目标检测:YOLO v1学习笔记
文章目录
- 引言
- YOLO
- 设计理念
- 核心思想
- 算法特点
- 结构设计
- 训练
- 测试
- 要点分析
- 大致步骤
- 分成单元格
- 单元格输出
- 训练细节
- 论文中与RCNN的对比
- 不足
- 参考与引用文献
引言
提到Computer Vision,可能我们会最先想到CV的基本任务Image Classification,但在此基础上,还有其他更为复杂和有趣的任务,如Object Detection、Object Localization、Image Segmentation等等,而其中目标检测(Object Detection)是一件比较实际的且具有挑战性的计算机视觉任务,其可以看成图像分类与定位的结合,给定一张图片,目标检测系统要能够识别出图片的目标并给出其位置,由于图片中目标数是不定的,且要给出目标的精确位置,目标检测相比分类任务更复杂。目标检测的一个实际应用场景就是无人驾驶,如果能够在无人车上装载一个有效的目标检测系统,那么无人车将和人一样有了眼睛,可以快速地检测出前面的行人与车辆,从而作出实时决策。
在深度学习出现之前,传统的目标检测方法大概分为区域选择(滑窗)、特征提取(SIFT、HOG等)、分类器(SVM、Adaboost等)三个部分,其主要问题有两方面:一方面滑窗选择策略没有针对性、时间复杂度高,窗口冗余;另一方面手工设计的特征鲁棒性较差。自深度学习出现之后,目标检测取得了巨大的突破,最瞩目的两个方向有:
- 以RCNN为代表的基于Region Proposal的深度学习目标检测算法(RCNN,SPP-NET,Fast-RCNN,Faster-RCNN等),它们是two-stage的,需要先使用启发式方法(selective search)或者CNN网络(RPN)产生Region Proposal,然后再在Region Proposal上做分类与回归。
- 以YOLO为代表的基于回归方法的深度学习目标检测算法(YOLO,SSD等),其仅仅使用一个CNN网络直接预测不同目标的类别与位置。
本篇介绍YOLO算法,全称:You Only Look Once: Unified, Real-Time Object Detection. 其实个人觉得这个题目取得非常好,基本上把Yolo算法的特点概括全了:You Only Look Once说的是只需要一次CNN运算,Unified指的是这是一个统一的框架,提供end-to-end的预测,而Real-Time体现是Yolo算法速度快。
YOLO
论文链接:You only look once:unified real-time object detection
代码下载:https://github.com/pjreddie/darknet
Abstract
作者提出了一种新的物体检测方法YOLO。YOLO之前的物体检测方法主要是通过region proposal产生大量的可能包含待检测物体的 potential bounding box,再用分类器去判断每个 bounding box里是否包含有物体,以及物体所属类别的 probability或者 confidence,如R-CNN,Fast-R-CNN,Faster-R-CNN等。
YOLO不同于这些物体检测方法,它将物体检测任务当做一个regression问题来处理,使用一个神经网络,直接从一整张图像来预测出bounding box 的坐标、box中包含物体的置信度和物体的probabilities。因为YOLO的物体检测流程是在一个神经网络里完成的,所以可以end to end来优化物体检测性能。
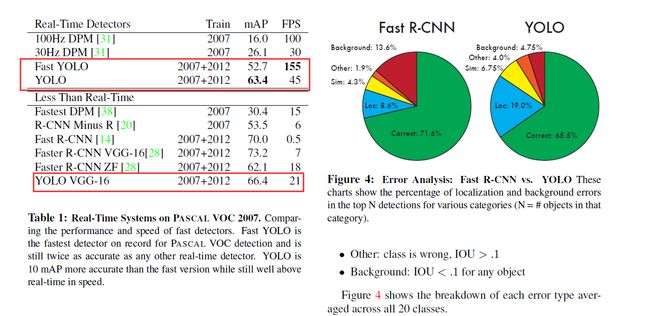
YOLO检测物体的速度很快,标准版本的YOLO在Titan X 的 GPU 上能达到45 FPS。网络较小的版本Fast YOLO在保持mAP是之前的其他实时物体检测器的两倍的同时,检测速度可以达到155 FPS。
相较于其他的state-of-the-art 物体检测系统,YOLO在物体定位时更容易出错,但是在背景上预测出不存在的物体(false positives)的情况会少一些。而且,YOLO比DPM、R-CNN等物体检测系统能够学到更加抽象的物体的特征,这使得YOLO可以从真实图像领域迁移到其他领域,如艺术。
设计理念
整体来看,Yolo算法采用一个单独的CNN模型实现end-to-end的目标检测,整个系统如图5所示:首先将输入图片resize到448x448,然后送入CNN网络,最后处理网络预测结果得到检测的目标。相比R-CNN算法,其是一个统一的框架,其速度更快,而且Yolo的训练过程也是end-to-end的。

核心思想
-
整张图作为网络的输入,把 Object Detection(物体检测)问题转化成一个Regression(回归)问题,用一个卷积神经网络结构直接在输出层回归bounding box的位置和bounding box所属的类别。
-
Faster RCNN中也直接用整张图作为输入,但是faster-RCNN整体还是采用了RCNN那种proposal+classifier的思想,只不过是将提取proposal的步骤放在CNN中实现了。
算法特点
- 将物体检测作为回归问题求解。基于一个单独的End-To-End网络,完成从原始图像的输入到物体位置和类别的输出,输入图像经过一次Inference,便能得到图像中所有物体的位置和其所属类别及相应的置信概率。
- YOLO网络借鉴了GoogLeNet分类网络结构。不同的是,YOLO未使用Inception Module,而是使用1x1卷积层(此处1x1卷积层的存在是为了跨通道信息整合)+3x3卷积层简单替代。
- Fast YOLO使用9个卷积层代替YOLO的24个,网络速度更快,在Titan X GPU上的速度是45 fps(frames per second),加速版的YOLO差不多是155fps。但同时损失了检测准确率。
- 使用全图作为 Context 信息,这一点和基于sliding window以及region proposal等检测算法不一样。与Fast RCNN相比,误检测率(把背景错认为物体)降低一半多。
- 泛化能力强,可以学到物体的generalizable representations,在自然图像上训练好的结果在艺术作品中的依然具有很好的效果。
结构设计
结构上主要的特点就是 unified detection,不再是原来许多步骤组成的物体检测,这使得模型的运行速度快,可以直接学习图像的全局信息,且可以end-to-end训练。

算法首先把输入图像划分成S*S的格子(grid cell),然后对每个格子都预测B个bounding boxes,每个bounding box都包含5个预测值:x,y,w,h和confidence(即每个bounding box除了要回归自身的位置之外,还要附带预测一个confidence值)。
- x,y就是bounding box的中心坐标,与grid cell对齐(即相对于当前grid cell的偏移值),使得范围变成0到1;
- w和h进行归一化(分别除以图像的w和h,这样最后的w和h就在0到1范围)
- confidence代表了所预测的box中含有object的置信度和这个box预测的有多准两重信息,计算公式如下: P r ( O b j e c t ) ∗ I O U p r e d t r u t h Pr(Object)*IOU^{truth}_{pred} Pr(Object)∗IOUpredtruth其中第一项表示是否有物体落在grid cell里(落在取1,否则取0),第二项表示预测的框和实际的框之间的IOU值。
所以如何判断一个grid cell中是否包含object呢?如果一个object的ground truth的中心点坐标在一个grid cell中,那么这个grid cell就是包含这个object,也就是说这个object的预测就由该grid cell负责。 每个grid cell都预测C个类别概率,表示一个grid cell在包含object的条件下属于某个类别的概率。

每个bounding box要预测 (x, y, w, h)和confidence共5个值,每个网格还要预测一个类别信息,记为C类。则SxS个网格,每个网格要预测B个bounding box还要预测C个categories。输出就是 S ∗ S ∗ ( 5 ∗ B + C ) S*S*(5*B+C) S∗S∗(5∗B+C)的一个tensor。
注意:class信息是针对每个网格的,confidence信息是针对每个bounding box的。
另外每个格子都预测C个假定类别的概率。
举例说明:在本文中,网络结构参考GooLeNet模型,包含24个卷积层和2个全连接层,卷积层主要用来提取特征,全连接层主要用来预测类别概率和坐标。对于卷积层,主要使用1x1卷积来做channle reduction,然后紧跟3x3卷积。对于卷积层和全连接层,采用Leaky ReLU激活函数,但是最后一层却采用线性激活函数。除了上面这个结构,文章还提出了一个轻量级版本Fast Yolo,其仅使用9个卷积层,并且卷积层中使用更少的卷积核。图像输入为448x448,取 S = 7 , B = 2 , C = 20 S=7,B=2,C=20 S=7,B=2,C=20(因为PASCAL VOC有20个类别),所以最后有 7 ∗ 7 ∗ 30 7*7*30 7∗7∗30 个tensor。如下图。

训练

- 预训练分类网络:在 ImageNet 1000-class Competition Dataset上预训练一个分类网络,这个网络是前文网络结构中的前20个卷积层+Average-Pooling Layer+Fully Connected Layer(此时网络输入是224*224)。
- 训练检测网络:“Object detection networks on convolutional feature maps” 提到在预训练网络中增加卷积和全链接层可以改善性能。YOLO添加4个卷积层和2个全链接层,随机初始化权重。检测要求细粒度的视觉信息,所以把网络输入也从224x224变成448x448。
(1)一幅图片分成7x7个网格,某个物体的中心落在这个网格中此网格就负责预测这个物体。每个网格预测两个Bounding Box。网格负责类别信息,Bounding Box负责坐标信息(4个坐标信息及一个置信度),所以最后一层输出为 7 ∗ 7 ∗ ( 2 ∗ ( 4 + 1 ) + 20 ) = 7 ∗ 7 ∗ 30 7*7*(2*(4+1)+20)=7*7*30 7∗7∗(2∗(4+1)+20)=7∗7∗30 的维度。
(2)Bounding Box的坐标使用图像的大小进行归一化0-1。Confidence使用 P r ( O b j e c t ) ∗ I O U p r e d t r u t h Pr(Object)*IOU^{truth}_{pred} Pr(Object)∗IOUpredtruth 计算,其中第一项表示是否有物体落在网格里,第二项表示预测的框和实际的框之间的IOU值。 - 损失函数的确定:损失函数的定义如下,损失函数的设计目标就是让坐标,置信度和类别这个三个方面达到很好的平衡。简单的全部采用了Sum-Squared Error Loss来做这件事会有以下不足:
① 8维的Localization Error和20维的Classification Error同等重要显然是不合理的;
② 如果一个网格中没有Object(一幅图中这种网格很多),那么就会将这些网格中的Box的Confidence Push到0,相比于较少的有Object的网格,这种做法是Overpowering的,这会导致网络不稳定甚至发散。
解决方案如下:

每个图片的每个单元格不一定都包含object,如果没有object,那么confidenceconfidence就会变成0,这样在优化模型的时候可能会让梯度跨越太大,模型不稳定跑飞了。为了平衡这一点,在损失函数中,设置两个参数 λ c o o r d λ_{coord} λcoord和 λ n o o b j λ_{noobj} λnoobj,其中 λ c o o r d λ_{coord} λcoord控制bbox预测位置的损失, λ n o o b j λ_{noobj} λnoobj控制单个格内没有目标的损失。
(1)更重视8维的坐标预测,给这些损失前面赋予更大的Loss Weight, 记为 λ c o o r d λ_{coord} λcoord ,在Pascal VOC训练中取5。(上图蓝色框)。
(2)对没有Object的Bbox的Confidence Loss,赋予小的Loss Weight,记为 λ n o o b j λ_{noobj} λnoobj,在Pascal VOC训练中取0.5。(上图橙色框)。
(3)有Object的Bbox的Confidence Loss(上图红色框)和类别的Loss (上图紫色框)的Loss Weight正常取1。
(4)对不同大小的Bbox预测中,相比于大Bbox预测偏一点,小Bbox预测偏一点更不能忍受。而Sum-Square Error Loss中对同样的偏移Loss是一样。为了缓和这个问题,将Bbox的Width和Height取平方根代替原本的Height和Width。 如下图:Small Bbox的横轴值较小,发生偏移时,反应到y轴上的Loss(下图绿色)比Big Bbox(下图红色)要大。

(5)一个网格预测多个Bbox,在训练时我们希望每个Object(Ground True box)只有一个Bbox专门负责(一个Object 一个Bbox)。具体做法是与Ground True Box(Object)的IOU最大的Bbox 负责该Ground True Box(Object)的预测。这种做法称作Bbox Predictor的Specialization(专职化)。每个预测器会对特定(Sizes,Aspect Ratio or Classed of Object)的Ground True Box预测的越来越好。

测试
在test的时候,每个网格预测的class信息( P r ( C l a s s i ∣ O b j e c t ) Pr(Class_i|Object) Pr(Classi∣Object))和bounding box预测的confidence信息( P r ( O b j e c t ) ∗ I O U p r e d t r u t h Pr(Object)*IOU^{truth}_{pred} Pr(Object)∗IOUpredtruth)相乘,就得到每个bounding box的class-specific confidence score: P r ( C l a s s i ∣ O b j e c t ) ∗ P r ( O b j e c t ) ∗ I O U p r e d t r u t h = P r ( C l a s s i ) ∗ I O U p r e d t r u t h Pr(Class_i|Object)*Pr(Object)*IOU^{truth}_{pred}=Pr(Class_i)*IOU^{truth}_{pred} Pr(Classi∣Object)∗Pr(Object)∗IOUpredtruth=Pr(Classi)∗IOUpredtruth
等式左边第一项就是每个网格预测的类别信息,第二三项就是每个bounding box预测的confidence。这个乘积即encode了预测的box属于某一类的概率,也有该box准确度的信息。
得到每个box的class-specific confidence score以后,设置阈值,滤掉得分低的boxes,对保留的boxes进行Non-Maximum Suppression(NMS)处理,就得到最终的检测结果。
这个乘法具体如何操作?

即得到每个bounding box属于哪一类的confidence score。也就是说最后会得到20*(772)=20*98的score矩阵,括号里面是bounding box的数量,20代表类别。接下来的操作都是20个类别轮流进行:在某个类别中(即矩阵的某一行),将得分少于阈值(0.2)的设置为0,然后再按得分从高到低排序。最后再用NMS算法去掉重复率较大的bounding box。
NMS:针对某一类别,选择得分最大的bounding box,然后计算它和其它bounding box的IOU值,如果IOU大于0.5,说明重复率较大,该得分设为0,如果不大于0.5,则不改;这样一轮后,再选择剩下的score里面最大的那个bounding box,然后计算该bounding box和其它bounding box的IOU,重复以上过程直到最后。
最后每个bounding box的20个score取最大的score,如果这个score大于0,那么这个bounding box就是这个socre对应的类别(矩阵的行),如果小于0,说明这个bounding box里面没有物体,跳过即可。
神经网络输出后的检测流程
非极大值抑制
获取Object Detect 结果
要点分析
大致步骤
- 整个图片resize到指定大小,得到图片 I n p u t r s Input_{rs} Inputrs,将图像划分成7*7的网格
- 将 I n p u t r s Input_{rs} Inputrs塞给CNN,对于每个网格,我们都预测2个边框(包括每个边框是目标的置信度以及每个边框区域在多个类别上的概率)
- 根据上一步可以预测出7x7x2个目标窗口,然后根据阈值去除可能性比较低的目标窗口,使用NMS(非极大值抑制)去除多余框,得到最后预测结果
分成单元格
首先会把原始图片resize到448×448,放缩到这个尺寸是为了后面整除来的方便。再把整个图片分成S×S(例:7×7)个单元格,此后以每个单元格为单位进行预测分析。

- 单元格需要完成的事
1. 如果一个object的中心落在某个单元格上,那么这个单元格负责预测这个物体(论文的思想是让每个单元格单独干活)。
2. 每个单元格需要预测B个bbox值(bbox值包括坐标和宽高),同时为每个bbox值预测一个置信度(confidence scores)。也就是每个单元格需要预测B×(4+1)个值。
3. 每个单元格需要预测CC(物体种类个数)个条件概率值.
【注意】: 每个单元格只能预测一种物体,并且直接预测物体的概率值。但是每个单元格可以预测多个bbox值(包括置信度)。

-
单元格数据
我们细致的分析一下每个单元格预测的 B B B个 ( x , y , w , h , c o n f i d e n c e ) (x,y,w,h,confidence) (x,y,w,h,confidence):- ( x , y ) (x,y) (x,y)是bbox的中心相对于单元格的offset
- ( w , h ) (w,h) (w,h)是bbox相对于整个图片的比例
- confidenceconfidence下面有详解
-
何 为 ( x , y ) 何为(x,y) 何为(x,y)?
对于蓝色框的那个单元格(坐标为( x c o l = 1 , y r o w = 4 x_{col}=1,y_{row}=4 xcol=1,yrow=4)),假设它预测的是红色框的bbox(即object是愚蠢的阿拉斯加),我们设bbox的中心坐标为 ( x c , y c ) (x_c,y_c) (xc,yc),那么最终预测出来的 ( x , y ) (x,y) (x,y)是经过归一化处理的,表示的时中心相对于单元格的offset,计算公式如下:
x = x c w i ∗ S − x c o l , y = y c h i ∗ S − y r o w x=\frac{x_c}{w_i}*S−x_{col},y=\frac{y_c}{h_i}*S−y_{row} x=wixc∗S−xcol,y=hiyc∗S−yrow -
何为 ( w , h ) (w,h) (w,h)?
预测的bbox的宽高为 b b b, h b h_b hb, ( w , b ) (w,b) (w,b)表示的是bbox的是相对于整张图片的占比,计算公式如下:
w = w b w i , h = h b h i w=\frac{w_b}{w_i},h=\frac{h_b}{h_i} w=wiwb,h=hihb -
何为 C o n f i d e n c e Confidence Confidence
这个置信度有两个含义:一是格子内是否有目标,二是bbox的准确度。我们定义置信度为 P r ( O b j e c t ) ∗ I O U p r e d t r u t h Pr(Object)*IOU^{truth}_{pred} Pr(Object)∗IOUpredtruth
-如果格子内有物体,则 P r ( O b j e c t ) = 1 Pr(Object)=1 Pr(Object)=1,此时置信度等于IoU
-如果格子内没有物体,则 P r ( O b j e c t ) = 0 Pr(Object)=0 Pr(Object)=0,此时置信度为0 -
C个种类的概率值
每个网格在输出bbox值的同时要给出给个网格存在object的类型。记为: P r ( C l a s s i ∣ O b j e c t ) Pr(Class_i|Object) Pr(Classi∣Object)这是条件概率。
需要注意的是:输出的种类概率值是针对网格的,不是针对bbox的。所以一个网格只会输出CC个种类信息。(这样就是默认为一个格子内只能预测一种类别的object了,简化了计算,但对于检测小object很不利)。
在检测目标时,我们把confidence做处理: P r ( C l a s s i ∣ O b j e c t ) ∗ P r ( O b j e c t ) ∗ I O U p r e d t r u t h = P r ( C l a s s i ) ∗ I O U p r e d t r u t h Pr(Class_i|Object)*Pr(Object)*IOU^{truth}_{pred}=Pr(Class_i)*IOU^{truth}_{pred} Pr(Classi∣Object)∗Pr(Object)∗IOUpredtruth=Pr(Classi)∗IOUpredtruth这就是每个单元格的class-specific,这即包含了预测的类别信息,也包含了对bbox值的准确度。 我们可以设置一个阈值,把低分的class-specific confidence scores滤掉,剩下的塞给非极大值抑制,得到最终的标定框。
【Tips】对于这部分可以看deepsystem.ai的PPT,讲的很详细。
一个grid cell中是否有object怎么界定?
首先要明白grid cell的含义,以文中77为例,这个size其实就是对输入图像(假设是224224)不断提取特征然后sample得到的(缩小了32倍),然后就是把输入图像划分成7*7个grid cell,这样输入图像中的32个像素点就对应一个grid cell。回归正题,那么我们有每个object的标注信息,也就是知道每个object的中心点坐标在输入图像的哪个位置,那么不就相当于知道了每个object的中心点坐标属于哪个grid cell了吗,而只要object的中心点坐标落在哪个grid cell中,这个object就由哪个grid cell负责预测,也就是该grid cell包含这个object。另外由于一个grid cell会预测两个bounding box,实际上只有一个bounding box是用来预测属于该grid cell的object的,因为这两个bounding box到底哪个来预测呢?答案是:和该object的ground truth的IOU值最大的bounding box。
单元格输出
每个网络一共会输出: B × ( 4 + 1 ) + C B×(4+1)+C B×(4+1)+C 个预测值.
故所有的单元格输出为: S × S × ( B × 5 + C ) S×S×(B×5+C) S×S×(B×5+C) 个预测值.
YOLO论文中: S = 7 , B = 2 , C = 20 S=7,B=2,C=20 S=7,B=2,C=20
所有单元格输出为 7 × 7 × ( 2 × 5 + 20 ) 7×7×(2×5+20) 7×7×(2×5+20),即最终的输出为 7 × 7 × 30 7×7×30 7×7×30 的张量。
训练细节
- 在激活函数上:
最后一层使用的是标准的线性激活函数,其他的层都使用leaky rectified linear activation(leaky RELU):
ϕ ( x ) = { x i f x > 0 0.1 x , o t h e r e l s e ϕ(x)=\begin{cases} x & if x>0\\ 0.1x &, otherelse \end{cases} ϕ(x)={x0.1xif x>0,otherelse - 在学习率上:
- 前75个epoch设置为 1 0 − 2 10^{−2} 10−2
- 再30个epoch设置为 1 0 − 3 10^{−3} 10−3
- 最后30个epoch设置为 1 0 − 4 10^{−4} 10−4
- 其他的训练细节:
- batch=64
- 动量0.9,衰减为0.0005
- 使用dropout,设置为0.5,接在第一个FC层后
- 对样本做了数据增强
论文中与RCNN的对比
R-CNN. R-CNN and its variants use region proposals instead of sliding windows to find objects in images. Selective Search generates potential bounding boxes, a convolutional network extracts features, an SVM scores the boxes, a linear model adjusts the bounding boxes, and non-max suppression eliminates duplicate detections. Each stage of this complex pipeline must be precisely tuned independently and the resulting system is very slow, taking more than 40 seconds per image at test time.
R-CNN及其变种使用推荐区域而不是滑动窗口来寻找图像中的目标。选择性搜索产生潜在的边界框,卷积网络提取特征,SVM对边界框进行打分,线性模型调整边界框,非极大值抑制消除重复检测。这个复杂流程的每个阶段都必须独立地进行精确调整,所得到的系统非常慢,测试时每张图像需要超过40秒。
YOLO与R-CNN有一些相似之处。每个网格单元提出潜在的边界框并使用卷积特征对这些框进行评分。但是,我们的系统对网格单元提出进行了空间限制,这有助于缓解对同一目标的多次检测。我们的系统还提出了更少的边界框,每张图像只有98个,而选择性搜索则只有2000个左右。最后,我们的系统将这些单独的组件组合成一个单一的,共同优化的模型。
不足
- YOLO对相互靠的很近的物体(挨在一起且中点都落在同一个格子上的情况),还有很小的群体检测效果不好,这是因为一个网格中只预测了两个框,并且只属于一类。
- 测试图像中,当同一类物体出现的不常见的长宽比和其他情况时泛化能力偏弱。
- 由于损失函数的问题,定位误差是影响检测效果的主要原因,尤其是大小物体的处理上,还有待加强。
- YOLO的定位准确率相对于fast rcnn比较差,但是YOLO对背景的误判率比Fast RCNN的误判率低很多。这说明了YOLO中把物体检测的思路转成回归问题的思路有较好的准确率,但是bounding box的定位不是很好。
参考与引用文献
- yoloV1,看过好多篇,这篇感觉讲的最通俗易懂
- 物体检测论文-YOLO系列
- 论文阅读笔记:You Only Look Once: Unified, Real-Time Object Detection
- RCNN学习笔记(6):You Only Look Once(YOLO):Unified, Real-Time Object Detection
- 目标检测之YOLO,SSD
- 知乎:https://zhuanlan.zhihu.com/p/24916786
- YOLO(You Only Look Once)算法详解
- 从YOLOv1到YOLOv3,目标检测的进化之路
- YOLOv1论文理解