TensorFlow 模型优化工具包正式推出
来源 | TensorFlow 公众号
我们非常激动地宣布 TensorFlow 新增一个优化工具包,这是一套让新手和高级开发者都可以用来优化机器学习模型以进行部署和执行的技术。
我们预期这些技术对优化任何准备部署的 TensorFlow 模型都会非常有用,但对于 TensorFlow Lite 开发者而言,这些技术尤为重要,因为他们在设备上提供模型时会受到内存紧张、功耗约束及存储空间限制等条件的制约。如果您尚未试用过 TensorFlow Lite,可以点击此处,了解更多信息。
注:此处链接
https://www.tensorflow.org/lite/

优化模型以缩减尺寸、延时和功率,令其在精确度上的损耗可以忽略不计
我们新支持的第一项技术是 TensorFlow Lite 转换工具的训练后量化。对于相关机器学习模型,这项技术可以实现高达 4 倍的压缩,并能将执行速度提升 3 倍。
通过模型量化,开发者还可以获得因功耗降低而带来的额外益处。这有助于开发者在除手机之外的边缘设备上部署模型。
启用训练后量化
我们将训练后量化技术集成到 TensorFlow Lite 转换工具中。这项技术很容易入门:在完成 TensorFlow 模型构建后,开发者只需在 TensorFlow Lite 转换工具中启用 “post_training_quantize” 标记即可。假设保存后的模型存储在 saved_model_dir 中,则可以生成量化的 tflite flatbuffer:
converter=tf.contrib.lite.TocoConverter.from_saved_model(saved_model_dir)
converter.post_training_quantize=True
tflite_quantized_model=converter.convert()
open(“quantized_model.tflite”, “wb”).write(tflite_quantized_model)
我们的教程将深入介绍如何执行此操作。我们希望日后在通用的 TensorFlow 工具中也纳入此技术,以便将其用于在 TensorFlow Lite 目前不支持的平台上进行部署。
注:教程链接
https://github.com/tensorflow/tensorflow/blob/master/tensorflow/contrib/lite/tutorials/post_training_quant.ipynb
训练后量化的益处
- 使模型尺寸缩减 4 倍
- 对于主要由卷积层组成的模型,可以使其执行速度提高 10–50%
- 使基于 RNN 的模型速度提升 3 倍
- 由于对内存和计算的要求下降,我们预计大部分模型的功耗都会有所降低
请参阅下图,了解若干模型的尺寸缩减和执行速度加快情况(使用单核心 Android Pixel 2 手机测量)。
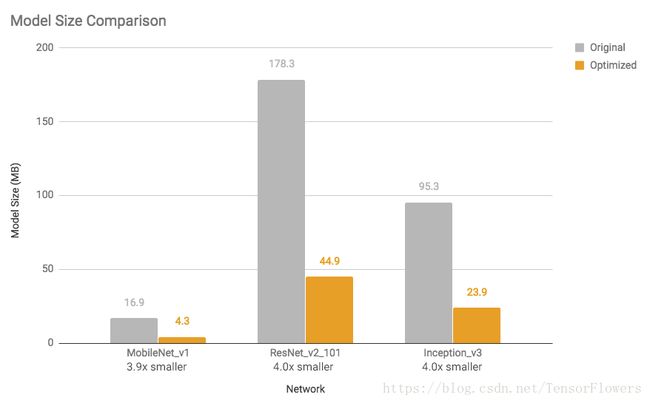
图 1:模型尺寸对比:优化后的模型缩小了几乎 4 倍

图 2:延时对比:优化后的模型速度提升了 1.2 到 1.4 倍
这些速度提升和模型尺寸缩减对精确度基本没有影响。一般情况下,对手头任务而言已经很小的模型(例如,用于图像分类的 MobileNet v1)可能精确度损耗较多。我们为许多这样的模型提供了预训练的完整量化模型。
注:完整量化模型链接
https://github.com/tensorflow/tensorflow/blob/master/tensorflow/contrib/lite/g3doc/models.md
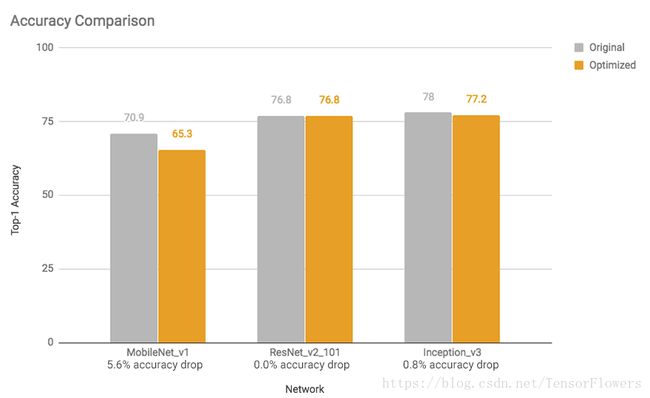
图 3:精确度对比:优化后模型的精确度下降可以忽略不计(MobileNet 除外)
我们希望日后可以继续改进成果,请参阅模型优化指南,获取最新测量数据。
注:模型优化链接
https://www.tensorflow.org/performance/model_optimization
训练后量化的工作原理
在后台,我们将参数(即神经网络权重)的精度从其训练时的 32 位浮点数值降低到更小且更高效的 8 位整数值,以通过这种方式进行优化(也称为量化)。如需了解更多详情,请参阅训练后量化指南。
注:训练后量化指南链接
https://www.tensorflow.org/performance/post_training_quantization
这些优化可确保将所产生模型中精度降低的运算定义与混合使用固定和浮点数学的内核实现进行配对。这会使模型以较低精度快速执行最繁重的计算,但以较高精度执行最敏感的计算,因此在执行此类任务时通常只会造成很少甚至完全不会造成最终精确度损耗,而执行速度却远远超过纯浮点的方式。如果运算中没有匹配的“混合”内核,或者工具包认为不必要,则模型会将这些参数重新转换为较高的浮点精度执行。如需受支持的混合运算列表,请参阅训练后量化页面。
注:训练后量化页面链接
https://www.tensorflow.org/performance/post_training_quantization
未来工作
我们将继续改进训练后量化技术,同时开发能够使模型优化更加简单的其他技术。我们会将这些技术集成到相关的 TensorFlow 工作流程中,让它们更加轻松易用。
训练后量化是我们正在开发的优化工具包中的第一款产品。我们很期待收到开发者的使用反馈。
请在 GitHub 上提交问题,并在 Stack Overflow 上提问。
注:GitHub 链接
https://github.com/tensorflow/tensorflow/issues
Stack Overflow 链接
https://stackoverflow.com/questions/tagged/tensorflow-lite
致谢
非常感谢 Raghu Krishnamoorthi、Raziel Alvrarez、Suharsh Sivakumar、Yunlu Li、Alan Chiao、Pete Warden、Shashi Shekhar、Sarah Sirajuddin 和 Tim Davis 的重要贡献。同时衷心感谢 Mark Daoust 帮助我们创建 Colab 教程。感谢 Billy Lamberta 和 Lawrence Chan 帮助创建网站。
注:Colab 教程链接
https://github.com/tensorflow/tensorflow/blob/master/tensorflow/contrib/lite/tutorials/post_training_quant.ipynb
网站链接
https://www.tensorflow.org/performance/model_optimization