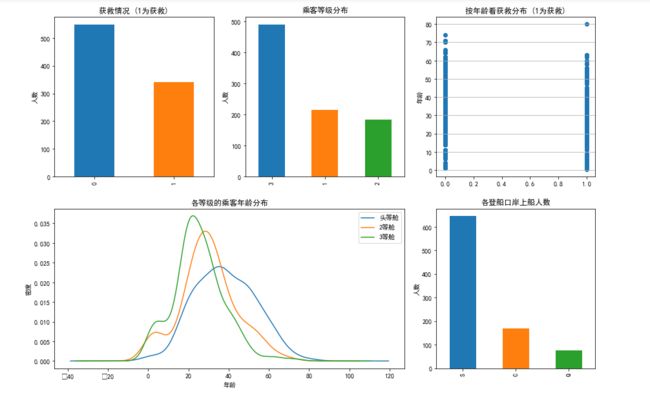
这几张图分别对获救情况、乘客等级、个口岸上船人数进行统计,右上角年龄与获救情况关系图,基本看不出来有关系,左下角乘客年龄与舱等级的分布,可分析出20-30岁的乘客较多的选择2-3等舱 (年轻,最穷的时候),30-50岁普遍选择头等舱 (黄金时期)
#看看各乘客等级的获救情况
fig = plt.figure()
fig.set(alpha=0.2) # 设定图表颜色alpha参数
Survived_0 = data_train.Pclass[data_train.Survived == 0].value_counts()
Survived_1 = data_train.Pclass[data_train.Survived == 1].value_counts()
df=pd.DataFrame({u'获救':Survived_1, u'未获救':Survived_0})
df.plot(kind='bar', stacked=True)#化成两层
plt.title(u"各乘客等级的获救情况")
plt.xlabel(u"乘客等级")
plt.ylabel(u"人数")
plt.show()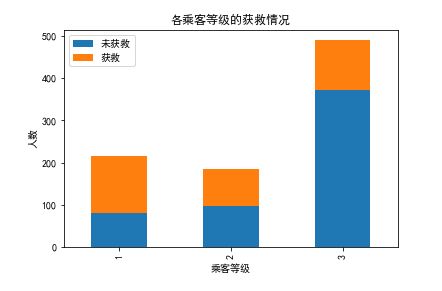
plt.plot(np.arange(3)+1,np.array(Survived_1/Survived_0))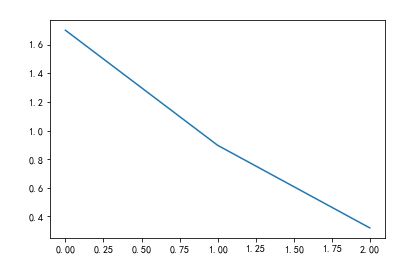
下面图是对根据上图比例画出的线,关系已经很明显了,有钱真好,三等舱的获救率非常低
#看看各性别的获救情况
fig = plt.figure()
fig.set(alpha=0.2) # 设定图表颜色alpha参数
Survived_m = data_train.Survived[data_train.Sex == 'male'].value_counts()
Survived_f = data_train.Survived[data_train.Sex == 'female'].value_counts()
df=pd.DataFrame({u'男性':Survived_m, u'女性':Survived_f})
df.plot(kind='bar', stacked=True)
plt.title(u"按性别看获救情况")
plt.xlabel(u"性别")
plt.ylabel(u"人数")
plt.show()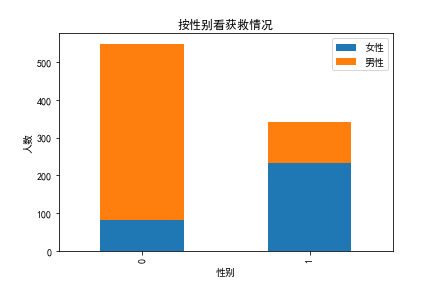
都不用再画折线图了,很明显,女性获救几率,远大于男性,“妇女和孩子线上救生船”
#然后我们再来看看各种舱级别情况下各性别的获救情况
fig=plt.figure(figsize=(15,7))
fig.set(alpha=0.65) # 设置图像透明度,无所谓
plt.title(u"根据舱等级和性别的获救情况")
ax1=fig.add_subplot(141)
data_train.Survived[data_train.Sex == 'female'][data_train.Pclass != 3].value_counts().plot(kind='bar', label="female highclass", color='#FA2479')
ax1.set_xticklabels([u"获救", u"未获救"], rotation=0)
ax1.legend([u"女性/高级舱"], loc='best')
ax2=fig.add_subplot(142, sharey=ax1)
data_train.Survived[data_train.Sex == 'female'][data_train.Pclass == 3].value_counts().plot(kind='bar', label='female, low class', color='pink')
ax2.set_xticklabels([u"未获救", u"获救"], rotation=0)
plt.legend([u"女性/低级舱"], loc='best')
ax3=fig.add_subplot(143, sharey=ax1)
data_train.Survived[data_train.Sex == 'male'][data_train.Pclass != 3].value_counts().plot(kind='bar', label='male, high class',color='lightblue')
ax3.set_xticklabels([u"未获救", u"获救"], rotation=0)
plt.legend([u"男性/高级舱"], loc='best')
ax4=fig.add_subplot(144, sharey=ax1)
data_train.Survived[data_train.Sex == 'male'][data_train.Pclass == 3].value_counts().plot(kind='bar', label='male low class', color='steelblue')
ax4.set_xticklabels([u"未获救", u"获救"], rotation=0)
plt.legend([u"男性/低级舱"], loc='best')
plt.show()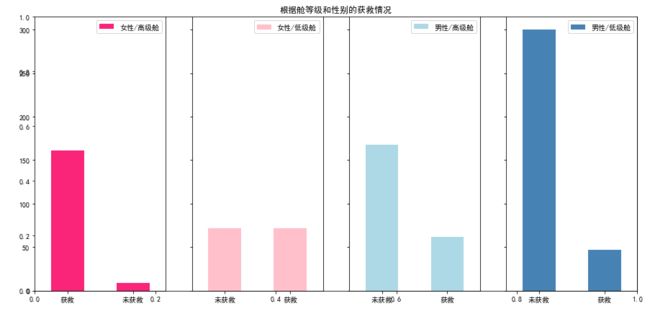
贵族女性几乎全部获救,是否获救和身份、性别关系很大。
fig = plt.figure()
fig.set(alpha=0.2) # 设定图表颜色alpha参数
Survived_0 = data_train.Embarked[data_train.Survived == 0].value_counts()
Survived_1 = data_train.Embarked[data_train.Survived == 1].value_counts()
df=pd.DataFrame({u'获救':Survived_1, u'未获救':Survived_0})
df.plot(kind='bar', stacked=True)
plt.title(u"各登录港口乘客的获救情况")
plt.xlabel(u"登录港口")
plt.ylabel(u"人数")
plt.show()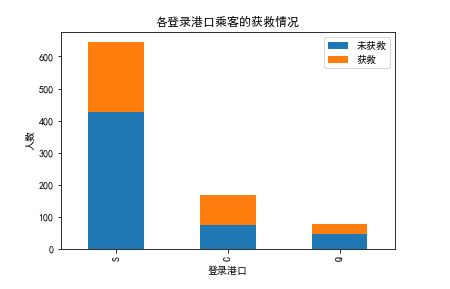
三个港口与获救关系几乎持平,关系不是很大(关系不大也加入模型,只是权值小一些而已)
plt.figure(figsize=(15,7))
Survived_0 = data_train.SibSp[data_train.Survived == 0].value_counts()
Survived_1 = data_train.SibSp[data_train.Survived == 1].value_counts()
df=pd.DataFrame({u'获救':Survived_1, u'未获救':Survived_0})
df.plot(kind='bar', stacked=True)
plt.title(u"堂兄弟/妹个数数量与获救情况")
plt.xlabel(u"堂兄弟/妹个数数量")
plt.ylabel(u"人数")
plt.show()plt.plot(np.arange(7),Survived_1/Survived_0)
plt.title(u"堂兄弟/妹个数数量与获救/未获救的比例")

根据右边折线图可以看出来,,有一个兄弟姐妹的获救概率比较大,是否获救和堂兄弟姐妹关系比较大。
基本上数据关系分析完了,这主要目的是为模型输入选取合适的参数。
【3】格式化数据,预处理数据
RangeIndex: 891 entries, 0 to 890
Data columns (total 12 columns):
PassengerId 891 non-null int64
Survived 891 non-null int64
Pclass 891 non-null int64
Name 891 non-null object
Sex 891 non-null object
Age 714 non-null float64
SibSp 891 non-null int64
Parch 891 non-null int64
Ticket 891 non-null object
Fare 891 non-null float64
Cabin 189 non-null object
Embarked 891 non-null object
dtypes: float64(2), int64(5), object(5)
memory usage: 83.6+ KB Age和Cabin有缺失参数,由于Cabin缺失过半,暂不考虑使用此数据,Age比较重要,此处用平均值补全。
#为了简便年了暂时用平均数代替,
data_train.Age[data_train.Age.isnull()] = data_train.Age.mean()
#Cabin 缺少太多了,暂且踢掉
try:
train_x = data_train[['Pclass','Sex','Age','SibSp','Parch','Fare','Embarked']]
except:
pass
train_x.info()此处选择这几项参数【['Pclass','Sex','Age','SibSp','Parch','Fare','Embarked']】
PassengerId,name没有实际含义去除即可,
Pclass Sex Age SibSp Parch Fare Embarked
0 3 male 22.0 1 0 7.2500 S
1 1 female 38.0 1 0 71.2833 C
2 3 female 26.0 0 0 7.9250 S
3 1 female 35.0 1 0 53.1000 S
4 3 male 35.0 0 0 8.0500 S其中Sex和Embarked还是字符串的,需要数字化,
train_x.Sex.value_counts()male 577
female 314
Name: Sex, dtype: int64train_x.Embarked.value_counts()S 645
C 169
Q 77
Name: Embarked, dtype: int64train_x.Sex[train_x.Sex=='male'] = 1
train_x.Sex[train_x.Sex=='female'] = 0
train_x.Embarked[train_x.Embarked=='S'] = 0
train_x.Embarked[train_x.Embarked=='C'] = 0.5
train_x.Embarked[train_x.Embarked=='Q'] = 1【4】建立模型,训练模型
都是老套路,主要学习莫烦的神经网络教程
"""
添加神经网络层的函数
inputs -- 输入内容
in_size -- 输入尺寸
out_size -- 输出尺寸
activation_function --- 激励函数,可以不用输入
"""
def add_layer(inputs,in_size,out_size,activation_function=None):
W = tf.Variable(tf.zeros([in_size,out_size])+0.01) #定义,in_size行,out_size列的矩阵,随机矩阵,全为0效果不佳
b = tf.Variable(tf.zeros([1,out_size])+0.01) #不建议为0
Wx_plus_b = tf.matmul(inputs,W) + b # WX + b
if activation_function is None: #如果有激励函数就激励,否则直接输出
output = Wx_plus_b
else:
output = activation_function(Wx_plus_b)
return outputimport tensorflow as tf
X = tf.placeholder(tf.float32,[None,7])
Y = tf.placeholder(tf.float32,[None,1])
output1 = add_layer(X,7,14,activation_function = tf.nn.sigmoid)
output2 = add_layer(output1,14,7,activation_function = tf.nn.sigmoid)
temp_y = add_layer(output2,7,1,activation_function = tf.nn.sigmoid)
loss = tf.reduce_mean(tf.reduce_sum(tf.square(Y-temp_y),
reduction_indices=[1]))#先求平方,再求和,在求平均
train_step = tf.train.AdamOptimizer(0.004).minimize(loss)#通过优化器,以0.1的学习率,减小误差loss# train_x = iris[['a','b','c']]
# train_y = iris[['class']]
#拆分训练集数据集,分为输入和输出
train_x = np.array(train_x).reshape(-1,7)
train_y = data_train.Survived.reshape(-1,1)
sess = tf.Session()
sess.run(tf.global_variables_initializer())
save_process = []
for i in range(300000):#训练90000次
sess.run(train_step,feed_dict={X:train_x,Y:train_y})
if i%300 == 0:#每300次记录损失值(偏差值)
save_process.append(sess.run(loss,feed_dict={X:train_x,Y:train_y}))
if i%3000 == 0:#每300次记录损失值(偏差值)
print(sess.run(loss,feed_dict={X:train_x,Y:train_y}))画出loss曲线
#第前两个数据比较大,踢掉
save_process = np.delete(save_process,[0,1])
plt.plot(range(len(save_process)),save_process)
模型训练的还阔以,测试一下
【5】使用模型,测试模型
test_csv = pd.read_csv("../data/test.csv")测试数据需要和训练数据有同样的预处理,所以讲预处理过程封装成函数:
def preprocessing(data):
""""""
items = ['Pclass','Sex','Age','SibSp','Parch','Fare','Embarked']
data.Age[data.Age.isnull()] = data.Age.mean()
test_x = data[items]
test_x.Sex[test_x.Sex=='male'] = 1
test_x.Sex[test_x.Sex=='female'] = 0
test_x.Embarked[test_x.Embarked=='S'] = 0
test_x.Embarked[test_x.Embarked=='C'] = 0.5
test_x.Embarked[test_x.Embarked=='Q'] = 1
return test_x
test_data_x = preprocessing(test_csv)开始测试:
test_data_y = sess.run(temp_y,feed_dict={X:test_data_x})threshold = 0.8#阈值根据感觉
test_data_y[test_data_y > threshold] = 1
test_data_y[test_data_y <= threshold] = 0
test_data_y = test_data_y.reshape(418,)
test_data_y = test_data_y.astype(np.int32,copy=False)
test_data_y[test_data_y > threshold] = 1
test_data_y[test_data_y <= threshold] = 0
passengerId = np.arange(len(test_data_y))+892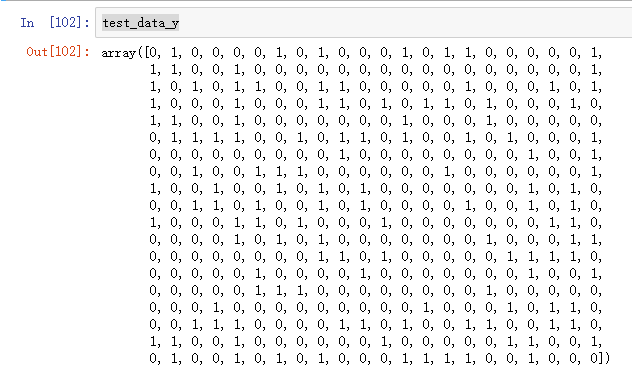
out_cvs = pd.DataFrame({'PassengerId':list(passengerId),'Survived':list(test_data_y)})
out_cvs.to_csv(path_or_buf = "../data/out.csv",index=False)
完了就能看自己的排名楼0.0
 这就是在下了,,嘿嘿,79约等于80,,还蛮不错的哈()
这就是在下了,,嘿嘿,79约等于80,,还蛮不错的哈()
完整notebook 看码云:【码云链接,不错的话给个小星星】